
The bag-of-words model represents a corpus literally as a bag of words, not taking into account the position of the words—only their count. Stop words are common words such as "a", "is," and "the", which don't add information value.
TF-IDF scores can be computed for single words (unigrams) or combinations of multiple consecutive words (n-grams). TF-IDF is roughly the ratio of term frequency and inverse document frequency. I say "roughly" because we usually take the logarithm of the ratio or apply a weighting scheme. Term frequency is the frequency of a word or n-gram in a document. The inverse document frequency is the inverse of the number of documents in which the word or n-gram occurs. We can use TF-IDF scores for clustering or as a feature of classification. In the Extracting topics with non-negative matrix factorization recipe, we will use the scores to discover topics.
NLTK represents the scores by a sparse matrix with one row for each document in the corpus and one column for each word or n-gram. Even though the matrix is sparse, we should try to filter words as much as possible depending on the type of problems we are trying to solve. The filtering code is in ch8util.py and implements the following operations:
- Converts all words to lower case. In English, sentences start with upper case and in the bag-of-words model, we don't care about the word position. Obviously, if we want to detect named entities (as in the Recognizing named entities recipe), case matters.
- Ignores stop words, as those have no semantic value.
- Ignores words consisting of only one character, as those are either stop words or punctuation pretending to be words.
- Ignores words that only occur once, as those are unlikely to be important.
- Only allows words containing letters, so ignores a word like "7th" as it contains a digit.
We will also filter with lemmatization. Lemmatization is similar to stemming, which I will also demonstrate. The idea behind both procedures is that words have common roots, for instance, the words "analysis," "analyst," and "analysts" have a common root. In general, stemming cuts characters, so the result doesn't have to be a valid word. Lemmatization, in contrast, always produces valid words and performs dictionary look-ups.
The code for the ch8util.py file in this book's code bundle is as follows:
from collections import Counter
from nltk.corpus import brown
from joblib import Memory
memory = Memory(cachedir='.')
def only_letters(word):
for c in word:
if not c.isalpha():
return False
return True
@memory.cache
def filter(fid, lemmatizer, sw):
words = [lemmatizer.lemmatize(w.lower()) for w in brown.words(fid)
if len(w) > 1 and w.lower() not in sw]
# Ignore words which only occur once
counts = Counter(words)
rare = set([w for w, c in counts.items() if c == 1])
filtered_words = [w for w in words if w not in rare]
return [w for w in filtered_words if only_letters(w)]I decided to limit the analysis to unigrams, but it's quite easy to extend the analysis to bigrams or trigrams. The scikit-learn TfidfVectorizer class that we will use lets us specify a ngram_range field, so we can consider unigrams and n-grams at the same time. We will pickle the results of this recipe to be reused by other recipes.
The script is in the stemming_lemma.py file in this book's code bundle:
- The imports are as follows:
from nltk.corpus import brown from nltk.corpus import stopwords from nltk.stem import PorterStemmer from nltk.stem import WordNetLemmatizer import ch8util from sklearn.feature_extraction.text import TfidfVectorizer import numpy as np import pandas as pd import pickle import dautil as dl
- Demonstrate stemming and lemmatizing as follows:
stemmer = PorterStemmer() lemmatizer = WordNetLemmatizer() print('stem(analyses)', stemmer.stem('analyses')) print('lemmatize(analyses)', lemmatizer.lemmatize('analyses')) - Filter the words in the NLTK Brown corpus:
sw = set(stopwords.words()) texts = [] fids = brown.fileids(categories='news') for fid in fids: texts.append(" ".join(ch8util.filter(fid, lemmatizer, sw))) - Calculate TF-IDF scores as follows:
vectorizer = TfidfVectorizer() matrix = vectorizer.fit_transform(texts) with open('tfidf.pkl', 'wb') as pkl: pickle.dump(matrix, pkl) sums = np.array(matrix.sum(axis=0)).ravel() ranks = [(word, val) for word, val in zip(vectorizer.get_feature_names(), sums)] df = pd.DataFrame(ranks, columns=["term", "tfidf"]) df.to_pickle('tfidf_df.pkl') df = df.sort(['tfidf']) dl.options.set_pd_options() print(df)
Refer to the following screenshot for the end result:
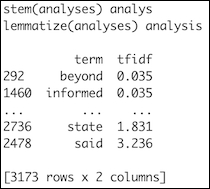
As you can see, stemming doesn't return a valid word. It is faster than lemmatization; however, if you want to reuse the results, it makes sense to prefer lemmatization. The TF-IDF scores are sorted in ascending order in the final pandas DataFrame object. A higher TF-IDF score indicates a more important word.
- The Wikipedia page about the bag-of-words model at https://en.wikipedia.org/wiki/Bag-of-words_model (retrieved October 2015)
- The Wikipedia page about lemmatization at https://en.wikipedia.org/wiki/Lemmatisation (retrieved October 2015)
- The Wikipedia page about the TF-IDF at https://en.wikipedia.org/wiki/Tf%E2%80%93idf (retrieved October 2015)
- The Wikipedia page about stop words at https://en.wikipedia.org/wiki/Stop_words (retrieved October 2015)
- The documentation for the
TfidfVectorizerclass at http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.TfidfVectorizer.html (retrieved October 2015) - The documentation for the
WordNetLemmatizerclass at http://www.nltk.org/api/nltk.stem.html#nltk.stem.wordnet.WordNetLemmatizer (retrieved November 2015)