
7.1 Object Detection and Recognition in Computer Vision
Object detection is one kind of image segmentation based on geometrical and statistical features of objects, and object recognition refers to identification of a specific object from other objects including similar objects. Recognition is a further work that takes place after detection; in other words, detection is the important first stage of recognition. For example, face detection in a scene is to find human facial regions that have symmetrical geometrical features and specific skin colour (or other features), while face recognition is to distinguish a specific person from many other people.
7.1.1 Basic Concepts
In general, a raw input image needs to be preprocessed, such as denoising and segmentation. Denoising is mainly accomplished by different low-pass filtering in a spatial or transform domain. The conventional segmentation methods are of three types: region based, edge based and motion based. The region based segmentation includes threshold segmenting by setting one or several intensity values as the thresholds in grey or colour histograms to partition the image, or segmentation with the aid of entropy, region growing from some seed pixels, clustering, graph segmentation, region marking, region splitting and merging and so on. Edge based methods include edge extraction, active contour (snake) models and so on. The motion based methods mainly use the difference between two adjacent frames and optical flow. In the preprocessing stage, prior knowledge is not considered. The preprocessing methods are not specially presented here. Some of them (e.g., segmentation) which are related to visual attention [13–20] are presented in Section 7.2.
Conventional object detection and recognition are to learn visual categories from a training dataset, and then to identify new instances of those categories. So they need supervised learning with a training dataset. Two stages are necessary for object detection and recognition: one is feature extraction for each window in an image (each key-point or the whole image) and the other is classification that compares the new instance with labelled samples in the training dataset and decides which class it belongs to. In this sense, object recognition has more than two categories to be identified. If there are only two categories (object/not-object or foreground/background) that need to be recognized, it becomes object detection.
7.1.2 Feature Extraction
Features extracted from an object or image region can succinctly represent the object and distinguish its category from other categories, and this is a crucial issue in object detection and recognition. In general, these extracted features include both global and local features. The global features are obtained by an image transform such as principal components analysis (PCA), independent components analysis (ICA), Fourier transform, wavelet transform, intensity or colour histogram and so on. Among these global features, PCA is an optimal representation from high dimension to low dimension while keeping the main information in the image or the image region. The local features include edges, intensity and colour obtained by filtering as mentioned in the BS model of Chapter 3, geometric features (line, corner, angle, gradient and symmetry) attained by using early Hough transform [36], corner detecting operator [37] and statistical features on a local region or pixel-wise (one- and two-order moment, higher-order moment and entropy).
A challenge for global and local feature extraction is to keep the invariance: shift invariance, rotation invariance, affine invariance, luminance invariance and size invariance. When a new instance (object) is different from the same object in the training set in position, orientation, viewing angle and size it is difficult to be detected and recognized, because the global or local features, as mentioned above, are not robust to a wide variety, though some features have invariance in certain aspects. For instance, moment features have rotation invariance, but they cannot keep affine invariance; coefficients of polar Fourier transform have rotational invariance but no other invariance.
Recently, the local invariant feature detectors and descriptors have been developed in [38–40], which can operate under different viewing conditions, even with partial occlusion. The local features extraction system, called the scale invariant feature transform (SIFT) was proposed in [39], and then an improved method called speeded up robust feature (SURF) is proposed by [40] in order to speed up the computation time of SIFT. The underlying ideas of SIFT and SURF are similar. In some applications of attention-based object recognition, the local key-points extracted by SIFT for a new object are often used to match the key-points of the labelled object in the training database. For the applications in Sections 7.2.4, 7.3 and 7.5, a simple introduction to SIFT is to be given as follows.
The features extraction by SIFT include four steps: (1) scale-space extremes detection; (2) key-point localization; (3) orientation assignment; (4) structure of key-point descriptor.
(7.3) ![]()
7.1.3 Object Detection and Classification
Suppose the features of an object (an image patch) or a key-point of image are extracted by using the approach mentioned above, and each of them can be represented as a feature vector f, ![]() , referred to as a sample, where fi is the value of the ith feature, i = 1, 2, . . . d and d is the dimension of the feature vector. For object detection, we need to find a location or an image patch in a scene where a desired object is located. Object recognition needs to recognize the object's label in the scene, if there are multiple objects to be classified.
, referred to as a sample, where fi is the value of the ith feature, i = 1, 2, . . . d and d is the dimension of the feature vector. For object detection, we need to find a location or an image patch in a scene where a desired object is located. Object recognition needs to recognize the object's label in the scene, if there are multiple objects to be classified.
Both detection and recognition belong to the classification problem. Object detection separates the scene into two classes: the object region and the no-object region, as with object segmentation, and object recognition classifies the object into its category as a multiclass problem. A classification program operates in a set of typical objects called the training set in which each sample is labelled in advance. Suppose that in the training set the feature vector and label of each sample are known, represented as ![]() , where the superscript
, where the superscript ![]() is the label of the jth sample
is the label of the jth sample ![]() , and c is the number of classes in the training set. Assume class l includes Nl samples in the training set, and then the total sample number is N = N1 + N2 + . . . Nc. Evidently, c = 2 for object detection and c > 2, for object recognition.
, and c is the number of classes in the training set. Assume class l includes Nl samples in the training set, and then the total sample number is N = N1 + N2 + . . . Nc. Evidently, c = 2 for object detection and c > 2, for object recognition.
Suppose that each sample with d features is one point in a d-dimensional feature space, and the classification aims at finding a discriminant function by means of learning the samples in the training set, such that all samples in the training set can be correctly classified. The discriminant function may be linear, piecewise or non-linear. Figure 7.1 shows the three cases in two-dimensional (f1 and f2) feature space.
Figure 7.1 Discriminant function for two classes and multiple classes: (a) linear discriminant function for A and B classes; (b) non-linear discriminant function for A and B classes; (c) piecewise discriminant function for four classes (A, B, C and D)

Figure 7.1(a) shows the samples in two classes that are linearly separable, and the discriminant function is a straight line. In Figure 7.1(b), the two categories are non-linearly separable, and the rounded discriminant function can separate the two classes. The multiclasses discriminant function is shown in Figure 7.1(c). In the real world, some samples may be overlapped, and statistical estimation criteria are necessary, such as minimum error rate estimation and minimum risk estimation based on Bayesian decision. Although there are many classification methods in engineering applications, here we only introduce the commonly used methods in the next application examples.
Suppose that all samples in the training set are correctly labelled after the training phase. Given a testing sample f with unknown label, the classification algorithms to label the testing sample are presented as follows.
(7.4) ![]()
(7.5) ![]()
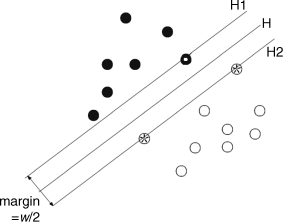
Figure 7.2 Optimal hyperplane in a high-dimensional space
The discriminant function for a two-class issue is
where ![]() is the weight vector for a neural network with a single neuron whose input is
is the weight vector for a neural network with a single neuron whose input is ![]() and the output is label yl of
and the output is label yl of ![]() ,
, ![]() , and b is the threshold of the neuron. H is an optimal discriminant hyperplane that satisfies
, and b is the threshold of the neuron. H is an optimal discriminant hyperplane that satisfies
(7.7) ![]()
Two parallel lines H1 and H2 pass the two-class samples (two hollow circles with a star and one solid circle with a white point in Figure 7.2) that have the nearest distance to the optimal hyperplane, respectively. Both H1 and H2 are parallel to the optimal hyperplane H. The distance between H1 and H2 is the margin of the two classes. The optimal separate hyperplane should separate the two classes correctly and make the margin maximum. The samples passed by H1 and H2 are referred to as support vectors for the two-class issue. The following procedures are how to find the optimal hyperplane H.
Let us normalize the discriminant function ![]() and let the two-class samples satisfy
and let the two-class samples satisfy ![]() . If the support vectors for the two classes are denoted by
. If the support vectors for the two classes are denoted by ![]() and
and ![]() that are substituted into Equation 7.6, considering the support vectors satisfy
that are substituted into Equation 7.6, considering the support vectors satisfy ![]() and
and ![]() , then we can obtain the margin between hyperplanes H1 and H2 equals
, then we can obtain the margin between hyperplanes H1 and H2 equals ![]() , according to
, according to
![]()
![]()
Evidently, maximizing the margin ![]() means to minimize the weight vector
means to minimize the weight vector ![]() . Thus, the classification issue becomes an optimal problem, that is minimizing
. Thus, the classification issue becomes an optimal problem, that is minimizing ![]() under the constraint condition
under the constraint condition ![]() . A cost function with a Lagrange function is built to find the optimal hyperplane H, which is defined as
. A cost function with a Lagrange function is built to find the optimal hyperplane H, which is defined as
where ![]() is the Lagrange multiplier for the ith sample,
is the Lagrange multiplier for the ith sample, ![]() is number of samples in the training set, and
is number of samples in the training set, and ![]() is the label of sample
is the label of sample ![]() which is known in the training set (
which is known in the training set (![]() = 1 while
= 1 while ![]() and
and ![]() = −1 while
= −1 while ![]() ). Minimizing the function of Equation 7.8 by setting to zero for the partial derivative of Equation 7.8 with respect to vector
). Minimizing the function of Equation 7.8 by setting to zero for the partial derivative of Equation 7.8 with respect to vector ![]() and variable b respectively, we can get
and variable b respectively, we can get
Substituting the above equation into Equation 7.8, we put the question into its dual question, that is to solve the maximum value of
for the constraint condition ![]() .
.
Maximizing Equation 7.9 by setting the partial derivative of each Lagrange multiplier to zero, we can obtain all the optimal Lagrange multipliers, ![]() for i = 1, 2, . . . , N, and the optimal weight vector is
for i = 1, 2, . . . , N, and the optimal weight vector is
It is worth noting that most optimal Lagrange multipliers are zeros, except support vectors, and the optimal variable b* can be obtained by setting the second term of Equation 7.8 to zero for given ![]() and support vector. The optimal parameters (
and support vector. The optimal parameters (![]() and b*) can be used to label a new sample
and b*) can be used to label a new sample ![]() according to the following discriminant function
according to the following discriminant function
In fact, the dimension of ![]() may be very high (infinite) and the inter-product terms
may be very high (infinite) and the inter-product terms ![]() and
and ![]() in Equation 7.9 cannot be really implemented. If we use a symmetrical function as the kernel, the inter-product of
in Equation 7.9 cannot be really implemented. If we use a symmetrical function as the kernel, the inter-product of ![]() and
and ![]() can be represented by the samples in original feature space; then we rewrite Equation 7.9 and 7.11 as
can be represented by the samples in original feature space; then we rewrite Equation 7.9 and 7.11 as
Thus, for the given N training samples ![]() the steps of the SVM are: (1) select kernel function K; (2) calculate Equation 7.12 by maximizing
the steps of the SVM are: (1) select kernel function K; (2) calculate Equation 7.12 by maximizing ![]() to obtain the optimal Lagrange multipliers,
to obtain the optimal Lagrange multipliers, ![]() ; (3) compute the optimal weight vector w* by using Equation 7.10; (4) find the support vectors from the samples with
; (3) compute the optimal weight vector w* by using Equation 7.10; (4) find the support vectors from the samples with ![]() in the training set and compute the variable b* while setting the second term of Equation 7.8 to zero. For the testing stage, the new sample can be classified by Equation 7.13.
in the training set and compute the variable b* while setting the second term of Equation 7.8 to zero. For the testing stage, the new sample can be classified by Equation 7.13.
With the SVM method, it is very simple to classify new samples; the approach is very robust to noise, and has been used in many applications for object detection and recognition. Notice that (1) although original SVM operates in the case where two classes can be separated, it can still suit the inseparable case by adding a relaxed term in the constraint condition in Equation 7.8; (2) for a multiclass issue, it can decompose the multiclass issue to a number of two-class issues (each class vs. the remaining classes), and therefore the SVM can also solve the multiclass issue.
All the classification algorithms mentioned above need to know the cluster of all samples with their labels in a training set (NN, k-NN, decision tree) or to learn the discriminant function (neural network, SVM) in advance, and this needs prior knowledge (experience). In addition, full search in a scene is probably required. For example, to find the object patch (or object feature vector) in a scene, all the possible patches (or feature vectors), through shifting the patch window in the scene, are compared with the object patch in the training set, or directly inputted to the learned neural network. This full search strategy is time consuming and does not meet the requirements of real-world applications. A pure visual attention method or visual attention combining with the engineering methods introduced above will greatly improve the effect and efficiency.