
Domain-specific languages, DSLs for short, are computer languages used to solve problems within the explicit boundaries of the problem domain. The benefits of DSLs are multiple: They help by separating domain-related code from application code; they let domain experts solve problems using a language they understand; they can have multiple outputs, and users can easily shift from one to another; and last but not least, designing domain-specific languages usually tighten relations between programmers and experts. This gem will dig into domain-specific languages, answering the following questions: What is a DSL? When should I use a DSL? How do I build a DSL?
In this section we’ll explore DSLs and their uses, concluding with some guidance on when to use them.
Several definitions have been proposed for domain-specific languages. DSLs can be defined as artificial languages expressing instructions to a machine while working on a narrow field of expertise, a specific domain. These computer languages are sometimes referred to as little languages or micro-languages because of the limited expressivity of their syntaxes. Their syntaxes are restricted to the problem domain they are modeling, including only what is relevant to the problems. Languages such as C, C++, or Java, which are labeled general programming languages, or GPLs, provide generic solutions to a broad range of problems and, as such, can be opposed to DSLs that provide more tailored solutions to a restricted set of problems.
Domain-specific languages have existed for a long time, and their use in computer science is widespread. Successful examples include Lex and Yacc, programming languages intended to create lexers and parsers to help in building compilers; SQL, a computer language targeted at relational databases; and LaTeX, a document markup language providing a high-level abstraction of TeX. DSLs have several characteristics emerging from their form and the process used to build them. The main characteristic of DSLs is their syntaxes, which provide appropriate notations to the domain model and a very limited set of instructions. This limits what problems users can solve but at the same time allows the language to be learned quickly. DSLs are also usually declarative. They can sometimes be viewed as specification languages, providing domain experts with the capability of writing specifications that will become new tools, solve problems, and encode domain knowledge. Because they encode domain knowledge as perceived by domain experts, DSLs are usually built from a user perspective. Such a user-centric process tries not to take into account external factors, such as compiler capabilities, and prefers focusing on user experience.
Data mining is a domain that could be used as an example illustrating how domain-specific languages help. Code to search for persons matching certain criteria in tables can be written in any GPL, but it is much easier to write with a language that is appropriate to the domain. Listings 4.9.1 and 4.9.2 show SQL and C++ code snippets that provide the same feature to an application. Even if C++ is more adequate on a general basis, it does not focus on the domain and thus is harder to use in this specific case than SQL.
Example 4.9.1. Mining a table for persons named Paul in SQL
Select users from table where name='Paul'
Example 4.9.2. Mining a table for persons named Paul in C++—relying on the STL to handle allocations and strings manipulation
std::list<CUser>::const_iterator const table_end = table.end();
std::string SearchedName("Paul");
for(std::list<CUser>::iterator it = table.begin();
it != table_end;
++it)
{
if (it->Name == SearchedName)
{
users.push_back(*it);
}
}Another interesting feature these two listings exhibit is the differences in term of interface. While GPLs provide a satisfying interface for programmers, some DSLs provide very light syntaxes nearly exempt from notations that do not translate into everyday language, dropping parentheses, braces, and any other artifact as much as possible. These notations are referred to as language noise, and programming interfaces that minimize this noise are called fluent interfaces. Domain-specific languages do not always provide a fluent interface to their users, but this can be a useful feature to provide when end users do not have a programming background.
While GPLs are usually classified by their programming paradigm and the type of output produced by their compilers, domain-specific languages are distinguished by the methods used to build them. As such, two main categories are emerging—internal DSLs, sometimes referred to as embedded DSL, and external DSLs.
When a DSL provides a custom syntax and relies on a custom-made lexer, parser, and compiler, it is categorized as an external DSL. Building an external DSL is the same process as building a new general-purpose language: Programmers have to design the language and implement it as well as any needed tools, such as editors, parsers, compilers, and debuggers. On the other hand, internal DSLs are built from general programming languages that offer syntaxes malleable enough to build new language from them. This greatly reduces the amount of work needed to implement the language as programmers rely on the existing tool chain and language’s features. On the down side, internal DSLs’ syntaxes usually include language noise from their host language.
In addition to these two categories, DSLs are also often classified by the type of interface they provide to end users. While some DSLs are created by programmers to be used by other programmers, others are designed to be used by domain experts who do not have programming experience. Thus, some DSLs provide textual interfaces, but other DSLs adopt graphical front ends in order to ease programming. An example of a successful visual domain-specific language is Unreal Engine’s Kismet, which allows designers to control actions and handle events by connecting boxes using the graphical user interface provided by Unreal Editor.
Domain experts may not be able to write code but are usually able to review code written using domain-focused syntaxes. DSL code can sometimes even be written directly by domain experts, achieving end user programming. DSLs concentrate on domain knowledge, and thus it is important that coders creating new DSLs deeply understand the problem domain. As a side effect, this usually tightens relations between programmers and domain experts, resulting in more accurate solutions.
The limited expressiveness of DSLs limits user input and, as such, can help to reduce user errors. DSLs are easier to master, and as interfaces become more fluent, the code starts to be self documenting.
Through these characteristics, DSLs are able to express important information while hiding implementation details. Just like good APIs, DSLs provide users the ability to program at a higher level of abstraction. This leads to a clear separation between domain knowledge and implementation that allows for better conservation and reuse of this knowledge.
Finally, DSLs provide new opportunities to do error checking, statistical analysis, or any other transformation of the domain knowledge.
There are also several drawbacks to using domain-specific languages. The most problematic is the cost of building and maintaining a new language. While building external DSLs still requires quite a bit of effort, new tools and new techniques have been used to reduce these costs. Another alternative is to embed the DSL in a host language. As the language evolves and requirements change, language maintenance can become a burden. It can be very tempting to grow the problem domain by adding new keywords and notations, but this usually leads to building general-purpose languages with some domain-specific keywords. This is a very costly approach and should be avoided unless it is desired. Another drawback of using multiple languages to build an application is that programmers need to learn more than a few languages to control the whole pipeline, and thus they need to quickly learn and adapt. One last problematic aspect of using domain-specific languages is that it introduces an extra layer of complexity, which can slow the debugging process.
Game development provides a wide variety of challenges in many different domains. To take up these challenges, programmers usually use a few general-purpose languages and build frameworks that will help resolve domain-related issues. DSLs appear to be a good fit to this environment. Typical examples of problem domains related to video games are game logic, navigation, animation, locomotion, data modeling, serialization, and transport. Thinking in terms of modeling problem domains and user experience helps to define what solutions are needed.
Creating new languages is a difficult and time-consuming task, so deciding when to use a DSL is a very important process. The need for a domain-specific language usually arises when a common pattern is detected from several problems. Those patterns can occur at code level, in programs, subroutines, or data, as well as at the application level, building similar tools or architecture several times. The problem domain can usually be identified from these patterns, and the boundaries of the domain can then be determined. Domain-specific languages stress staying domain-focused, so it is important to deeply understand the domain’s definition. If the boundaries are blurry and users can’t anticipate requirements, then it may be impossible to design the language. It is important to carefully choose the bounds because if they are too narrow, the DSL won’t be used to encode enough domain language, whereas if they are too broad, the language may lose its focus. Boundaries also influence the language interface by defining which variants are to be exposed to the user. Exposing too many variants will slow language learning, while not exposing enough will render it less usable. Domain experts, documentations, and specifications can help determine such boundaries.
Lastly, because creating a new language is a difficult task, it is important to know whether such a language will be reused. If the problem domain is too narrow and domain knowledge should be encoded only once, it may be better to build a framework over a general-purpose language, but if domain knowledge needs to be encoded multiple times, solve multiple issues, or requires a lot of effort to be encoded using a GPL, then creating a new domain-specific language may be a good option.
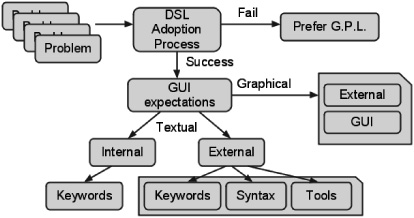
Figure 4.9.1 depicts part of the decision process.

The process applied when creating a domain-specific language can be summed in six steps, as illustrated by Figure 4.9.2.

We start with the problems that must be solved to meet our goals. As stressed earlier, it is important to be able to detect recurrent patterns coming from different problems because it will lead to the identification of a problem domain. If patterns are detected soon enough, the domain can be examined, and new problems may be anticipated. The second step is to acquire as much knowledge about the domain as possible. Documentation and domain experts are the best sources of domain knowledge and will be able to explain what users expect from the domain. This leads to a user-centric approach and designing the language from a user perspective. The last step before designing the language is to choose between internal and external DSLs and the type of interface the language will provide to the end user. Interfaces are usually driven by the domain model to represent end user ability to use graphical and textual interfaces. In the language design phase, the specifications of the language are laid down. Notations and keywords needed to model the domain are chosen, and variants—what the interface will show—and invariants—what assumptions about the model will be hidden in the implementation—are identified. Lastly, all tools required to implement the language are created.
Determining the user interface of a new language is a decisive factor for its adoption as a new tool. By understanding what users are expecting from the tool, programmers will be able to refine the required features.
If the domain can be modeled using text, then both internal and external DSLs can satisfy the needs, and choosing between them is a matter of understanding their constraints along with the programming proficiencies of the end user. Internal DSLs rely on the availability of a host language that is malleable enough to let a DSL emerge from its own syntax. When such a language is available, its syntax and tool chain will influence the look and feel of the DSL. If those constraints are acceptable, then building an internal DSL is the quickest way to create a new textual DSL, as it will provide needed tools for the language. On the other hand, external DSLs do not rely on another language, allowing for a better customization of their syntaxes. But they also require that programmers build tools such as parsers, interpreters, or compilers to support the new language. If no host language that satisfies syntax needs is available, then external DSLs are the way to go.
While some domains are very easy to model using words, other domains cannot be modeled, or at least are difficult to model, using text. In this case, the domain-specific language can rely on a graphical interface to help end users encode their knowledge. Another factor for building a graphical front end to the DSLs is the programming background of their users. Some DSLs are intended for non-programmers, and if the domain is too complex and thus requires exposing too many variants and keywords, it will then probably be easier for the user to represent the domain knowledge using graphical tools. Although graphical DSLs are usually built from scratch, some tools do exist that help in creating them.
Figure 4.9.3 synthesizes the whole process.
As domain-specific languages become more and more popular, several programming patterns used to build them emerge. Luckily, most programming tips used to build domain-specific languages are easy to understand and use, but some may not be available from all host languages.
The first, and probably oldest, technique is the use of macros. It has been widely used by C and C++ developers to pre-process source code. It uses the preprocessor capabilities to build fluent interfaces that generate complex code at pre-processing time.
Another old and widely available technique is called function sequencing. Domain knowledge is encoded using sequences of function calls. The implementation of this method relies heavily on the side effects of each function to affect the execution context of each subsequent call. While this method provides a potentially acceptable solution in terms of interface, relying on side effects can be dangerous and hard to debug as sequences become more and more complex. Listing 4.9.3 shows an example of function sequencing.
Example 4.9.3. Function sequencing
animation_engine();
character_controller();
playanimation("run_fast");
easing_in_using(LINEAR_EASE_FUNCTION);
during(10_MSEC);An evolution of function sequencing is called method chaining. It uses objects to pass the context between calls without adding noise to the language. With this technique, each method call returns an object that provides a part of the language interface. This helps to fragment the interface across multiple types of objects. Rewriting the previous example using method chaining leads to Listing 4.9.4.
Example 4.9.4. Method chaining
animation_engine().
character_controller().
playanimation("run_fast").
easing_in_using(LINEAR_EASE_FUNCTION).
during(10_MSEC);Nested functions are another way to call functions while removing language noise as much as possible. When using this method, all calls are nested, as presented in Listing 4.9.5. The main characteristic of nested functions is the order in which functions get called. It can be very useful when domain knowledge can be expressed as a sum of properties and containers.
Example 4.9.5. Nested functions
character_controller(
playanimation(
"run_fast",
easing_in_using(LINEAR_EASE_FUNCTION),
during(10_MSEC) ) )Another frequently used technique for building domain-specific languages on top of an existing framework is to separate the fluent interface from the existing API. Fluent interfaces are usually created using assumptions about the calling context of their routines. Although this helps naming methods that chain efficiently and produce nearly fluent code, this way of writing an API violates what is considered good programming practices. Thus, it may be interesting to get the best of both worlds by adding a fluent interface on top of a more standard framework.
Lambda functions, sometimes named blocks, anonymous methods, or closures, are a feature that only recently became widespread in many mainstream languages. They have been successfully applied to creating DSLs because they offer the key characteristic of evaluating code, with minimal language noise, in a predetermined context. Lambda functions are very similar to a standard method definition but do not require the same textual overhead as functions: They do not need to have names, complete parameter lists, and return types and are simply associated to standard variables that can be passed across functions.
The dynamic handling of missing methods is another widespread technique to create domain-specific languages. It is a popular feature of languages such as Smalltalk and Ruby, where you can override doesNotUnderstand and method_missing, respectively. Other languages, such as Python, can provide similar features using other internal mechanisms. Handling missing keywords can be very convenient when the language has to deal with unknown keywords and unknown function names. This technique allows the user to create keywords as needed. It allows creating new modeling languages with very little noise very easily.
Example 4.9.6. Animation DSL relying on method_missing, nested function, and closures
1: animset = define_animation_set( :terrestrial_locomotion) {
2: idle(from_file("tm_idle"))
3: run_forward from_file "tm_run_fwrd"
4: walk_forward from_file "tm_wlk_fwrd"
5: turn_90degsLeft from_file "tm_trn_90deg"
6:
7: jump_forward from_file "tm_jmp_fwrd"
8: jump_forward { can_blend_with all_from("terrestrial_locomotion") }
9: jump_forward { can_blend_with transitions_from("aerial_locomotion")
10: }Listing 4.9.6 shows a domain-specific language where animation identifiers are keywords chosen by the user and thus impossible to predict. It demonstrates usage of blocks and nested functions using the Ruby programming language. The code block is written between brackets and, in our example, it is given to the define_animation_set function. In this domain-specific language, define_animation_set creates an animation set object and asks Ruby to evaluate the given block in the context of this object. The animation set object interface will provide functions such as from_file, which is used to load an animation from a given filename. In order to reduce language noise, the language relies on the ability of Ruby to deduce parentheses placement. Lines 2 and 3 are similar and interpreted the same way by the Ruby language, the only difference coming from parentheses’ presence. Lastly, Ruby handles function calls such as idle or run_forward as missing calls that are handled by our implementation to identify new animations. A sample demonstrating how Listing 4.9.6 is implemented using the Ruby programming language is provided on the accompanying CD-ROM.
Another easy and very powerful technique to add meaning to code is called literals extension and is usually available from object-oriented languages. Extending literals helps readers by allowing modifiers, which may or may not do anything useful, to be used on literals in order to add fluency to the code. It requires the language to handle everything, including literals, as objects that can call methods. Literal extension also relies on the ability of the language to reopen and extend class definitions.
One last technique worth mentioning is abstract syntax tree and parse tree manipulations. It is a rare feature allowing programmers to access the parse tree or the abstract syntax tree after the code has been parsed by the host-language parser. Ruby’s ParseTree and C# 3.0 both work in a similar function; a library call is used to parse a code fragment and return a data structure representing the code expressions. This feature is useful when translating code from one language to another or when the DSL needs to rely on a wider range of expression than happens to be available in the host language and thus needs to be transformed before use.
External domain-specific languages have fewer constraints than internal ones but need slightly more effort to create because of the time required to build parsers and compilers. Luckily, tools have been created to ease this process and reduce this overhead.
Lexical analyzers and parser generators, such as Lex and Yacc, have been around for a long time and are still a great help to build languages, but they tend to be replaced by new tools, such as ANTLRWorks or Microsoft’s DSL tools, which are both providing powerful development environments focused on creating domain-specific languages. ANTLRWorks is an integrated development environment for creating languages using ANTLR V3 grammars. It offers rapid iteration cycles by providing a full-featured editor, embedding an interpreter, and providing a debugger and a lot of other tools to ease the development process. While ANTLRWorks uses textual grammars to create external textual DSLs, Microsoft’s DSL tools provide a way to create visual domain-specific languages to be integrated into Microsoft Visual Studio. The Microsoft DSL tools help design the language and its graphical interface by providing wizards and tools easing domain modeling, specifying classes and relationships, and binding designers’ shapes to the model concepts. Although Microsoft’s tools for domain-specific languages can’t be used for building run-time DSLs, they offer opportunities for integrating a custom visual domain-specific language inside Visual Studio.
This section presents domain-specific languages for two domains related to low-level engine programming. Other examples of DSLs for game engines are shading and rendering passes, sound logic encoding emitters, occluders and propagation logic, behaviors of artificial agents, and locomotion rules for animation systems.
The first example of a domain-specific language in a game engine relates to data structure modeling. Data management issues occur in many places, such as a pipeline’s applications intercommunication, engine working set, multi-threading and performance issues, and network replication. A common problem is the need to write data manipulation and serialization code multiple times. Thus, it may be interesting to encode as much knowledge about data structures as possible using a domain-specific language that handles tasks such as generating code for serializing and accessing data in all languages used in the pipeline. Such a DSL could also allow for statistical analysis of working sets, which would help profile the engine’s need in terms of data.
Acquiring knowledge about the domain of data management is easy because programmers are the domain experts. This type of DSL should solve data-related problems by providing a simple syntax to encode the data structures’ layout. The language will encode structures and should provide end users with a way to control fields’ identification, alignment properties, and serialization requirements. Lastly, this domain-specific language will be used by programmers, and thus it is acceptable to use a textual interface with low language noise. Listing 4.9.8 shows a sample of such data management DSL using Ruby as its host language. You can find an implementation of this DSL on the CD-ROM.
Example 4.9.8. Simple structure layout using a domain-specific language
struct (:PlayerInfos) {
required string :name, replicate_over_network!
required key :race
required boolean :is_male
required int32 :level
required int32 :exp_points
required vector3f :position, replicate_over_network!, 16.bytes.alignment
required quaternion :orientation, replicate_over_network!
optional int32 :money
optional float :reputation
}The second use case for domain-specific languages targets the engine’s threading model. Scalability of the engine’s performance over machine generations has become a very active field of research. Console engines usually take advantage of running on fixed hardware with known specifications, but good engines must allow evolution of hardware. A recurring pattern when changing hardware is to rewrite the threading model to reflect new hardware and get better performance. Another pattern related to threading models happens during development when programmers try to offload heavy tasks from one processor to another, thus changing how tasks update. Again, a language focused on task dependencies and hardware specifications can help handling modifications of the threading model. Such a language has to expose to the user variants such as number of cores, number of threads per core, or preferred number of software threads. It can also expose tasks that are run by the engine and their dependencies in order to help scheduling given the hardware constraints. The output of such a language can be either code or data that would drive current engine’s threading framework. Like the previous domain-specific language presented, this language is targeted at programmers, and an internal DSL’s properties satisfy our requirements. Listing 4.9.9 shows what such a DSL could look like, and its implementation is provided on the accompanying CD-ROM.
Example 4.9.9. Threading a domain-specific language
hardware {
has 3.cores.each { |core| core.have 2.hardware_threads }
}
software do
instanciate 6.software_threads
instanciate :camera.module
instanciate :player.module, :bots.module, :sound.module
instanciate :physics.module, :graphics.module
camera.depends_on(:player)
bots.depends_on(:player)
graphics.is_bound_to(thread(0))
endWe will now focus on how DSLs integrate in the production pipeline.
The quickest and easiest way to integrate a domain-specific language into an engine is to directly embed it. As such, creating an internal DSL that relies on the engine’s main language seems to be an evident way to provide domain-specific languages from the game engine. But, with C++ being the preferred language for building game engines, it is difficult to provide a domain-specific language that allows for rapid iterations. C++ provides a very strict syntax, and most of the advanced features used to build DSLs are difficult, if not impossible, to use. Another problem of relying on C++ to build an internal DSL is the compilation process that may disturb domain experts without any programming background. However, C++ provides macros, nested functions, method chaining, and templates that are powerful tools for building fluent interfaces.
Developers who create DSLs using C++ as a host language must be careful about build times, ease of debugging, and code bloat, as many of the aforementioned techniques can lead to these problems if not used properly.
Integrating a DSL that relies on a language other than the one used by the engine is made possible by using DSLs as application generators. In this case, the domain-specific language is used to input domain knowledge and transform these high-level specifications to low-level code that will be included in the engine. This approach provides the same advantages as any other code generation technique: End users can easily input data without worrying about the implementation, programmers can modify an implementation without the user noticing, and code need only be optimized once per code generator.
Although this technique has the advantage of separating the domain-specific language from the language used to implement the engine, it has the major drawback of increasing the complexity of the build process.
An example of DSL relying on code generation is Unreal Script, as it binds scripts to native classes by generating C++ headers. Although this is very convenient for debugging and for very tight integration into the engine, it requires script programmers to be really careful when modifying scripts, because it may trigger a full rebuild of the engine. When using this code generation technique, developers must try to reduce compilation and link time as much as possible.
DSLs can also be integrated into the engine by using a virtual machine that will read and execute domain-specific code at run time. Embedding virtual machines for languages such as Lua or Python has been a popular method for years, and it is possible to build internal DSLs on top of such languages. Another path is to create an external DSL and embed its virtual machine inside the engine, like [Gregory09] and [Sweeney06]. This integration method has the advantage of removing any constraint previously imposed by the engine’s language and also helping reduce iteration cycles, but it sacrifices run-time performances.
Independent of building your own virtual machine or using a preexisting one, it is crucial to provide tools that will assist the debugging phase, since this new language will add an extra layer of complexity.
An interesting way to integrate DSLs in an engine is a hybrid approach where DSL code can be either compiled to machine code or interpreted by a virtual machine. Although such an approach requires substantial effort to write compilers and interpreters, it would provide the best of both worlds, allowing for fast iteration during development and maximizing release build performance.
Tools are crucial to overcome debugging issues, but developers need to also care about the execution environment of scripts, as it will change when going from interpreted to compiled. The quickest way to set up this hybrid approach for game engines is to create an internal DSL using an already available interpreter, such as Lua, Python, Lisp, or Ruby, and bind it to the native engine’s framework. Code generation routines should be written in the host language and used to translate DSL code to native code relying on the engine’s framework.
Tools that help domain experts input their knowledge into the pipeline usually provide an interface relying on domain-specific languages. Tools providing DSLs integrated into game pipelines are very common. Unreal Engine provides Kismet for scripting game events [Unreal05], Crytek’s CryENGINE offers Flow Graph—a visual editing system allowing designers to script game logic [Crytek09]. Other examples exist in the field of artificial intelligence [Borovikov08].
DSLs let users encode domain knowledge using custom syntax and usually help centralize this knowledge. As a side effect, it can be very interesting to use DSLs not only to encode domain knowledge, but also to distribute it to any application of the production pipeline, easing knowledge transfer across multiple languages and applications. For example, tools such as Google’s protocol buffers or Facebook’s thrift provide domain-specific languages that ease data transfer across complex application architectures, which are very similar to game pipelines.
Domain-specific languages have been around for a long time and are successfully employed to solve a wide variety of problems throughout the software industry. They offer tailored solutions, are easy to learn and manipulate, enable various opportunities to mine the knowledge they encode, and focus on end user experience. It is still difficult to reduce the costs associated with creating and learning several languages, but because video game development addresses such a wide range of problem domains, it seems to be a perfect fit for domain-specific languages.