
Open Computing Language (OpenCL), initially developed by Apple Inc., is an open technology standard for programs, which can run on a variety of devices, including CPUs and GPUs that are available on commodity hardware, such as the machine I am using for this recipe. Since 2009, OpenCL has been maintained by the Khronos Compute Working Group. Many hardware vendors, including the one I am partial to, have an implementation of OpenCL.
OpenCL is a language resembling C (actually, there are multiple C dialects or versions) with functions called kernels. Kernels can run in parallel on multiple processing elements. The hardware vendor gives the definition of the processing element. OpenCL programs are compiled at runtime for the purpose of portability.
Portability is the greatest advantage of OpenCL over similar technologies such as CUDA, which is an NVIDIA product. Another advantage is the ability to share work between CPUs, GPUs, and other devices. It has been suggested to use machine learning for optimal division of labor.
Pythonistas can write OpenCL programs with the PyOpenCL package. PyOpenCL adds extra features, such as object cleanup and conversion of errors, to Python exceptions. A number of other libraries use and in some ways enhance PyOpenCL (refer to the PyOpenCL documentation).
Install pyopencl with the following command:
$ pip install pyopencl
I tested the code with PyOpenCL 2015.2.3. For more information, please refer to https://wiki.tiker.net/OpenCLHowTo.
The code is in the opencl_demo.ipynb file in this book's code bundle:
- The imports are as follows:
import pyopencl as cl from pyopencl import array import numpy as np
- Define the following function to accept a NumPy array and perform a simple computation:
def np_se(a, b): return (a - b) ** 2 - Define the following function to do the same calculation as in the previous step using OpenCL:
def gpu_se(a, b, platform, device, context, program):
- Create a queue with profiling enabled (only for demonstration) and buffers to shuffle data around:
queue = cl.CommandQueue(context, properties=cl.command_queue_properties. PROFILING_ENABLE) mem_flags = cl.mem_flags a_buf = cl.Buffer(context, mem_flags.READ_ONLY | mem_flags.COPY_HOST_PTR, hostbuf=a) b_buf = cl.Buffer(context, mem_flags.READ_ONLY | mem_flags.COPY_HOST_PTR, hostbuf=b) error = np.empty_like(a) destination_buf = cl.Buffer(context, mem_flags.WRITE_ONLY, error.nbytes) - Execute the OpenCL program and profile the code:
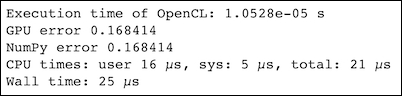
exec_evt = program.mean_squared_error(queue, error.shape, None, a_buf, b_buf, destination_buf) exec_evt.wait() elapsed = 1e-9*(exec_evt.profile.end - exec_evt.profile.start) print("Execution time of OpenCL: %g s" % elapsed) cl.enqueue_copy(queue, error, destination_buf) return error - Generate random data as follows:
np.random.seed(51) a = np.random.rand(4096).astype(np.float32) b = np.random.rand(4096).astype(np.float32)
- Access CPU and GPUs. This part is hardware dependent, so you may have to change these lines:
platform = cl.get_platforms()[0] device = platform.get_devices()[2] context = cl.Context([device])
- Define a kernel with the OpenCL language:
program = cl.Program(context, """ __kernel void mean_squared_error(__global const float *a, __global const float *b, __global float *result) { int gid = get_global_id(0); float temp = a[gid] - b[gid]; result[gid] = temp * temp; } """).build() - Calculate squared errors with NumPy and OpenCL (GPU) and measure execution times:
gpu_error = gpu_se(a, b, platform, device, context, program) np_error = np_se(a, b) print('GPU error', np.mean(gpu_error)) print('NumPy error', np.mean(np_error)) %time np_se(a, b)
Refer to the following screenshot for the end result:
- The PyOpenCL website at http://documen.tician.de/pyopencl/ (retrieved January 2016)