
Jean-François Dubé, Ubisoft Montreal
Nowadays, multi-core computers (and game consoles such as the Microsoft Xbox 360 and Sony PlayStation 3) are very common. Programmers are faced with the challenges of writing multi-threaded code: data sharing, synchronization, deadlocks, efficiency, and scalability. Adding multi-threading to an existing game engine is an enormous effort and might give an initial speed gain, but will it run twice as fast if you double the number of cores? What if you run it on a 16+ cores system, such as Intel’s Larrabee architecture? Will it be able to run on platforms with co-processors, such as Sony’s PlayStation 3?
In this gem, we’ll see how to write efficient and scalable multi-threaded code. The first section will deal with the “efficiency” part of the problem, while the second part will deal with the “scalability” part.
Multi-threaded programming introduces a variety of issues the programmer must be aware of in order to produce code that performs the required operations correctly. Additionally, certain operations can lead to additional overheads in a multi-threaded program. In this section we’ll look at high-performance methods for resolving these issues.
The main problem with multi-threaded programming is concurrent access to the same memory locations. Consider this simple example:
uint32 IncrementCount()
{
static uint32 Count=0;
return Count++;
}This is commonly translated into three operations: a load, an addition, and a store. Now, if two threads execute this function slightly at the same time, what will happen? Here’s an example:
Thread 1 read Count and store it into register R1 Thread 1 increment R1 Thread 2 read Count and store it into register R1 Thread 2 increment R1 Thread 1 store the value of R1 into Count Thread 2 store the value of R1 into Count
If Count was originally 5 before this sequence of events, what will be the result afterward? While the expected value is 7, the resulting value would be 6, because each thread has a copy of Count in its register R1 before it was actually updated to memory. This example is very simple, but with more complex interactions this could lead to data corruption or invalid object states. This can be fixed by using atomic operations or by using synchronization primitives.
Atomic operations are special instructions that perform operations on a memory location in an atomic manner; that is, when executed by more than one core on the same memory location, it is guaranteed to be done atomically. For example, the InterlockedIncrement function could be used in the previous example to make it thread-safe and lock-free.
A very useful atomic operation is the Compare And Swap (CAS) function, implemented as InterlockedCompareExchange on Windows. Essentially, it compares a value with another and exchanges it with a third value based on the outcome of the comparison, atomically. It then returns the original value before the swap. Here’s how it can be represented in pseudocode:
uint32 CAS(uint32* Ptr, uint32 Value, uint32 Comperand)
{
if(*Ptr == Comperand)
{
*Ptr = Value;
return Comperand;
}
return *Ptr;
}This atomic operation is very powerful when used correctly and can be used to perform almost any type of operation atomically. Here’s an example of its usage:
uint32 AtomicAND(volatile uint32* Value, uint32 Op)
{
while(1)
{
uint32 CurValue = *Value;
uint32 NewValue = (CurValue & Op);
if(CAS(Value, NewValue, CurValue) == CurValue)
{
return NewValue;
}
}
}In this example, we read the current value and try to exchange it with the new value. If the result of the CAS returns the old value, we know that it wasn’t changed during the operation and that the operation succeeded. (It was swapped with the new value.) On the other hand, if the result is not equal to the old value, we must retry, since it was changed by another thread during the operation. This is the basic operation on which almost all lock-free algorithms are based.
Sometimes, atomic operations are not enough, and we need to be able to ensure that only a single thread is executing a certain piece of code. The most common synchronization primitives are mutexes, semaphores, and critical sections. Although in essence they all do the same thing—prevent execution of code from multiple threads—their performance varies significantly. They are kernel objects, which means that the operating system is aware when they are locked. Therefore, they will generate a costly context switch if already locked by another thread. On the other hand, most operating systems will make sure the thread that has a critical section locked will not be preempted by another thread while it holds the lock. So using those primitives depends on a lot of factors: the time span of the lock, the frequency of locking, and so on.
When locking is required very frequently and for a very low amount of time, we want to avoid the overhead from operating system process rescheduling or context switching. This can be achieved by using a spin lock. A spin lock is simply a lock that will actively wait for a resource to be freed, as seen in this simplified implementation:
while(CAS(&Lock, 1, 0)) {}What it does is simple: It uses the CAS function to try to gain access to the lock variable. When the function returns 0, it means we acquired the lock. Releasing the lock is simply assigning 0 to the Lock variable.
A real implementation of a spin lock usually should contain another waiting loop that doesn’t use atomic functions to reduce inter-CPU bus traffic. Also, on some architectures, memory barriers are required to make sure that the state of the Lock variable is not reordered in some ways, as seen in the next section. The complete implementation is available on the CD.
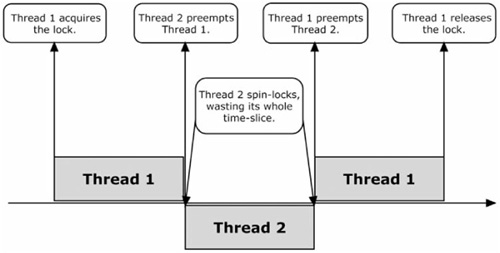
On architectures that don’t change a thread’s affinity (in other words, that don’t reschedule threads on different processors, such as Xbox 360), running several threads on the same core competing for a shared resource using a spin lock is a very bad idea. If the lock is held by a thread when it gets interrupted by the operating system scheduler, other threads will be left spinning trying to acquire the lock, while the thread holding it is not making progress toward releasing it. This results in worse performance than using a critical section, as shown in Figures 4.3.1 and 4.3.2.

Memory can be read and written in a different order than written in your code for two main reasons: compiler optimizations and hardware CPU reordering. The latter differs a lot depending on the hardware, so knowing your architecture is important. See [McKenney07] for a detailed look at this problem.
Consider the following pieces of code running simultaneously:
Thread 1 | Thread 2 |
|---|---|
|
|
|
|
While this looks completely fine and will almost always work when running on a single core depending on the compiler optimizations, it will probably fail when running on different cores. Why? First, the compiler will most likely optimize the while loop and keep ValueIsReady in a register; therefore, declaring it as volatile should fix the problem on most compilers. Second, due to out-of-order memory accesses, ValueIsReady might get written first; therefore, Thread 2 can read GlobalValue before it is actually written by Thread 1. Debugging this kind of bug without knowing that memory reordering exists can be long and painful.
Three types of memory barriers exist: read, write, and full barriers. A read memory barrier forces reads from memory to complete, while a write memory barrier forces writes from memory to complete, so other threads can access the memory safely. A full memory barrier is simply forcing both reads and writes to complete. Some compilers will also correctly handle reads and writes of volatile variables by treating them as memory barriers (Visual Studio 2005 for instance, as described in [MSDN]). Also, some of the Interlocked functions come with the Acquire and Release semantics, which behave like read and write barriers, respectfully.
The previous example can be solved by using a write memory barrier before setting ValueIsReady to ensure that the write to GlobalValue actually gets written before ValueIsReady, ensuring that other threads will see the new GlobalValue before ValueIsReady is written.
Most multi-core architectures have a per-core cache, which is generally organized as an array of memory blocks, each with a power of two size (128 bytes, for example), called cache lines. When a core performs a memory access, the whole line is copied into the cache to hide the memory latency and maximize speed. False sharing occurs when two cores operate on different data that resides in the same cache line. In order to keep memory coherency, the system has to transfer the whole cache line across the bus for every write, wasting bandwidth and memory cycles. The solution to this problem is to make sure that the data is structured in a way that avoids this problem.
Memory allocators can rapidly become a bottleneck in multi-threaded applications. Standard memory allocator implementations provided in the C run time (malloc/free) or even optimized and widely used allocators, such as Doug Lea’s dlmalloc [Lea00], aren’t designed to be used concurrently; they need a global lock to protect all calls, which inherently leads to false sharing. The design of a multi-processor’s optimized memory allocator is beyond the scope of this gem, but a good comparison of available multi-processor allocators can be found in [Intel07].
When a thread is idle, it is important that it doesn’t waste CPU cycles. Here’s some code we often see from a person writing multi-threaded code for the first time:
while(!HasWork())
{
Sleep(0);
}The Sleep(0) will make the thread give up the remainder of its time slice for other threads, which is fine. But, when it gets rescheduled, it will loop back, unnecessarily wasting CPU time (and multiple context switches) until it has work to do. A better solution is to put the thread in sleep mode, waiting for an event. This is achieved by using the CreateEvent and WaitForSingleObject functions. Waiting for an event essentially tells the operating system scheduler that the thread is waiting and shouldn’t get any CPU time until the event is triggered.
It is possible to declare per-thread global variables using Thread Local Storage (TLS). The declaration differs from compiler to compiler, but here’s how it works under Visual Studio:
__declspec(thread) int GlobalVar;
Each thread now has its own GlobalVar variable copy. This can be especially useful for per-thread debugging information (such as the thread name, its profiling stats, and so on) or for custom memory allocators that can operate on a per-thread basis, effectively removing the need for locking.
A good introduction to such things is discussed in detail in [Jones05] and [Herlihy08]. Essentially, these algorithms are pieces of code that can be executed by multiple threads without locking. This can lead to enormous speed gain for some algorithms, such as memory allocators and data containers. For example, a lock-free queue could need to be safe when multiple threads push data into it, while multiple threads also pop data at the same time. This is normally implemented using CAS functions. A complete implementation is available on the CD.
The most common way to rapidly thread an existing application is to take large and independent parts of the code and run them in their own thread (for example, rendering or artificial intelligence). While this leads to an immediate speed gain and lots of synchronization problems, it is not scalable. For example, if we run an application using three threads on an eight-core system, then five cores will sit idle. On the other hand, if the application is designed from the start to use small and independent tasks, then perfect scalability can be achieved. To accomplish this, several options already exist, such as the Cilk language [CILK], which is a multi-threaded parallel programming language based on ANSI C, or Intel’s Threading Building Blocks [TBB]. An implementation of a simple task scheduler is presented next.
The required properties of our scheduler are:
Handle task dependencies.
Keep worker threads’ idle time at a minimum.
Keep CPU usage low for internal task scheduling.
Have extensibility to allow executing tasks remotely and on co-processors.
The scheduler is lock-free, which means that it will never block the worker threads or the threads that push tasks to it. This is achieved by using fixed-size lock-free queues and a custom spin lock and by never allocating memory for its internal execution.
A task is the base unit of the scheduler; this is what gets scheduled and executed. In order to achieve good performance and scalability, the tasks need to be small and independent. The (simplified) interface looks like this:
class Task
{
volatile sint* ExecCounter;
volatile sint SyncCounter;
public:
virtual void Execute()=0;
virtual sint GetDependencies(Task**& Deps);
virtual void OnExecuted() {}
}A task needs to implement the Execute function, which is what gets called when it is ready to be executed (in other words, no more dependencies).
To expose dependencies to the scheduler, the GetDependencies() function can be overloaded to return the addresses and the number of dependent tasks. A base implementation that returns no dependencies is implemented by default.
A task is considered as fully executed when its Execute function has been called and when its internal SyncCounter becomes zero. The ExecCounter is an optional counter that gets atomically decremented when the Execute function is called. For tasks that spawn sub-tasks, setting the sub-task’s ExecCounter pointer to the parent’s SyncCounter ensures that their OnExecuted functions will only be called when all sub-tasks have been executed.
The scheduler automatically creates one worker thread per logical core. Figure 4.3.3 illustrates how the worker threads behave: Each worker thread is initially pushed in a lock-free queue of idle threads and waits for a wakeup event. When a new task is assigned to a worker thread by the scheduler, it wakes up and executes the task. Once the task is done, the worker thread does several things. First, it tries to execute a scheduling slice (which will be explained in the next section) by checking whether the scheduler lock is already acquired by another thread. Then, it tries to pop a waiting task from the scheduler. If a task is available, it executes it, and the cycle restarts. On the other hand, if no tasks are available, it pushes itself in the lock-free queue of idle threads and waits for the wakeup event again.

The scheduler is responsible for assigning tasks to the worker threads and performing tidying of its internal task queues. To schedule a task, any thread simply needs to call a function that will push the task pointer in the lock-free queue of unscheduled tasks. This triggers a scheduling slice, which is explained next.
At this point, pending tasks are simply queued in a lock-free queue, waiting to be scheduled by the scheduler. This is done in the scheduling slice, which does the following, as described in Figure 4.3.4:
Register pending tasks.
Schedule ready tasks.
Delete executed tasks.

During this phase, the scheduler pops the pending tasks and registers them internally. Then, it needs to handle dependencies. If a task is dependent on previously scheduled tasks, it goes through the dependencies and checks to see whether they have been executed. If that’s the case, the task is ready to execute and is marked as ready. Otherwise, the task is kept as pending until the next scheduling slice.
The second phase of the scheduling slice is to assign tasks that are ready to be executed to worker threads. The scheduler first tries to pop an idle thread from a lock-free queue of idle threads. If it succeeds, the task is directly assigned to that thread, and the thread waiting event is signaled. If all threads are working, the task is queued in the lock-free queue of waiting tasks. The scheduler then repeats the process until there are no more tasks to assign.
The last phase of the scheduling slice handles the tasks that are considered fully executed by calling the OnExecuted function on them and by deleting them if they are marked as auto-destroy; some tasks may need to be manually deleted by their owner, as they might contain results, and so on.
Since tasks are usually independent from each other, the scheduler can be extended to support execution of tasks on remote computers or on architectures with co-processors. To achieve this, each task would have a way to package all the data it needs to execute. Then, the scheduler would dispatch the task to other computers or co-processors though a simple protocol. Compilation of the Execute function might be required to target the co-processor’s architecture. When a completed task message arrives, the task would then receive and unpackage the resulting data. This could be used as a distributed system (such as static lighting/normal map computations, distribution of the load of a game server to clients, and so on) or as a way to distribute work on the PlayStation 3 SPUs automatically.
The single task queue could become a bottleneck on systems with a large number of cores or ones that have no shared cache between all cores. Here, using per-worker thread task queues along with task stealing could prove advantageous. Furthermore, the scheduling could be made more cache friendly through a policy of inserting newly created tasks into the front of the worker thread’s queue that generated the task, as these are likely to be consuming the data generated by the task that created them. All of these optimizations depend on the target architecture details.
As we have just seen, the scheduler is completely lock-free; its internal CPU usage is kept to a minimum, the worker threads are either executing a task or waiting for one, and most of all, it scales with the number of cores. The complete source code on the CD comes with several sample tasks that have been tested on a Intel Core 2 Quad CPU running at 2.83 GHz, with the following results (also see Figure 4.3.5):

Fibonacci Sequence | Perlin Noise | QuickSort | |
|---|---|---|---|
1 thread | 1.05ms | 9.06s | 9.30s |
2 threads | 0.29ms | 4.55s | 4.84s |
3 threads | 0.22ms | 3.03s | 3.44s |
4 threads | 0.15ms | 2.29s | 2.74s |
5 threads | 0.14ms | 2.21s | 2.81s |
6 threads | 0.12ms | 2.31s | 2.86s |
The Fibonacci sequence test has been created to see how dependencies are handled. The Perlin noise test, on the other hand, has been implemented to see how performance and scalability can be achieved; the test consists of computing a 2048 × 2048 Perlin noise grayscale image with 16 octaves. The QuickSort test consists of sorting 65 million random integers. As we can see, the expected scalability is achieved for all of these tests.