
3.2 Modelling for Videos
The major difference between images and videos is the possible object movement in the temporal axis. In fact, visual attention modelling is more meaningful for videos than still images. The perception of still images varies with the allowed observation time. That is, if an observer has a long enough time to perceive an image, every point of the image can become the attention centre eventually. The perception of video is different. Every video frame is displayed to an observer within a limited time interval, which is determined by the frame rate. Furthermore, motion causes the viewer to pay attention to the moving part and triggers subsequent eye movement. In this section, we will first discuss a simple extension of the BS model introduced in Section 3.1 for video scenario (as Section 3.2.1). Then the computation of the motion feature is presented in Section 3.2.2, and the introduction of an alternative visual attention formulation is given in Section 3.2.3, which allows the consideration of overlapping among different features appearing in the visual signal simultaneously, as well as interaction of salient locations and smooth transition.
3.2.1 Extension of BS Model for Video
Humans are interested in moving object in a static environment: a moving boat on a calm sea or a moving car in the street and so on, often attract the observer's attention, and so motion is a very important feature in the video attentional model. In principle, the BS model illustrated in Figure 3.1 can be extended to include motion feature maps for video. A simple idea is to add a motion feature channel in the BS as proposed in [3], in which a flicker pyramid that simulates light change (temporal onset/offset) is computed by using the absolute difference between the current and previous frames in the intensity channel and the motion pyramid estimation in four directions (up, down, left and right) is calculated by using one spatially shifted pixel in orientation maps. Specifically, four Gabor orientations are used in motion direction estimation, and only shifts of one pixel orthogonal to any orientation map between the current and previous frames are considered as a motion feature under the given direction. Because of the pyramidal representation, one pixel shift can capture a wide range of object motion (one-pixel shift for d = 8 is equivalent to 256 pixels for d = 0).
Flicker and motion pyramids are incorporated in the original BS model for computing the video saliency map. The added pyramids with nine scales for each of the four motion directions and one flicker, resulting in 45 images, produce an additional 30 feature maps via centre–surround processing in a similar way to other feature channels (see Section 3.1). There are a total of 72 feature maps (including the original 42 feature maps and the additional 30 feature maps) in the model for video. The cross-scale combination for motion feature and flicker is also the same with the other feature channels. Finally, the saliency map for video is obtained by cross-feature summation, as presented in Section 3.1.3 above. This simple extension of the BS mode is straightforward, and the reader should be able to implement it based upon the methodology that was introduced in Section 3.1.
3.2.2 Motion Feature Detection
Motion is one of the major stimuli on visual attention in video [16, 17]. How do we detect motion of moving objects? The simplest method is to compute the difference between two consecutive frames as introduced above, and the difference image at the locations of moving objects is often associated with non-zero values compared with zeros in the still background. However, this kind of detection cannot estimate the real motion direction of objects accurately, especially with camera motion, because the background motion disturbs the difference image (as will be elaborated next). Another motion detection method is to compute optical flow with some constraint conditions for each pixel under consideration, which can detect direction of motion at each pixel in the video [18]. Also, there are other motion detection methods such as affine motion parameter estimation, block motion estimation and so on, some of which are used in standard video coding (MPEG or H.26L).
For more careful studies, object motion can be divided into relative motion and absolute motion, denoted as vr and va, respectively. Relative motion in video plays a more significant role in visual attention [4]. Relative motion is the object motion against the background in the scene; absolute motion is the motion against the frame of viewing, that is the combination of camera motion and object motion in the real-world coordinates (if the camera follows the object exactly, absolute motion of the object is zero in the captured video).
Since the contributions of absolute and relative motion to visual attention are not the same, we need to detect and discuss them in detail. A multiple layer dense flow estimation algorithm [19] can be adopted to estimate the absolute motion va, and the relative motion vr can be estimated via the algorithm in [20]. Usually, the attentional level of an object is low when vr is low (as shown in the rows 2 and 3 in Table 3.1), while the attentional level of an object is relatively significant when vr is high; the highest attentional contribution occurs with low va and high vr. However, since the camera's motion often indicates the most important object/region in the visual field, the attentional contribution for a moving object with high vr and high va is moderate (because such an object is usually not of primary interest); an example is the video of a car race: if the camera follows a car, then other cars nearby are not the main centre of attention even if they move faster. These two circumstances are represented as the lower two rows in Table 3.1.
Table 3.1 Motion attentional level determined with vr and va (reproduced from [4]) © 2005 IEEE. Reprinted, with permission, from Z. Lu, W. Lin, X. Yang, E. Ong, S. Yao, ‘Modeling visual attention's modulatory aftereffects on visual sensitivity and quality evaluation’, IEEE Transactions on Image Processing, Nov. 2005.
| vr | va | Motion attentional level |
| low | low | low |
| low | high | low |
| high | low | high |
| high | high | moderate |
In fact, the global distribution of vr affects visual attention as well. In order to consider the extent of relative motion in the context of the whole frame, vr is scaled with the reciprocal of the average relative motion in the frame as [4]:

where nr(e) denotes the number of pixels in the image frame with vr = e. In Equation 3.12, the scaling factor decreases when the average relative motion is high. The manipulation of vr is similar to that by N(·) in Section 3.1, and can also be applied to other features (e.g., colour, intensity, orientation and texture). Following the idea shown in Table 3.1, the motion stimulus generated by vr should be adjusted by va, to obtain the motion feature map:
(3.13) ![]()
where gadj is an adjusting function, based on the concept of Table 3.1 to determine the correcting factor for vr. In [4], gadj is decided with the experimental results using the standard video sequences, and a simple heuristic realization can be illustrated as Figure 3.3.
Figure 3.3 Simple heuristic realization of gadj
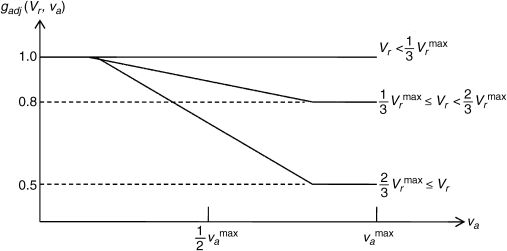
It is seen clearly from Figure 3.3, that when the levels of both absolute motion and relative motion are high, the adjusting function gadj is decreasing, and this reduces the contribution to the motion feature map.
3.2.3 Integration for Various Features
Assume that we have different features, denoted by ![]() , where
, where ![]() may represent C (for colour), I (for intensity), O (for orientation), Te (for texture), Mv (for motion) and so on.
may represent C (for colour), I (for intensity), O (for orientation), Te (for texture), Mv (for motion) and so on. ![]() may be detected via methods in Section 3.1 and the previous subsection. For simplicity of presentation, we will further assume that a feature
may be detected via methods in Section 3.1 and the previous subsection. For simplicity of presentation, we will further assume that a feature ![]() has been formalized by N(·) specified in either Section 3.1.3 or a way similar to Equation 3.12. Equation 3.11 has presented an approach for feature integration. Here, we discuss an alternative scheme with provision to account for inter-feature overlapping, and saliency interaction and transition. In [21], a non-linear additivity model has been adopted to integrate two different perceptual stimuli for saliency detection; it has been extended in [4] to multifeature integration to generate the saliency map:
has been formalized by N(·) specified in either Section 3.1.3 or a way similar to Equation 3.12. Equation 3.11 has presented an approach for feature integration. Here, we discuss an alternative scheme with provision to account for inter-feature overlapping, and saliency interaction and transition. In [21], a non-linear additivity model has been adopted to integrate two different perceptual stimuli for saliency detection; it has been extended in [4] to multifeature integration to generate the saliency map:
where ![]() stands for the major feature, that is
stands for the major feature, that is
(3.15) ![]()
The first term of Equation 3.14 accumulates various features for saliency determination; the second term accounts for the inter-feature overlapping effect, and a bigger ![]() indicates higher correlation between features
indicates higher correlation between features ![]() and
and ![]() . A reference set of
. A reference set of ![]() values is given in [4]. For instance, colour and intensity contrasts will attract largely independent attention, so
values is given in [4]. For instance, colour and intensity contrasts will attract largely independent attention, so ![]() ; if two features
; if two features ![]() and
and ![]() have weak correlation, we can choose
have weak correlation, we can choose ![]() .
.
In most applications of saliency map, a block (rather than a pixel) presentation is used for the sake of operating efficiency (i.e., all pixels in a block share the same saliency value) since the saliency changes gracefully or need not vary unnecessarily [22].
The saliency value of an image block is the average of all salient pixel values in the block, which can be represented as [4]:
where (bx, by) is the coordinate of the block in the frame, ![]() is the collection of pixels in block (bx, by),
is the collection of pixels in block (bx, by), ![]() is the size of
is the size of ![]() , and SM(x, y) is the saliency value at pixel (x, y). In practice, the block size is often set as 8 × 8, so
, and SM(x, y) is the saliency value at pixel (x, y). In practice, the block size is often set as 8 × 8, so ![]() . The saliency map of the block image is
. The saliency map of the block image is ![]() and each element in the block saliency map is equal to SM(bx, by) of Equation 3.16.
and each element in the block saliency map is equal to SM(bx, by) of Equation 3.16.
In order to mimic the gradient property with visual attention [23], account for the interaction of blocks in a neighbourhood and further ensure reasonable smoothness in the saliency map for video, a kernel can be used for post-processing, as in [4], to evaluate the influence of block (bx, by) on block (![]() ):
):
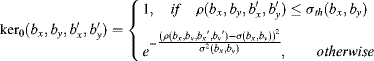
where the inter-block distance is
(3.18) ![]()
and the scope threshold for block (bx, by) is shown as
with ![]() being a constant close to 1.0, and we can see from Equations 3.17 and 3.19 that a bigger
being a constant close to 1.0, and we can see from Equations 3.17 and 3.19 that a bigger ![]() has a larger influence scope. The defined kernel is then normalized as
has a larger influence scope. The defined kernel is then normalized as
(3.20) ![]()
Therefore the smoothened saliency map becomes [4]:
In summary, Equations 3.14, 3.16 and 3.21 provide pixel-based, block-based and smoothed block-based saliency maps, respectively, for various problems to be solved, system requirements and application scenarios.