
17.3.2. The Match and Regex Iterator Types
The program on page 729 that found violations of the “i before e except after c” grammar rule printed only the first match in its input sequence. We can get all the matches by using an sregex_iterator
. The regex iterators are iterator adaptors (§ 9.6, p. 368) that are bound to an input sequence and a regex object. As described in Table 17.8 (on the previous page), there are specific regex iterator types that correspond to each of the different types of input sequences. The iterator operations are described in Table 17.9 (p. 736).
Table 17.9. sregex_iterator Operations

When we bind an sregex_iterator to a string and a regex object, the iterator is automatically positioned on the first match in the given string. That is, the sregex_iterator constructor calls regex_search on the given string and regex. When we dereference the iterator, we get an smatch object corresponding to the results from the most recent search. When we increment the iterator, it calls regex_search to find the next match in the input string.
Using an sregex_iterator
As an example, we’ll extend our program to find all the violations of the “i before e except after c” grammar rule in a file of text. We’ll assume that the string named file holds the entire contents of the input file that we want to search. This version of the program will use the same pattern as our original one, but will use a sregex_iterator to do the search:
// find the characters ei that follow a character other than c
string pattern("[^c]ei");
// we want the whole word in which our pattern appears
pattern = "[[:alpha:]]*" + pattern + "[[:alpha:]]*";
regex r(pattern, regex::icase); // we'll ignore case in doing the match
// it will repeatedly call regex_search to find all matches in file
for (sregex_iterator it(file.begin(), file.end(), r), end_it;
it != end_it; ++it)
cout << it->str() << endl; // matched word
The for loop iterates through each match to r inside file. The initializer in the for defines it and end_it. When we define it, the sregex_iterator constructor calls regex_search to position it on the first match in file. The empty sregex_iterator, end_it, acts as the off-the-end iterator. The increment in the for “advances” the iterator by calling regex_search. When we dereference the iterator, we get an smatch object representing the current match. We call the str member of the match to print the matching word.
We can think of this loop as jumping from match to match as illustrated in Figure 17.1.

Figure 17.1. Using an sregex_iterator
Using the Match Data
If we run this loop on test_str from our original program, the output would be
freind
theif
However, finding just the words that match our expression is not so useful. If we ran the program on a larger input sequence—for example, on the text of this chapter—we’d want to see the context within which the word occurs, such as
hey read or write according to the type
>>> being <<<
handled. The input operators ignore whi
In addition to letting us print the part of the input string that was matched, the match classes give us more detailed information about the match. The operations on these types are listed in Table 17.10 (p. 737) and Table 17.11 (p. 741).
Table 17.10. smatch Operations

Table 17.11. Submatch Operations

We’ll have more to say about the smatch and ssub_match
types in the next section. For now, what we need to know is that these types let us see the context of a match. The match types have members named prefix and suffix, which return a ssub_match object representing the part of the input sequence ahead of and after the current match, respectively. A ssub_match object has members named str and length, which return the matched string and size of that string, respectively. We can use these operations to rewrite the loop of our grammar program:
// same for loop header as before
for (sregex_iterator it(file.begin(), file.end(), r), end_it;
it != end_it; ++it) {
auto pos = it->prefix().length(); // size of the prefix
pos = pos > 40 ? pos - 40 : 0; // we want up to 40 characters
cout << it->prefix().str().substr(pos) // last part of the prefix
<< "
>>> " << it->str() << " <<<
" // matched word
<< it->suffix().str().substr(0, 40) // first part of the suffix
<< endl;
}
The loop itself operates the same way as our previous program. What’s changed is the processing inside the for, which is illustrated in Figure 17.2.
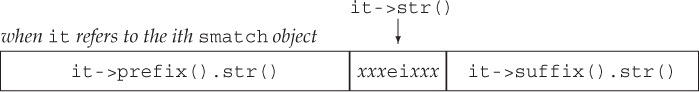
Figure 17.2. The smatch Object Representing a Particular Match
We call prefix, which returns an ssub_match object that represents the part of file ahead of the current match. We call length on that ssub_match to find out how many characters are in the part of file ahead of the match. Next we adjust pos to be the index of the character 40 from the end of the prefix. If the prefix has fewer than 40 characters, we set pos to 0, which means we’ll print the entire prefix. We use substr (§ 9.5.1, p. 361) to print from the given position to the end of the prefix.
Having printed the characters that precede the match, we next print the match itself with some additional formatting so that the matched word will stand out in the output. After printing the matched portion, we print (up to) the first 40 characters in the part of file that comes after this match.