
8.2 Use of Visual Attention in Quality Assessment
Visual attention plays an important role in image/video quality assessment (QA). The distortion that occurs on the salient areas should be treated differently from that which occurs on the less salient areas. Let us take Figure 8.5 for example [18]: (a) is a reference image; (b) is the saliency map of (a), and (c)–(f) are distorted images polluted by blur or noise. The difference is that (d) and (f) are polluted in less salient areas (river blurred and river noised), while (c) and (e) are polluted in salient areas (boat blurred and boat noised). We can easily distinguish the quality of two image pairs – the quality of (d) and (f) is better than (c) and (e), respectively. Similar to image QA, we focus much more in the video scene. We can hardly observe all the details in the frame or analyse every object in each salient area because the interval between two frames in the video is so short that we probably grasp only the most salient area. Any distortions that occurs other than in the primary salient area would likely be neglected.
Figure 8.5 Comparison of images with different perceptual qualities: (a) original image; (b) saliency map of (a); (c) image with blurred pollution in salient area; (d) image with blurred pollution in less salient area; (e) image with noised pollution in the salient area; (f) image with noised pollution in a less salient area [18]. Ma, Q., Zhang, L., Wang, B., ‘New strategy for image and video quality assessment’, Journal of Electronic Imaging, 19(1), 011019, 1–14, 2010. Society of Photo Optical Instrumentation Engineers

Figure 8.6 The main architecture of video encoding standards

Therefore, visual attention should be considered in the image QA to improve its performance, that is to make the assessment results approach more closely to human subjective perception. In most of the existing work, visual attention is used as a weighting factor to spatially pool the objective quality scores from the quality map. Following a brief review of QA, three typical methods are introduced below.
8.2.1 Image/Video Quality Assessment
Digital images and videos are usually affected by a wide variety of distortions during acquisition and processing which generally result in loss of visual quality. Therefore, QA is useful in many applications such as image acquisition, watermarking, compression, transmission, restoration, enhancement and reproduction.
The goal of image QA is to calculate the extent of quality degradation and is thus used to evaluate/compare the performance of the processing systems and/or optimize the choice of parameters in the processing. For example, the well-cited Structural SIMilarity (SSIM) index [19] has been used in image and video coding [20, 21].
The HVS is the final receiver of the majority of processed images and videos, and evaluation based on subjective experiments (as formally defined in ITU-R Recommendation BT.500 [22]) is the most reliable way of image QA if there is a sufficient number of subjects. However, subjective evaluation is time-consuming, laborious, expensive and not easily repeatable; it cannot be easily and routinely performed for many scenarios, such as in the selection of the prediction mode in H.264, a video compression standard. These drawbacks have led to the development of objective QA measures which can be easily embedded in image processing systems.
The simplest and most widely used QA scheme is the mean square error (MSE) between the original and degenerated images, and the PSNR related to MSE (the ratio of the power of peak value in the image to the MSE). They are popular due to their mathematical simplicity as well as being easy for use in various image/video processes. It is, however, well known that MSE/PSNR do not always agree with the subjective viewing results, especially when the distortion is not additive in nature [23]. This is not surprising given that MSE/PSNR is simply based on an average of the squared pixel differences between the original and distorted images.
Aimed at accurate and automatic evaluation of image quality in a manner that agrees with subjective human judgment, regardless of the type of distortion corrupting the image, the content of the image or the strength of the distortion, substantial research effort has been directed, over the years, towards developing image QA schemes [24, 25]. The well-known schemes proposed in the past ten years include SSIM (structural similarity) [19], PSNR-HVS-M [26], visual information fidelity (VIF) [27], visual signal-to-noise ratio (VSNR) [28]) and the most recently proposed most apparent distortion (MAD) [29]. Of these, SSIM [19] is the most widely accepted due to its reasonably good evaluation accuracy [18, 30], pixel-wise quality measurement and simple mathematical formulation which facilitates analysis and optimization. The SSIM assumes that natural images are highly structured, and the human vision is sensitive to structural distortion. The structural information in an image is defined as those attributes that represent the structure of objects in the scene, independent of the average luminance and contrast [19].
The SSIM is calculated for each overlapped image block by using a pixel-by-pixel sliding window, and therefore it can provide the distortion/similarity map in the pixel domain. It has also been extended using multiscale analysis [31], complex wavelets [32] and discrete wavelets [33]. For any two image blocks Bx and By (located at the same position, in two different images), the SSIM models the distortion/similarity between them as three components: luminance similarity, contrast similarity and structural similarity, and these three components are mathematically described as Equations 8.21–8.23 below, respectively:
(8.22) ![]()
where ![]() ,
, ![]() ,
, ![]() ,
, ![]() and
and ![]() are the mean of Bx, the mean of By, the variance of Bx, the variance of By and the covariance of Bx and By, respectively;
are the mean of Bx, the mean of By, the variance of Bx, the variance of By and the covariance of Bx and By, respectively; ![]() ,
, ![]() and
and ![]() are claimed as small constants to avoid the denominator being zero.
are claimed as small constants to avoid the denominator being zero.
The SSIM for the two image blocks is given as
where ![]() ,
, ![]() and
and ![]() are positive constants used to adjust the relative importance of the three components. The higher the value of
are positive constants used to adjust the relative importance of the three components. The higher the value of ![]() , the more similar the image blocks Bx and By are. Obviously if By (assumed to be the image block under evaluation) and Bx (assumed to the reference block) are the same, Equations 8.21–8.24 will all give the value of 1, indicating no change in the block By with respect to the block Bx. When the block measurement is applied to an entire image for each local pixel, an SIMM map is created. The overall image quality score of the whole image is determined using the mean of the SSIM map [19] or calculated as the information content weighted average of local SSIM [34].
, the more similar the image blocks Bx and By are. Obviously if By (assumed to be the image block under evaluation) and Bx (assumed to the reference block) are the same, Equations 8.21–8.24 will all give the value of 1, indicating no change in the block By with respect to the block Bx. When the block measurement is applied to an entire image for each local pixel, an SIMM map is created. The overall image quality score of the whole image is determined using the mean of the SSIM map [19] or calculated as the information content weighted average of local SSIM [34].
When it comes to video QA, the most straightforward way of course is to use the average of frame level quality (quality of each frame computed using the above-mentioned schemes) as the overall video quality measure. One other possibility is to use the image QA methods to measure the spatial quality and incorporate a temporal factor (e.g., by using similarity between the motion vectors [35] or the variation of quality along the time axis [36]). The spatial and temporal factors may also be combined via machine learning as in [36]. Another feasible approach is to use the image QA methods to measure the quality (or similarity) of motion-compensated blocks (in reference and distorted video sequences), which can serve as the temporal factor (a similar approach reported in [37] uses SSIM).
8.2.2 Weighted Quality Assessment by Salient Values
A very simple consideration is that the abovementioned image QA schemes are weighted by the values on saliency map of the image, that is while estimating image quality, giving larger weighting for salient places and small weighting for non-salient regions [18, 34]. If the saliency map of the image is computed in advance, the weight of each location for the pixel-based QA score can be given by the saliency map. As an example of the popular QA score, SSIM based saliency map [18], the weighted SSIM score is
(8.25) ![]()
![]()
where X and Y represent the original image and the degraded image respectively, and Bxj and Byj are two block images in X and Y, N is the number of blocks in original image that is the same as degraded image. When all image blocks are overlapped by using a pixel-by-pixel sliding window, the N approaches the pixel number of the whole image (the margin pixels of the image should be deducted from the pixel number of the whole image). SMj is the salient value of the jth pixel on the saliency map calculated for the original image. The function g is an ascending function with SM increase.
The same salient weighted method as above can be used in other image QA schemes. With the four degraded images shown in Figure 8.5(c)–(f), subjects' perception of the image quality is that Figures 8.5(d) and (f) should be better than Figure 8.5(c) and (e), respectively. However, the indexes of PSNR, SSIM and VIF give the reverse conclusion. Salient weighted QA score (PSNRSM, SSIM SM and VIFSM) are coincident with human perception in [18].
In [18], video salient weighted QA (VSQA) makes use of both spatial and temporal weighing to combine the QA. The spatial QA adopts weighted QA from the saliency map of each frame mentioned above. The temporal weighting depends on the saliency of relative motion between two adjacent frames, as well as according to the following two rules: (1) Motion masking effect [8] in Figure 8.2: the adjacent frames with dramatic changes such as a scene switch or intense motion; in this case, the weight of the latter frame should decrease, because the human is not sensitive to large inter-frame change; (2) Degree of concentration of visual attention: the frame with distractive attention is given small weight as there is nothing to be particularly attractive. The synthetic consideration of the above factors forms the VSQA in [18].
8.2.3 Weighting through Attention-modulated JND Map
Let ![]() ,
, ![]() and
and ![]() denote the original video sequence, the degraded video sequence and the attention-modulated STJND profile as introduced in Section 8.1.2, respectively. The visual attention accounted MSE can be expressed as
denote the original video sequence, the degraded video sequence and the attention-modulated STJND profile as introduced in Section 8.1.2, respectively. The visual attention accounted MSE can be expressed as
where
(8.27) 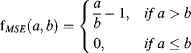
In Equation 8.26, any distortion below the detectability threshold ![]() is excluded from accumulation for the visual distortion score.
is excluded from accumulation for the visual distortion score.
Similarly, the visual attention-modulated STJND accounted pixel-based SSIM can be expressed as
(8.28) 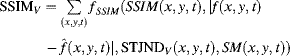
where
(8.29) ![]()
where ![]() and
and ![]() are the constants to map the attention/saliency values (SM) into an appropriate range non-linearly. With the choice of
are the constants to map the attention/saliency values (SM) into an appropriate range non-linearly. With the choice of ![]() , the weighted SSIM accounts for the effect of both visual attention and visibility threshold: if the maximum block-based error is below
, the weighted SSIM accounts for the effect of both visual attention and visibility threshold: if the maximum block-based error is below ![]() , it is not accumulated for
, it is not accumulated for ![]() ; otherwise, the SM values are non-linearly and monotonously scaled as the weighting for visual annoyance measurement.
; otherwise, the SM values are non-linearly and monotonously scaled as the weighting for visual annoyance measurement.
Performance of the attention-modulated JND QA method is evaluated on VQEG Phase-I video data [38] by using the Pearson linear correlation coefficient between the algorithm's output and the mean quality scores given by a large number of subjects. Performance is improved from 0.779 to 0.812 for the MSE algorithm and that for SSIM is from 0.849 to 0.895.
8.2.4 Weighting through Fixation
In additional to the attention-modulated JND map, the visual attention mechanism is also adopted in QA through the fixation map. Researchers have produced some successful fixation finding algorithms, such as the one in [39] which seeks regions of high saliency, and the gaze-attentive fixation finding engine (GAFFE), which uses image statistics measured at the point of gaze from actual visual fixations [40].
Given a set of image coordinates that may be perceptually important – the fixations – two important decisions are required. First, how many fixations should be used per image? Second, given ![]() fixations per image, what is the weighting factor
fixations per image, what is the weighting factor ![]() by which the original quality scores (e.g., SSIM values) at these fixations should be weighted relative to other pixels?
by which the original quality scores (e.g., SSIM values) at these fixations should be weighted relative to other pixels?
The numbers of fixations found in [40] were ten fixations per image (on average). However, these fixations were generated based on the subjective study carried out, where each image was shown to the subject for 5 seconds. Conversely, for QA, the subjects were allowed to look at the images for as long as they wanted, until they made their decision. Hence, the number of fixations is set as a constant ![]() (although GAFFE can be programmed to compute any number of fixations). Each fixation is extrapolated by a 11 × 11 2-D Gaussian function centred at the fixation. Since fixations are recorded at single coordinates, and since areas of visual importance may be regional, the Gaussian interpolation used in GAFFE serves to associate the fixations with regions subtending a small visual angle. Each 11 × 11 region is then scaled by a factor
(although GAFFE can be programmed to compute any number of fixations). Each fixation is extrapolated by a 11 × 11 2-D Gaussian function centred at the fixation. Since fixations are recorded at single coordinates, and since areas of visual importance may be regional, the Gaussian interpolation used in GAFFE serves to associate the fixations with regions subtending a small visual angle. Each 11 × 11 region is then scaled by a factor ![]() .
.
The peak values of the weights applied to the fixated regions (the Gaussian centres) relative to the weights of the non-fixated areas are in the ratio ![]() . It is found in [41] that the value
. It is found in [41] that the value ![]() for the best correlation between the objective and subjective scores (tested on the LIVE image QA database [42]) remains approximately the same over various distortion types. A value
for the best correlation between the objective and subjective scores (tested on the LIVE image QA database [42]) remains approximately the same over various distortion types. A value ![]() should yield good results, since varying this ratio in the range
should yield good results, since varying this ratio in the range ![]() does not change performance much.
does not change performance much.
Thus, the weighted SSIM score through fixation (![]() ) is defined as
) is defined as
(8.30) ![]()
where ![]() is the SSIM value at pixel location indexed by (
is the SSIM value at pixel location indexed by (![]() ); w are the SSIM weights, and the pixels that do not fall under the fixation masks are left untouched:
); w are the SSIM weights, and the pixels that do not fall under the fixation masks are left untouched: ![]() , otherwise,
, otherwise, ![]() .
.
8.2.5 Weighting through Quality Distribution
The weighting methods in Sections 8.2.2–8.2.4 are based on the hypothesis that visual attention of the original reference image influences human perception of image quality. There is also another hypothesis that humans tend to perceive ‘poor’ regions in an image with more severity than the ‘good’ ones – and hence penalize images with even a small number of ‘poor’ regions heavily. This means that regions of poor quality in an image can dominate the subjective perception of quality. A reasonable approach to utilizing the visual importance of low-quality image patches is to more heavily weight, the lowest p% of scores obtained from a quality metric.
A term that is commonly known among statisticians is quartiles [43]. Quartiles denote the lowest 25% values of an ordered set. Generalizing this, the pth percentile of an ordered set is the lowest p% of values of that set. Given a set, the elements are first ordered by ascending order of magnitude with the lowest p% of values being denoted as the pth percentile.
In the further discussion that follows, involving percentile scores (denoted as ![]() ), we assume that a quality map of the image has been found using one of the quality metrics mentioned in Section 8.2.1 (e.g., SSIM), and that these values have been ordered by ascending value, but the questions remain – what percentile should be used, and by how much should we weight the percentile score? In order to arrive at a solution, several values of p from 5% to 25% in 1% increments are tried in [41]. Rather than using an arbitrary monotonic function of quality (such as the smooth power-law functions used in [44]), they use the statistical principle of heavily weighting the extreme values – in this case, the lowest percentiles. Thus, the lowest p% of the original quality scores (e.g., the SSIM values) are (equally) weighted. Non-equal weights of the rank-ordered SSIM values are possible, but this deeper question has not been explored. Similar to the case for
), we assume that a quality map of the image has been found using one of the quality metrics mentioned in Section 8.2.1 (e.g., SSIM), and that these values have been ordered by ascending value, but the questions remain – what percentile should be used, and by how much should we weight the percentile score? In order to arrive at a solution, several values of p from 5% to 25% in 1% increments are tried in [41]. Rather than using an arbitrary monotonic function of quality (such as the smooth power-law functions used in [44]), they use the statistical principle of heavily weighting the extreme values – in this case, the lowest percentiles. Thus, the lowest p% of the original quality scores (e.g., the SSIM values) are (equally) weighted. Non-equal weights of the rank-ordered SSIM values are possible, but this deeper question has not been explored. Similar to the case for ![]() , it is found that the value p = 6% yields good results; however, small perturbations p do not alter the results drastically in [41].
, it is found that the value p = 6% yields good results; however, small perturbations p do not alter the results drastically in [41].
Given an SSIM map, the SSIM values are arranged in ascending order of the magnitude, and scale the lowest p% of these values by a factor of ![]() . Although
. Although ![]() is finally used in [41], a variation of this ratio in the range
is finally used in [41], a variation of this ratio in the range ![]() did not affect the performance much. The pixels that do not fall within the percentile range are left unchanged,
did not affect the performance much. The pixels that do not fall within the percentile range are left unchanged, ![]() . This yielded better performance than when
. This yielded better performance than when ![]() for the pixels that do not fall within the percentile range.
for the pixels that do not fall within the percentile range.
In order to validate the algorithm of weighting through fixation and through quality distribution, the LIVE database of images was used as a test bed [42]. The specific contents of the type of distortions present in the database are: JPEG2000: 227 images, JPEG: 233 images, white noise: 174 images, Gaussian blur: 174 images, fast fading: 174 images. The database includes subjective scores for each image. Results for ![]() and
and ![]() are tabulated in Table 8.2, where WN = white noise; Gblur = Gaussian Blur, and FF = fast fading.
are tabulated in Table 8.2, where WN = white noise; Gblur = Gaussian Blur, and FF = fast fading.
Table 8.2 Pearson linear correlation coefficient values for SSIM and its variations [41]. © 2009 IEEE. Reprinted, with permission, from Moorthy, A.K., Bovik, A.C., ‘Visual Importance Pooling for Image Quality Assessment’, IEEE Journal of Selected Topics in Signal Processing, April 2009.

The improvements afforded by ![]() were not across the board, and indeed were limited to the Gaussian blur and fast fading distortion types. These distortions tend to destroy the structure of perceptually significant features such as edges. The improvement in performance using
were not across the board, and indeed were limited to the Gaussian blur and fast fading distortion types. These distortions tend to destroy the structure of perceptually significant features such as edges. The improvement in performance using ![]() was more substantial. Indeed, the improvement afforded by single-scale
was more substantial. Indeed, the improvement afforded by single-scale ![]() is so significant that it competes with standard multiscale SSIM! This suggests that using percentile scoring in combination with simple SSIM is a viable alternative to the more complex multiscale SSIM. Yet, using
is so significant that it competes with standard multiscale SSIM! This suggests that using percentile scoring in combination with simple SSIM is a viable alternative to the more complex multiscale SSIM. Yet, using ![]() for multiscale SSIM affords even better gains.
for multiscale SSIM affords even better gains.