
Clustering is an unsupervised machine learning type of analysis. Although we don't know in general what the best clusters are, we can still get an idea of how good the result of clustering is. One way is to calculate the silhouette coefficients as defined in the following equation:
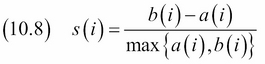
In the preceding equation, a(i) is the average dissimilarity of sample i with respect to other samples in the same cluster. A small a(i) indicates that the sample belongs in its cluster. b(i) is the lowest average dissimilarity of i to other cluster. It indicates the next best cluster for i. If the silhouette coefficients s(i) of a sample is close to 1, it means that the sample is properly assigned. The value of s(i) varies between -1 to 1. The average of the silhouette coefficients of all samples measures the quality of the clusters.
We can use the mean silhouette coefficient to inform our decision for the number of clusters of the K-means clustering algorithm. The K-means clustering algorithm is covered in more detail in the Clustering streaming data with Spark recipe in Chapter 5, Web Mining, Databases and Big Data.
- The imports are as follows:
import dautil as dl from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score from sklearn.metrics import silhouette_samples from IPython.display import HTML
- Define the following function to plot the silhouette samples:
def plot_samples(ax, years, labels, i, avg): silhouette_values = silhouette_samples(X, labels) dl.plotting.plot_text(ax, years, silhouette_values, labels, add_scatter=True) ax.set_title('KMeans k={0} Silhouette avg={1:.2f}'.format(i, avg)) ax.set_xlabel('Year') ax.set_ylabel('Silhouette score') - Load the data and resample it as follows:
df = dl.data.Weather.load().resample('A').dropna() years = [d.year for d in df.index] X = df.values - Plot the clusters for varying numbers of clusters:
sp = dl.plotting.Subplotter(2, 2, context) avgs = [] rng = range(2, 9) for i in rng: kmeans = KMeans(n_clusters=i, random_state=37) labels = kmeans.fit_predict(X) avg = silhouette_score(X, labels) avgs.append(avg) if i < 5: if i > 2: sp.next_ax() plot_samples(sp.ax, years, labels, i, avg) sp.next_ax().plot(rng, avgs) sp.label() HTML(sp.exit())
Refer to the following screenshot for the end result:

The code is in the evaluating_clusters.ipynb file in this book's code bundle.
- The Wikipedia page about the silhouette coefficient at https://en.wikipedia.org/wiki/Silhouette_%28clustering%29 (retrieved November 2015)
- The
silhouette_score()function documented at http://scikit-learn.org/stable/modules/generated/sklearn.metrics.silhouette_score.html (retrieved November 2015)