
2.3 Guided Search Theory
Another influential idea, Wolfe et al.'s proposal called guided search (GS), has been proposed as an extension of the FIT. It has eliminated the deficiency of the standard FIT and captured a wide range of search behaviours [55–61]. Similar to the use before, the term ‘search' refers to scanning the environment in order to find a target in a scene no matter whether the target exists or not. Hence, the GS theory is implemented from the perspective of target search in input visual field. The main differences between the standard FIT and GS can be stated as follows. (1) In FIT, the two stages, pre-attention (or feature registration) in parallel and attention (or feature integration) in serial are processed almost separately. Very little information from the parallel pre-attention stage influences the next serial attention stage in conjunction cases. Two of main results are: 1) searching a conjunctional target is very slow and its RT increases with detractor size; 2) target-absent (negative) search requires double RT compared to the target-present (positive) search. In the standard FIT experiments, the subjects did not know what to look for, so there is no guidance from the parallel pre-attention stage for the serial search stage. In fact, the linear ascended (RT vs. size) function of conjunctional search and the 2 : 1 ratio in slopes between negative and positive searches are not valid in some trials. GS theory gives some experimental results to confirm that the pre-attention stage can transfer information to the attention stage, so that searching for a conjunctional target becomes very fast and the RT increasing with detractor size cannot hold, since subjects can indeed get some guidance from the parallel search stage or from the summarization of their experience in the parallel search stage to find the target. (2) In the second GS version (GS2), top-down knowledge is added into the model, so both bottom-up and top-down activities are summed to form an activation map in which the locations with high value are regarded as candidate target regions. The activation map can guide the subject to search these candidate target regions. It is worth noting that in the conceptual model of FIT, the master map only records the focus location to complete integration of features extracted from the input visual field. It does not concern the guidance of the target search in serial attention stage. (3) A threshold is set in the activation map in the GS2 model, so that the serial search in the conjunction case can stop if the values at some locations on the activation map are less than the threshold, which can avoid exhausted search. The threshold aims to simulate a physiological phenomenon of just noticeable difference (JND) in the pre-attention stage when the target is in a noisy or poorly illuminated scene. More detail difference between FIT and GS will be introduced in the following subsections.
The GS theory is based on the facts that cannot be predicted and explained by the standard FIT. Early guided search theory called GS1 was proposed by Wolfe et al. [55] and Cave and Wolfe [56]. In the GS1 model, parallel feature extraction from the input visual field is similar to the methodology in FIT, but the parallel process divides the set of all information into distractors and candidate targets, although it cannot determine the location of a conjunctional target. Therefore, in the series process that follows, the search is only for these candidate targets. Afterwards, the early GS1 model was modified into many improved versions [57–61]. The most widely used model was called GS2 [58]. In GS2, the input is filtered by broadly tuned channels in parallel for each feature map, and then the summation of the filters' outputs generates bottom-up activation in each feature map. Top-down activation is added by the weighted feature maps and combined with bottom-up activation to create an activation map. An activation map is a topographic map that combines both bottom-up and top-down activations for all feature maps. The location with the highest value in the activation map is the first attention focus. That is, the information in both bottom-up and top-down processes forms an activation map to determine the attention location. If a subject did not find the target at the first maximum location in the activation map, his eyes would move to the second maximum location. This seems to be more coincident with reality. Versions GS3 and GS4 were proposed later [60, 61], which have further improved GS2 to cover more psychological facts and to capture a wider range of human search behaviours. Since GS2 is the most influential model for many computational models, this section mainly introduces the GS2 model.
2.3.1 Experiments: Parallel Process Guides Serial Search
There were many trials showing that target detection defined by a feature conjunction might be beyond the predicted result of the standard FIT in some situations. For some subjects, a number of conjunction cases could produce very small slopes of the linear function (RT vs. distractor size) [55, 62–65] or even near flat slopes such as the published data for single feature search in the FIT (i.e., RT is independent of set size). Wolfe's group designed some experiments to explore the cause, and a new modified FIT model was proposed in 1989 –1990. A part of early represented experiments [55, 56] are abstracted from their publications as follows in order to explain the idea.
2.3.2 Guided Search Model (GS1)
The experiments described in Section 2.3.1 show that the original FIT cannot explain some psychological facts. The modified version was first proposed in [55, 56], considering guidance from the parallel process. There are two different ideas in [55, 56], which are related to the relevant physiological and psychological facts. In terms of physiology, input stimuli projected onto the retina from the visual field are processed in detail only at the fovea, and the information in the periphery is coarsely sampled. Therefore, uninteresting input information is discarded. The related idea of psychology is that the parallel process inhibits non-target locations and discards some distractors' information; the results will guide the serial process in the second stage for the conjunction search [56], that is the parallel process can give some selections to guide the later serial search.
The guided search model GS1 [55] in a simple conjunction case is demonstrated in Figure 2.11. The conjunction target (red vertical bar) is put in several red horizontal bars and several green vertical bars. In the parallel search stage, the locations of input stimuli which have the features of horizontal and green are discarded as distractor information. Each parallel feature map excites the spatial locations related to all the candidate targets; for instance, items in feature map (red colour or vertical orientation) are considered as candidate targets first. The conjunction target will excite two different dimension feature maps (both colour and form), but the distractors only excite a feature map (colour or form). An activation map is the pixel-by-pixel summation of all the feature maps. The spotlight of attention is pointed to the target at the maximal location of the activation map since the location of that target receives double excitation. In Figure 2.11, input stimuli include colour and orientation bars. All the red bar locations and all the vertical locations are excited in colour and orientation maps. Finally, the location of the activation map with the maximum value indicates the location of the target. In that case, subjects can sometimes find the target quickly, and the RT is near to the single feature case.
Figure 2.11 The guided search model for simple conjunction search. Adapted from Wolfe, J.M., Cave, K.R., Franzel, S.L. (1989) ‘Guided search: an alternative to the feature integration model for visual search’ Journal of Experimental Psychology: Human Perception and Performance, 15, page 528, Figure 5

This serial search may be faster than that of the case without guidance of the location map (master map) in the standard FIT (Figure 2.3). In a target-absent case, the serial search may continue at random until every item is checked. Consequently, the 2 : 1 slope ratio for the searching of negative vs. positive does not hold in the experiments above because in a target-present case the RT vs. size function has a small slope. Note that the GS1 model implies top-down instructions. Let us again use the example above. If in the parallel stage a subject first considers the green feature map, there will be no different orientation associated with it, so it will be discarded rapidly and the red feature map is to be considered next. In red feature map the item with unique orientation is detected easily. This model can explain all the facts in the simple conjunction case shown in experiment (a) of Section 2.3.1.
To search for a ‘T' among ‘L's, both target and distractors contain the same simple features, vertical and horizontal segments, in the orientation feature map. At all the locations, the same features can be seen in a parallel stage, so the feature map is unable to guide the serial search stage. Subjects have to use a serial self-terminating technique to search for the target. The results are the same with the standard FIT, that is the result in experiment (b) of Section 2.3.1 accords with the conclusion of standard FIT.
In a noisy or less salient stimulus case, many positions in feature maps will be excited because of noise influence, and the resultant searches will be serial, as mentioned in Section 2.3.1 (experiments (d)). In that case, the first maximum value on the activation map may not be the target location. Eyes need to search for targets serially according to the order of excited values on the activation map.
For a triple conjunction case, the target and distractors will share one or two features and the target makes three different feature maps excited simultaneously. This should lead to a more efficient search, especially when the target sharing one feature for each of three kinds different distractors, respectively, because a very large value on the activation map can be obtained at the target location. Experiments (e) of Section 2.3.1 can also be illuminated by the model in Figure 2.11.
In summary, the GS1 model can explain facts both differing from or agreeing with the standard FIT. It highlights an important idea that the serial search for conjunctions can be guided by the parallel processes if top-down information is implied.
2.3.3 Revised Guided Search Model (GS2)
Although GS1 can explain more psychological facts than the FIT, not all of the new data or phenomena are completely consistent with GS1. Hence, the model needs adaptation or modifications to make it coincide with even more psychological facts that are relevant to human visual attention. For this reason, a revised version of GS1 was proposed in 1994, called GS2 [58]. In GS2, each feature map of Figure 2.11 is separated into categorical channels by several filters. Top-down and bottom-up activations are combined to an activation map by weighted summation. The activation of bottom-up information is sensitive to the difference and distance between each local item and its neighbours. A threshold is explicitly added in GS2, which can stop the serial search when the excited value at the location of a hill point is less than the threshold on the activation map. As mentioned at the beginning of this Section 2.3, the threshold aims to simulate just noticeable difference in a noisy or poorly illuminated scene. In addition, the inhibition between the same items in a feature map is considered in GS2; for example, in feature search for the target (a red bar in many green bars), the non-targets (green bars) are inhibited by each other, so the corresponding values in the green feature map are lower. However, the unique red target in the red feature map appears with a highly excited value because there are no inhibited signals from its neighbours, which will cause the red target to stand out more.
GS2 is the most widely used model and can be easily approved by the researchers from relevant engineering areas even in comparison to the further modified versions, GS3 and GS4, which were developed later. Therefore, it is essential to describe GS2 in detail. Figure 2.12 shows the architecture of model GS2.
Figure 2.12 The architecture of GS2 [58]. With kind permission from Springer Science+Business Media: Psychonomic Bulletin & Review, ‘Guided Search 2.0 A revised model of visual search,’ 1, no. 2, ©1994, 202–238, Jeremy M. Wolfe
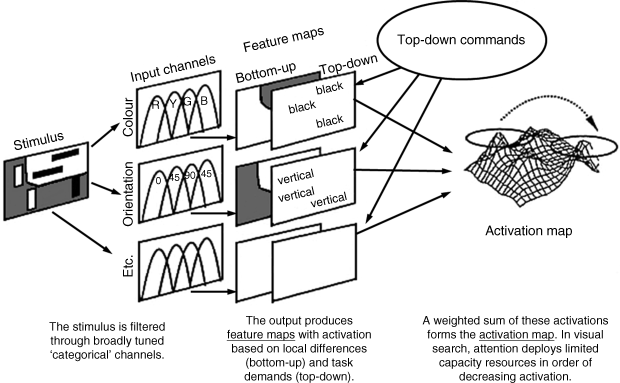
The model includes several feature dimensions (or feature maps), several separate filters in each feature map, both bottom-up activation and top-down activation for each feature map, and a final activation map. The bottom-up process in each feature map depends on several separate filtered channels. The top-down knowledge drives the top-down activation of a feature map and guides attention to a desired target.
According to the final activation map, the information located in high activations is directed to the limited resources in the brain for further processing (in the post-attention stage).

2.3.4 Other Modified Versions: (GS3, GS4)
GS1 suggests that the parallel process can guide the attention in the serial stage and this explains the efficient search in conjunction cases; GS2 separates parallel feature maps to several broadly tuned ‘categorical' channels and considers the activation map as a combination of bottom-up and top-down information to guide the target search. In other words, GS2 extends the search guided model GS1 and can account for more laboratory findings.
In the real world, target search involves eye movement. The fovea of the retina samples input stimuli with much greater detail. Searching for an object in the visual field, subjects often make the fovea move towards regions of interest, and the fovea is often moved to the central coordinate of visual field. GS3 [60] incorporates eye movement and eccentricity effects in GS2. In GS3, the activation map is a winner-take-all neural network. All the units on the activation map compete with each other. The unit located at the maximum hill in the activation map will win the competition, and this results in the attention focus being fixated by the eyes. Attention focus on the activation map acts like a gate, and at a given time only one object can be conveyed for higher level processes and recognition that corresponds to the post-attention stage. If the selected object is not the desired target, a feedback signal from higher level of the brain will return to the activation map and inhibit the winner unit. In succession, the competition continues and creates a new winner as a new fixation point that the eyes' fovea is pointing towards. The inhibition of return is necessary in the eye movement and attention deployment in order to find the next attention focus. In GS3, the eye movement is represented by a trace of serial searches by an eye saccade map. Obviously, GS3 can cover more examples and phenomena in the laboratory and the natural environment. However, in GS3 the functions of eye movement, attention gate, object recognition, saccade generation and so on, are represented as blocks that cannot be described in detail. Thus, these functions are hard to implement in engineering.
GS4 is one recent version proposed in 2007 [61]. It describes a parallel-serial hybrid model. The top-down guidance is based on the match between a stimulus and the desired properties of a target. If the processing from input to activation map is a path from input to output, in GS4 an added path from input to output is considered to deploy the attention in addition to the path already described in GS1–3. Hence, the version can not only model simple search tasks in the laboratory, but can also capture a wide range of human search behaviours.
In GS4, one object or a group of objects can be selected and passed through a bottleneck at a time, and both parallel and serial stages are combined together to form the attention that is to control the bottleneck. Most parts of GS1–GS3 are incorporated in GS4. It is known from the FIT that attention can bind features produced in the parallel process to represent the early vision of an object. Without attention, people cannot glue more than one feature to a conjunction item correctly. Another view is that the limited resources in the brain cannot process all the information from the early vision. The attention mechanism selects the input of interest, and then controls and deploys the limited resources to process it effectively. Based upon the two considerations above, GS4 suggests two parallel paths: one of the paths is like the one in GS1–GS3 and early FIT models in which input stimuli are processed by parallel channels, and then are selected via attention mechanism; the other path is to analyse the statistical characteristics in the input image based on [66, 67]. The deployment of selection in the latter path can be guided by statistical properties extracted from the input scene, and this is the another capability of GS4. The working of two paths is independent in a parallel manner, but finally the outputs of the two paths are simultaneously input to another bottleneck (the second bottleneck) to make the final decision. The inhibition of return is from the output of the second bottleneck. GS4 is a more complicated system which includes many parameter controls and timing considerations, so it is not discussed here in detail. The interested reader is referred to [61] for GS4, and should be able to understand the model after the introduction of the various GS models in this section above. As with GS3, there are no detailed descriptions for the added path in [61].
The GS model can be developed into even more advanced versions with the progress of psychology. New processing modules can be added in the GS model. For many scientists and engineers, GS2 is sufficient for developing meaningful, effective and efficient computational models in many engineering applications.