
5.1 Attention of Population-based Inference
A biologically plausible top-down model was proposed in 2000 [11], and then enhanced in 2004 [28] and 2005 [12] by Hamker. It is a complete top-down computational model, since it concerns prior knowledge's memory, representation, learning and integration with observed data. Moreover, in this model all the computations are based on cell populations; that is, any kind of feature in each location is represented by a cell population. Each cell in the population has its preferred value as with simple cells in the brain. Regardless of the population, the flowchart of the top-down model is illustrated in Figure 5.1.
Figure 5.1 The flowchart of the population-based inference top-down model
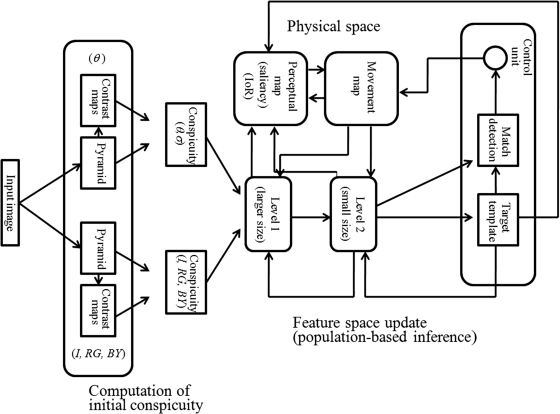
The data flow between blocks of Figure 5.1 includes feed-forward from the left to the right, the feedback from the right to the left and some interconnects between blocks indicated by the arrows. In the feed-forward part, four feature channels such as intensity (I), red-green (RG), blue-yellow (BY) and orientation (θ) are computed from the input image by filtering and down-sampling to four pyramids (each pyramid includes eight feature maps, 1 . . . 8) as in the BS model mentioned in Chapter 3. The centre–surround contrast processing in the four pyramids generates their respective contrast maps. The above processing is shown in the leftmost rounded rectangle of Figure 5.1. The initial conspicuity (the cells' activity) at each channel and each location is calculated from the maps with different resolutions in the pyramid and their corresponding contrast maps, which integrates maps of all resolutions to one conspicuity map in each feature channel. It is worth noting that in this model the orientation channel will split two conspicuity maps: one is the initial orientation conspicuity map (θ), and the other is the initial scale or spatial frequency conspicuity map (σ) which is different from the BS model. Now, a total of five initial conspicuity maps (I, RG, BY, θ, σ) are built, representing the initial values of five feature channels for all cells in the populations at each location (see the next subsection in details).
The initial conspicuity maps for the five channels are input to the feature space level 1. In the level 1, the five conspicuity maps with the same scale are used as initial conspicuity maps, and the values in these initial conspicuity maps are updated by feedback signals from the feature space level 2 and the movement map. The result of the feature space level 1 is transferred to the feature space level 2. The difference between the feature spaces level 1 and level 2 is just the scale. The cells at level 2 have larger receptive fields than those at level 1, and the size of each conspicuity map at level 2 is smaller than that at level 1. The conspicuity maps with smaller size at level 2 are updated by information from prior knowledge. The updated results of the feature space at level 2 are sent to the working memory in the learning stage, or to the match detection block in order to see if the features are matched with the required target. The feed-forward path can be seen as the arrowheads from the left to the right in Figure 5.1 (computation of initial conspicuity map and feature space update).
In the feedback part, the aforementioned prior knowledge (the features of the expected target in the model), in the form of cell populations, is stored in working memory (the block named ‘Target template’ in the rightmost rounded rectangle of Figure 5.1). These features in the working memory, which do not include location information, are fed back to the feature space level 2 and enhance the activties of those cells with features similar to those stored in working memory. The prior knowledge related to the interesting location comes from the movement map that predicts the eye fixation location, which is also fed back to the feature space level 2, and this enhances the conspicuity of all features at the location. The output of the feature space level 2 is fed back to the feature space level 1 to participate in update of level 1. The update of the conspicuity maps at level 1 depends on the information from level 2 and from the movement map resembling the feature space at level 2. The feedback path can be seen in Figure 5.1. The saliency map is colligated from all results from the feature space level 1, level 2, target template and movement map to create the perceptual map and to guide eye shifts. A control unit is set in this model to control eye shift. If the attention focus does not match the prior knowledge it will reset the fixation until the desired target is found. When the most salient location is found and has been processed, the signal of inhibition of return (IoR) can suppress this most salient region for it to be reselected in the next attention period. The movement map and perceptual map (saliency map) are considered in physical space which is different from feature space, namely levels 1 and 2.
This model has two peculiarities: (1) all computation and the influence of prior knowledge are based on cell populations that are similar to simple cells in the human brain; (2) the target detection is a dynamic process related to cell activities in the feature space levels 1 and 2 and prior knowledge influence. The cell population representation and each block's work will now be introduced.
5.1.1 Features in Population Codes
How information is encoded by the neural architecture in the brain is fundamental in computational neuroscience. Many studies have shown that individual elements of information are not coded by a single cell, but rather by populations or groups of cells in the neural system [29, 30]. It is known from Figure 4.7 that a group of cells share the same receptive field and extract these features in the common receptive field, such as orientation, colour, intensity, direction of motion and so on. In fact, the value of each feature in the receptive field is represented by the activity of a cell cluster in the brain. A simple cell in the brain can respond to a preferred value of a feature in its receptive field by its firing; for example, a cell preferring the orientation 45° has higher firing rate for a 45° bar in the scene than other cells preferring other orientations (0°, 10°, . . . 40°, 50°, 60°, . . . 90°) in their common receptive field. However, other cells for the feature value, orientation 45°, defined in the same receptive field still have some firing rate. So the pattern of all cells' firing rates in a population represents the value (45°) of the orientation feature in the receptive field, which is called the population code. If the feature value for an orientation feature that lies between −180° and +180° is represented by one-dimensional axis, then the population for the orientation feature is defined by i ![]() N cells equably sampling the axis with each cell tuned around its preferred value (the feature value, ui), for which the response (firing rate) of the cell is maximal. An example for a feature channel is shown in Figure 5.2, in which N bell-shaped curves represent the responses (firing rate) for the N cells respectively. Each cell has its preferred feature value (the peak value of its corresponding bell-shaped curve) and response range (the covered range of the bell-shaped curve). Consequently, for an actual feature value at any location in any feature channel extracted from input scene, the N cells at the location x related to the feature d generate their respective firing rate according to the response curves in Figure 5.2, denoted as rd,i,x, i
N cells equably sampling the axis with each cell tuned around its preferred value (the feature value, ui), for which the response (firing rate) of the cell is maximal. An example for a feature channel is shown in Figure 5.2, in which N bell-shaped curves represent the responses (firing rate) for the N cells respectively. Each cell has its preferred feature value (the peak value of its corresponding bell-shaped curve) and response range (the covered range of the bell-shaped curve). Consequently, for an actual feature value at any location in any feature channel extracted from input scene, the N cells at the location x related to the feature d generate their respective firing rate according to the response curves in Figure 5.2, denoted as rd,i,x, i ![]() {1, . . . N}, where x is location coordinate x
{1, . . . N}, where x is location coordinate x ![]() (x1, x2) in the image, and d denotes the feature channel – orientation (θ), intensity (I), colour (RG), colour (BY) and scale (σ). The pattern of firing rate rd,i, x, i
(x1, x2) in the image, and d denotes the feature channel – orientation (θ), intensity (I), colour (RG), colour (BY) and scale (σ). The pattern of firing rate rd,i, x, i ![]() {1, . . . N} is named the conspicuity in this model. The pattern of conspicuity at feature d and location x is updated dynamically according to prior knowledge. In the working memory, the target template, as prior knowledge, also uses the population code to represent the features of the required object that is denoted as
{1, . . . N} is named the conspicuity in this model. The pattern of conspicuity at feature d and location x is updated dynamically according to prior knowledge. In the working memory, the target template, as prior knowledge, also uses the population code to represent the features of the required object that is denoted as ![]() , i
, i ![]() {1, . . . N}, and here we do not consider location information. Location information of the object comes from the movement map in the updating process. The target template (features) and location information during the update period as top-down information are embedded in each cell activity, which is like the process in the human brain. Though target detection in the scene is a decision-making issue which involves uncertainty from noise in the sensation, the population code in computational neuroscience can partly overcome the uncertainty and obtain stable results [12].
{1, . . . N}, and here we do not consider location information. Location information of the object comes from the movement map in the updating process. The target template (features) and location information during the update period as top-down information are embedded in each cell activity, which is like the process in the human brain. Though target detection in the scene is a decision-making issue which involves uncertainty from noise in the sensation, the population code in computational neuroscience can partly overcome the uncertainty and obtain stable results [12].
Figure 5.2 Response curves of the cells in a population

5.1.2 Initial Conspicuity Values
In order to determine the initial conspicuity of these cell populations, we first consider bottom-up features computation in the BS model described in Section 3.1, which is calculating basic features such as intensity (pI) and colour opponents (pRG, pBY,), generating Gaussian pyramids with eight scales (q = 0, 2, . . . 7) and computing multiscale centre–surround difference maps pI (q,s), pRG(q,s) and pBY, (q,s) with the centre scales selected as q ![]() {2,3} and surround scales defined as s = q + δ where δ
{2,3} and surround scales defined as s = q + δ where δ ![]() {3,4}. All the above-mentioned steps are the same as those in the BS model as shown in Equations 3.1–3.9 in Chapter 3. For the intensity and colour channels, the contrast map per channel at each centre scale q can be obtained by averaging the maps in different surround scales. However, the detection of local orientation at each point in the image is achieved using over-complete steerable filters [31, 32] with varying resolution (or spatial frequency) (σ) and 20 different orientations (θ). For the contrast map of the orientation channel, the centre–surround difference for each orientation operates respectively and only uses the value with a higher centre than surround input to do the point-by-point subtraction, getting the orientation contrast maps O(q, s). Another difference is that the orientation channel is not averaged across surround scales since the information will be used to determine the spatial frequency features as shown in the following step (4) and Equation 5.3b below.
{3,4}. All the above-mentioned steps are the same as those in the BS model as shown in Equations 3.1–3.9 in Chapter 3. For the intensity and colour channels, the contrast map per channel at each centre scale q can be obtained by averaging the maps in different surround scales. However, the detection of local orientation at each point in the image is achieved using over-complete steerable filters [31, 32] with varying resolution (or spatial frequency) (σ) and 20 different orientations (θ). For the contrast map of the orientation channel, the centre–surround difference for each orientation operates respectively and only uses the value with a higher centre than surround input to do the point-by-point subtraction, getting the orientation contrast maps O(q, s). Another difference is that the orientation channel is not averaged across surround scales since the information will be used to determine the spatial frequency features as shown in the following step (4) and Equation 5.3b below.
The initial conspicuity value, rd,i, x(0), i ![]() {1, . . . N}, of the population at the location x of the feature channel d combines both the scale maps in Gaussian pyramids and the centre–surround maps in the corresponding location of scale maps. If the centre–surround difference maps pI(q, s), po(q, s), pRG(q, s) and pBY(q, s) are available using Equation 3.9 in Chapter 3, the detailed computation of initial conspicuity rd,i, x(0) is shown as follows.
{1, . . . N}, of the population at the location x of the feature channel d combines both the scale maps in Gaussian pyramids and the centre–surround maps in the corresponding location of scale maps. If the centre–surround difference maps pI(q, s), po(q, s), pRG(q, s) and pBY(q, s) are available using Equation 3.9 in Chapter 3, the detailed computation of initial conspicuity rd,i, x(0) is shown as follows.
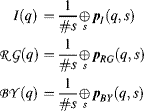
(5.1b) ![]()
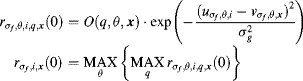
5.1.3 Updating and Transformation of Conspicuity Values
From the previous subsection, the observed data are calculated and finally represented by five initial conspicuity maps. Each initial conspicuity map is coded by the cell population at each location x, and is named a computational unit at location x. These initial conspicuity maps are submitted to level 1 (see Figure 5.1). At level 1, the d channels receive the initial conspicuity maps which have the same size (no. of units) as input, and the updated results at level 1 are transferred to level 2 in which each unit has a larger receptive field than level 1, and the no. of units at level 2 is smaller than that at level 1. Modification of the conspicuity maps is performed in both level 1 and level 2 according to the prior knowledge from feature space (working memory) and from spatial space (eye movement space).
The required target object in feature space is defined by the expected features denoted as ![]() where the cuspate hat represents the expected value. The target template
where the cuspate hat represents the expected value. The target template ![]() is stored in a working memory with the same sets of features for the conspicuity maps, but independent of location x. In the learning stage, a target object with black background appears in the scene and the working memory receives the input from level 2, but only memorizes the most conspicuous feature in each channel to create the required features,
is stored in a working memory with the same sets of features for the conspicuity maps, but independent of location x. In the learning stage, a target object with black background appears in the scene and the working memory receives the input from level 2, but only memorizes the most conspicuous feature in each channel to create the required features, ![]() . The memory units can hold the pattern after the input is removed.
. The memory units can hold the pattern after the input is removed.
To predict the location of the target in physical space, the conspicuity across all d feature channels and all cells in all populations generate an expectation in physical space (from perceptual map to movement map), denoted as ![]() . The location with higher conspicuity
. The location with higher conspicuity ![]() across d feature sets in the perceptual map has higher expectation
across d feature sets in the perceptual map has higher expectation ![]() in the movement map, which returns to levels 1 and 2 as location prior knowledge.
in the movement map, which returns to levels 1 and 2 as location prior knowledge.
The updating equation of conspicuity (firing rate) for each cell at levels 1 and 2 is summarized as follows.

where ![]() is the current firing rate of the cell i at location x of feature d, η is the time step and τ is a constant. The
is the current firing rate of the cell i at location x of feature d, η is the time step and τ is a constant. The ![]() and
and ![]() denote actual observed conspicuity and required feature conspicuity at level 1 and level 2, respectively. Notice that although the symbols
denote actual observed conspicuity and required feature conspicuity at level 1 and level 2, respectively. Notice that although the symbols ![]() and
and ![]() are the same at level 1 and level 2, their sizes (no. of units) and values are totally different. At level 1, there are d channels that receive input from the initial feature conspicuity maps in t = 0 so that their sizes are the same as the initial feature conspicuity maps, and the expected feature conspicuity is the feedback from level 2, so its size is consistent with level 2. The actual observation and expected feature conspicuity are
are the same at level 1 and level 2, their sizes (no. of units) and values are totally different. At level 1, there are d channels that receive input from the initial feature conspicuity maps in t = 0 so that their sizes are the same as the initial feature conspicuity maps, and the expected feature conspicuity is the feedback from level 2, so its size is consistent with level 2. The actual observation and expected feature conspicuity are
where the number 1 in brackets in the superscript represents the observed value at level 1 from the conspicuity map d, and ![]() is the feedback from level 2, at location x, which is regarded as the required feature at level 1. The subscript x′ is the location at level 1 and x is the location at level 2, x′
is the feedback from level 2, at location x, which is regarded as the required feature at level 1. The subscript x′ is the location at level 1 and x is the location at level 2, x′ ![]() RF(x) (RF(x) is the receptive field of location x).
RF(x) (RF(x) is the receptive field of location x).
At level 2, the actual observation is the projection from level 1, but only within the same feature channel d. The sizes in levels 1 and 2 are different, the conspicuity of features at several locations in level 1 converges to one location in level 2 by taking the maximum value from the receptive field of the unit at level 2, and the expected conspicuity of features is the required target feature that comes from working memory, and so we have
where the number 2 in brackets in the superscript represents the conspicuity of all features at level 2, and the symbol ∝ denotes that the left term and the right term are in proportion.
The expected locations ![]() in both level 1 and level 2 come from the eye movement map, but in different resolutions:
in both level 1 and level 2 come from the eye movement map, but in different resolutions:
where ![]() and
and ![]() are the locations at x and x′ in the eye movement map with coarse and fine resolutions, respectively, and α is a constant. Equations 5.5–5.7 give the detailed explanations about the symbols in Equation 5.4 for level 1 and level 2. Let us now turn back to Equation 5.4 which covers the conspicuity update for both level 1 and level 2.
are the locations at x and x′ in the eye movement map with coarse and fine resolutions, respectively, and α is a constant. Equations 5.5–5.7 give the detailed explanations about the symbols in Equation 5.4 for level 1 and level 2. Let us now turn back to Equation 5.4 which covers the conspicuity update for both level 1 and level 2.
The first term A(·) in the second row of Equation 5.4 is an activation function that measures the match of the actual observed value ![]() with the required feature value
with the required feature value ![]() and the expected location
and the expected location ![]() respectively. If the expected feature matches the actual observation well, the activation term increases. Analogous to the inference of required feature, at the site with a similarity between the expected location (region) and the observed location (region), the conspicuities of all features in the location or region are enhanced. The second term H(·) in the second row of Equation 5.4 induces competition and normalizations of the activity of cells. The iterated results in levels 1 and 2 at each time step are transferred to the perceptual map (saliency map). The perceptual map indicates the salient regions by integrating the conspicuity of levels 1 and 2 across all channels, and then it is projected onto the movement map to form a few candidate regions which will be used as new location prior knowledge (the expected location (region)) in the next iteration of Equation 5.4 for level 1 and 2 units. This is a dynamically iterated course among the level 1, level 2, perceptual map and movement map. The flowcharts for level 1, level 2, perceptual map and movement map are shown in Figure 5.1. In addition, the match detection block shown on the right of Figure 5.1 is to compare the activity pattern at level 2 with the target template in working memory in order to determine if the activity pattern fits the target object. When the match detection indicates no match, eye movement occurs by a control unit shown in Figure 5.1. As similarity with the saliency map mentioned in these pure bottom-up attention models, an inhibition of return is considered in the perceptual map in order to avoid revisiting the same attention focus.
respectively. If the expected feature matches the actual observation well, the activation term increases. Analogous to the inference of required feature, at the site with a similarity between the expected location (region) and the observed location (region), the conspicuities of all features in the location or region are enhanced. The second term H(·) in the second row of Equation 5.4 induces competition and normalizations of the activity of cells. The iterated results in levels 1 and 2 at each time step are transferred to the perceptual map (saliency map). The perceptual map indicates the salient regions by integrating the conspicuity of levels 1 and 2 across all channels, and then it is projected onto the movement map to form a few candidate regions which will be used as new location prior knowledge (the expected location (region)) in the next iteration of Equation 5.4 for level 1 and 2 units. This is a dynamically iterated course among the level 1, level 2, perceptual map and movement map. The flowcharts for level 1, level 2, perceptual map and movement map are shown in Figure 5.1. In addition, the match detection block shown on the right of Figure 5.1 is to compare the activity pattern at level 2 with the target template in working memory in order to determine if the activity pattern fits the target object. When the match detection indicates no match, eye movement occurs by a control unit shown in Figure 5.1. As similarity with the saliency map mentioned in these pure bottom-up attention models, an inhibition of return is considered in the perceptual map in order to avoid revisiting the same attention focus.
In Equation 5.4, the terms A(·) and H(·) have very detailed representations in [12] and all perceptual map, movement map, match detection and inhibition of return also have been formularized in [12], so we will not go into more detail here because of space limitations. Readers interested in the model can refer to reference [12].
When input image and target template are available, the population-based attention model mainly operates in the following four steps: (1) calculate the five initial conspicuity maps from the input image by means of Equations 5.1–5.3; (2) transfer the conspicuity maps to level 1 and project level 1 to level 2, then obtain the initial perceptual map and movement map from level 1 to level 2; (3) insert the target template information (required feature) from working memory and update level 1 to level 2 under prior knowledge of both feature and location by the aid of Equation 5.4–5.7; (4) check the match result between level 2 and the target template stored in working memory by using match detection and then control the eye movement if the match fails until the required target is found. In this model visual attention emerges as part of the process of planning an eye movement, so the covert search (without executing any eye movement) can emerge from an overt search while the model is planned but has not carried out the eye shift.
In summary, the population-based attention model integrates the information of both top-down and bottom-up based on the level of cell populations, and then processes the information by means of updating these distributed conspicuities, which is biologically plausible. Some biological evidences related to the computational model can be found in several papers [11, 28, 33, 34] by the same author as [12]. Moreover, some tests in both psychological patterns and natural maps have proven the validity of the population-based attention model, which further demonstrated that the neurobiological principle in [11, 28] holds for object detection [12].