
The star schema is a database pattern that facilitates reporting. Star schemas are appropriate for the processing of events, such as website visits, ad clicks, or financial transactions. Event information (metrics, such as temperature or purchase amount) is stored in fact tables linked to much smaller dimension tables. Star schemas are denormalized, which places the responsibility of integrity checks to the application code. For this reason, we should only write to the database in a controlled manner. If you use SQLAlchemy for bulk inserts, you should choose the Core API over the ORM API or use straight SQL. You can read more about the reasons at http://docs.sqlalchemy.org/en/rel_1_0/faq/performance.html (retrieved September 2015).
Time is a common dimension in reporting. For instance, we can store dates of daily weather measurements in a dimension table. For each date in our data, we can save the date, year, month, and day of year. We can prepopulate this table before processing events and then add new dates as needed. We don't even have to add new records to the time dimension table if we assume that we only need to maintain the database for a century. In such a case, we will just prepopulate the time dimension table with all the possible dates in the range that we want to support. If we are dealing with binary or categorical variables, pre-populating the dimension tables should be possible too.
In this recipe, we will implement a star schema for direct marketing data described in http://blog.minethatdata.com/2008/03/minethatdata-e-mail-analytics-and-data.html (retrieved September 2015). The data is in a CSV file from a direct marketing campaign. For the sake of simplicity, we will ignore some of the columns. As a metric, we will take the spend column with purchase amounts. For the dimensions, I chose the channel (Phone, Web, or Multichannel), the zip code (Rural, Suburban, or Urban) and segment (Mens, Womens, or no e-mail). Refer to the following entity-relationship diagram:

The following code downloads the data, loads it in a database, and then queries the database (refer to the star_schema.py file in this book's code bundle):
- The imports are as follows:
from sqlalchemy import Column from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import ForeignKey from sqlalchemy import Integer from sqlalchemy import String from sqlalchemy.orm import sessionmaker from sqlalchemy import func import dautil as dl from tabulate import tabulate import sqlite3 import os from joblib import Memory Base = declarative_base() memory = Memory(cachedir='.')
- Define the following class to represent the ZIP code dimension:
class DimZipCode(Base): __tablename__ = 'dim_zip_code' id = Column(Integer, primary_key=True) # Urban, Suburban, or Rural. zip_code = Column(String(8), nullable=False, unique=True) - Define the following class to represent the segment dimension:
class DimSegment(Base): __tablename__ = 'dim_segment' id = Column(Integer, primary_key=True) # Mens E-Mail, Womens E-Mail or No E-Mail segment = Column(String(14), nullable=False, unique=True) - Define the following class to represent the channel dimension:
class DimChannel(Base): __tablename__ = 'dim_channel' id = Column(Integer, primary_key=True) channel = Column(String) - Define the following class to represent the fact table:
class FactSales(Base): __tablename__ = 'fact_sales' id = Column(Integer, primary_key=True) zip_code_id = Column(Integer, ForeignKey('dim_zip_code.id'), primary_key=True) segment_id = Column(Integer, ForeignKey('dim_segment.id'), primary_key=True) channel_id = Column(Integer, ForeignKey('dim_channel.id'), primary_key=True) # Storing amount as cents spend = Column(Integer) def __repr__(self): return "zip_code_id={0} channel_id={1} segment_id={2}".format( self.zip_code_id, self.channel_id, self.segment_id) - Define the following function to create a SQLAlchemy session:
def create_session(dbname): engine = create_engine('sqlite:///{}'.format(dbname)) DBSession = sessionmaker(bind=engine) Base.metadata.create_all(engine) return DBSession() - Define the following function to populate the segment dimension table:
def populate_dim_segment(session): options = ['Mens E-Mail', 'Womens E-Mail', 'No E-Mail'] for option in options: if not dl.db.count_where(session, DimSegment.segment, option): session.add(DimSegment(segment=option)) session.commit() - Define the following function to populate the ZIP code dimension table:
def populate_dim_zip_code(session): # Note the interesting spelling options = ['Urban', 'Surburban', 'Rural'] for option in options: if not dl.db.count_where(session, DimZipCode.zip_code, option): session.add(DimZipCode(zip_code=option)) session.commit() - Define the following function to populate the channel dimension table:
def populate_dim_channels(session): options = ['Phone', 'Web', 'Multichannel'] for option in options: if not dl.db.count_where(session, DimChannel.channel, option): session.add(DimChannel(channel=option)) session.commit() - Define the following function to populate the fact table (it uses straight SQL for performance reasons):
def load(csv_rows, session, dbname): channels = dl.db.map_to_id(session, DimChannel.channel) segments = dl.db.map_to_id(session, DimSegment.segment) zip_codes = dl.db.map_to_id(session, DimZipCode.zip_code) conn = sqlite3.connect(dbname) c = conn.cursor() logger = dl.log_api.conf_logger(__name__) for i, row in enumerate(csv_rows): channel_id = channels[row['channel']] segment_id = segments[row['segment']] zip_code_id = zip_codes[row['zip_code']] spend = dl.data.centify(row['spend']) insert = "INSERT INTO fact_sales (id, segment_id, zip_code_id, channel_id, spend) VALUES({id}, {sid}, {zid}, {cid}, {spend})" c.execute(insert.format(id=i, sid=segment_id, zid=zip_code_id, cid=channel_id, spend=spend)) if i % 1000 == 0: logger.info("Progress %s/64000", i) conn.commit() conn.commit() c.close() conn.close() - Define the following function to download and parse the data:
@memory.cache def get_and_parse(): out = dl.data.get_direct_marketing_csv() return dl.data.read_csv(out) - The following block uses the functions and classes we defined:
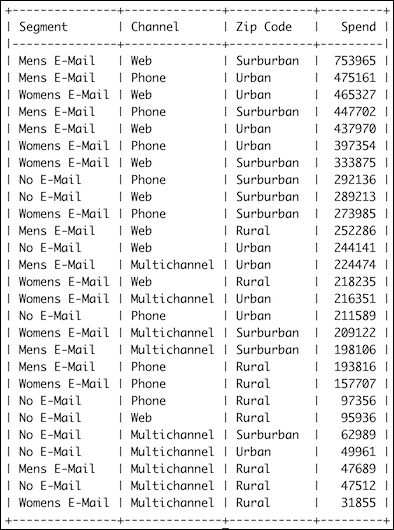
if __name__ == "__main__": dbname = os.path.join(dl.data.get_data_dir(), 'marketing.db') session = create_session(dbname) populate_dim_segment(session) populate_dim_zip_code(session) populate_dim_channels(session) if session.query(FactSales).count() < 64000: load(get_and_parse(), session, dbname) fsum = func.sum(FactSales.spend) query = session.query(DimSegment.segment, DimChannel.channel, DimZipCode.zip_code, fsum) dim_cols = (DimSegment.segment, DimChannel.channel, DimZipCode.zip_code) dim_entities = [dl.db.entity_from_column(col) for col in dim_cols] spend_totals = query.join(FactSales, *dim_entities) .group_by(*dim_cols).order_by(fsum.desc()).all() print(tabulate(spend_totals, tablefmt='psql', headers=['Segment', 'Channel', 'Zip Code', 'Spend']))
Refer to the following screenshot for the end result (spending amounts in cents):
- The Star schema Wikipedia page at https://en.wikipedia.org/wiki/Star_schema (retrieved September 2015)