
2.2 Feature Integration Theory (FIT) of Visual Attention
As introduced in Section 2.1, input stimuli projected on the retina are processed through the LGN, primary cortex V1, V2 until the high cortex in the HVS. The RFs of some neurons in the LGN are the centre-surround homocentric circle that extracts objects edges on their RFs, while other cells with colour-opponent RFs in the LGN extract colour features. In the V1 area there are simple cells with different orientation-selective and colour-antagonistic RF to select respective features of input stimuli. Some simple cells in V1 have frequency sensitivity. The neurons at higher layer have larger RF size which can obtain more complex features or a large number of features. Detective cells for motion direction in the LGN and V1 can perceive movement of objects. Since these neurons in the early cortex work simultaneously, we know that the perception of these features in the input scene is done in parallel. Then perceptive information is further processed through the dorsal and ventral streams in different brain areas. However, how to search an object with several different features in the intricate visual input and how to bind the separate features dispersed in diverse cortical regions together to a specific object in the human vision, are not clear only from the viewpoint of either physiology or anatomy.
Many psychologists and experts on neuroscience have engaged in the feature binding problem for more than three decades [29–34]. The most influential theory among these studies is the feature integration theory (FIT) proposed by Treisman and Gelade [30] and by Treisman [29, 34, 35]. The theory suggests that these separate features are integrated for visual attention. Without focus of attention, humans cannot correctly locate the object with many features in complex circumstances. The theory has been confirmed by numerous psychological findings reported in the articles of Treisman and Gelade [30] and studies on neurological patients [34]. Although the idea has been disputed in the recent years and several new suggestions have been proposed [32, 33], this theory is still unanimously the foundation of stimulus binding and visual attention. The rest of this section mainly introduces the theory and its extended works.
2.2.1 Feature Integration Hypothesis
The FIT deals with the first two stages of three stages in visual attention that we have discussed in Sections 1.4.1 and 2.1.3, that is, (1) pre-attention (or feature registration) stage; (2) attention (or feature integration). In the feature registration stage, humans do not need to exert any effort to get the information from their environments. The HVS can extract features from input light stimuli via early cortex cells. This is an automatic process that occurs in parallel. The early visual stage can only detect the independent features such as colour, size, orientation, motion direction, contrast and so on. Under the feature integration hypothesis, these features may stay in a free-floating state, that is their existence is possibly apperceived, but their locations and relations with objects are unknown. Thereby, they do not specify ‘what’ and ‘where’ for an object in the scene and they also cannot decide the relationship between the features and the particular object.
In the second stage (feature integration), perception in the HVS combines the separable features of an object by the stimulus locations. The features, which occur in the same attention fixation, form a single object. Thus, focal attention acts as mucilage by binding the original and mutually independent features together in order to define an object during the perception process in the HVS [30]. This process needs effort, and works in series, so its operation is slower than that in the first stage. The theory suggests that, without focused attention, features cannot be related to each other.
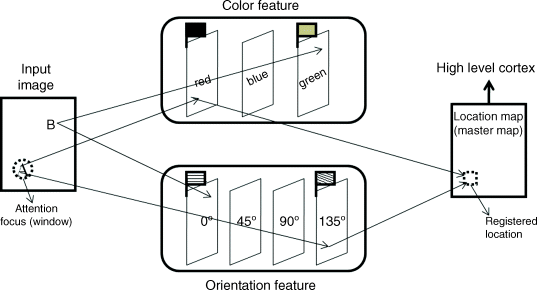
Treisman [34] proposed a conceptual model which includes a location map representing the objects' locations and a set of independent feature maps for colour, orientation, luminance, depth and motion. The location map (master map) is used for registering the positions where objects appear. The set of feature maps is obtained by different simple or complex cells working in parallel. In feature maps there are two kinds of information: one is the flag information and the other is some implicit spatial information. The flag information represents whether the feature appears anywhere in the visual field or not. If the feature exists, the flag sets up on the feature map, otherwise not. If a task can be finished in a single feature map by checking the flag, it does not need attention to glue several features on the focal region, so the target search in the visual field can be implemented in the feature map, which is very fast. However, if the task is related to more than one feature, the attention focus (window) shifts and selects the features in different feature maps located in the current attention window, and the process ignores other features outside the attention window. These features in the attention window are a temporary object representation. In this way, the feature maps and the master map are connected. The features and the location (‘where’) of an attended object at a given time are bound together by the conceptual model. After that, the information of an object is sent to the high cortex for further analysis, processing and recognition. Figure 2.3 shows the conceptual model of the FIT with a set of colour and orientation features in order to explain how the visual attention can glue different features and locate the object's position. In Figure 2.3, there are two objects (A and B) in the input image, and A is a red object with oblique (135°) stripe and B is a green object with a horizontal stripe. The flag information of feature maps for red and green, horizontal and oblique (135°) orientations are set up as shown in Figure 2.3, where different flags represent different features. This means that these features exist in the input visual field. In fact, only the features of red and oblique (135°) orientation, which are related to the object A in current attention region, can be registered on the master map and sent to the high cortex for further processing, because the attention focus is at the location at this moment. These objects on the outside of the attention window at the time are omitted (like object B). The attention focus maybe shifts from one to another, and the object B will be searched in another temporal time. This operation is serial. Just because of visual attention, the independent red and oblique orientation features can be glued, and the information of location on the master map with the glued features can be sent to the high level cortex. We will explain this model in the rest of this section with relevant experiments available.
Figure 2.3 Conceptual model of the FIT
2.2.2 Confirmation by Visual Search Experiments
A large number of different visual patterns (paradigms) as stimulus cards were designed, and then tested with observers for explaining and validating the feature integration hypothesis. The typical and quantificational experiments were proposed by Treisman's group [29, 30]. In their experiments, each of these artificial patterns (stimulus cards) contained a target among the several distractors. Subjects were asked to search for the targets when they viewed the display of different patterns. The reaction time (RT) was recorded with a digital timer. If the target search was in parallel, the RT of subjects would be short and not influenced by the varying number of distractors in these cards. Contrarily, a serial search needs to check more items or more shift attention windows in the stimulus card so the search would become slow, and RT would increase with the increasing number of distractor items (size of the distractors).
There are two types of serial search [36, 37]. The first one is the exhaustive search. In this search, all of the items are examined before an answer is decided. The other type of serial search is the self-terminating search. In this type of process, the search terminates as soon as a target is found by the subjects. It is obvious that the RT with self-terminating search is faster than the exhaustive search.
In the article of Treisman and Gelade [30], the perceptual subsystem (e.g., subsystem: colour or orientation), was defined as a perceptual dimension. The features were denoted as a particular value on a perceptual dimension. Red, blue and green were the features on the colour perceptual dimension, and the features on different orientations were defined on the orientation perceptual dimension. The target detection task is difficult when the target is specified as a conjunction of the features in different perceptual dimensions.
In the following subsections, five types of experiments in different visual patterns, each of which can partly confirm the FIT, are introduced with both easy and difficult target search conditions. Some quantitative results of experiments described in [30] are presented to substantiate the theory in order to enhance the reader's understanding of the related issues. It will be noticed that Figures 2.4–2.8 are not from the paradigms in [30], and they used here only for convenience of explanation.
2.2.2.1 Target Search with Features and Conjunctional Conditions
Intuitively, if the target and distractors are in the same perceptual dimension and the target is specified by a single feature, for example a red bar (target) among many green bars (distractors) or one orientation bar (target) among many other orientation bars (distractors), the subject will detect the target very fast with an automatic self-terminating search. Figures 2.4(a) and (b) depict the two single-feature target cases. Here, black and white bars represent red and green bars, respectively.
Figure 2.4 Intuitive stimulus paradigms: (a) colour dimension; (b) orientation dimension; (c) conjunction of the features on two dimensions. (Here black and white bars represent red and green bars, respectively)

If the target is specified by a conjunction of the features in two different dimensions (a target with red 45° bar in the distractors with half red-135° bars and half green-45° bars) as in Figure 2.4(c), the search time (RT) will become very slow.
When the number of distractor items increases in the display for a single feature and conjunctional features, respectively, it is found that the target with a single feature is still detected fast, but contrarily, more time needs to be spent for finding the target with a conjunctional condition. In Figures 2.5(a) and (b), there are more distractor items than Figures 2.4(a) and (b) under a single feature condition, but the targets can be still detected easily. However, for a conjunctional case as in Figure 2.5(c), search for the target is more difficult to accomplish, compared with Figure 2.4(c). This phenomenon can be explained from the model of Figure 2.3. When Figure 2.4(a) appears in the visual field, the red and green flags simultaneously rise on red and green feature maps respectively. The unique item on the red map is for the target. Therefore, when the number of green distractor items increases in Figure 2.5(a), the target item on the red map is still unique, so the search time does not change. The same result can be seen for Figures 2.4(b) and 2.5(b). For the target with conjunction of two features shown in Figures 2.4(c) and 2.5(c), the feature maps for 45° orientation, 135° orientation, green and red are active at the same time, and there is no unique spot or item on any one of feature maps. The human vision has to use the attention mechanism to search the location of the target, which works in series on the location map.
Figure 2.5 Increase the number of distractor items in single and conjunctional cases. (Here black and white bars represent red and green bars, respectively)

In addition to the intuitive examples illustrated above, many quantitative experiments have also attested to the difference between single feature and conjunctional features. Early experiments reported by Treisman et al. [38] in 1977 compared the RT of subjects for targets specified by a single feature (a ‘pink’ (colour) target among ‘brown’ distractors, and a letter ‘O’ (shape) among letters ‘N’), and for targets specified by a conjunction of features (a pink ‘O’ among distractors of half green ‘O’ and half pink ‘N’). The function relating RT to display size of the distractors (number of distractor items) is near flat; that is, RT is unchanged with varying sizes of the distractors, when a single feature is sufficient to define the target. However, the relation of RT vs. display size is a linearly ascending function when a target with conjunction of features is to be detected. In 1980, the psychometric experiment of six subjects for different conditions (a total of 1664 trials) proposed by Treisman and Gelade reported the same results [30]. The average RT for the targets with a single feature is stable while displaying size changes. The average RT almost linearly increases with display size of distractors (1, 5, 15, 30) in any conjunctional conditions [30].
All the intuitive and quantitative tests reveal that the targets of conjunctional features need to find the location of the input visual field then to integrate more than one feature together at the location. The focal attention can scan successively the locations (in Figure 2.3) serially, and therefore correctly integrate these features into multidimensional perception.
In fact, it was later found that if the conjunction of features is in the same perceptual dimension as in Figures 1.4(c) and (d), the search time also increases with the display size of the distractors increases.
2.2.2.2 Positive and Negative Searches
Search for a target in the input stimuli has two cases: positive search and negative search. A positive search means that the observer is asked to find a target within the scene, while in a negative search, the observer tries to confirm that a target is not in the scene. Sometimes, positive and negative searches are called target-present and target-absent search, respectively. In Figures 2.6(a) and (b), an intuitive example is given to demonstrate that a negative search needs more RT for subjects than a positive search among the same distractors.
Figure 2.6 Positive and negative searches: (a) affirm a target (45° green bar); (b) negate the target (absent 45° green bar) (Here black and white bars represent red and green bars, respectively)

In a positive search for a target with a single feature, the RT does not change with the number of distractor items, but for a negative search, a near linear variation exists when the number of distractor items increases. The difference between positive and negative targets exists in both single feature and conjunctional feature cases. It is suggested by [30] that, with a negative search, subjects tend to scan all the items in the display to check whether the target exists. That is, the negative search does the exhaustive search while a positive one is a self-terminating search. Consequently, a negative search needs more time. For a conjunctional negative search, many data in [30, 39] confirm that the slope of the linearly ascending function of RT vs. display size is doubled, that is a 2 : 1 slope ratio for a negative search over a positive one for conjunctional conditions. This implies that the RT of a self-terminating search on the average is a half of that for the exhaustive search in conjunctional conditions. For single feature cases, a negative search still needs to perform an exhaustive search, so the report in the experiments of Treisman's group showed that the ratios for negative and positive searches in single feature conditions are greater than 2 : 1.Target search for conjunctional negative cases with the large-size distractors is the most difficult. The results of RT for a negative search in a single feature condition and a positive search in a conjunctional condition are very close. The fastest search is a positive one in a single feature condition, since the associated process is performed in parallel.
Another interesting phenomenon is that, in general, targets with an added feature are easier to detect than the targets with a missing feature. Figure 2.7 gives intuitive patterns for both added and missing feature cases. It is easy to detect the target in Figure 2.7(a) but difficult to find the target in Figure 2.7(b). This example does not seem to be similar to Figure 2.6. However, it can be explained, in intuitional perceptivity, by the feature integration model in Figure 2.3. With the pattern of an added feature, the vertical and horizontal feature maps automatically set up flags in the model of Figure 2.3. The unique horizontal line segment is just for the target so in the first stage of feature extraction, the human vision can find it easily. For the missing feature pattern, although the flags rise on both vertical and horizontal feature maps, there are many line segments on the two feature maps. Obviously, the human has to search the conjunctional items to negate horizontal features in order to find the target with no conjunctional feature. Figure 2.7 is sometimes called search asymmetry [40].
Figure 2.7 Targets with (a) an added feature pattern and (b) a missing feature pattern

2.2.2.3 Alphabet Search and Search Difficulty
An alphabet often consists of several features. While searching for a letter among other letters, the subject needs to analyse the letter in separate features, and then these features should be integrated into a letter by focused attention. This is a controversial issue since people often feel that they can detect the highly familiar letter in parallel. If the FIT is tenable, then conjunction of features in different letters will take more time to be detected. To be able to compare conjunction with other difficult search conditions, two cases for letter detection were designed in [30]. In one case, a letter would be difficult to search for when distractors and the target are similar, and in the other case, search difficulty is in the heterogeneity of distractors [41, 42]. The two cases may need successive scans with the fovea on the retina to observe these items of display in detail.
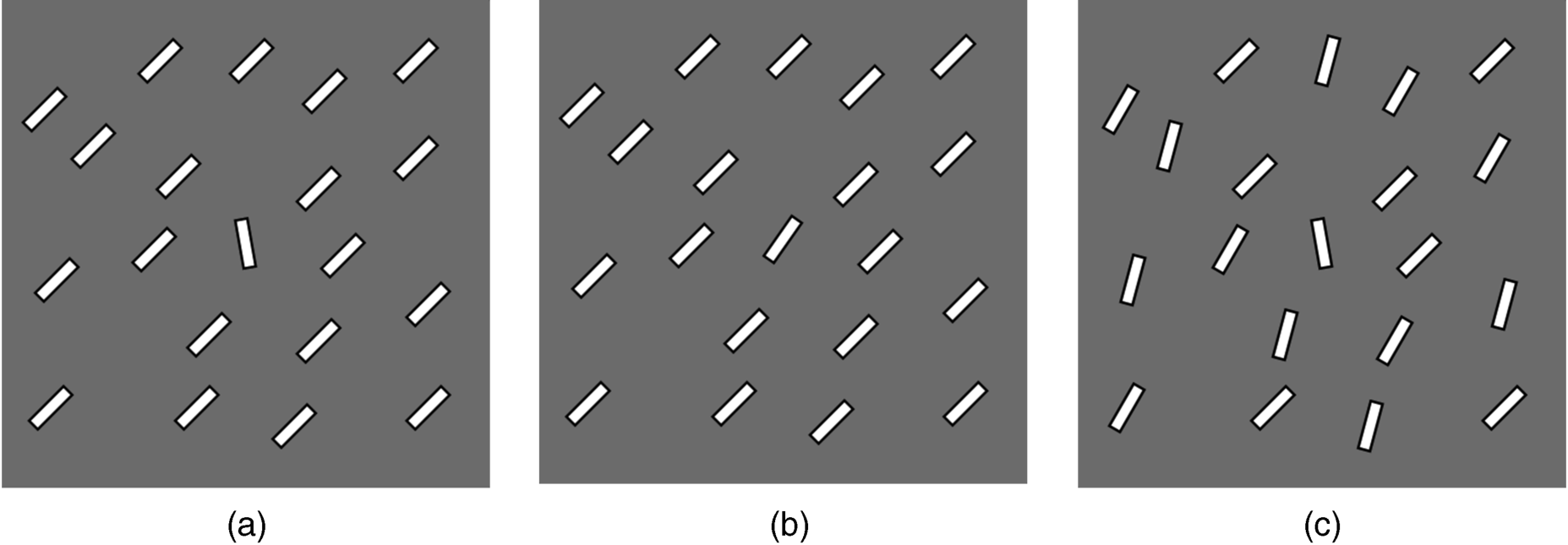
In order to illuminate the abovementioned cases in a simple way, Figures 2.8(b) and (c) show the two conditions with orientation bars (no letters used). In Figure 2.8(a), the target is readily distinguishable from its circumambient distractors so it is easy to detect. In Figure 2.8(b), the orientation of the target bar is very similar to the orientation of distractors, and this results in confusion in the search task. If the orientation difference between the target and distractors is too small, a search process may make mistakes. Furthermore, for Figure 2.8(c), the heterogeneity of distractors may disturb the target which causes search difficulty or false detection. A further reason for search difficulty in Figure 2.8 will be explained later in this chapter (Sections 2.3 and 2.6).
Figure 2.8 The target (a) with distinctive orientation in homogenous distractors, (b) in similar distractors and (c) in heterogeneous distractors
Let us consider the cases of alphabet search designed by Treisman and Gelade [30] for searching a target letter with conjunction of features, a target with similar features to distractors and a target in heterogeneous distractors. Two patterns in conjunction condition were defined as follows. (1) A target letter ‘R’ among the distractor letters ‘P’ and ‘Q’ was a conjunction of two separate features, where ‘diagonal’ segment on the tail of ‘Q’ and the feature of letter ‘P’ composed letter ‘R’. The case was denoted as R/PQ. (2) A target letter ‘T’ among the distractor letters ‘Z’ and ‘I’ was the conjunction of a separate feature ‘I’ and transverse line segment of letter ‘Z’, expressed as T/IZ. Two patterns searching for a target with similar features to the distractors were defined in cases (3) and (4). (3) The distractors ‘Q’ in pattern (1) was replaced by the letter ‘B’ that was more confusable with the target ‘R’ but could not combine with the other distractor ‘P’, denoted as R/PB (this was a case where the upper parts of all distractor letters were the same as the target letter ‘R’). (4) It is the same to the similarity control for (2): the letter ‘Y’ was substituted for the letter ‘Z’ in the distractors, denoted as T/IY (feature ‘I’ being in both target and distractors). A pattern for heterogeneity control of distractors is designed for (5) that the letter ‘T’ in the letters ‘P’ and ‘Q’ with heterogeneous arrangement, denoted as T/PQ.
In order to check the different cases mentioned above, in the experiment of Treisman and Gelade [30], six subjects (male) took part in the target searching with the conditions of conjunction, similarity and heterogeneity. All the displays were presented until the subjects made their responses. Average linear regression of RT vs. display size (number of distractor items: 1, 5, 15, 30) in the experiment was computed.
The prediction was that if the FIT hypothesis was tenable, the search for a target with conjunction of features (R/PQ and T/IZ) should take a longer time, because in that condition, the target shared one feature with each distractor (e.g., target letter ‘R’ included ‘diagonal’ line segment of distractor ‘Q’, and a vertical line segment and hole of the upper part in distractor ‘P’). Since there was no unique item in any one feature map, the subject had to use the attention mechanism to search the target in series. For the case of searching a target with similar features to distractors and in heterogeneity control of distractors, the unique feature for the target could be found on a feature map; for instance, the ‘diagonal’ line segment of target letter ‘R’ in R/PB and the transverse line at the top of letter ‘T’ for T/IY and T/PQ are unique.
The results of average linear regression of RT vs. display size in the experiment showed that the slopes in the conjunction cases (1) and (2) (T/IZ and R/PQ) were the highest (12.2 for T/IZ and 27.2 for R/PQ). Although the slope of linear regression in similarity cases (3) and (4) (T/IY and R/PB) and heterogeneity case (5) (T/PQ) were not complete flat, they showed a much lower slope than cases (1) and (2) (5.3 for T/IY, 9.7 for R/PB and 4.9 for T/PQ). Consequently, the letter search in conjunction conditions would be serial and self-terminating because the average RT increased with increase of display size.
These interesting experiments validate the FIT hypothesis concerning the role of focal attention, not only with the patterns of colours and shapes (as presented in subsection 2.2.2.1), but also with letters which are highly familiar to human subjects.
2.2.2.4 Relation of Spatial Localization and Identification of Target
The feature integration model indicates that the perceptual task has two levels. In the feature level, the features of the visual field are extracted in parallel, and in the feature integration level, subjects must locate target positions with the aid of focal attention for searching the objects with conjunction features. What is the relation between identification and spatial localization of a target that subjects apperceive? The following experiments in [30] further explain the feature integration hypothesis.
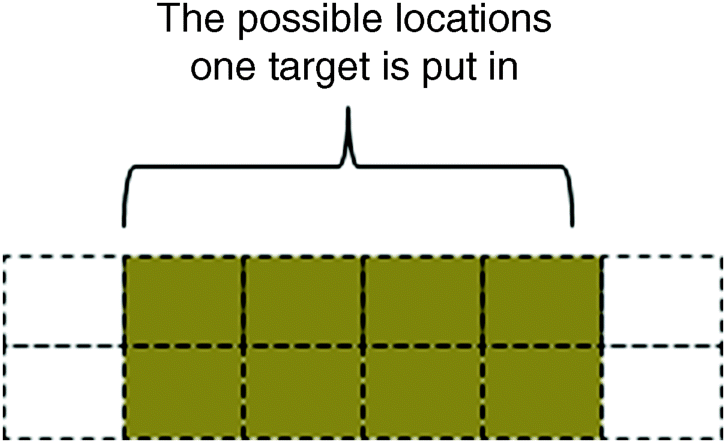
The stimuli for the experiments consisted of two rows of coloured letters which were evenly arranged in a rectangular array, with six letters on each row. Each display had one target item that was randomly placed in any of eight central positions (the two positions at the ends of each row are not considered) as shown in Figure 2.9.
Figure 2.9 Rectangular array testing location and identity of the target
The distractors, pink ‘O’ and blue ‘X’ with nearly equal numbers, were randomly distributed within the positions in Figure 2.9. Two kinds of patterns existed in the experiments: one was a single feature condition where the possible targets were ‘H’ (in pink or blue) and the colour orange in the shapes of an ‘X’ or ‘O’; the other was a conjunction condition where the possible targets were pink ‘X’ or blue ‘O’. For both conditions, only one possible target is set in the possible (4 × 2) positions among the distractors pink ‘O's and blur ‘X's. There were 64 different arrays per condition. Six male subjects were selected and asked to recognize both the target and its location. There may be four results: One result is correct recognition of both the target and its location; another result is correct identification of the target but with false position, or true position with false target identification; the final result is false recognition of both target and position. The middle two results would be of interest because they concern the conditional probability of correct target recognition given the wrong location, and the conditional probability of the correct location given the wrong target identity.
Two similar experiments were designed in [30] to test the relation of identification and spatial localization of a target. In experiment 1, the presentation time of displays was chosen so that the target identification accuracy was about 80% for all experimental conditions. It is worth noting that keeping above 80% recognition rate for identity means that the search time is different for each subject in each trial under single feature and conjunction conditions respectively. There may be three kinds of location reports: correct location, adjacent location error (displaced by one place horizontally or vertically from the correct position) and distant location error (all other location errors). Experiment 2 used the same presentation time for both single feature and conjunction cases, but it had to ensure that the performance was above chance in the conjunction condition and that there was sufficient error in the single feature conditions, that means, for different subjects and different pattern pairs (single feature and conjunction cases) the presentation time was perhaps different.
First, the feature integration hypothesis of serial search for conjunctions and parallel search for single features was supported again, because, in experiment 1, the average identification time was 414 ms for the conjunction cases and 65 ms for the single feature cases while keeping correct identification rate at about 80%. Second, for the conjunction condition, higher conditional probability of correct target recognition was in correct location responses (93% in experiment 1 and 84% in experiment 2), and low probability (close to 50%) in the wrong location responses (distant location error) (50% in experiment 1 and 45.3% in experiment 2). That is, when the subjects failed to locate the target, correct identification was just based on guesses. Consequently, it confirmed that targets under conjunction conditions could not be identified without focal attention [30]. Third, the probability of the target being identified correctly at adjacent location error in conjunction conditions was higher than that of chance (72.3% and 58.3% for experiments 1 and 2 respectively). The article [30] suggested that ‘Focused attention is necessary for accurate identification of conjunctions, but it may not be necessary on all trials to narrow the focus down to a single item.' Fourth, in the single feature conditions, the detection rate of all targets was higher than 0.5; even when the detection of the target's location was false the target was still able to be identified. In the single feature experiments, around 40% of trials were with correct target recognition but location misjudgement, so the identification of the target with a single feature does not need focal attention and the location information of the targets.
The results of experiments mentioned above further attest the prediction of FIT. If the subject correctly identifies a conjunction target, he must have located it, so higher dependence between identification and spatial localization of a target for the conjunction case can be obtained. For the single feature case, he identifies a target without necessarily knowing where the target is located.
2.2.2.5 Illusory Conjunction
In the experiments of the previous subsection all subjects had enough time to make decisions while various patterns were displayed. Other experiments from [30] were held under different conditions as the display time for these subjects was very short. Therefore, they might have no time to conjunct the extracted features to an object (still at the pre-attention stage), since they do not know the location of the object before focal attention. If FIT was valid, these free floating features without attention would be combined wrongly and result in illusory conjunctions. Treisman gave some evidences from psychogenic experiments to validate the feature integration hypothesis in [34], and Treisman with Schmidt in [43], to be described next. In addition, some tests from a patient with parietal lesions (with less attention ability) further confirmed the illusory conjunction [34, 44].
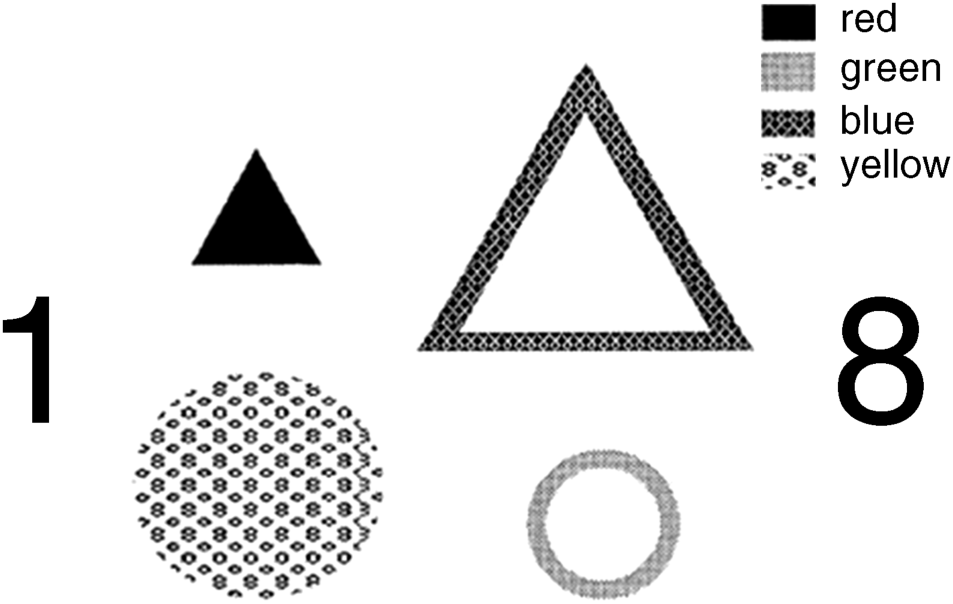
Figure 2.10 gives one experiment of [34] in which four shapes varying in colour, size, shape and format (filled or outlined) were arranged in a square area that was flanked by two small digits (1 and 8). Subjects were tested with the displays and asked to note the digits first and, in addition, to report all the features they could in one of the four locations cued by a marker, all within 200 ms. Many conjunctional errors referred to as illusory conjunctions happened in their reports. The wrong combinations of different features (shapes, size, colour and format) were reported in error, the error rate being above 12%, more than the error resulting from noise intrusion. The experimental setup in Figure 2.10 is just one example among several experiments dealt with in [30, 34]. The same results for the illusory conjunction phenomena can be found from other similar studies in the literature, and the relevant theory has been discussed in various works such as [45–49].
Figure 2.10 A display illustration for the subjects who were asked to identify two digits first, then to report the features in cued location by the bar marked [34]. Reproduced from A. Treisman, ‘Feature binding, attention and object perception,’ Philosophical Transactions B, 353, no. 1373, 1297, 1998, by permission of the Royal Society.
Other evidence was from a patient (named RM) whose parietal lobe was damaged. It had been shown that parietal lobes were certainly involved in spatial attention, as reported in [44, 50]. Experimental results have shown that target detection is not difficult when the subject is tested by simple displays with single feature conditions such as a red ‘X' in red ‘O's (shape dimension) or in blue ‘X's (colour dimension). Nevertheless, in the conjunctional task of detecting a red ‘X' among red ‘O's and blue ‘X's, the subject made 25% mistakes. When the displays were small in size with few distractors (3–5 items) or the subject was allowed to have longer detection period, the mistakes were still observed for the conjunctional task. These experimental findings were consistent with the FIT because attention uses spatial location to bind floating features to an object. The individual patient lost the ability of localization, so he had to guess the target location, which caused errors for the given task. There are many experiments for patient RM in [34, 44, 50], and we will not describe them all here.
In summary, the FIT states that a search task has two stages: a parallel stage in which all features in the visual field are registered in respective feature maps, and then a serial stage controlled by visual selective attention that binds the features to an object at the location of attention focus. Many psychological experiments, including target searches in conjunction and single feature conditions, positive and negative searches, letter searches and so on, reveal that the RT of subjects with respect to the display size (the number of displayed items) was linearly ascending in serial and self-terminating search. The slope ratio of the linear function (RT vs. number of distractors) between target-absent (negative) and target-present (positive) cases was 2 : 1 for conjunction cases. Other experimental results coming from trials such as search conditional probability and illusory conjunction (including the test of a patient with damaged parietal lobe) have reported that correct search cannot be completed with complicated stimuli without the attention mechanism except for single feature cases. Since searching for a target in single feature cases, the unique feature on a target can pop out in the pre-attention stage as mentioned in subsections 2.2.2.1–2.2.2.4.
The results of these psychological experiments have been repeated in a number of articles [51–54] which verify the rationality of the feature integration hypothesis. For this reason, the FIT has played an important role on psychological visual attention for more than 30 years. Although the idea has been disputed and therefore different kinds of alternative attention theory and models have been proposed, the FIT has certainly been very dominant in the field of visual attention until today.