
4.4 Phase Spectrum of the Quaternion Fourier Transform Approach
In the case of multiple channels, PFT can be easily extended to a phase quaternion Fourier transform (PQFT) approach if multidimensional data at each pixel can be represented as a quaternion [5, 6]. The quaternion is a mathematical tool in multidimensional signal processing [28]. In later discussion, we will see that the use of the quaternion in the visual attention model has somewhat biological reason.
4.4.1 Biological Plausibility for Multichannel Representation
Most of the spatial domain models consider several low-level features as different feature maps or channels, which are coincident with physiological results. Let us recall the cells in the low-level visual cortex. Several simple cells that are close together share a receptive field in the input scene. These simple cells extract different features in the receptive field such as intensity, colour, orientations and so on, which can be simulated by a neural network [29]. Figure 4.7 gives a sketch of receptive fields and their related simple cells, where visual input is regarded as the input image or retina of the eye, and the ellipses on the visual input are these overlapped receptive fields that cover the whole visual input. Each receptive field is related to a cell set in a row-dashed block or to same location (one pixel) of many feature images. In Figure 4.7 we only draw the receptive fields on one side of the visual input. In each row-dashed block of this figure there are five cells that represent five different kinds of low-level features that share the same receptive field. It should be noted that the number of features is not fixed to five here. Figure 4.7 leads to two ways of representing multichannel signal processing in the brain. One is the same as spatial domain models that are based on separate features, and the other is based on the cells sharing the same receptive field. In the frequency domain, the two representations conduct two kinds of method.
Figure 4.7 Receptive fields and their related simple cells

In the former representation, we consider that the cells at the same location of all row line boxes extract the same feature from the visual input as shown in the right of Figure 4.7. For example, if the first cell in row line boxes is in charge of extracting the intensity feature, then all the first cells of the row line boxes will form a plane parallel to the visual input and construct an intensity feature image pI. In this manner, several parallel feature maps can be regarded as several feature channels similar to the spatial domain model. For an input RGB (red-green-blue) colour image, the intensity feature at location (x, y) can be written as
where ![]() ,
, ![]() and
and ![]() are three colours at pixel (x, y). Equation 4.17 is the same as Equation 3.1 in the BS model. In the same way, the second and third cells in all the row line boxes construct colour opponent feature images (channels) pRG and pBY and so on. The pRG and pBY can make use of broadly tuned colour as Equations 3.2, 3.3 or 3.4 in Chapter 3. The multichannel SR or PFT use this way to calculate a conspicuity map for each channel (pI, pRG and pBY, etc.) by Fourier and inverse Fourier transform respectively, and then to sum the conspicuity maps of all the feature channels together, obtaining the final saliency map. Figures 4.4 and 4.6 are the results of using this representation to calculate the final saliency map.
are three colours at pixel (x, y). Equation 4.17 is the same as Equation 3.1 in the BS model. In the same way, the second and third cells in all the row line boxes construct colour opponent feature images (channels) pRG and pBY and so on. The pRG and pBY can make use of broadly tuned colour as Equations 3.2, 3.3 or 3.4 in Chapter 3. The multichannel SR or PFT use this way to calculate a conspicuity map for each channel (pI, pRG and pBY, etc.) by Fourier and inverse Fourier transform respectively, and then to sum the conspicuity maps of all the feature channels together, obtaining the final saliency map. Figures 4.4 and 4.6 are the results of using this representation to calculate the final saliency map.
However, the simple summation of these separate conspicuity maps is probably not reasonable. There is no evidence in physiological experiments to support the idea: the contribution of conspicuity map for each channel is equal. Especially, the normalization of the conspicuity map of each channel is actualized independently. An alternative representation considers the cells that share the same receptive field (the cells in the row-dashed block of Figure 4.7) as a unit, and all the computation is carried out for these units. The reason why it can do this is based on the premise that the simple operation of the PFT approach is very easy to extend the computation from scalar to multiple dimensions. In addition, there is a mathematical tool for multidimensional signal processing, called quaternion or hypercomplex number to represent these units. The algorithm based on units is the phase spectrum of quaternion Fourier transform (PQFT) already mentioned. In order to understand the PQFT algorithm, a brief introduction to quaternion follows.
4.4.2 Quaternion and Its Properties
Complex numbers have been widely applied to mathematics, physics and engineering because multiplication of complex numbers is achieved as a whole unit with a rule for the product of two numbers together. In 1843, Hamilton proposed a way for triple-number multiplication and created the quaternion [28]. Later, various works on mathematics introduced the algebra of the quaternion [30].
Definition A quaternion includes one real number and three imaginary numbers that can be represented as
(4.18) ![]()
where μi, i = 1, 2, 3 is the imaginary axis, a is the real part, Re(q) = a, b, c and d are the imaginary parts,
The quaternion has many properties and rules for calculation of itself that are discussed separately in other books. Here we only list some useful rules for the PQFT approach.
Properties
![]()
(4.20) ![]()
(4.22) ![]()
(4.23) ![]()
(4.24) 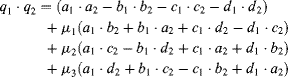
4.4.3 Phase Spectrum of Quaternion Fourier Transform (PQFT)
We will now extend the PFT approach in a single channel to multiple channels by using quaternions. As with the PFT, the PQFT model has four steps: (1) quaternion representation of the input image, that constructs a quaternion image: the data on each pixel of the input image are represented as a quaternion that consists of colour, intensity and motion features. When the motion feature is included in the quaternion, the PQFT can obtain a spatiotemporal saliency map; (2) perform a quaternion Fourier transform for the quaternion image and compute its modulus and eigenangle of each quaternion spectral component; (3) set the modulus for all frequency components to unity and maintain their eigenangles, and then recover the image from the frequency domain to the spatial domain by inverse quaternion Fourier transform; (4) post-process the recovered image by using a low-pass Gaussian filter and get the spatiotemporal saliency map. The detailed analysis and equations are shown as follows.

(4.27) ![]()
(4.28) ![]()
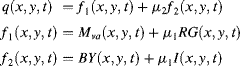
(4.39) ![]()
(4.41) ![]()
(4.43) ![]()
4.4.4 Results Comparison
The computational cost of PQFT is mainly due to the quaternion Fourier transform. As stated in [43], PQFT's computational complexity is based on the real multiplication process and can be expressed as 4MN·log2MN if the input image has M × N pixels. Considering the other aspects causing computational cost such as building the quaternion, changing the quaternion to Cayley–Dickson form and the equivalent complex numbers, transferring the frequency components into polar form and so on, the cost of PQFT is slightly higher than PFT and SR. However, it can still meet the requirements for real-time applications. To compare the PQFT model with other computational models fairly, five computational models (two spatial domain models and three frequency models), and two different types of test dataset, used in [6] and [2, 3], are selected. One of them is a video of 15 frames per second which consists of 988 frames with a resolution of 640 × 480 pixels. And the other one is a dataset of 100 natural images with the resolution around 800 × 600 pixels. For the still images from the dataset of natural scenes, the real part of the quaternion is set to zero in the PQFT model since there is no information for motion in still images. The testing results based on the average computation time showed that PQFT is third among the five models. Table 4.2 demonstrates the average time cost (seconds) per frame or image for the two testing sets. It is worth noting that the original BS model (NVT) is implemented in C++ and other four models are coded by MATLAB® [6].
Table 4.2 Average time cost per frame in test video and per image in natural image set [6]. © 2010 IEEE. Reprinted, with permission, from C. Guo, L. Zhang, ‘A Novel Multiresolution Spatiotemporal Saliency Detection Model and its Applications in Image and Video Compression’, IEEE Transactions on Image Processing, Jan. 2010.
| Models | Time Cost (s) for Video | Time Cost (s) for Image |
| PQFT | 0.0565 | 0.0597 |
| PFT | 0.0106 | 0.0099 |
| SR | 0.0141 | 0.0159 |
| BS (NVT) | 0.4313 | 0.7440 |
| STB | 3.5337 | 4.7395 |
The computational attention models in the frequency domain are faster than those in the spatial domain (see Table 4.2). The PFT model is the fastest and the SR model takes the second. PQFT in the MATLAB® version still meets real-world (16–17 f/s) notwithstanding its third rank. Although the BS model with C++ code is the fastest among the spatial domain models, its processing time is only around 2–3 f/s which is slower than the frequency-based approaches in average regarding the overall datasets.
The results of performance comparison among the five computational models in [6] showed that the PQFT model is better than the other four models for the two testing sets. Since a quantitative index is not involved now, which will be discussed in Chapter 6, we only give the following three intuitive examples (psychological pattern, the pattern with repeating texture and a man-made object image of a city) in order to compare PQFT and the other frequency models (SR and PFT).
Example 4.1 Psychological pattern
In the top left of Figure 4.8 (the original pattern) a horizontal red bar (the target) is located among the many heterogeneous vertical red bars (distractors). All three frequency models (PQFT, PFT and SR) can pop out the target (the top row of Figure 4.8) in their saliency maps. Although in the PQFT model the target does not stand out from the distractors, the detection result for the region of interest is still satisfactory. However, the original psychological pattern in the bottom left of Figure 4.8 is a red inclined bar (target) among many heterogeneous inclined green bars (distractors), and also some distractors may have the same or similar orientation as the target. Even in these conditions, PQFT can highlight the target. On the other hand, PFT and SR fail in their saliency map, as shown in the bottom row of Figure 4.8. This is because PQFT considers all features as a whole, while PFT and SR process their features separately, which may lose some information.
Example 4.2 Pattern with repeating texture
As mentioned above, the SR model cannot suppress the repeating texture that expresses the peaks in the amplitude spectrum, but these peaks are just redundancy in the scene. Figure 4.9(a) illustrates an array of vertical bars with an absent location. The human can rapidly find the absent location as the salient object. Both PQFT and PFT can detect the location in their saliency map as the human does (Figures 4.9(b) and (c)), but SR fails in this case since the locations with vertical bars and the location without a bar are all enhanced in their saliency. The absent location cannot be detected by the SR model.
Figure 4.8 Saliency maps of three frequency models for two psychological patterns (where the psychological patterns are from http://ilab.usc.edu/imbibes). Reproduced with permission from Laurent Itti, ‘iLab Image Databases,’ University of Southern California, http://ilab.usc.edu/imgdbs (accessed October 1, 2012)

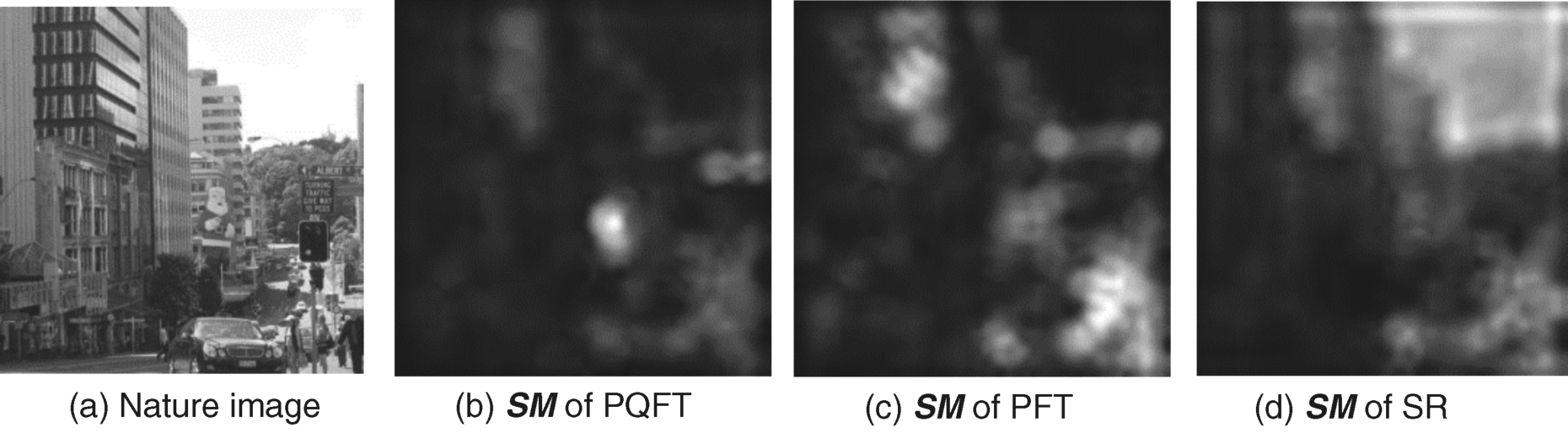
Example 4.3 Image of a city scene
Figure 4.10(a) displays the black and white version of a colour city image in which a striking statue of Father Christmas dressed in red stands up near several high buildings. In general, people first shift their focus to the statue of Father Christmas. The saliency map of the PQFT model gives the same focus (Figure 4.10(b)). However, PFT and SR lose the important object since the reflected light of the glass curtain wall on the high building or the bright sky are enhanced in the separately processed intensity channel and the colour channels, and their saliency maps give prominence to these unimportant areas (Figure 4.10(c) and (d)).
Figure 4.9 Saliency maps of three frequency models for pattern (64 × 64 pixels) with repeating texture

Figure 4.10 Saliency maps of three frequency models for a natural image within a city scene
4.4.5 Dynamic Saliency Detection of PQFT
In PQFT the motion feature represented by the real part of the quaternion only considers the difference between two successive frames. That is, only absolute motion is considered as introduced in Section 3.2. However, since motion features often include background motion such as camera motion, absolute motion in Equation 4.30 is not helpful in some cases. In the frequency domain, background motion can be separated by utilizing phase correlation [44], which provides the motion vector for translational motion. Let Ic and Ip be the current and previous intensity frames, and Fc and Fp be their Fourier transform, respectively. The equation to calculate the phase correlation of successive frames is
where ![]() is the inverse Fourier transform, (
is the inverse Fourier transform, (![]() ) denotes global motion (background motion) between the successive frames and
) denotes global motion (background motion) between the successive frames and ![]() is the conjugate complex of Fp. The phase difference of two spectra denotes the global displacement. Given (
is the conjugate complex of Fp. The phase difference of two spectra denotes the global displacement. Given (![]() ) by computing Equation 4.44, the two successive frames are shifted by the global motion to compensate for the camera motion. The new motion feature in the quaternion is the difference between the shifted frames. A qualitative comparison of the simple difference frame and the difference frame with motion compensated is shown in Figure 4.11.
) by computing Equation 4.44, the two successive frames are shifted by the global motion to compensate for the camera motion. The new motion feature in the quaternion is the difference between the shifted frames. A qualitative comparison of the simple difference frame and the difference frame with motion compensated is shown in Figure 4.11.
Figure 4.11 Comparison of PQFT without and with motion compensation. (a) motion frame with moving pedestrians; (b) difference frame with camera shake; (c) compensated difference frame; (d) saliency map of motion channel of (b); (e) saliency map of motion channel of (c) [45]. With kind permission from Springer Science + Business Media: Lecture Notes in Computer Science, ‘Biological Plausibility of Spectral Domain Approach for Spatiotemporal Visual Saliency’, 5506, © 2009, 251–258, Peng Bian and Liming Zhang

It is obvious that the saliency map of the compensated difference frame is better at popping out moving pedestrians. The phase correlation method (Equation 4.44) can also be used in other frequency domain models such as PFT, SR and the models introduced in the following sections of this chapter.
In summary, PQFT, as with PFT, sets the amplitude spectrum to a constant (one) while keeping the phase spectrum in the frequency domain, implements the inverse Fourier transform and post-processes the recovered image in the spatial domain to finally obtain its saliency map. The difference is that PQFT is based on a quaternion image; that is all the features in each pixel of the image are combined in a quaternion. This kind of whole processing method is similar to the structure of the primary visual cortex in the brain. The mathematical tool and properties of quaternion give PQFT better performance than PFT or SR. However, the quaternion may suffer from its computational complexity. Its computational speed is five times slower than PFT. Even so, PQFT is still a good choice in many engineering applications because it can meet the real-time processing requirement for image coding or robot vision.