
5.3 Computational Model under Top-down Influence
As stated earlier, it is not very clear how top-down knowledge is represented and how visual attention is influenced by top-down knowledge in the brain. However, many psychophysical experiments have validated that the subject's motivation and experience stored in their brain often speed up finishing the task such as target search and recognition, scene understanding and so on. Attention modelling under the influence of a task is proposed in [14], which is related to the representation of top-down knowledge, task-specific guidance for visual attention, and object recognition under the guidance of top-down knowledge. This model combines top-down and bottom-up attention together to find salient locations in a scene for object detection, and object recognition at these salient locations via the prior knowledge of the relevance between the object and current task. The prior knowledge in [14] is stored in working memory and long-term memory in two potential forms. One is symbolic representation – the task defined by subject and task-relevance of existing objects – that is regarded as human inherent knowledge and their current motivation. The other is low-level features related to the expected object (statistical properties for each low-level feature) that need to be learned from many instances. The stored low-level features are regarded as the knowledge about a subject's experience. Both potential forms of the prior knowledge guide the computation of visual salience and object recognition. The attention at the location with task-irrelevance is ignored according to the symbolic knowledge, even if the location is more salient than others. The prior knowledge of the required target-related low-level features is to control the weight on each low-level feature obtained from pure bottom-up salient computation. These features related to the required target gain top-down bias so that the expected object can pop out. The object recognition is finished by matching the low-level features of the most salient location in the scene with those stored in long-term memory (LTM). In [14], the optimal choice of top-down bias is not considered, and the later literature of the same authors adopts the maximum signal-to-noise ratio (SNR) to bias the low-level features for fast object detection [41, 42]. In the following subsections, we introduce bottom-up salient computation, the top-down knowledge representation, top-down and bottom-up integration, object recognition and the implemental process of the computational model and results; finally we present another top-down biasing method based on maximum SNR.
5.3.1 Bottom-up Low-level Feature Computation
As in the pure bottom-up model (the BS model, as mentioned in Section 3.1), the input image is decomposed in to nine different feature channels, such as orientation (0°, 45°, 90° and 135°), colour (R, G, B and Y) and intensity and so on. Gaussian pyramids for these channels are built by using Gaussian low-pass filtering and down-sampling progressively. In [14], seven centre–surround feature types: intensity contrast (on/off), double colour opponent contrast (red/green, blue/ tallow), and four local orientation contrast is used to yield totally 42 feature maps via six different pairs of centre and surround scales. Non-linear interactions and spatial competition are implemented in each of these feature maps before linearly combination of these maps [43]. After competition the feature map with high value at many locations does not generate the salience more and the feature map with high activity at only one location is a strong driver to the map's salience. Here we do not introduce the bottom-up computation to avoid repeating, readers can see Chapter 3 in detail. These low-level features are very important for bottom-up saliency computation, top-down knowledge collection, and object recognition in this model of top-down influence.
5.3.2 Representation of Prior Knowledge
It is known that top-down process requires prior knowledge about the world and semantic processing. Since people may be not clear how to represent the prior knowledge in the high-level cortex, this model adopts two afore-represented schemes: symbolic potential form based on artificial intelligence without more biological basis and feature-based potential form with some biological evidences. The symbolic potential form is to simulate subject's inherent knowledge (task-relevance knowledge) and to decide if the recognized object is related to the current task. The feature-based potential form is to match the tested object for recognizing the object. Where is the prior knowledge stored in the human brain? There are two memories: working memory (WM) which serves for the current work and long-term memory (LTM) which serves for a lifetime. Studies of WM suggest that both the frontal and extra striate cortices may be separated into a ‘what’ memory storing the visual features of input stimuli and a ‘where’ memory to store spatial information [44, 45]. Both these forms are to simulate the two memories (what and where). The information stored in LTM is available for a lifetime, so the information is permanent, managed and retrieved for later use. The visual representation stored in WM related to the current attended object in the form of statistics of the low-level features is referred to as visual WM. The symbolic knowledge stored in WM related to the properties of an attended object and its relationship with other objects or the current task in the form of symbols (nodes and edges) is referred to as symbolic WM. The location of current attended object (or entity) is memorized in the task-relevance map (TRM), a two-dimensional topographic map in this model which is like the saliency map in pure bottom-up computational model. The visual WM and TRM simulate the ‘what’ and ‘where’ memories in the brain respectively. The LTM is a knowledge base which has a symbolic module set from the subject and visual modules by learning the input instances as with WM. LTM can help WM to build the symbolic module in the initial stage and the visual WM module when the task has been decided.
5.3.2.1 Symbolic Modules in LTM and WM
The symbolic LTM includes entities or objects (nodes) and their relationship (edges) that create a graph by hand-setting. The entities contain real-world concepts and some simple relationships. For example, the intent is to find a hand in an indoor scene and the relationship between the hand and other possible entities (or objects) in the scene such as man, fingers, pens, table and chairs is created. The fingers are more relevant than the man since if the fingers are found then the hand has been found, but finding the man implies that the subject needs a few eye movements to find the hand [14]. The table is more relevant than chairs because hands are often put on the table. Consequently, the entities in the world and their relationships can be stored in the LTM according to the rule created by [14]. The nodes in the symbolic LTM are the entities, and the connected edges denoting the degree of task-relevance, or the probability of joint occurrence of entities.
Symbolic WM creates a current task graph including the definition of task (keywords), task-relevant entities and their relationships that are somewhat like symbolic LTM. The difference from symbolic LTM is that symbolic WM only services the current task at the fixation point of a scene, so symbolic WM possesses little information and acts as short-time memory. After the entity at the current fixation is recognised, symbolic WM estimates its task-relevance. There are three cases. (1) If the entity appears in symbolic WM, the simple search can find the required object by the connection between the entity at the current fixation and the defined object or task. For instance, if the defined object is a hand, the entity at the current fixation is a fork, that is in the task graph of symbolic WM (fork is task-relevant), so the search for the defined object, hand, is easy via the task-relevant path. (2) If the entity at the current fixation is not in the symbolic WM, then it needs to check the symbolic LTM to find whether there is a path from the fixated entity to the defined object (task). If it is yes, the defined object or task can still be found according to the path. (3) If no path is checked in the symbolic LTM, the fixated entity is irrelevant to the task. The eye moves to the next fixation to find the task-relevant entity. The focus locations with the task-relevance for each fixation entity are stored in the TRM that plays the role of the ‘where’ memory. TRM needs to update in the processing course.
It is worth noting that symbolic knowledge is mainly used to discriminate whether the entity at the fixation point in a scene is relevant to the defined task and to find the path from the entity to the defined task; it generally operates after the entity has been recognized, except that the definition of the initial task in symbolic WM has matched the task.
5.3.2.2 Visual Modules in LTM and WM
The visual modules (visual LTM and WM) store the information of several target objects that are learned from a training set at the training stage. For each required learning object there are several images with different circumstances in the training set, which are regarded as the instances of the object. In the training set, the target object's region in each image is highlighted by a binary mask map (one for the object's region and zero for others) while keeping the background of the object. It is noticed that the mask map is not used to segment the object, but only to enhance the saliency of the target object.
During the training stage, the model operates under free-viewing case (no top-down task) like pure bottom-up model. For the image with highlighted target region, bottom-up calculation can rapidly find the target region. Taking the most salient location (fixation point) from the target region, the 42 centre–surround features across six scales of seven sub-channels (mentioned in Section 5.3.1) in the location are observed. The visual WM learns the observed values of the pixels in a 3 × 3 grid of fixed size centred at the salient location. At the coarse scale, feature maps of a view may cover some neighbourhood properties that are exactly expected by the model, because the background information can help to detect the object in the testing images.
The sample vector related to 42 centre–surround features as the location-representation is called a ‘view’ and is stored in the visual LTM. A collection of these views contained in the current instance of the target forms an instance-representation in the visual WM and is stored in the visual LTM. The visual WM repeats the process by retrieving the stored instances from LTM for the same object to combine a more robust object representation that is also stored in visual LTM. Different object representations in visual LTM form a super-object representation with a tree structure, from views, instances and objects to super-object representation. Notice that the visual LTM includes the representation for all objects, and visual WM only stores the current object representation. Figure 5.5 is a sketch map of the learning process about a general object representation in visual WM: view, instance and object. The triangles on the original images denote the same target object in different circumstances. The view samples the vectors for each with 42 features at diverse locations in the target region to form a second statistical representation for each of the features, where μ and σ are the mean and variance of the feature in these views. The visual WM collect all the views in an original image to form an instance representation and collect all instances to the representation of target object. The learning result is like a tree structure, and the object representation in visual WM is important for top-down bias.
Figure 5.5 Learning a general representation of an object
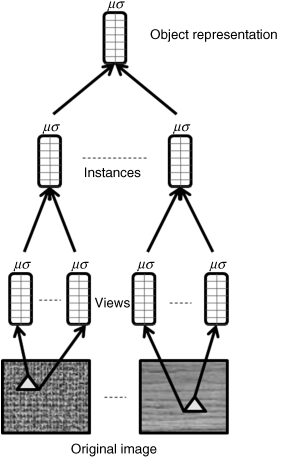
In the visual LTM, many object representations like Figure 5.5 from the visual WM construct a super-object for the same class of objects until it reaches a root object. This is like a decision tree in machine learning, the views in visual LTM are leaves and instances denoting the nodes of sub-branch, and the final super-class object is the root. Using a decision tree as top-down knowledge is mentioned in [46, 47]. In this model the decision tree is used for object recognition.
5.3.3 Saliency Map Computation using Object Representation
From Section 5.3.1, the low-level features in bottom-up computation are 42 centre–surround feature maps for six scales of seven sub-channels. Combining the six-scale feature maps in the same feature type forms sub-channels (four orientation maps, two colour maps and one intensity map), and then goes on to form three channels (orientation, colour and intensity); finally combining the three channels forms a saliency map. The top-down influence is implemented by weighted combinations of different feature maps. Given a specific target object, the visual WM retrieves the representation of the target object stored in the visual LTM to bias the combination of different feature maps. If a feature f has high mean value and low variance, then that feature is more relevant to target object (high weight), that is feature f has a high contribution to the saliency map. The weight is defined as
where μ(f) is the mean of feature f and σ(f) is the variance of feature f. Since these feature maps are combined to sub-channels, channels and a saliency map, all the sub-channels and channels related to the target object will gain promotion in order to pop out the required object. In the top-down bias, each parent channel promotes itself proportionally to the maximum feature weight of its children channels, so the weight of each parent channel satisfies
![]()
where subscript p denotes the parent channel. For example, a target object has strong vertical edge at some scales, then the weight of the 90° sub-channel increases and the weight of the orientation channel also increases. The weights of other channels or sub-channels, such as the colour channel, are decreased. The final saliency map is the combination of all the features with top-down bias, so the given target object can be rapidly detected in the saliency map with top-down influence.
5.3.4 Using Attention for Object Recognition
The recognition of an observed event whose 42 feature values are calculated at the current fixation, is to match the extracted feature vector Ob with these object representations (vectors) which are already learned and stored in the visual LTM {X1, X2, . . . Xn} (the total number of objects is n). A maximum likelihood estimation is used to find the match between Ob and Xi, i = 1, 2, . . . n. Since the form of stored information in the visual LTM is a decision tree from root node (root object class representation) to leaf nodes (view representations), the search starts from the root object then finds a good match among all the child nodes from the root (level 0) to some desired level k of specificity, in the other words first comparing the feature vector Ob with super-object representation (object class) and then comparing with more specific representation such as a particular object or instance or view. If the best match node belongs to object Xj, then event Ob at current fixation means that object Xj has occurred. According to the label of Xj the event Ob has been recognized. The symbolic WM and LTM can work to determine if the search has finished or needs to continue, as described in Section 5.3.2.1.
5.3.5 Implementation
Suppose that the prior knowledge (symbolic information and low-level object-representations) in the LTM is available. The model is implemented in four phases: initialization, computation, recognition and updating.
5.3.6 Optimizing the Selection of Top-down Bias
In Section 5.3.3, the influence of top-down is to bias the low-level features related to the target object by Equation 5.16. An alternative strategy for biasing weights based on maximizing the speed of target detection is proposed in [41, 42]. The strategy aims at finding optimal top-down influence (bias) on bottom-up processes such that the target in the scene can be detected as fast as possible. It is known that those features that can pop out the target should be more weighted than those features that cannot distinguish it. For instance, a ripe apple with red colour among green leaves is easier to detect than green apples in the colour feature dimension, so the colour feature should have high top-down bias for picking the ripe fruit from the tree. In signal detection theory the goal of maximizing the speed of target detection is to maximize the ratio between signal and noise (SNR). If the expectation for salience of the target is regarded as signal and the expectation for salience of the distracting clutter in its surrounding is regarded as noise, the biasing weight of the top-down influence is proportional to
![]()
where the mean salience is the expectation taken over all possible targets and the distractors (distracting clutter), their features and spatial configurations with several repeated trials.
For the salience of each feature in each feature dimension, the weight is different. Suppose the bottom-up salience of every scene location for different local visual features (different colours, orientations and intensities) at multiple scales has been computed, denoted as ![]() , where A is input scene, (x, y) is the location and the subscripts i and j denote the ith feature value in the jth feature dimension. Here the feature dimension is one of intensity, colour and orientation channels and so on. Considering that top-down influence on the feature response is modulated by multiplying by a gain, the salience of the jth feature dimension
, where A is input scene, (x, y) is the location and the subscripts i and j denote the ith feature value in the jth feature dimension. Here the feature dimension is one of intensity, colour and orientation channels and so on. Considering that top-down influence on the feature response is modulated by multiplying by a gain, the salience of the jth feature dimension ![]() at a given location (x, y) can be represented as
at a given location (x, y) can be represented as
where ![]() is top-down gain to modulate the response of the ith feature value within the jth feature dimension, and n is the number of features in an feature dimension. In the same manner, the salience across all feature dimensions with top-down influence at location (x, y) is expressed as
is top-down gain to modulate the response of the ith feature value within the jth feature dimension, and n is the number of features in an feature dimension. In the same manner, the salience across all feature dimensions with top-down influence at location (x, y) is expressed as
where ![]() denotes the modulated gain for the jth feature dimension and N is the number of feature dimension. The top-down gains
denotes the modulated gain for the jth feature dimension and N is the number of feature dimension. The top-down gains ![]() and
and ![]() are calculated from prior knowledge of the target and distractors.
are calculated from prior knowledge of the target and distractors.
Let scene A contain target and distractors that are sampled from probability density functions ![]() and
and ![]() , respectively, where f is the feature vector composed of multiple low-level feature values in different feature dimensions, and T and D represent target and distractors. The feature value in each dimension is represented by a population of neurons with broad and overlapped tuning curves as in Figure 5.2 in Section 5.1. The samples from scene A simulate a detector to test each location in the scene repeatedly in order to avoid noise. The mean salience of the target and the mean salience of the distractor are the expectation over all locations, features and feature dimensions by repeated tests. From Equations 5.17 and (5.18), we have
, respectively, where f is the feature vector composed of multiple low-level feature values in different feature dimensions, and T and D represent target and distractors. The feature value in each dimension is represented by a population of neurons with broad and overlapped tuning curves as in Figure 5.2 in Section 5.1. The samples from scene A simulate a detector to test each location in the scene repeatedly in order to avoid noise. The mean salience of the target and the mean salience of the distractor are the expectation over all locations, features and feature dimensions by repeated tests. From Equations 5.17 and (5.18), we have
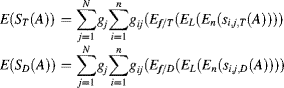
and
(5.19) 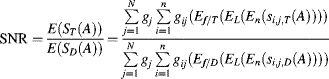
where ![]() is the mean of all samples in a location,
is the mean of all samples in a location, ![]() is the mean of all locations,
is the mean of all locations, ![]() and
and ![]() are the mean across all features in all feature dimensions. Now the goal is to select optimal top-down gains
are the mean across all features in all feature dimensions. Now the goal is to select optimal top-down gains ![]() and
and ![]() such that the SNR is maximized, which has
such that the SNR is maximized, which has
where ![]() and
and ![]() are the normalization term and
are the normalization term and ![]() and
and ![]() can be represented as
can be represented as
(5.21) ![]()
The sign of the gradient for each gain (Equation 5.20) can decide whether the gain value is increasing, decreasing or remaining the same. If ![]() the gain
the gain ![]() , contrarily,
, contrarily, ![]() (SNR) < 0, the gain,
(SNR) < 0, the gain, ![]() . While
. While ![]() ,
, ![]() .
.
Several experiments in [41, 42] showed the validity of the model since it makes the target more salient than the distractors even if the target is not prominent in bottom-up processing.
Other computational models considering top-down influence have been proposed [48, 49]. The study in [48] uses the human face and skin features as top-down cues to design a computational model for video. In the study of [49], the orientation features of man-made objects are extracted as top-down features for salient object detection.