
5.6 Hybrid Model of Bottom-up Saliency with Top-down Attention Process
Another top-down model with learning function and visual memory is proposed in [18, 59–63]. In its bottom-up saliency map, symmetry is considered as a low-level feature. The four conspicuity maps in the model: intensity, colour, orientation and symmetry are generated, and processed by independent component analysis (ICA) [64, 65] in order to reduce redundancy. The visual memory that stores the top-down knowledge adopts a fuzzy adaptive resonance theory (ART) neural network with learning function [66]. The pattern input to the fuzzy ART neural network comprises the conspicuity maps from the bottom-up processing before ICA filtering. There are two fuzzy ART networks to memorize the knowledge about the objects: the reinforced part and the inhibited part. In the training stage, the conspicuity maps in the most salient area, computed by the pure bottom-up model, are given as inputs of the fuzzy ART network. Depending on the label that the supervisor gives to a salient area, as an interesting or unwanted area, the features are given as inputs to the reinforced or the inhibited part, respectively. Thereby, the fuzzy ART network memorizes the features of both interesting and unwanted areas in the training stage. Thus, in the testing stage, it becomes easy to decide whether a new salient area is interesting to the supervisor or not, based on the top-down information. The model is easily realized in the real world because the top-down attention shares its features with the bottom-up processing. The precision of the saliency map of an interesting object is higher than the other pure bottom-up models due to the top-down influence. This model has been extended to dynamic image saliency and stereo saliency [18, 61], and applied to object recognition and detection [60, 62].
5.6.1 Computation of the Bottom-up Saliency Map
Natural and artificial objects often give rise to the human sensation of symmetry, which is important in the context of the free search problem [67]. In computer vision research, symmetry of an object's shape has been suggested as one of the fundamental properties. Considering that the primary cortex and the LGN in the human visual pathway are used to detect the edge and shape (symmetry) of an object, this bottom-up computation uses symmetry as a low-level feature.
As described in Chapter 3, the low-level features – intensity (I), colour opponent (R/G, B/Y) and edge (E) – are extracted from an input image by the filtering and down-sampling operations to create four Gaussian pyramids. The edge feature is related to the object shape and can be obtained by any edge-detection filter. Using the centre–surround difference (CSD) of different scale maps in each pyramid, the difference maps for four channels (intensity, two colour opponents and edge) with different scales are created, and the difference maps are normalized as introduced in Section 3.1.
The diverse orientation features are calculated from the edge difference maps by using a Gabor filter bank, and the symmetry feature is computed from orientation information with the aid of a neural network that modifies Fukushima's neural network [68] to get a symmetry axis [61]. After uniting the two colour opponent channels into one colour channel and integrating the diverse orientation channels to one orientation, the cross-scale combination generates four conspicuity maps (CMs) denoted intensity(![]() ), orientation (
), orientation (![]() ), colour (
), colour (![]() ) and symmetry (
) and symmetry (![]() ).
).
The following operation uses ICA to reduce the redundancy in the four conspicuity maps. The ICA filters are learned from large numbers of image samples with 7 × 7 × 4 pixels randomly taking in the four CMs. For the image patches with the size of 7 × 7 pixels each for the four conspicuity maps construct a sample called a patch group. The basis vectors are determined by using the information maximization algorithm [65] from 20 000 samples. After training, 196 basis vectors representing 196 ICA filters are obtained, the length of each filter being 7 × 7 × 4 pixels. The saliency map of pure bottom-up attention is the summation of the convolution between the patch group and these ICA filters:
(5.32) ![]()
where SM(x, y) is the salient value located at (x, y), ![]() is the image patch group at (x, y) and
is the image patch group at (x, y) and ![]() is the ith ICA filter. The computational process of a bottom-up saliency map is shown in the left rectangular block with dashed lines in Figure 5.9. The bold line with arrows from the top (input image) to the bottom (saliency map SM) represents the computational flow of the bottom-up saliency map.
is the ith ICA filter. The computational process of a bottom-up saliency map is shown in the left rectangular block with dashed lines in Figure 5.9. The bold line with arrows from the top (input image) to the bottom (saliency map SM) represents the computational flow of the bottom-up saliency map.
Figure 5.9 Hybrid model of bottom-up and top-down. The left block with dashed line is the bottom-up part and the right block with dashed line is the top-down part
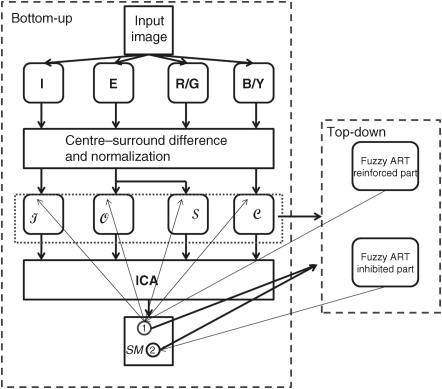
The presented model differs from other bottom-up computational models due to the additional symmetry feature and the ICA processing of the conspicuity maps. The experimental results in the papers [59–61] demonstrate the efficiency of the symmetry feature and the ICA filters which helps in focusing on an object area in a visual search.
5.6.2 Learning of Fuzzy ART Networks and Top-down Decision
In the model, the top-down knowledge or top-down cue is stored in a fuzzy ART network which is biologically plausible with STM and LTM visual memory and can be easily trained for additional input patterns [66, 69, 70]. An introduction to the ART network will be given below for understanding of the presented model.
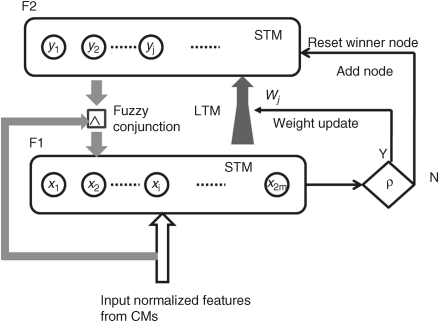
The ART network consists of two layers: input layer F1 and output layer F2. Every layer consists of several neural nodes as shown in Figure 5.10. The connection weights from all the nodes in F1 to each node in F2 are denoted by Wji ∀ i, j, where i is the index of the input node and j is the index of the output node. The feature values of the salient area on the bottom-up saliency map are obtained by back search from the corresponding location of the four conspicuity maps (the thin line with an arrowhead from area 1 on the saliency map to the maps, ![]() ,
, ![]() ,
, ![]() and
and ![]() shown in Figure 5.9). These feature values are normalized to [0, 1], denoted as (a1, a2, . . . am), and are given as an input pattern to the F1 layer. If the pattern consists of m feature values, then the number of nodes in F1 layer is 2m corresponding to the m features (a1, a2, . . . am) and their complements (1 − a1, 1 − a2, . . . 1 − am). The 2m-dimensional pattern is denoted as Ipat. When the pattern is given as an input to the F1 layer, a preliminary choice among the nodes in F2 layer by fuzzy conjunction between F1 and F2 is executed, resulting in one current winner node in F2 layer with the weight vector Wj
shown in Figure 5.9). These feature values are normalized to [0, 1], denoted as (a1, a2, . . . am), and are given as an input pattern to the F1 layer. If the pattern consists of m feature values, then the number of nodes in F1 layer is 2m corresponding to the m features (a1, a2, . . . am) and their complements (1 − a1, 1 − a2, . . . 1 − am). The 2m-dimensional pattern is denoted as Ipat. When the pattern is given as an input to the F1 layer, a preliminary choice among the nodes in F2 layer by fuzzy conjunction between F1 and F2 is executed, resulting in one current winner node in F2 layer with the weight vector Wj ![]() R2m, if the jth node in F2 is winner. The match of the input pattern and the current winner weight vector is measured by
R2m, if the jth node in F2 is winner. The match of the input pattern and the current winner weight vector is measured by
Figure 5.10 Fuzzy ART network
(5.33) ![]()
where symbol ∧ is fuzzy conjunction. The match measurement determines whether the current winner weight needs to be modified (the pattern is memorized in the weights) or the winner node should be moved. Two cases are considered: (1) if ![]() > threshold (ρ) the current winner weight vector is updated and the pattern is stored in the weight vector as an LTM; (2) otherwise, the current winner node is reset, and the new winner node will be found in F2 layer. If none of the nodes in the F2 layer can satisfy case (1), then a raw node is added in F2 layer, and this means that a new class appears. The structure and connections of the fuzzy ART network are set out in Figure 5.10. In the hybrid computational attention model there are two fuzzy ART networks to represent the top-down information: reinforced ART and inhibited ART, shown in the right-hand block of Figure 5.9. The whole work of this hybrid computational attention is expressed as follows.
> threshold (ρ) the current winner weight vector is updated and the pattern is stored in the weight vector as an LTM; (2) otherwise, the current winner node is reset, and the new winner node will be found in F2 layer. If none of the nodes in the F2 layer can satisfy case (1), then a raw node is added in F2 layer, and this means that a new class appears. The structure and connections of the fuzzy ART network are set out in Figure 5.10. In the hybrid computational attention model there are two fuzzy ART networks to represent the top-down information: reinforced ART and inhibited ART, shown in the right-hand block of Figure 5.9. The whole work of this hybrid computational attention is expressed as follows.
In the ART training process, a supervisor decides whether the salient area on the bottom-up saliency map is an interesting area or an unwanted area. If the salient area is an interesting area, the pattern in the attention area inputs to the reinforced fuzzy ART network to memorize the interesting pattern. Contrarily, the pattern of the unwanted area is memorized in the inhibited fuzzy ART network.
For the testing image, if a salient area selected by bottom-up saliency computation has similar characteristics to those in the reinforced ART network, the area is enhanced. Contrarily, when the similarity between characters of the salient area and those stored in the inhibited ART network is high, the area will be suppressed. Consequently, the model can focus on a desired attention area and ignore the unwanted areas.
As discussed above, in the model, the process of the top-down part (fuzzy ART network) is almost the same in the training and test stages, and the top-down information is very easy to influence on the bottom-up saliency map through the choice of reinforced or inhibited parts in the visual memory. This model has been extended to depth perception when two hybrid computational models corresponding to two cameras (left and right eyes) are adopted [18, 61]. The stereo saliency map and binocular fixation are estimated in the extended model. Besides, the model can be extended to the computation of dynamic and static saliency maps [61]. These extended hybrid models have been applied to many object detection and recognition areas in diverse environments [60, 62].