7.2 Attention Based Object Detection and Recognition in a Natural Scene
In pure bottom-up computational visual attention models in the spatial domain (e.g., the BS model mentioned in Chapter 3), local feature extraction forms part of the models, and after contrast processing and normalizing, the locations of some of the candidate objects can pop out on the resulting saliency map. Thus, we do not need to search the full scene to detect the objects by shifting windows one pixel and one pixel. Also, the idea of visual attention enables some engineers of computer vision to create fast algorithms of detecting objects. In this section, first a pure bottom-up model combined with a conventional object detection method is introduced. Then some two-region segmentation methods based on the visual attention concept are presented, after which object detection with the training set is provided. Finally, the BS visual attentional model with SIFT features for multiple object recognition is presented.
These introduced methods mainly provide readers a new strategy of how to incorporate visual attention models in object detection and recognition applications.
7.2.1 Object Detection Combined with Bottom-up Model
1. Simple detection method
The development of bottom-up computational models closely links to object detection. A simple method uses the most salient location in a scene as the possibly desired object or object candidate location. Suppose we have obtained the saliency map (SM) of an image using a bottom-up computational model, and the most salient location (x, y) and its surrounding pixels are labelled as one (+1) by four connected or by eight connected neighbourhoods if the salient values of its neighbouring pixels are greater than γ SMmax(x, y) for 0 < γ < 1, where SMmax denotes the maximum value on the saliency map. The connected region of the most salient location extends until no salient value in the region's neighbouring pixels is greater than the value of γ SMmax(x, y). The regions not labelled are set to zero. Thus a binary mask map (one for the object region, and zero for the background) is created. Since the size of the saliency map in the BS model is smaller than the original input image, the binary mask map is adapted to the size of original image first, and then it multiplies the original image, pixel by pixel, to complete the object detection. For a simple natural image with a single salient object as foreground – such as a white boat in blue sea, or a red flower among green leafs – the object can be detected rapidly by the computation above. If the most salient location does not include the desired object, the search can continue to the second maximum salient location. The binary mask map for the second maximum salient location can be obtained using the same procedure as introduced above except that the maximum salient value SMmax (x, y) changes to the second maximum value SM2nd-max (x, y). The search continues for the third, fourth . . . , until the object is found. In this case, prior knowledge (the training set) and a classification method in Section 7.1 should be considered. It is worth noting that the object detection is only for these salient regions on the image according the order of the region's signification, and it can avoid doing a full search and save time. This detecting method has been used in many object detection and recognition applications [5, 42].
2. Seed selection by salient location
The pixels within an object of the input image often have similar features which are different from features for the background. An object in the scene often appears to be homogeneous. In the case of a single object in a natural scene, two-region image segmentation can partition an image into object/background regions according to the similarity criterion. Seeded region growing [43] is a conventional method in image segmentation. For the given initial seeds, the algorithm of seeded region growing aims to find homogeneous regions around the given seeds. Suppose each pixel on a colour image belongs to colour components R, G and B. When the differences between the initial seeds and their surrounding pixels for all the three colour components are less than a fixed threshold, then the surrounding pixels unite into the region enclosing the initial seeds, which makes the size of the seed regions increase. Then the mean colours for the three colour components (mean red, blue and green) in the increased regions are computed. The comparison between surrounding pixels outside of the increased regions and the mean colour components within the increased regions, continues according to similarity criteria. The regions enclosing these seeds gradually grow until the whole image is covered by these growing regions. For natural images of a simple background with a single object, the seeded region growing algorithm can find the single object and the background by the two-region image segmentation algorithm.
The problem is how to select the initial seeds, and this directly affects the quality of segmentation. The bottom-up attention model can easily find the most salient points on the image. By choosing these salient points as seeds in the scene, the objects can be found while ignoring the background [12].
3. Region growing with fuzzy theory
The computation of the binary map in (1) is related to the threshold γ. A larger γ value makes the size of object region smaller, such that the object cannot be entirely covered by the mask, and a smaller γ value results in dilating the object region; that is, part of the surrounding background is included in the object region. A fuzzy growing method proposed in [19] is to more reasonably extract the object area from the saliency map. It considers the saliency map as a fuzzy event, modelled by a probability space with k grey levels. Two classes of pixels in the saliency map are regarded as two fuzzy sets: the attended and unattended areas. Two parameters (tha and thb; tha > thb) construct the membership functions. The optimal fuzzy partition is to find the optimal parameters (tha and thb) according to the probability distribution and fuzzy method. When the grey level value at a pixel is great than tha, the pixel belongs to the salient region (definite object region); when the grey level of a pixel is less than thb, it belongs to the unattended area (definite background region). The pixels with grey level between tha and thb (the vague region) satisfy the linear membership. The initial parameters tha and thb are set by assuming the nearly equal probabilities of salient and unattended regions. Then the rough partition can be found by the aid of the parameters. Let the most salient pixels in the definite object region be the initial seeds, and then the seed region growing algorithm is used to find a more accurate object region, and the parameters of membership function change for the new groups; the iterative growing can then help to get a reasonable object region.
7.2.2 Object Detection based on Attention Elicitation
In the BS computational visual attention model and its variations, feature extraction is limited to local features and does not consider the features in terms of other aspects. In recent years, some literature has proposed faster and simpler methods for object detection. The developers of these works followed the concept of visual attention, but their approaches are more about engineering. Several such methods are introduced here.
1. Frequency tuned salient region detection (FTS)
Most bottom-up computational models introduced in Chapter 3 use the low-pass filters and down-sampling processing to generate a multiresolution pyramid and adopt the centre–surround in different scales or in the same scale (like the DoG band-pass filter) to further process the information in multiple resolution maps. The size of final saliency map is often smaller than the original image. Thus, most of low and high spatial frequency components are discarded after the above processing. In fact, an object region, especially one object with larger size in the scene, has homogeneous properties in which strong lower-frequency components appear. In that case, the detected saliency of the bottom-up computational models only appears on the object's edge, resulting in failure of detection of the whole object. For natural images with a single large-size object, the presence of a wide spatial frequency range may help in detecting the object. In [14, 15], the analysis of the frequency range of five different bottom-up computational models (including the BS and GBVS models in Chapter 3, and the SR model in Chapter 4 etc.) are provided, and it shows that the use of a multiresolution pyramid by low-pass filters and then down-sampling with reduction of the saliency map's size shrink the frequency range of an original image. An idea without resorting to multiresolution is proposed in [14, 15]: all the centre–surround operations (DoG band-pass filters) convolute the original image, and a wide frequency range can be maintained. Suppose that the DoG filter is the difference between two Gaussian functions like
Equation 7.2 in the SIFT approach but acts on the image of the same resolution; it is rewritten as
(7.14) 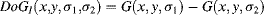
where G(·) is the Gaussian function, and σ
1 and σ
2 are the standard deviations which satisfy
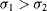
, so
Equation 7.14 is an inverse DoG function (negative at the centre and positive at the surrounding). The pass-band width of the DoG filter is controlled by the ratio
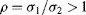
. It is known that the larger the value of σ
1 in the Gaussian filter, the smoother the result of the convoluted image. If
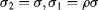
and location (
x,
y) in
Equation 7.14 is omitted for convenience of presentation, the inverse DoG
I filter can be rewritten as
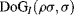
. In the BS model, the summation of several centre–surround differences in different scales for a feature channel forms a conspicuity map. Let the original image
I be denoted as the
I(
x,
y) array which is decomposed into
L, a and b channels (intensity, red-green and yellow-blue) in CIE LAB colour space. Consider the summation of the results by several narrow band-pass DoG
I filters to convolute the highest resolution channel image,
Ic, for
c = L, a, b given by
(7.15) 
Note that the middle Gaussian filters are cancelled out each other in
Equation 7.15, so that only the difference between two Gaussian filters remains: one is the lowest-frequency smoothing filter (for ρ
N 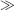
1) and the other is the highest-frequency narrow band-pass filter to convolute each channel's image
Ic. Let the convoluted result of the very smoothing filter with each channel (
L,
a and
b) approximate to a mean value of the whole channel image,
Icμ, that is a scalar quantity and not related to the coordinate. The highest narrow band-pass filter is a Gaussian kernel filter with 3 × 3 or 5 × 5 pixels and the convolution with each channel image obtains a blurred image
Ich for channel
c =
L,
a, and
b. Considering each pixel, the saliency map can be obtained by
(7.16) 
Note that in
Equation 7.16, the ± sign of the difference between mean and blurred values (e.g.,
ILμ −
ILh(
x,
y) is greater or less than zero) does not affect the salient results.
Equation 7.16 gives a method of computing the saliency map for a single object of large size in a natural scene. The object segmentation is computed by threshold cutting to create a binary mask as mentioned in Section 7.2.1. Simulated results in [14, 15] showed that a single object with large size in the foreground in the image database can be detected very accurately.
FTS is a high resolution full-field saliency computation method and it is very simple as it only needs to compute the mean value of an image and blurred image by convoluting a Gaussian kernel patch with 3 × 3 or 5 × 5 pixels for each channel in LAB space, and then
Equation 7.16 is computed. It can make the whole object region salient and avoid suffering from detection failure caused by only detecting the edges of large size objects.
However, the approach only suits simple backgrounds and fails in salient objects of small size; also, a very large size object, with a very smooth inside in a complex background, cannot be detected well. For example, a large egg (object) in bird's nest (background) fails to be detected by FTS, because the mean value of the whole image is near to the mean of the object region so that it cannot pop out the local information in the object region. An improvement of this method is proposed by [15], in which the mean value of the whole image is replaced by a local symmetric surround region for each pixel. Thus, pixels far from the object region on the complex background are calculated in a small image patch enclosing the pixels. In that case each pixel needs to find its symmetrical image patch first, then to compute
Equation 7.16. The code of FTS method is available in [44].
2. Object detection by integrating region features
In biologically plausible computational models, feature extraction is mostly based on local features (colour, intensity, orientation and motion), and in computer vision all kinds of features including local pixels, regions and global features are considered in order to easily detect objects. Some methods using both the visual attention concept and the features of computer vision are proposed in [13, 16–18, 20].
One idea to detect a large size object in a natural scene is based on global contrast on different regions [17], which uses histogram-based contrast in colour space to distinguish the object from its surroundings. It can uniformly highlight the whole object in its saliency map and directly detect the object without prior knowledge or a training set. First, a tested image is segmented into several regions by using classical image segmentation methods mentioned in Section 7.1. In [17], the authors adopt a graph-based method proposed by [45] to segment the images. It is worth noting that the number of regions is greater than two. Thereby, the purpose of selecting the object region among these segmented regions is to find the most salient one. The computation of saliency for each region is based on global contrast in the CIE LAB colour space. First we explain the colour contrast or distance. If the histogram of an image for colour components (L, a and b) is computed, that is, the number of pixels on each quantized colour bin in the image is calculated, and the global colour contrast for a pixel is the summation of all distance between the pixel's colour and all other pixels' colours in the colour histogram of the image.
The region saliency metric is based on the global colour contrast of all pixels in the region with other regions. For a region R
k, its saliency is defined as
(7.17) 
where
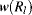
is the weight of region
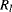
which can be set as the pixel number in region

, for profiting larger region.
Ds (
Rk,
Rl) and
Dc (
Rk,
Rl) are the spatial distance and the colour distance metric between region
Rk and
Rl respectively. When
k = 1 and
l = 2, the colour distance metric
Dc(
R1,
R2) is defined as
(7.18) 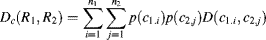
where
n1 and
n2 are the colour bin's number in region
R1 and
R2, respectively,
p(
c1,j) is the probability of the
ith colour bin among
n1 colours in region
R1, and
p(
c2,j) is the probability of the
jth colour bin among
nj colours in region
R2.. D (
c1i,
c2j) is the difference between the
ith colour bin in region
R1 and the
jth colour bin in region
R2 when the colour histogram is built in advance. The exponential item in
Equation 7.17 is to reduce the effect from farther regions. Here σ
s controls the strength of spatial distance weight. The region saliency map is very easy to be cut by threshold to obtain the object.
Colour contrast serves as a global feature in the computation of the saliency map, which combines image segmentation and visual attention concepts together and can detect a single larger size object in natural scene if there is one larger object with arbitrary shape and size in the scene.
In [18], other features are considered for computing the saliency map aiming at object detection. The saliency of a pixel in visual attention is related to the pixel's location with its context: each pixel with its surrounding pixels forms an image patch and there are three kinds of features for each patch in [18]: dissimilarity, immediate context and high-level factors related to the task. Since the feature of dissimilarity uses both global and local contexts, we introduce it here for the reader's reference. The dissimilarity between patches based on colour and position contrast can be found by using the following equation:
(7.19) 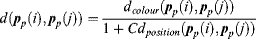
where
pp(·) denotes the vectorized patch and
dcolour is the distance between two vectors in CIE LAB colour space,
dposition is the spatial distance between two patches, and
C is a constant. From
Equation 7.19, the dissimilarity feature is proportional to the colour contrast and inversely proportional to the distance between the two patches. By computing
Equation 7.19, the
Kp most similar patches are found and stored as
qp(k),
k = 1, . . .
Kp (these patches may be background), and the saliency at pixel
i for scale
r is obtained by
Equations 7.19 and
7.20:
(7.20) 
From
Equation 7.20, the larger the dissimilarity between the patch
i and the
Kp most similar patches the more salient the patch
i is. The superscript
r of
SM represents the scale index if multiscales are considered in the computation. Summation of the saliency maps for all scales
r, generates the total saliency map for the feature of dissimilarity.
The methods of object detection based on the visual attention concept in this subsection mainly aim at a single object with large size in a simple natural environment. This larger size object has homogenous content or a smooth region in its interior, and in general, bottom-up computational models based on local features find it difficult to pop out the whole object. The various features of computer vision a (global features, statistical histograms and so on, apart from local features) can be used in saliency computation. In addition, larger size object detection in background may be a two-class process, and the entire object can be detected as saliency by hard thresholding. A merit of such an approach is that it does not need to be learned in advance, since these features are common for distinguishing the foreground with unknown size and shape from the background, and independent of any specific object. The saliency maps of these models calculate in the original resolution so that object detection can be directly used in the original image and there is no need to adapt the size. The partial code of these models mentioned in Section 7.2.2 can be found in [46].
It is believed that a more effective means for learning-free object detection based on the visual attention concept will be developed [13, 47, 48] as science and technology progresses. We hope that the above case studies help readers to understand and explore modelling and applications more effectively.
7.2.3 Object Detection with a Training Set
In Sections 7.1.3 and 7.2.1, we have introduced the classification methods with training and how to combine the selective regions of the bottom-up saliency map with these classification methods to detect an object in a scene. This subsection presents a method of object detection by conditional random field (CRF) to detect objects as proposed in [16, 49]. All local, regional and global features for an image/video are taken into account in this method, and the parameters of CRF are decided by learning and inference from the labelled database which introduced in Chapter 6. As with the approaches in Section 7.2.2, this approach can detect salient objects without knowledge of objects and object category in static and dynamic images. Since we discuss how features are combined with the classical CRF detection method in [16], only the features for salient objects in static images are introduced in the following text.
7.2.3.1 Salient Object Features
The local, regional and global features defined in [16] are based on each pixel; that is, each pixel is represented as its local, regional and global features. The local features are like those in the BS model (introduced in Chapter 3), which compute local contrast in a Gaussian pyramid. The difference between each pixel and its neighbour pixels is calculated at each pixel in each resolution image of the Gaussian pyramid, which creates several contrast images for different resolutions. Then, these contrast images are modulated to the original image size. Finally, they are combined and normalized to a contrast feature map denoted as 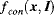 , where x is the location coordinate of the pixel under consideration (in the following text of this subsection, we use x to denote the pixel), the subscript con denotes the contrast feature and I is the original image.
, where x is the location coordinate of the pixel under consideration (in the following text of this subsection, we use x to denote the pixel), the subscript con denotes the contrast feature and I is the original image.
The regional feature is a histogram difference between the centre region Rc and the surrounding region Rs at each pixel. The centre region Rc is a rectangle region probably enclosing a salient object, and an example is shown in Figure 6.2(b) of Chapter 6, where the object is labelled by drawing a rectangular window artificially as the ground-truth. The regional feature is also computed at each pixel, and the rectangular centre region at each pixel is imagined with different sizes and aspect ratios. The surrounding region Rs is the margin enclosing the region Rc with varying distances to the edge of the Rc region for the pixel x. It is noticed that at each pixel there are several possible sizes for its centre and surrounding regions. For a given region size, the histogram distance between Rc and Rs in RGB colour space can be calculated. In [16], the chi-square distance is used to compute the histogram distance between Rc and Rs, defined as
(7.21) 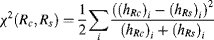
where i denotes a quantized colour bin in the histogram, and hRc and hRs represent the histograms in central and surrounding regions, respectively, which satisfy
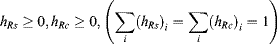
For each pixel, the chi-square distances between the rectangular central regions (containing the pixel under consideration) and the surrounding regions (enclosing the centre region) are calculated for different region sizes and aspect ratios. The optimal size and aspect ratio of the central and surrounding regions of the pixel located at x are the highest chi-square distance among all sizes and aspect ratios, which is defined as Rc*(x) and Rs*(x), where symbol * means the optimal size for the region. The feature of the histogram difference at pixel x is given by
(7.22) 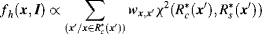
where weight wxx′ is the Gaussian distance between pixels x and x′. From Equation 7.22, the feature of the centre–surround histogram at pixel x,  , is a weighted sum of χ2 distance of pixels in the optimal centre regions enclosing the pixel x, and the effect of the pixels a long way from the pixel x is smaller than that near the pixels. Equation 7.22 represents a regional feature since the feature of each pixel is based on the colour histogram of the centre–surround regions.
, is a weighted sum of χ2 distance of pixels in the optimal centre regions enclosing the pixel x, and the effect of the pixels a long way from the pixel x is smaller than that near the pixels. Equation 7.22 represents a regional feature since the feature of each pixel is based on the colour histogram of the centre–surround regions.
The global feature is the colour spatial distribution, because a wide colour distributed in the tested image is often not possible to be the salient object region. The colour spatial distribution can be estimated by its spatial position variance. Suppose that all colours of the tested image can be approximated by the Gaussian mixture model which is composed of several Gaussian functions with different mean colours, covariance matrices and weights. In statistical signal processing, the parameters of the Gaussian mixture model can be estimated, so the colour at each pixel is assigned to a colour component with the probability p(cl/Ix) given by the Gaussian mixture model. The spatial variance for colour component cl is defined as
(7.23) 
with  , and the mean of horizontal and vertical positions for colour component cl are
, and the mean of horizontal and vertical positions for colour component cl are  and
and 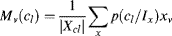 , respectively, where xh and xv are the horizontal and vertical coordinates of pixel x. The spatial variance for colour component cl (Equation 7.23) is normalized to [0, 1]. The colour spatial distribution feature at pixel x is given by a weighted summation:
, respectively, where xh and xv are the horizontal and vertical coordinates of pixel x. The spatial variance for colour component cl (Equation 7.23) is normalized to [0, 1]. The colour spatial distribution feature at pixel x is given by a weighted summation:
(7.24) 
From Equation 7.24, when spatial variance of a colour approaches zero, that is the colour centralizes on a small spatial region, the feature value is the largest. Now all local, regional and global features at a pixel are computed, and then are normalized in [0, 1].
7.2.3.2 Object Detection by CRF
CRF is a conventional method in machine learning, which assigns a well-defined probability distribution over possible labelling. The idea is to find the optimal labels for the pixels in the image, such that the conditional probability approaches a maximum. Consider that the label of each pixel in an image is a random variable. The group of those random variables in the image can be described as a random field. In object detection, suppose the random labelling at each pixel is one or zero for object and background respectively. CRF is defined as the probability of random field labelling under the condition of a given observation. In the training stage, the parameters of CRF need to be learnt with a known labelled training set, and in the testing stage the labels with larger condition probability are regarded as the result of classification.
Suppose that the probability of a labelling configuration A = {ax}, ax  {0, 1} for a given image I is modified as a conditional probability distribution p(A/I) shown as
{0, 1} for a given image I is modified as a conditional probability distribution p(A/I) shown as
(7.25) 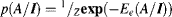
where Z is the normalization function and Ee(A/I) is the energy. The smaller the energy, the larger probability is. The energy can be represented as
(7.26) 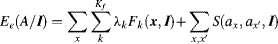
where the first term is a linear combination of Kf normalized salient features mentioned above, k is the feature's index for local, regional and global features, k {con, h, s}, for Kf = 3 in static image, Fk is satisfied by
(7.27) 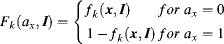
where ax is the possible label at position x and λk is the weight of the kth feature. It can be seen from the above equation, while ax = 1 (x belongs to the object), the larger the feature, the smaller is Fk, resulting in a small contribution to the energy (Equation 7.26). Conversely, if x belongs to the background (ax = 0) larger features lead to larger energy.
The second term of Equation 7.26 represents the spatial relationship between the labels of two adjacent pixels (x and x′), which can be described as
(7.28) 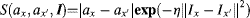
where Ix and Ix′ are the colour for the adjacent pixels (x and x′), respectively. η is an inverse colour mean in the image. When ax and ax′ belong to different labels, the larger colour distance means smaller energy for Equation 7.26.
The conditional probability distribution in Equation 7.26 needs to be learned from labelled samples in order to estimate the linear weights {λk}, k = 1, . . . Kf, in a training database. Maximized likelihood criteria or other probability estimating methods are used to estimate the parameters in CRF, which is omitted since it belongs to other areas. The advantage of CRF is that it is easy to increase the kinds of features (increase Kf) in the energy function (Equation 7.26) if necessary, and it can be used in sequential images if the salient object features in sequential images are extracted.
When Equation 7.26 is available after training, the object detection in a tested image can be achieved through features extraction from the tested image and CRF computation.
In this method, local feature extraction refers to features from the BS model (with multiple resolution). Similarly, as in Section 7.2.2, the regional and global features are effective for detecting bigger size objects in a scene. The CRF model is an engineering approach because there is no evidence that our brains have done these complex computations, and these computations are time-consuming.
7.2.4 Object Recognition Combined with Bottom-up Attention
Sections 7.2.2 and 7.2.3 consider the single object detection with larger size in a scene. When there are multiple objects in a cluttered scene or there are unwanted objects in the scene, the top-down knowledge has to participate in the object recognition. The following two examples show object recognition based on visual attention.
7.2.4.1 Neural Network Classification as the Back-end of Object Recognition
The early examples which combined visual attention model with neural network classification are proposed in [2, 3, 5]. In the training stage, some known objects are cut into sub-images with a fixed size and they form training images in [2, 3]. Each sub-image with a known object is input to a neural network with hierarchical S-C layer architectures referred to an HMAX network [50, 51]. It consists of several S-C layer architectures: S1-C1, S2-C2, . . . to extract scale-invariance and shift-invariance features. The units in the S1 layer of the network tune to different orientation features of multiple scales for the sub-image, and then these extracted features are feed-forwarded to the C1 layer where the translation and scale invariance features are extracted by maximizing the operation of pooling over units tuned to the same feature but different scale and position. The units in the high layer (S2 and C2 etc.) respond to more complex invariance features, and the output of the final C layer (e.g., the C2 layer, if the neural network is composed of two S-C layer architectures) feeds to view-tuned units for object identity. The connected weights of the HMAX network are learned in the training stage, so that all instances including different objects and backgrounds in the training set can be correctly identified by the HMAX network.
The testing stage employs a bottom-up computational model (BS model) to rapidly choose the few most salient locations from the saliency map in any given scene (simple or cluttered background). Winner-take-all and inhibition-of-return operations are performed on the saliency map such that attention focuses can be scanned in the order of decreasing saliency. For each attention focus, a sub-image with the same size as that of the training stage covering the focus is input to the HMXA network and the output of the HMXA network is the result of the category.
This strategy is biologically plausible, because the bottom-up attention simulates the ‘where’ pathway in the visual cortex and the HMXA network with S-C layer architectures mimics the ‘what’ pathway of the visual cortex. Object recognition is the interactional result of where and what pathways. As mentioned above, visual attention can avoid exhaustive search of all sub-images in the scene, and increases the speed of object recognition; in addition, it can improve the recognition ratio when compared with the case without attention [3]. This method has been used for face and object recognition in [2, 3, 5].
7.2.4.2 SIFT Key-points Matching for Attention Region
SIFT features introduced in Section 7.1.2 are with shift, orientation and scale invariance, and they are commonly used in object recognition. At the training stage, the SIFT features (key-points and their descriptors) for each object are extracted from reference images and stored in the database. When a new image is inputted, the algorithm extracts the SIFT features from the new image and compares them with the stored key-points for objects. A matching method (e.g., the nearest neighbour method introduced in Section 7.1.3) is considered to find the matching key-points of one object. If there are several key-points (in general, more than three key-points) in a reference object, successfull matching, the tested object must be with high probability as labelled by the category of the reference object.
For a cluttered scene such as a scene of grocery, a junk-piled room and so on, there will be a number of key-points, and this results in time-consuming feature extraction for the training stage and wrong recognition for the testing stage. A useful idea proposed in [4, 5] is to insert visual attention in the feature extraction and object recognition before all key-points are extracted. First the saliency map by pure bottom-up computational model is created. The possible salient regions for the object candidates are found. The extraction of key-points is based on the luminance contrast peaks across scales, and discards the cluttered image regions outside the attention regions. This operation can be completed by keeping the salient regions and setting the highest grey value (e.g., 255 for 256 grey levels) for other unimportant regions. Thus, only the key-points on the salient regions are extracted. In the recognition stage, only key-points in the attention regions need to be matched to the stored objects. When key-points of all the attention regions are matched, multiple-object recognition or object recognition in a cluttered environment can be achieved.
One problem is that the number of fixation points on the attention models in the training stage is different for low-resolution images than for high-resolution images. Low-resolution images may include fewer objects than those of high resolution, so its fixation number should be fewer. The other reason is that edges of attention regions, while setting the background to 255, need to be smoothed in order to avoid spurious key-points.
The advantage of the consideration of visual attention is to remove many cluttered backgrounds for multiple object recognition. Experiments for video and for cluttered scenes in [4] have shown that the recognition time and the rate of accuracy with the attention mechanism obviously outperforms that without attention for the SIFT algorithm.
