
9.2 Further Discussions
It is known that saliency map models are based on biological hypotheses about visual search such as FIT and GS theories. With the development of psychophysics, psychology and neuroscience, some existing biological hypotheses and conclusions face challenges. A review paper [8] in 2006, based on the experiments and ideas of many experts from various aspects of visual search, listed four controversial issues to discuss the theories: the role of bottom-up and top-down mechanism, the role of memory mechanism, the implementation of these mechanism in the brain and the simulation of visual search in neuronal computational models. Although the discussion is in the pure biological area, it still influences the development of computational models of visual attention. Since computational models introduced here are closely related to biological facts, each progress in biology will lead to change and improvement of the computational models. Besides, many unclear issues in visual information processing of the high-level cortex often have impact in the engineering area. This section collects nine controversial issues related to the content in this book, in the intersection area of biological and engineering, and we hope that these can stimulate further discussions and also serve as the reference and starting point in future development of new saliency map models.
9.2.1 Interaction between Top-down Control and Bottom-up Processing in Visual Search
It is known from FIT that visual search in the input scene is fast (i.e., RT is short) for a target with a single feature and is slow for a target with feature conjunction. The target search for a single feature is in parallel, while in the conjunctive condition the search may be serial. In GS1, the information from the parallel process can be used in the serial process, which speeds up the RT of conjunctive condition. In some cases, the RT of conjunctive search approaches that of parallel search. In the GS2 search system the explicit top-down weighted maps are added to the feature maps, and both bottom-up and top-down mechanisms simultaneously act on the early visual search. Of course, the advanced definition of top-down knowledge for the target (feature) will speed up the RT of search. However, whether and to what extent does the top-down mechanism modulate the visual search in the pre-attentive stage? It is not clear so far.
There are two different points of view in visual cognition: one is that top-down modulation exists in not only the attention or post-attention stages, but also the early visual search, because dimensional weighting operations may lead to more efficient search [8–10]; the other point of view is that efficient search in the pre-attentive stage is influenced by bottom-up priming effects [11, 12].
The priming effect was discovered by [13]: if the target has the same features or appears in the same location as on the previous display, the target search is faster than others. For example, a target with conjunctive features (e.g., red and vertical bars) among many distractors (green vertical and red horizontal bars) is searched in the current trial, the primed feature (red and vertical) or location associated with the target will be rapidly found in the next trial, if the target has the same features or appears in the same position. Another form of priming, called negative priming, proposed in [14] aims at distractors. These features or positions of the distractors appear in current display often are disregarded in the next display. Priming is to enhance the saliency of the target, and negative priming is to suppress the distractors in the next trial. Thus, the visual search is fast with priming effect, even if for the target with conjunctive features [12]. Priming is different from top-down processing, because it does not require prior knowledge and learning, and it operates automatically. The later study in [15–17] indicates that the priming effect may contain inner memory, because the feature or location of the target in the current trial is memorized for the next trial. The priming effect should be considered in the bottom-up mechanism.
Although there is the aforementioned dispute over the pre-attention stage, researchers believe that top-down attention is subsistent when people complete a task or find the target in all information processing stages of the HVS. But how does the top-down knowledge modulate bottom-up processing in the brain and how are these two different processing mechanisms balanced? To what extent does the top-down mechanism modulate the visual search in different information processing stages or for different visual cortex areas? The answers to these issues are still ambiguous.
In the computational models with top-down guidance mentioned in this book, several modulation methods have been used in the computational models: (1) Top-down knowledge comes from manual intervention, for instance, the hierarchical object search model (Section 5.2) makes use of human instructions to decide whether the search needs to continue at the salient focus in higher resolution or shift the focus to the next salient point in the recently used resolution. (2) The top-down cues from learning results bias to a few feature maps of bottom-up processing so that they influence the salient focus (the VOCUS model in Section 5.5, and the model with decision tree in Section 5.3). (3) Top-down attention as a representation of cell population in each feature dimension dynamically modulates the cell in the corresponding population of bottom-up (the population-based model in Section 5.1). However, the interaction between top-down and bottom-up mechanisms may not be so simple as these models suggest. How do different processing modes interact in the brain? This needs more careful research.
Due to the complex nature of interaction between top-down and bottom-up mechanisms, as well as priming effect in bottom-up processing in the brain, the performance measurement and benchmarking of computational models face challenges, especially for bottom-up computational models. Most evaluating criteria are based on the comparison between computational results and eye movements of several observers in natural image databases. The observers' eye movements as the benchmarks for bottom-up models may not be right, because human perception is often a result of both bottom-up and top-down mechanisms in the brain, and different observers have different top-down knowledge. The attention focuses of eye movement are the results of multiple mechanisms.
9.2.2 How to Deploy Visual Attention in the Brain?
In the early phase of FIT development, Treisman and her colleague (Gelade) assumed that attention can be focused narrowly on a single object [1]. In her recent research [18], different kinds of visual attention with multiple object focuses have been suggested according to what observers see. One kind of visual attention is called distributed attention that occurs based on the statistics of sets of similar objects in the visual field or the possessive ratio of different kinds of objects in a scene, and the other is that the gist and meaning of the input scene is first apperceived. These two attention modes are automatic and they operate in parallel when we observe the world with widely different objects or a lot of similar objects. For instance, it is hard to focus a special element from a scene of a parking lot including many cars while glancing at the scene in hurry. Whereas, it can be easy to perceive the proportions of colour feature (e.g., black cars are in the majority). The statistical processing in distributed attention should be restricted to features (the mean of colour or size), rather than for individuated objects. Another perception, while treating the richer world, is the gist extracted from the scene, because observers can capture the meaning of scene with short-time glances. Thus, which kind of attention is deployed to high level cortex determines what we see. Although humans can easily choose different aforementioned attention modes, it is still tough for the computational models to achieve this. Whether there is a criterion we can use for the viewing a scene which can help with an automatic choice of attention modes in computational models or whether this choice needs top-down guidance is an open research topic.
Most saliency map computational models in this book adopt the narrow visual attention, though the idea of gist features extracted from scenes and statistical features (mean and variance) from various feature maps have been applied in the object detection in satellite imagery [19, 20] (Section 7.3.3).
9.2.3 Role of Memory in Visual Attention
It is known that memory plays a key role in top-down visual attention because knowledge and experience need to be stored in memory to guide and modulate the attention in the input field. Short-term memory (working memory) and long-term memory have been implemented in a number of computational models combining with top-down processing in this book (the model with decision tree in Section 5.3, the model with amnesic function HDR in Section 5.4 and the population based model in Section 5.1).
Can the memory guide the target search in the pre-attention processing stage? The answer is positive [8] despite some existing arguments. Many indirect experiments have evidenced that memory in pre-attention visual processing can prevent already searched locations of the visual field from being re-inspected [21–23], as the phenomenon of inhibition of return (IoR) that was mentioned in Chapter 1, especially in a cluttered search scene that involves serial attention processing with eye movements. The phenomenon of bottom-up priming may contain an implicit memory that can remember a target feature or location from the previous trial [15–17]. The open questions are: How large is the memory in visual processing? What is the memory decay time? Some experiments validate the idea that the capacity of memory in IoR and priming is probably not large, the decay time is short because the eye's refixation frequently occurs after several saccades for IoR [24], and priming only happens in the last trial [12]. However, other argue in favour of a longer lasting memory of relatively large capacity [25].
Although the IoR function is considered in most pure bottom-up computational models, sometime it is also used in a top-down combining model, for example, an eye movement's map is regarded as the location's prior knowledge in the population based model already mentioned (Section 5.1) to control IoR. However, the decay time and the detailed function of IoR are rarely formulated.
9.2.4 Mechanism of Visual Attention in the Brain
During the past decades, many measuring instruments and strategies have been developed to investigate the interplay of different brain areas at a variety of levels when subjects engage in ‘target search’. The measures include single cell recording at the neuronal level, electrophysiological approaches for the time course – electroencephalograph (EEG), magneto-encephalograph (MEG) and event-related potentials (ERPs) – and function-imaging approaches for information about the interplay among brain areas during the implement of visual attention – position emission tomography (PET), functional magnetic resonance imaging (fMRI), transcranial magnetic stimulation (TMS) – that give more precise examination of certain brain areas towards visual attention and so on.
The data related to visual search (visual attention) behaviour from these measuring instruments and strategies have led to different controversial hypotheses. The reader interested can refer to the special issue about visual search and attention in the Visual Cognition journal in 2006 [11].
An interesting question about the saliency map model is that whether there is a cortex area that reflects the saliency map of the visual field to guide visual attention, or the saliency map is nominal and distributed among neurons in more cortex areas. For the former, the early point of view was that various features formed in the pre-attentive stage in the visual cortex converge at the frontal eye field (FEF) for the formation of the saliency map [26] as mentioned in Section 2.1. The discussion in the special issue of ‘Visual Cognition’ in 2006 [11] showed that the saliency map is located in different brain areas. One view is that in the MT (V5 cortex) of the brain bottom-up processes are integrated with top-down attention mechanisms, resulting in an integrated saliency map [27]. They ascribe saliency coding to the areas of the extra-striate cortex [8]. This position is challenged in [28] by arguing that the bottom-up saliency map is created from the V1 area. The fire rate of cells in V1 represents the extent of saliency. Does a real area exist in the brain that represents the saliency map? If so, where does the saliency map actually locate? This is obviously still an open question for biologists. These questions may not directly impact on the saliency map model, but they will influence other kinds of computational models that simulate the brain functioning, such as neuronal-level modes.
9.2.5 Covert Visual Attention
Covert attention refers to attention without the eye movement. Its behaviour is hard to observed. Thus, most saliency map models and their related benchmarks of performance measurement are only considered in the overt attention case, because the eye movement can be easily monitored. Covert attention exists in everyday life. It may be a prediction of the attention focus with no action, or it may be controlled by volition from top-down. In this book, the two cases of covert attention are factored into top-down models. The population based model (Section 5.1) is somewhat to simulate the former, when all computation has finished and the salient location is found on an input field but the eye movement has not started. In the hierarchical object search model (Section 5.2), top-down instructions control the eyes to fix one place of the input field in order to observe it in detail. However, the two simulations are somewhat implied. Covert attention is probably intended to search the target from the corner of the eye but not by the eye's centre. How does covert attention generate in the brain? How can covert attention be modelled in computing methods and, more importantly, what are the applications for its modelling?
9.2.6 Saliency of Large Smooth Objects
When a large smooth object is embedded in a complex background, most pure bottom-up saliency map models will fail to detect it. Reducing the size of the input image can somewhat mitigate the interference of the complex background and pop out the larger object, but this will lose a lot of high frequency components (details) of the input image. However, humans can rapidly find large smooth objects without any difficulty in high resolution images as shown in the colour image in Figure 9.3(a). Why is there this discordance between the results of humans and computational models? Especially for the biologically plausible BS model, it almost completely mimics the anatomical structure and processing from retina to primary visual cortex V1 and follows the related physiological and psychological facts, but it cannot obtain the similar results as humans generally do.
Figure 9.3 The saliency map with large smooth object (a) original image; (b) saliency map of FIS model; (c) saliency map of BS model; (d) saliency map of PQFT model. The original image, Figure 9.3(a). Reproduced from T. Liu, J. Sun, N. Zheng, X. Tang and H. Y. Shum, ‘Learning to detect a salient object,’ Microsoft Research Asia, http://research.microsoft.com/en-us/um/people/jiansun/salientobject/salient_object.htm (accessed November 25, 2012)
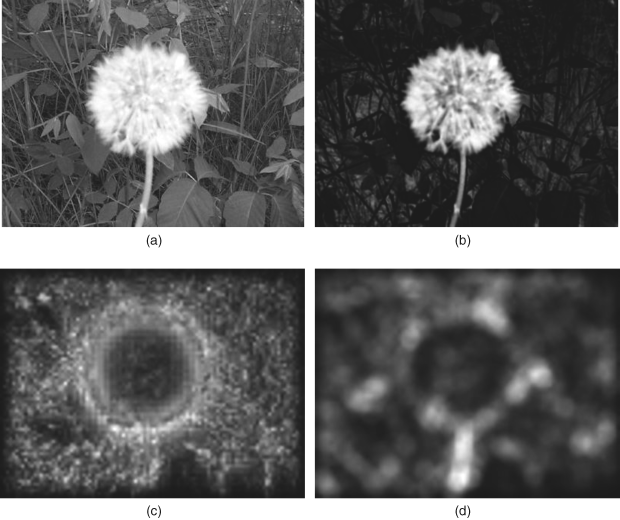
On the other hand, a lot of literature related to pure computer vision models (e.g., the FTS method keeping wide frequency band of input image [29, 30], the region contrast or context-aware methods [31, 32], etc.) mentioned in Section 7.2.2, can easily solve the problem in applications of object segmentation. Many results have been shown in the articles [29–32]. Figure 9.3 only gives one example of a colour image (a dandelion in a tussock), in which the BS model (a typical spatial domain model) and the PQFT model (a typical frequency domain model) can only detect the edges of the object, but a pure computer vision model (e.g., FTS) can detect the whole object at the original resolution. However, the pure computer vision models often aim at special applications such as large object segmentation, and rarely consider biological plausibility, so they fail to pop out a salient object in most simple psychological patterns that are often used as paradigms in many measure experiments. Figure 9.4 shows some unsuccessful examples of the FTS model.
Figure 9.4 Unsuccessful examples of FTS model when the target has different orientations from the distractors. (a) and (c) are psychological paradigms (come from http://ilab.usc.edu/imgdbs); (b) and (d) are the saliency map of FTS model. Reproduced with permission from Laurent Itti, ‘iLab Image Databases,’ University of Southern California, http://ilab.usc.edu/imgdbs (accessed on October 1, 2012)

When there is one horizontal bar (target) in many vertical bars, Figure 9.4(a), or conversely, one vertical bar (target) in many horizontal bars, Figure 9.4(c), the FTS will distinguish all items in the psychological paradigms, but not the target. Other models based on region contrast can probably pop out the target item (horizontal or vertical bar in Figure 9.4(a) and (c) respectively, if each item (bar) in Figure 9.4 is just put in a region, but the region size seems a key problem, because for different patterns the number and density of items are different and unknown beforehand.
We perhaps should not judge the computer vision models too harshly, because they are not based upon any biological background. The question is why the BS model in the spatial domain and the PQFT in the frequency domain both fail to pop out a large object.
For the PQFT model, Figure 9.3(d) can be explained easily, because flattening the amplitude spectrum means enhancing the high frequency components and suppressing the low frequency components, resulting in high saliency of the edges of the large object and low prominence on the smooth part within the large object. The FTS model almost keeps all the amplitude spectrum in the wider frequency band from high to low components, so the whole large object can pop out; but the FTS model cannot distinguish the target in Figure 9.4(a) and (c), because all items with the same frequency components are enhanced. On the other hand, the PQFT model (as a special case of FDN) simulates the three stages of the BS model and is implemented in the frequency domain, so it can pop out most psychological paradigms and natural images.
For the BS model, first let us consider one of its important operations, ‘centre–surround’ (off/on or on/off), that simulates the receptive field of the ganglion cells in the retina, formularized by the difference-of-Gaussian (DoG) function (Equation 2.3). Many spatial domain computational models such as the BS, GBVS and DISC models make use of the centre–surround operation that often indicates prominent objects. Since the centre–surround operation extracts the edges of objects in an input image, the smooth part within a large-size object is discarded in the early visual processing. This seems unreasonable, because the human vision can perceive the whole large object, and not only the edges of it. In this regard, let us consider the following finding in physiology.
Since the 1960s, studies have found that, apart from the classical receptive field (cRF) of a ganglion cell, there is a large-size region called the non-classical receptive field (non-cRF). Non-cRF not only contains the region of the cRF, but covers the larger periphery region beyond the cRF. The function of the non-cRF of ganglion cell is to modulate the response of the cRF when some stimuli exist in the cRF, [33–35]. Another finding in [36, 37] showed that the diameter of the non-cRF is about 3–6 times larger than the cRF and it can inhibit the antagonistic effect of the surrounding area on the centre of a ganglion cell. Thus, the non-cRF compensates for the loss of low frequency components while keeping edge enhancement, highlighting the whole object with low luminance change on a large scale. Considering non-cRF of a ganglion cell, the processing was formularized by combining three Gaussian functions (the difference of two Gaussian functions represents cRF while another Gaussian function simulates the non-cRF's processing) [38], and the image representation of the non-cRF and the controlled cRF processing was discussed in [39]. Figure 9.5 shows the processing result after cRF (difference between two Gaussian functions: centre–surround) and the result of considering the action of non-cRF (combining all three Gaussian functions).
Figure 9.5 The processing results of large size object by cRF and combining cRF and non-cRF of ganglion cells. (a) original image; (b) the resulting image after classical RF processing; (c) the resulting image under considering the action of non-cRF
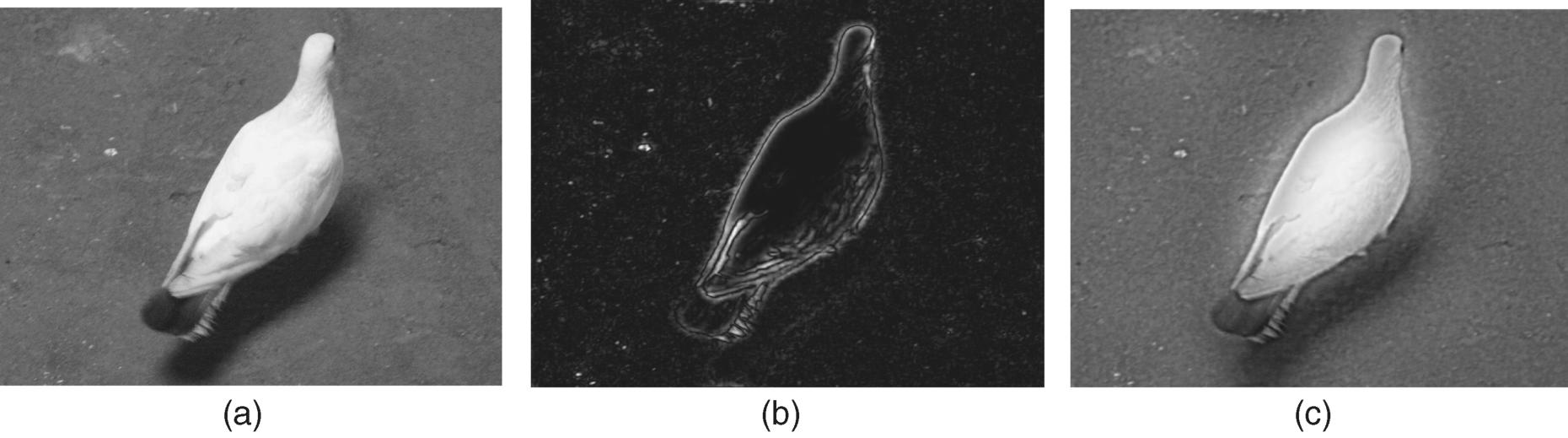
Figure 9.5 shows that the common processing of the centre–surround receptive field may discard too much information (only the edges of an object pop out) and the adjustment of the largely peripheral receptive field helps to hold the whole information (the whole dove can pop out).
But can this biological fact be incorporated in computational models with biological plausibility and are other biological facts needed to improve the computational model? These are still the open questions.
9.2.7 Invariable Feature Extraction
A puzzling problem in pattern recognition applications is how to extract invariable features as in the human brain when object change happens, especially for flexible and deformable objects. The human being has no difficulty in recognising various kinds of deformable objects, but many algorithms in engineering cannot do so well. Simple feature extraction concerned in the early processing in the brain can partly solve this tough issue, such as multiple scale processing for a scale invariable feature, but extraction of most other features or complex features related to high-level cortex processing in the brain still remain as a problem to be solved.
9.2.8 Role of Visual Attention Models in Applications
There is no doubt that visual attention is important in human perception. However, there are various views on its role in various engineering applications. Improvement has been reported by using the saliency map to weight a quality map for perceptual quality prediction [40–42] and to guide computer graphic rendering [43, 44]. On the other hand, it has been argued that a visual attention model is not always beneficial for a perceptual quality metric (at least for simple weighting) [45]. Even when metrics were reported to be improved using recorded saliency data (via an eye tracker) [46], it was also observed that greater improvement was found with saliency recorded in task-free viewing than in the cases of subjects being asked to assess the picture quality. This seems to be related to top-down (task-oriented) aspects of visual attention.
Visual quality may be influenced not only by attentional regions, but also by non-attentional ones, since the HVS's visual information processing is over the whole visual field in the pre-attentive stage. Therefore, besides the quality of the attended regions, that of unattended regions needs to be properly fused into the overall quality index [47].
Some researchers argue that distortion in image compression (with JPEG and JPEG 2000 coding) and transmission (with packet loss) changes subjects' eye fixation and the associated duration [48], while another work indicated that there is no obvious difference in the saliency maps between a test video sequence and its original [49].