3.5 Attention Modelling Based on Information Maximizing
The BS model and its variations are based on feature integration theory, and the GBVS model with graph theory (which was discussed in the previous section) also works in a similar framework, since they all need low-level feature extraction and integration. Their feature maps obtained by using filters and contrast processes are based on explicit extraction of intensity, colour, orientation and so on, and then the final saliency map is a cross-feature integration. The BS model is very successful for simulating human attentional focus in numerous experiments including artificial and natural scenes.
However, this definition of saliency based on local feature contrast may be somewhat questionable since some discarded regions from the feature extracting process in the BS model are possibly fixation locations [7, 34]. For instance, in Figure 3.10(a) many long bars of various colours with random orientation are almost stacked over the full scene except for a small homogeneous region and in Figure 3.10(b), in a regular bar array an absent region appears. Very often, these unique regions in their respective scenes are not detected by these filters in the BS model since there are no orientation or colour features in these regions, but their uniqueness attracts the fixation of human eyes. In the view of information theory, these unique regions have more information than other regions with repeating or random objects.
Figure 3.10 Examples failed in original BS

Also, in the feature extraction stage of the BS model, the filters extracting low-level features are fixed; for example four orientations are equally distributed between 0° and 180°, and are not adaptive to the scene's context. Actually, in the human brain, connections between these cells extracting features and their receptive fields, which the filters are emulating, are obtained by a learning process from input environment. The learning is to capture more useful information from the outside environment and discard the redundancy. Considering the properties of reducing information redundancy mentioned in Section 2.6.3 for both salient and feature filters' design criteria, the model of attention based on information maximization (AIM), is proposed by Bruce et al. [7, 34, 35]. From the view of the AIM model, the locations of attention focus in the input scene are just those places that include maximum information. In general, information is measures by entropy or self-information as defined in Section 2.6.3. The AIM model suggests a computational strategy to estimate self-information at each location, in which principal components analysis (PCA) and independent components analysis (ICA) are used as approaches to reduce redundancy and to achieve basis functions like simple cells' receptive fields. We will now introduce the idea of the AIM model, basis function attaining, self-information estimation and computational steps of the AIM model in detail.
3.5.1 The Core of the AIM Model
Figure 3.10 gives us a challenge: what is the saliency in scenes? Edges of objects or some locations with high contrast are often considered as salient regions in a scene but sometimes they may turn into inattentive areas. The reason is probably that there is significant redundancy in these inattentive areas. A game to guess the structure of an obscured region on a picture is proposed in [35]. Several observers are asked to guess the structure in covered patches of scene. These patches with repeated or similar structure to their surround may be guessed correctly with a high chance, and by contrast, the observers probably make mistakes in the covered patches if they are different from their surround. An example is shown in Figure 3.11(a) and (b) – an outdoor garden without and with obscured patches respectively. The obscured regions A and B (black solid circles) located in the blue sky and green lawn of Figure 3.11(b) are very easy to correctly estimate and the stonework (region C) that stands at the centre of the pool might be a difficult guess. The intuitional example means that the context of the neighbourhood is significant for measuring the salient location. This is equivalent to self-information related to each location and its context. Hence the AIM model suggests that the saliency of visual content may be equal to a measure of the information presented locally within a scene as defined by its surround [35].
Figure 3.11 An example of a guessing game (a) original image (b) the image with obscured patches

Self-information is a measure of the information content associated with the outcome of a random variable. The uncertainty of a random variable is often described as the probability by taking statistics over time or over a set. If the random variable is a probabilistic event x, the self-information ![]() of the event x depends only on the probability of that event associated with its context.
of the event x depends only on the probability of that event associated with its context.
where p(x) is the probability of x. In the AIM model, the event can be regarded as a possible value that the observer guesses at a concealed image patch, and the context may be the patches surrounding the concealed image patch or even all the patches over whole scene. The unit of self-information depends on the base of logarithm used in its calculation. However, whatever unit you take it will not influence the result because saliency in a scene is relative. Evidently from Equation 3.34, the smaller probability with which the event does indeed occur, the larger the self-information associated with receiving the information. Self-information of a certain event is zero and the self-information of an event, that almost never happens, is equal to infinity. The measure of self-information is positive and additive. If an event A is composed of several independent events, then the amount of information that event A happens is equal to the sum of the information of the various independent events. Self-information is sometimes used as a synonym for entropy; that is entropy is the expected value of self-information (Equations 2.11 and 2.12 in Section 2.6.3). It is worth stressing that in the AIM model a local region (image patch) is considered as an event and the entropy or self-information is defined on the surround of local region under consideration.
The next step is how to estimate the self-information of each image patch defined in its context. Even for a very small image patch, for example a 7 × 7 RGB patch, the estimation of probability density function residing in a very high dimensional space (49 × 3 dimensions) is very difficult and unfeasible, since it requires calculating a joint likelihood for a local window in RGB space based on measuring a mass of data, resulting in high computational complexity. Therefore, the dimensionality reduction adopted in many statistical applications is necessary. The AIM model employs ICA, introduced in Section 2.6.3, to reduce the dimensionality of the colour image patch. The basis functions of ICA are obtained by learning large numbers of patches, randomly sampled from thousands of natural images. An arbitrary test image patch can be described by the basis functions and the coefficient of each basis. Since the number of basis functions of ICA is far less than the dimension of an image patch, an image patch of high dimension can be represented by the coefficients of the ICA basis bank with low dimension, which reduces the computational complexity. On the other hand, these coefficients of the ICA basis bank are statistically independent, so the probability of an image patch that appeared is the product of the probability of these independent coefficients that respectively appeared. Therefore, it simplifies the computation of joint likelihood for self-information of the image patch under consideration. From the viewpoint of biology, we regard an image patch as a receptive field of simple cells in the primary visual cortex, and each basis of ICA is the weight vector to extract a related feature in the receptive field. Several cells share a receptive field to extract various features, and this is similar to filters of the feature extraction stage in the BS model. As the aforementioned difference from the BS model, these filters are not fixed and are obtained by learning from external stimuli. They include more general features such as spatial frequency, orientation, colour and position.
In summary, the AIM model consists of two parts: one is learning of basis functions by ICA and the other is self-information calculation of the image patch at each location defined on its surround. In the latter part, three steps are needed: (a) If the basis functions of ICA are given, the patch under consideration and its surround patches on the scene are projected onto each basis of ICA to get the related coefficients; (b) the probability density function of each coefficient defined on both the centre and surround patches is estimated by histogram or Gaussian kernel; (c) according to the probability density function of each coefficient and their independence, the self-information can be calculated by Equation 3.34 in each location on the scene.
Finally, the saliency map based on the AIM criterion is generated. The computational equation and drawing for each part and step are discussed below.
3.5.2 Computation and Illustration of Model
(3.36) ![]()
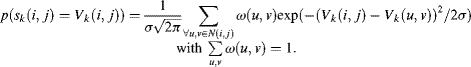
(3.40) 
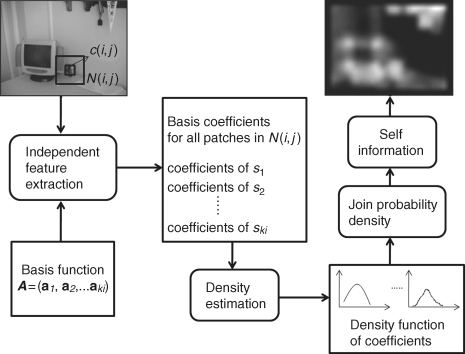
Figure 3.12 The framework for learning basis of ICA, here each basis of ICA, ![]() , is a recovered 2D colour patch. The learning basis set of x(t) is 360,000 image patches randomly sampled from 3600 nature images [35]
, is a recovered 2D colour patch. The learning basis set of x(t) is 360,000 image patches randomly sampled from 3600 nature images [35]
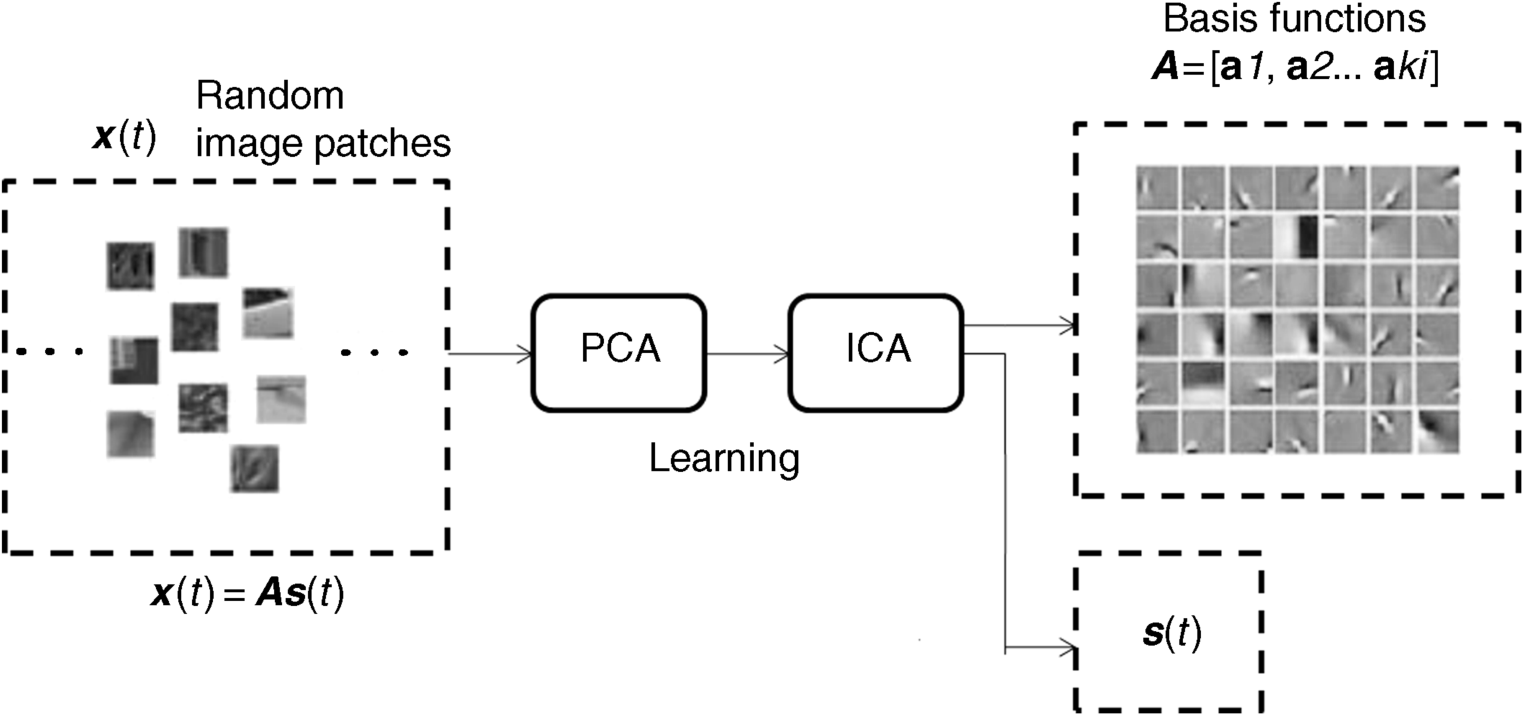
Figure 3.13 The flowchart of the AIM computational model