
3.3 Variations and More Details of BS Model
There have been lots of variations for the original baseline saliency (BS) model since 1998. Some of them change certain details in the BS model, when it is used in object recognition and computer vision of robot and so on. From the core of the BS model in Figure 3.1 the model can be divided into four main steps after image input:
Besides the four main steps, the winner-take-all (WTA) neural network connecting to the saliency map and the inhibition of return (IoR) are necessary in some applications, which was not discussed in Section 3.1. The framework of original BS with WTA is described in Figure 3.4.
Figure 3.4 Framework of BS with WTA and IoR

We will introduce first the variations to the BS model in Section 3.3.1, and then WTA and IoR in Section 3.3.2.
3.3.1 Review of the Models with Variations
There are many models with meaningful changes in each step (as mentioned above) of the original BS model. For the variations to the BS model to be discussed here, we will not address the different parameter selection for the filters in Section 3.1 because these are straightforward. We review the more significant variations as follows.
Alteration in Step 1
Alteration in Step 2
Alteration in Step 3
Alterations in Step 4
3.3.2 WTA and IoR Processing
Steps 1–4 in Figure 3.4 acquire a topographical map (saliency map) to guide the attention direction, whereas attentional focus at a particular time only falls on the most salient region in the saliency map and the fixation will shift to the next most salient region after a while, and the process repeats (please refer to eye movement as mentioned in Chapter 1). How to find the current most salient spot in the saliency map and how to determine the next fixation in other places are important issues in a computational visual attention model. In Figure 3.4, a WTA neural network block and IoR feedback path are added to the saliency map, which simulate the attentional focus and eye movement.
WTA processing is to map a set of input units from the saliency map onto corresponding outputs by using the following transformation:
where ![]() is the input set,
is the input set, ![]() is the output set, and f(ui) is a constant or increasing function. It is obvious that after WTA processing, the output of a maximum input unit is non-zero and all other units' outputs are set to zero. The processing of Equation 3.23 needs to compare the two values of a pair, many times in a serial fashion, which is not in line with the mechanism in our brain. One idea for completing WTA in a parallel fashion is to use a neuron network with a 2D structure, where each neuron receives the output from the corresponding place in the saliency map (the value on each pixel of the saliency map is inputted to a neuron) and suppresses all other neurons by mutual inhibitory weights. The WTA network implementation satisfies:
is the output set, and f(ui) is a constant or increasing function. It is obvious that after WTA processing, the output of a maximum input unit is non-zero and all other units' outputs are set to zero. The processing of Equation 3.23 needs to compare the two values of a pair, many times in a serial fashion, which is not in line with the mechanism in our brain. One idea for completing WTA in a parallel fashion is to use a neuron network with a 2D structure, where each neuron receives the output from the corresponding place in the saliency map (the value on each pixel of the saliency map is inputted to a neuron) and suppresses all other neurons by mutual inhibitory weights. The WTA network implementation satisfies:
where ![]() is the output of the ith neuron in the WTA network at time (t + 1), ui(t) denotes input of the neuron from saliency map, wij is the connected weights between the outputs of the neuron at location i and location j; wij < 0; here the monotonic increasing function f(ui) is defined above a positive threshold value. Unfortunately, the neural network with full inhibitory connections is unstable, since several local maxima exist in the neural network that cannot guarantee to converge to a correct and unique solution in all input cases [1]. A pyramid structure WTA network was proposed by Koch and Ullman in 1985 [1], in which the WTA involves a small neuronal group including two neurons and forms a multilayer pyramid. Figure 3.5 shows a binary pyramidal structure of WTA, in which the signals of the saliency map (greyscale values) are inputted to the corresponding neurons of the first level of the pyramid as shown in Figure 3.5. The top layer is the saliency map obtained after the four-step processing of Figure 3.4. The WTA pyramid is from the second layer to the bottom neuronal unit.
is the output of the ith neuron in the WTA network at time (t + 1), ui(t) denotes input of the neuron from saliency map, wij is the connected weights between the outputs of the neuron at location i and location j; wij < 0; here the monotonic increasing function f(ui) is defined above a positive threshold value. Unfortunately, the neural network with full inhibitory connections is unstable, since several local maxima exist in the neural network that cannot guarantee to converge to a correct and unique solution in all input cases [1]. A pyramid structure WTA network was proposed by Koch and Ullman in 1985 [1], in which the WTA involves a small neuronal group including two neurons and forms a multilayer pyramid. Figure 3.5 shows a binary pyramidal structure of WTA, in which the signals of the saliency map (greyscale values) are inputted to the corresponding neurons of the first level of the pyramid as shown in Figure 3.5. The top layer is the saliency map obtained after the four-step processing of Figure 3.4. The WTA pyramid is from the second layer to the bottom neuronal unit.
Figure 3.5 Schematic drawing of WTA pyramidal network to compute the maximum value and to find the most salient location on the saliency map
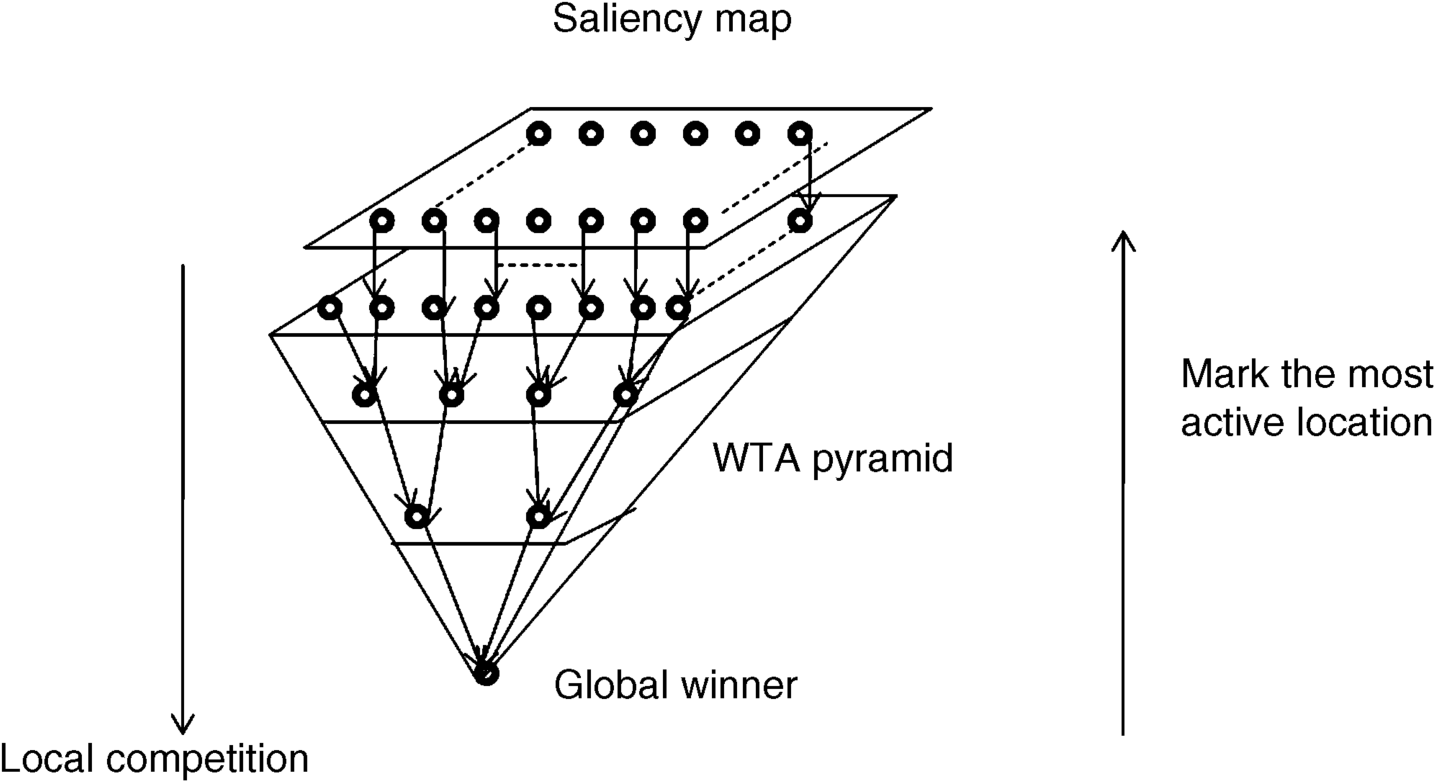
In the WTA network, each pair of neurons at the first pyramidal level competes with each other, and the output of the neuron with maximum value is sent to the next level in the WTA pyramid. It is noteworthy that the competition between two neurons is easy and convergent. This operation goes on from the first pyramidal level, second pyramidal level, . . . . The global maximum propagates in this way to the top of the pyramid. After finding the winner, the information on the winner will go back to its previous pyramidal level along the winner's path until it terminates at the first pyramidal level, and then the location of the most active neuron in the first level of pyramid is marked. Owing to the one-to-one relationship between the first pyramidal level and the saliency map, the marked location is the focus of attention on the saliency map. Figure 3.5 illustrates the downward computational processing of the WTA pyramidal levels, and the backward process is simplified as the direction of an arrow. As well as the WTA network in Figure 3.5, there are other WTA algorithms such as the multiscale version [30], integrate and fire neurons [2] and so on. We will not introduce these one by one.
The attentional focus shift depends on the IoR processing that is presented in Figure 3.4. The most salient location should decay with the aid of an inhibitory signal after a while or after the object in the focus of attention has been processed. In that time the saliency map with the degenerated winner unit as the new input retransfers to the WTA network. Then a new focus is found by the WTA network. The process will continue until going through all the local maxima in the saliency map. Note that the IoR signal cannot forever stay at one location of the saliency map. After a period, the inhibitory signal is released from the saliency map, and these salient locations that have been focuses of attention at one previous time or another, will be re-attended as new visual focuses. The operation of WTA and IoR in Figures 3.4 and 3.5 simulate the phenomenon of attentional focus shifts that have been discovered by psychologists.
In the original BS model, the WTA has some differences from the process stated above, and its saliency map is a 2D array composed of leaky integrate-and-fire neurons with a strong inhibitory population at scale 4 [2]. Each neuron includes a capacitance, a leakage conductance and a voltage threshold. The capacitor of each neuron integrates the charge from its input and then its action potential rises. When the action potential exceeds the threshold, the charge on the capacitor is shunted to zero by its parallel conductance, resulting in a spiking signal. This is like the spiking encoder part in Figure 2.13. For the most salient location on a saliency map, its corresponding neuron will first fire (as the winner cell) because its input value is the largest and the inhibitory synaptic interaction will make only the neuron at the most salient location survive. The focus of attention will shift to the winner location. It is noticed that the firing neuron will avoid the unstable case in Equation 3.24, because only the first firing neuron can suppress other neurons by the inhibitory connections at that time and other neurons without firing are unable to influence the winner.
In the original BS model, the focus of attention on the saliency map is a disk area [21]. The IoR is the same as [12] after the winner selection, but here the inhibitory signal is to suppress all the neurons within the focus of the attention region (disk). In succession, the calculation in the 2D neuronal array with suppressed region can detect the next firing neuron's location that guides the focus shift.
In the practice of object search and recognition, the object's size in the scene is important information. Itti et al.'s BS model did not consider the issue. A method of estimating the attentional region that approximates to the object's size is proposed in [5] while trying to implement the BS model for object recognition. Its idea is to find one feature map that is the most contributive to the most salient location on the saliency map. Let the winner location be (![]() ) on the saliency map, the traced back path is first to find one with maximal contribution at the winner location of the saliency map among the conspicuity maps. Let
) on the saliency map, the traced back path is first to find one with maximal contribution at the winner location of the saliency map among the conspicuity maps. Let ![]() denote the value at the winner location (
denote the value at the winner location (![]() ) of conspicuity map
) of conspicuity map ![]() , and the index of the conspicuity map with maximal contribution is:
, and the index of the conspicuity map with maximal contribution is:
where the argmax function is implemented by two means in [5]: one is the neural network of the linear threshold units (LTUs), which has higher computational complexity, and the other is the image processing method which simply takes the conspicuity map with maximal contribution to the saliency map at the winner location as the winning conspicuity map ![]() .
.
In the selected conspicuity map ![]() , one feature map with the most contribution at the winner location can be found:
, one feature map with the most contribution at the winner location can be found:
where ![]() is the feature map in channel kw at centre scale q and surround scale (q + s) that is coherent with Equation 3.9a,
is the feature map in channel kw at centre scale q and surround scale (q + s) that is coherent with Equation 3.9a, ![]() is the value at the winner location, (
is the value at the winner location, (![]() ), on the feature map
), on the feature map ![]() . When the winning feature map is detected, a binary version can be computed in the winning feature map by the following equation:
. When the winning feature map is detected, a binary version can be computed in the winning feature map by the following equation:
where (x, y) is the pixel's coordinate in the winning feature map. Collection of the B(x, y) for all (x, y) forms a binary image B. Finally, these active pixels (B(x, y) = 1) is labelled to some regions by the four-connected neighbourhood (marked connectivity in the binary image can implement the bwlabel function in MATLAB®) [5]. The region including the winner location (![]() ) in B is an object candidate area, and these pixels in above region are labelled to one. The background and other labelled regions are set to zero. This process can be expressed as
) in B is an object candidate area, and these pixels in above region are labelled to one. The background and other labelled regions are set to zero. This process can be expressed as
The image Bm is used to segment the object from the winning feature map. In the same manner, it can mark the salient region, matching the object in the saliency map more accurately than the fixed disk area taken in Itti's BS model while being resized to the same size. When Bm is adapted to the original image size, the marked extent exactly matches the object for further recognizing tasks. In addition, the inhibition of return from Bm is sent to the saliency map and suppresses the salient region, and then the next salient location can be found by the WTA operation. The flow chart of estimating the extent of the attended object is shown in Figure 3.6, which emphasizes the traced back process.
Figure 3.6 Illustration of the traced back process for obtaining the attentional regions

In Figure 3.6, the location (xw, yw) on the block of the saliency map is the current attention focus, two arrowheads towards the conspicuity maps denote that the location information is sent to the conspicuity maps for competition. The winner conspicuity map transmits the information to its feature maps to get the winning map (in the top-left of Figure 3.6). The segmentation processing (Equations 3.27 and 3.28) is implemented in the winning map to obtain the segmentation map Bm. The black ellipse in Bm of the figure denotes the size of the object for object recognition when it is scaled up to the same size as the input image. At the same time an IoR signal is sent to the saliency map in order to avoid re-winning in the next period. (The ellipse at location (xw, yw) in Figure 3.6).
3.3.3 Further Discussion
A more biologically plausible model for realizing Equations 3.25–(3.28) is proposed in [5], in which the WTA of the saliency map is the same as the BS model by competition between neuronal units that are named linear threshold units (LTU); the difference is that a feedback unit in an LTU at the most salient spot receives an excitatory signal and the output of the unit is transferred to the related location in the conspicuity maps. The competition of WTA between conspicuity maps (Equation 3.25) uses the LTU network that includes four units with inhibitory and excitatory synapses at corresponding spots of each conspicuity image, to compute the argmax function in Equation 3.25. In the selected conspicuity map, the competition of WTA between feature maps (Equation 3.26) is used with a similar LTU network to get the winning feature map with the largest contribution to the saliency map of this location [5]. The segmentation operation is implemented by another recurrent network of LTUs, in which each location includes four working units (representing the activity, selecting signal from the argmax function, receiving inhibition from neighbouring units, and combining excitatory and inhibitory signals into output activity, respectively) and some inter-neurons. Each unit in the LTUs has itself a function from input to output. It can implement Equations 3.27 and 3.28 by a complex dynamic process of units in the neural network. The LTU strategy is biologically plausible because it tries to simulate neuronal activity in the brain, but its calculation is too complex to be implemented for engineering applications. Therefore, we do not present it here in detail. If readers are interested in this please refer to [5].
Both the algorithms presented in Section 3.3.2 (for fast image processing) and the LTU network version mentioned above have been well formularized so they are easy to program. In fact, the C++ code of the algorithm presented in Section 3.3.2 can be found at [15] as a part of the iLab neuronorphic vision Toolkit (iNTV), while a MATLAB® code for the fast image processing method and its LTU network is available in [31]. Since the website of [31] includes a combining word ‘slaienttoolbox’, it is referred to as the STB model in some literature.