
1.2 Types of Selective Visual Attention
In Section 1.1 we showed that visual attention is an ability of humans and quadrumanes, and exists universally. Over the past several decades, many researchers, especially physiologists, psychologists and computational neuroscientists, have tried to understand the mechanisms of visual attention. Different types of selective visual attention has been explored and described in the literature from different viewpoints and with different emphases, such as pre-attention and attention [25, 26], bottom-up attention and top-down attention, voluntary and passive attention, parallel and serial processing of attention in the brain, overt and covert attention and so on. Although these types are related, overlapped or similar, it is beneficial to discuss them for the purpose of understanding of visual attention studies and the related theory, since in fact, the different types (to be introduced in the rest of this section) reflect different aspects of selective visual attention and are often complementary to each other.
1.2.1 Pre-attention and Attention
From the signal processing point of view, visual attention is divided into two stages: pre-attention and attention stages, as proposed by Neisser and Hoffman [25, 26]. The pre-attention stage provides the necessary information for attention processing. For instance, a single feature such as orientation, colour or motion must be detected before the stimulus can be selected for further processing. In this stage, both features on the background and the objects are extracted. However, only the object ones may attract human attention in the attention stage. In the anatomical structure of the visual pathway, we can see that many simple cells of the primary visual cortex can extract these simple features from their receptive fields respectively by applying different filters when an input scene appears. The pre-attentive processing is supported by local processing and is independent of attention. It is an automatic process with very high speed and is involuntary. It works in parallel for multiple features in the visual field.
The attention stage occurs after the pre-attention one. The region with important information in the input scene is fixated longer and is observed in detail. In the attention stage, only one target is processed at a time. The stage may need the integration of many features and sometimes needs guidance from human experience, intention and knowledge. In most cases, pre-attention gives all the salient information in the visual field as a result of parallel processing, and in the attention stage, a selected object is observed firstly. There is a special case with the same focus in both the pre-attention and attention stages. If a target in the pre-attention stage can be discriminated, for example, a spotlighted target in a dark room can attract attention rapidly, and then the target always can be dealt with first, in the attention stage.
In summary, pre-attention is an operation based on a single feature such as colour, orientation, motion, curvature, size, depth cues, lustre or aspects of shape. In the pre-attentive stage, there is no capacity limitation; that is, all the information is processed across the entire visual field. Once the field of view has been analyzed and features are processed, the attention is focused. Features are only analyzed but not integrated in the pre-attentive stage.
Attention is an operation of feature integration. In the attentive stage, features may be bound together or the dominant feature may be selected. A target with several features can be focused.
Pre-attention and attention are also called vision before attention and vision with attention, respectively in [5, 27]. Another stage, proposed in [28], is vision after attention or the post-attentive stage. In the post-attentive stage, a subject performs further searches among objects of the same group. Search efficiency in this stage will improve because the HVS has already attended to the presented objects and is now familiar with them.
1.2.2 Bottom-up Attention and Top-down Attention
Many experimental results favour a two-component framework for the control of attentive deployment [27–30]. This framework suggests that the subject's attention for an input scene arises from both stimuli-driven factors referred as bottom-up attention and task-driven factors referred as top-down attention.
The bottom-up attention is based on salient features of the input image such as orientation, colour, intensity and motion. Bottom-up attention in the pre-attention stage (as introduced in the previous section) is the outcome of the simple feature extraction across the whole visual field and the inhibition of the centre neuron versus surrounding neurons. Therefore, a highly salient region of input stimuli can capture the focus of human attention. For example, flashing points of light on a dark night, sudden motion of objects in a static environment, and red followers on a green background (its luminance version was shown in Figure 1.1(c)) can involuntarily and automatically attract attention. Bottom-up attention is derived from the conspicuousness of areas in the input visual field, influenced by an exogenous factor and regardless of any tasks and intentions. Therefore, bottom-up attention is sometimes called stimuli-driven attention. It is believed that stimuli-driven attention is probably controlled by early visual areas in the brain. Due to the cells in the early visual areas operating in parallel for input data, the response time of bottom-up attention is very fast, on the order of 25–50 ms per item, excluding eye shift time [23].
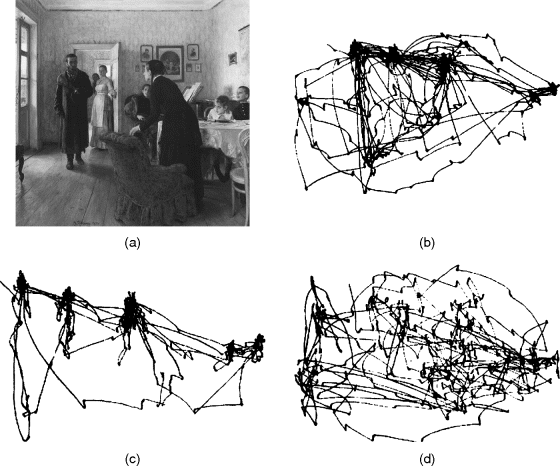
Top-down attention refers to the set of processes used to bias visual perception based on task or intention. This mechanism is driven by the mental state of the observer or cues they have received. In the famous top-down attention experiment proposed by Yarbus [24], observers were asked several questions about the scene of a family room shown in Figure 1.3(a). The tracking positions of the eye saccades vary in the question- free case and the cases with questions. The attention focus of observers is different between the question-free case and a case with a question, and that is also different if a different question was asked in the same scene. Figure 1.3(b)–(d) show the results of eye movement in the question-free case, in the case with the question about the ages of persons and in the case with a cue of remembering the positions of objects, respectively. The selected regions congregate around the faces of the people when the observers were asked about persons' ages (Figure 1.3(c)). In addition, the focal regions were around the locations of objects or people when they were required to remember the positions of objects. Since the saccade diversity is dependent on tasks or cues, top-down attention is also referred as task-driven attention. Note that the tasks or cues are concerned with the objects in a scene, and the final selective regions of top-down attention are probably related to the observer's prior knowledge, experience and current goal, which are mostly controlled by high-level cortex. Therefore, information from higher area is fed back to influence the attention behaviour.
Figure 1.3 The tracks of saccades and fixations by Yarbus (1967) [24]. Each record lasted 3 minutes for (b)–(d): (a) The scene of a family room (source: courtesy of www.liyarepin.org); (b) the saccade track in the question-free case without any cues; (c) the saccade track with a cue: to answer the ages of family members in the scene; (d) the saccade track with a cue: to remember object and person positions. With kind permission from Springer Science + Business Media: Eyes movements and vision, © 1967, Yarbus
Bottom-up attention only pops out the candidate regions where targets are likely to appear, while top-down attention can depict the exact position of the target. Sometimes top-down attention is not related to bottom-up saliency at all. A tiger in the forest can capture small animals hidden in brushwood rapidly, notwithstanding there being no prominent sign of bottom-up processing in the area where the animals are hidden. Under the experiential guidance from itself and its mother, the tiger can still find its prey. It has become obvious that top-down attention is more powerful in object search and recognition. Nevertheless, both forced and voluntary attention comes at a price. In general, task-driven attention costs more than 200 ms [23] for a young and inexperienced subject. Learning and knowledge accumulation help to reduce the reaction time of top-down attention.
Commonly, both bottom-up and top-down attention mechanisms operate simultaneously. It is difficult to distinguish which attracted region is the effect of bottom-up and which part is influenced by top-down. In most situations, the final results of attentive focus in an image or a scene come from both mechanisms. For instance, freely viewing a scene, different subjects may gaze at different salient regions. Knowledge and experience – and even emotion embedded in subject's higher areas of the brain – will be partly involved in the attention processing. For studying these two kinds of attention respectively, many psychologists and scientists of computational neuroscience and cognitive science have designed various psychophysical patterns for subjects to test the reaction time of searching targets. Some carefully designed image patterns can roughly distinguish between sensory-driven and task-driven processes [4, 5, 29, 30].
Since the structure and principles for early visual regions in the brain have been revealed by physiologists [31–34] and the analysis of input stimuli is easier than for mental states in higher areas of the brain, a large number of computational models simulating bottom-up attention have been developed. A two-dimensional topographical map that represents the conspicuity of input stimulus at every location in the visual scene has been proposed in bottom-up attention models [5, 30, 35]. The resultant map for attention is called the ‘activation map’ in Wolfe's model [30], and the ‘saliency map’ in Koch's model [35]. The level in the saliency map reflects the extent of attention. A location with a higher value attracts attention more easily than a location with a lower value in the saliency map.
Contrarily, only a few computational models of top-down processing have been investigated up to now, and usually the models are based on the knowledge about an object to be found. The other top-down factors such as expectations and emotions are very difficult to control and analyse. Therefore, this book introduces more bottom-up computational models and only a few top-down models [36, 37] in which the aspects on expectations and emotions are not investigated.
The essential points of bottom-up and top-down mechanism are summarized as follows.
1.2.3 Parallel and Serial Processing
It is known that the neurons in our brain are interconnected. Also, they work in massive and collective fashion. Many physiological experiments have revealed that input stimuli projected on the retina of our eyes are processed in parallel. In addition to that, the cells in the primary visual areas work in parallel too, as mentioned in the pre-attention stage. On the other hand, deduced from the phenomenon in Figures 1.2 and 1.3, the focus of our eyes often shifts from one place to another, so the search for eye movement is serial. Since parallel processing is faster than serial, the reaction time of object search can be used to test the processing type. Some psychological patterns were proposed to test which is parallel and which is serial according to the reaction time of observers seeing these patterns [4, 30]. Figure 1.4 shows a simple example. The unique object of all the patterns in Figures 1.4(a)–(d) is located in the central place to test the reaction time of the observers. In the early 1980s, Treisman suggested that the search for a target with simple features that stands out or pops up relative to its neighbours (many distractors) should be detected in parallel, since the search was little affected by variations in the number of distractors [4]. Figures 1.4(a) and (b) demonstrate a good example for the simple feature case with Treisman's suggestion. The object (vertical bar) in the midst of horizontal bars (distractors) pops out very easily and quickly with varying numbers distractors and their distribution.
Figure 1.4 Examples of simple psychological patterns to test reaction time of an observer: (a) and (b) are the cases with a single feature involving parallel processing; (c) and (d) are the cases with conjunction of multiple features involving serial processing

In contrast, the search for a target with a combination of more than one feature should be detected after a serial scan of varying numbers of distractors [4]. The examples in Figures 1.4(c) and (d) can explain this situation. The unique object is a combination of two simple features, a cross made up of a horizontal line segment and one tilted at 45°. The surrounding distractors are crosses that all include a different line segment (line segments vertical or tilted at 135°) and the same line segment (horizontal or tilted 45° line segment) as the object. The detection time of search object slows down with increasing the number of distractors; that is, the pattern of Figure 1.4(d) is more difficult to detect than the pattern of (c). That means that single features can be detected in parallel, but combinations of two (or more) different features results in a serial scan. Therefore, in a complex scene eye search is serial by nature.
1.2.4 Overt and Covert Attention
Figures 1.2 and 1.3 illustrate the fact that the HVS has the ability of information selection within a scene, and the location attended shifts from one to another. After an interesting region is selected by the attention mechanism, its saliency will decrease along with the novelty being weakened because an inhibitive signal from higher areas returns, so the location of the next salient location replaces the current attention focus. This ability of the HVS is called attention shift [35, 38]. The shifting attention involves the eye movement to the positions in the visual field as shown in Figures 1.2 and 1.3. Eye movement occurs typically about 3–5 times/per second. Some attention shifts do not depend on eye movement, which is usually observed when the viewers look at an object or attend to an event out of the corner of their eye or by intentionally using the visual periphery. For example, a scatterbrained student sitting in the classroom uses their eyes' periphery to attend to the bird out of window while their eyes still face the blackboard. Such attention shift in the absence of eye movement is frequent. If two objects in a scene need to be attended at the same time, a viewer has to employ attention without eye movement to track the second object, since your eyes cannot fixate two different locations simultaneously.
We call the visual attention associated with eye movement as overt attention, and the attention shift independent of eye movement as covert attention. With covert attention, it is not necessary to move the eyes or the head to concentrate on the interesting regions, so it is quicker than overt attention. Covert attention and overt attention can be studied separately, but in most cases both attentions often work together. As eye fixation is easy to be observed with measurement equipment, most studies of visual attention have been concerned with overt attention so far.