7.5 Applications of Visual Attention in Robots
Object detection and recognition for robots with visual sensors seem similar to that in natural scenes, but in mobile robots there are many differences. First, mobile robots often face complex environments in a dynamic scene as the robots move. Consequently, a mobile robot needs to detect or recognize multiple objects around its surroundings in order to avoid collision of occluded objects and to navigate its motion. Second, in general a robot should create an environmental map to aid its motion in an unknown environment step by step, and localize its position in the map for navigation. An early conventional method of building the map is named simultaneous localization and mapping (SLAM), which requires features extraction and features tracking in the environment [90]. The robots with visual sensors use the landmarks (features or objects) in the dynamic scene to build the map in SLAM. Detection, tracking and recognition of landmarks are very important in robots. Third, a moving robot results in a moving scene, so detection of moving objects in a moving background is a challenge for object detection. Finally, a robot often has several sensors such as laser and infrared sensors to detect occluded objects, multiple cameras for stereoscopic vision, auditory sensors to receive audio signal streams and so on. The constant stream of multisensory data provides a mass of information that needs to be integrated before making decisions. How to quickly and reliably detect objects in a complex and variational environment is a key problem in robotics. Even without the other sensor data, the visual sensors (cameras) alone mean that the mobile robot has already found it difficult to correctly process the huge amount of information because of its finite memory space and computation power. Visual attention can be used to tackle the problem.
There has been a lot of literature about applications of visual attention in robots since the end of twentieth century. A humanoid robot using overt vision attention is proposed in [91] and a robot combining visual attention with a multimodal 3D laser scanner is proposed in [92]. In [31], a robot adopts two cameras which are not for stereo vision, but for multiobject recognition. One camera with low resolution works for visual attention by using fast frequency computation model. The other camera with high resolution implements object recognition in these attention regions by using SIFT features. A method of robot localization and landmark recognition based visual attention is introduced in [25–27]. A SLAM framework for robot navigation based on visual attention in the indoor case is published in [28–30]. Moving object detection for robots in dynamic backgrounds is presented in [32–35]. Although there have been many papers on robot applications, in this section we only introduce three typical examples. One application is robot localization in an unknown environment, the SLAM based visual attention is presented next, and finally we talk about moving object detection of a moving robot.
7.5.1 Robot Self-localization
If you visit a strange city, you require a city map or a street map to locate your position, and then your destination and a navigation path can be found from the map. If there is no available map, the landmarks of the city could help you to find the location and destination. The landmarks of a city or destination may be known by searching the internet or hearing from your friends. Relying on the landmarks you can then find your destination. This landmark-based navigation paradigm is often used in mobile robot self-localization.
In the early work, artificial landmarks are set on the robot's path, so the attention mechanism can pop out some salient locations (the candidate region of the landmarks), then the salient region is matched with the landmarks by a recognition algorithm, if these artificial landmarks have been learned before. The recognition of more natural landmarks in an environment needs some knowledge about the environment. However, in most cases, the environment around the robot is in is often unknown, so the robot has to acquire the landmarks for itself, and this includes exploration of its environment and automatic extraction of a set of distinguishing and robust features to use as landmarks; then the navigation of the robot is based on these landmarks which are obtained by itself. In other words, the robot needs to move at last twice: once to extract the landmarks by scanning the unknown environment and the second time to move the path according to the extracted landmarks.
An idea of robot localization proposed in [25] is based on visual attention. Two stages are considered in the robot localization: the learning stage and the localization stage based on visual attention.
In the learning stage, a bottom-up visual attention model with multiple scales and multiple channels (cues) is employed to automatically obtain landmarks from the image sequence sampled from a camera of the robot. The most salient features along a navigation path are characterized by descriptor vectors in different scales and various cues. It is worth noting that cues (intensity and colours) of the bottom-up visual attention model are like the BS model in Chapter 3, but the corner-based cue approach computed by Harris [93] replaces the orientation cue because the corner in an indoor scene is a key feature. The most robust descriptor vectors in the navigation path are selected as landmarks whose attributes are described by the key frame, and then are stored in the landmark configuration over time. The detailed steps of the learning stage are as follows.
1. Computation of saliency map
Four cues (intensity, R/G, Y/B and corner) are extracted from the scene under a considered frame in multiple scales and these feature maps are transformed into a conspicuity map for each cue channel by centre–surround difference as the processing in SIFT [39]. Finally the four conspicuity maps (denoted as
Cpj,
j = 1, 2, 3, 4 for four cues) are integrated into a saliency map
SM by competition and normalization:
(7.37) 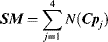
where N(.) is the operation of normalization. The most salient locations of the scene are selected by the saliency map SM.
2. Feature characterization at salient locations
Firstly, the salient locations at the
mth frame are denoted as coordinate points
xm,n,, where subscript
n is the
nth salient location in frame
m, and the visual descriptor vector of coordinate points
xm,n can be characterized as a vector:
(7.38) 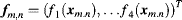
where the components of the descriptor vector satisfy
(7.39) 
The location with its feature descriptor vector in the sequence is represented as Pthm,n = (xm,n, fm,n), m = 1, 2, . . . M, n = 1, 2, . . . L, M is the total number of the sequential frames in the navigation path and L is number of salient location in a frame.
3. Salient locations tracking in the sequential frames of the navigation path
Given the
L salient locations computed from the first frame as the head of initial trajectories, each salient location is in one trajectory. Without loss of generality, let
Tp represent one trajectory among the
L trajectories. The location
xh, descriptor vector
fh and
Pthh = (
xh,
fh)
 Tp
Tp are the head information of trajectory
Tp in the first frame, where the superscript
h represents the head of trajectory
Tp. The new detected salient locations (
xm,n) in
Pthm,n of the next frame are compared with the existing trajectory
Tp to decide whether there exists a new salient location to append to the trajectory
Tp or not, according to the following inequation, with a very simple tracking algorithm shown as follows:
(7.40) 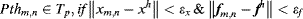
where

and

are small constants which determine the similarity between two salient locations on different frames. If
Pthm,n does not satisfy
Equation 7.40, it will become the head of a new trajectory. The tracking procedure continues one by one in the sequence frames along with the navigation path, resulting in many trajectories with different lengths over the time. More advanced tracking algorithms use the mean descriptor vector of all spots on a trajectory instead of
fh in
Equation 7.40.
4. Landmark selection and representation
The landmark in robot navigation must meet two conditions: uniqueness and robustness. The salient locations obtained by the bottom-up attention model can satisfy the uniqueness because of competition and normalization in the course of computation. The robustness condition is to examine the length of trajectories, because a persistent feature descriptor appears on a navigation path is commonly regarded as robustness. During the learning stage, the cardinalities of the salient positions with a long trajectory are selected as landmarks. In [25], the navigation path is divided into several representative portions. Each portion is represented by a key frame, which may contain several landmarks. Each of these selected landmarks is described by a five-component vector with location and feature information (horizontal spatial order of the landmark, mean vertical position, maximum deviation of the vertical position, mean feature descriptor vector and its standard deviation in the trajectory landmark appears). It is worth noting that these attributes are computed within the corresponding path portion. Finally these landmarks are stored in the memory of the mobile robot.
At the localization stage, the moving robot extracts a set of features from its current site by the aid of a visual attention model. The feature descriptor vector for each salient location of the saliency map is calculated as in the learning stage. The landmark recognition is to find the similarity of spatial location features between the attributes detected during the navigation path and the landmarks stored in the learning stage of the robot. Since the key frame can roughly reflect the location in the navigation path, the self localization of the robot is based on matching of the key frame. In order to decide which key frame is most similar to the current site of the robot, a probabilistic measure of robot location within the navigation path is proposed in [25]. A voting method is used to match these features in the current location of the robot with the landmarks in each key frame, and then integrate contextual location to determine the most likely key frame.
The introduced method is an application of robot localization by using the extended BS model. When the landmarks in the scene are unknown, the robot can find the optimal landmarks with uniqueness and robustness in its pathway. As mentioned at the beginning of step 4, the uniqueness is just taken from visual attention mechanism; what is more, the bottom-up attention can avoid a full search for each frame and save the computational time to find landmarks.
7.5.2 Visual SLAM System with Attention
The robot localization only considers its location, but another aspect of mobile robot navigation is to build an environmental map while moving along its pathway. A mobile robot starts move at a given coordinate in an unknown environment. In the moving course, a robot uses its sensors to perceive the external environment. The SLAM system aims to create an environmental map for the unknown environment; moreover, complete self-localization and navigation are implemented by using the map that it created by itself.
A SLAM problem can be described from a probability viewpoint. Let the state of the mobile robot at time t, be denoted as xt. For the robot moving on flat ground, xt is a three-dimensional vector including two coordinate and a pose (a viewing angle) of the robot. The moving pathway can be represented as XT = {x0, x1, . . . xT}, where subscript T is the time that the robot arrives at the endpoint. The motion information (velocity) between time t and t−1 is represented as Vt = {v1, v2, . . . vt}. The observation data perceived from the external environment at each time period are Zt = {z1, z2, . . . zt} in an environment. It is noteworthy that the observed data are related to the robot state and the environmental model. Let Me be the environmental model. The SLAM needs to estimate post-probability of xt and Me given Zt and Vt. Since the observed data at a moment may be just a small part of the whole environmental model, the robot can only build a local map with the help of the previous and current observation data. The connection between old and new local maps needs to be considered. The process of building the map is the precise estimation of location and the proper match of old and new local maps.
There are several algorithms to implement SLAM, such as the extended Kalman filter [90], fast SLAM [94] and so on. A mature SLAM for indoor environment often uses a laser scanner as a perceptive sensor; however, the laser scanner is expensive for many applications. Using the information from a camera (the robot's vision) to implement SLAM has been proposed in recent years [95–97].
Since some errors occur in the course of creating the map and state estimation, the mobile robot will fail in revisiting same places that it has been visited before; that is, the loop cannot close. In addition, the robot may generate several local maps for the same place, resulting in inconsistency of the map. If the mobile robot can reliably detect loop closing places and modify the current location according to the map built before, then the incorrect localization will be reduced and the precision of creating the map will be improved. This subsection presents a visual attention based mobile robot system with active gaze control [28–30] as an application example, for landmark detection, tracking and matching for visual localization and mapping. Since the visual attention model with top-down cues (VOCUS) in the system has been introduced in Section 5.5, here we mainly introduce how the attention mechanism can be incorporated into the robot system to control the activity of gaze.
Figure 7.12 gives a flowchart of an activity SLAM system to estimate the environmental map from the camera in a mobile robot. The image frame from monocular vision is provided to the feature detection module (see Figure 7.12). The VOCUS in the feature detection module computes the salient regions of the input image (called regions of interest – ROIs – in [28–30]) and the features in these salient regions are extracted. The features on each salient region are represented by feature descriptors. Two kinds of descriptors are used in the system: the attentional descriptor and the SIFT descriptor. The features in the ROI are transmitted to the feature tracker module and loop close module (see Figure 7.12). The feature tracker module is a buffer memory that stores the n past frames in order to track the ROIs over several frames by using attentional feature descriptors. These stable salient regions are chosen as candidate landmarks which will further be identified by the triangulation module (see the top row in Figure 7.12). These triangulated landmarks are sent to the SLAM module and are simultaneously stored in a database. The loop close module (the middle row in Figure 7.12) compares the features in the current frame with the landmarks stored in the database for deciding if the scene has been visited before by the aid of feature descriptors extracted from the feature detection module. The SLAM module builds a map of the environment and estimates the landmark position by using the extended Kalman filter [90]. If the result of comparison in the loop close module is positive, the updated landmarks are input to the SLAM module to modify the map. The module of gaze control decides the camera pose of the mobile robot (SLAM, gaze control and map modules are shown in the bottom row of Figure 7.12). Of course an accurate map can help navigation of the mobile robot, as the conventional SLAM system does. In order to understand the implementation of the mobile robot better, four major modules in Figure 7.12 are to be introduced in the following text.
1. Feature detection module
In this module, the visual attention computational model VOCUS is used to get the saliency map of an input image. Let us review the VOCUS computational model mentioned in Section 5.5. Its computational steps of the bottom-up part include intensity, colour and orientation pyramids, centre–surround operation and scale summation, and these generate ten feature maps: two intensity maps (on/off and off/on), four colour maps (red, green, blue, yellow) and four orientation maps (0, 45̊, 90̊, 135̊). The ten feature maps are weighted to obtain three conspicuity maps (intensity, colour and orientation). These weighs are computed according to the top-down knowledge in the training stage. Finally, the weighted summation of three conspicuity maps creates a saliency map.
The feature detection is based on the salient regions in the saliency map. The brightest regions are extracted from the saliency map to form a list of ROIs by region growing. Each ROI is defined by a two-dimensional location, region size and feature vector. The feature vector for feature tracking is an attentional descriptor (13-dimensional vector) which is extracted from ten feature maps and three conspicuity maps of the VOCUS model. The value of each element in the attentional descriptor, calculated from one of the 13 maps, is the ratio of mean saliency in the ROI and that in the background of the map under consideration. The computation of the attentional descriptor is fast and easy. It is shown in [30] that the attentional descriptor has the highest repeatability on tracking ROIs of image sequences, and comparing with other features such as Harris corners and SIFT features.
The other feature descriptor is the SIFT descriptor (with 128 dimensions for pixel gradient magnitude in its neighbour grids) introduced in Section 7.1.2, which gives more precise features for loop closing. In the computation of the SIFT descriptor, the centre of ROI provides the position, and the size of the ROI gives the size of grid. In the loop close module, the SIFT descriptor has higher matching power in the experiments of [30].
2. Landmarks selection
Selecting landmarks is implemented in the feature tracker and triangulation modules. When the saliency map for a new image is calculated in the feature detection module, the ROIs in the current frame are matched with the previous n frames stored in a buffer of the feature tracker module by Euclidean distance. The output of the feature tracker module determines which ROIs can be regarded as candidate landmarks. As with the system mentioned in Section 7.5.1, the ROIs with longer length trajectories are chosen as candidate landmarks. The triangulation module attempts to find an estimate for the location of the landmarks. Those landmarks that fall far away from the estimated landmark locations are discarded. The stable and better triangulated landmarks are sent to the SLAM algorithm to predict the next state and to build the map, and at the same time, they are stored in the database.
3. Loop close module
The features of the ROIs extracted from the current frame are input to the loop close module which will decide if the mobile robot has returned to a site that it has visited before. The loop close module is asked to match the landmarks in the database with the ROIs from the current frame. Since the database includes all landmarks in the process of the mobile robot, the matching needs to search the whole database for each moment. A decision tree strategy can be used in this search in order to save time. The results of the loop closing module update the location and modify the map built before, if some ROIs in the current frame find the matched landmarks.
4. Active gaze control module
The camera of a mobile robot often views a part of the scene, so control of camera's direction is related to different behaviours. In this system the position of the camera is controlled by the gaze control module. There are three behaviours: redetecting the expected landmarks for the close loop, tracking the landmarks and exploring unknown areas.
For redetection behaviour, the expected landmarks are defined as the ones in the potential field of view of the camera and with low uncertainty in the expected positions relative to the camera or the landmarks that have not been seen for a while. If there are several landmarks, the most promising one is chosen and the camera is controlled to gaze at the landmark.
For landmark tracking, one of the ROIs in the current frame has to be chosen to be tracked, and this needs to be chosen as the landmark with most stable and best triangulation result first, and then the camera is directed in the direction of the landmark. It is noteworthy that the redetection behaviour has the highest priority, but it is only chosen if there is an expected landmark. When the redetection behaviour does not apply, the tracking behaviour is active.
In the behaviour of exploring unknown areas, the camera moves to an area within the possible field of view without landmarks because the areas are often omitted areas.
In the system introduced [30], the visual attention model (VOCUS) extracts the ROIs in an input image sequence, and these are used in landmark selection and tracking. Since the VOCUS considers the top-down attention cues, the location detection of ROIs has higher accuracy. The feature descriptors of landmarks obtained from the visual attention mechanism have low cost and high tracking repeatability and can be applied in real time. In addition, the loop closing is easily implemented with the attention model since fewer landmarks make the matching between the landmarks in the current frame and the landmarks in whole database easy and fast. The gaze control module helps the system to see the environment from very different viewpoints to improve the performance of the SLAM system. Experiments in [30] show that the mobile robot with visual attention can move in a correct trajectory in its pathway and has better loop closing from start to end for several loop walks.
7.5.3 Moving Object Detection using Visual Attention
Moving objects in a static scene are easy to detect by computing the difference of two consecutive frames. However, for a mobile robot, detection and tracking of moving objects is difficult owing to the relative motion of the observer (camera) when a mobile robot moves in its environment. In computer vision, generally the motion vector of the dynamic background is first estimated through several frames and then used to compensate for the camera motion. This approach is not propitious for mobile vision because the background motion is often not linear transition for mobile robots. In particular, the frames are a radial expansion from the centre of the visual field. As an example of visual attention's application to solving this problem, the visual attention model with local and global features and integrating bottom-up and top-down information is presented in this subsection. This model was proposed by a research group [32–35, 98]. Using this model, the moving object in a moving background can stand out without estimating the background motion.
As a complete visual attention model in [32–35, 98], its construction and algorithm are more complex when applied to various aspects of mobile robots such as object detection, object tracking and recognition. Here, we mainly introduce moving object detection in robot applications by using the visual attention model. In the model, there are four modules: bottom-up attention with motion feature, object segmentation (pre-attention), object representation and top-down bias. For simplicity, only the characteristic modules are introduced here. The reader interested can see the papers [32–35, 98] for the details.
1. Bottom-up attention
The bottom-up attention module is similar to the BS model except for adding a motion feature. The motion feature extracted from the optical flow field is computed at each pixel location for two consecutive frames, based on the assumption of invariability of illumination intensity in space and time [99]. Let
I(
x,
y,
t) be the illumination intensity of the point location (
x,
y) in the image at time
t,
vx and
vy be the components of optical flow velocity in the
x and
y directions,
v = (
vx,
vy)
T. If a point at time (
t + δ
t) moves to location (
x + δ
x,
y + δ
y) keeping invariable intensity, we have
 I
I = 0 shown as
(7.41) 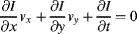
Thus we have the cost function
(7.42) 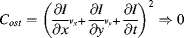
Setting the partial derivatives of
vx and
vy for the cost function to zero, we obtain two equations related to
vx and
vy, respectively. For the given two consecutive frames, the gradients of intensity in the
x,
y directions and the change of intensity between the two frames are known. The optical flow velocity can be obtained by
Equations 7.41 and
7.42. Thus, the direction tg
−1(
vy/
vx) and amplitude

of the optical flow velocity (
vx and
vy) of each point of an image can be computed. The movements (direction and amplitude) of all points in an image construct an optical flow field. As with the other features in the BS model, we use the operations of the Gaussian pyramid, centre–surround difference across scales, linear addition of scales and normalization to get the motion conspicuity map. In the conspicuity map of the motion feature, each point in the image is a vector with
vx and
vy components, but this is not a scale value like other feature dimensions in the BS model. Also, the optical flow vector is often disturbed by noise, light change and so on. In [32–35], the probability distribution of the motion feature is estimated [100], considering measurement error for the temporal and spatial derivatives at each point. The energy of motion conspicuity map at each point can pop out the moving object, which is computed by using the norm of the estimated probability's mean vector. Of course, moving background may also stand out in the motion conspicuity map in some cases. In order to distinguish the contour of a moving object, the motion energy combines the edges information obtained by the total orientation feature or by the Sobel operator, to generate the moving contour feature
fmc. Let
fm(
x,
y,
t) and
fe(
x,
y,
t) be the mean of motion feature vector and edge information at location (
x,
y) and time
t, respectively, the moving contour feature
fmc being the result of a logical AND between
fm(
x,
y,
t) and
fe(
x,
y,
t) shown as
(7.43) 
where ζ
m is a threshold and & denotes the AND operator, and the
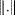
is the Euclidean norm operation. The points with small motion amplitude (less than ζ
m) in the optical flow field are omitted.
2. Object segmentation (pre-attention)
The object segmentation module uses the k-means clustering algorithm to partition the input image pixels into k clusters, according to the features on these pixels and their proximity relations. After clustering, each pixel in an image belongs to a cluster. This segmentation results in some potential regions which might contain one object. Let Rj denote the jth region, j = 1, 2, . . . k, after object segmentation. Each region includes a group of pixels with close features (intensity, colour, edge and moving contour) and nearby locations.
3. Top-down object representation of task-specified objects
Top-down object representation is based on the task-specified object. Given a required moving object, for example a walking human in the environment of a robot's view, two kinds of feature descriptors are used to represent the specific object: one is its appearance and the other is its salience.
The descriptor of appearance feature is the contour information of the task-specified object described by a B-spline curve, which consists of an invariant basic shape
Qo and the function of a state vector
X. The basic shape consists of several control points on the contour of the task-specified object and the state vector
X is estimated by the actual object observation with the spatial transformation, rotation and scale change. The appearance feature descriptor is described as
(7.44) 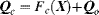

where Fc(.) is the affine transformation function, and (xoi, yoi), i = 1, 2, . . . l is the coordinate of control points on the contour of the task-specified object. The basic shape Qo is invariant to the centre of the object template.
The salience descriptor consists of statistical local features (two for colour pairs, one for intensity) on the task-specified object, that is mean and variance for each feature dimension on the object.
4. Top-down bias for each location for each feature dimension
Top-down bias is obtained by object representation and object segmentation. There are two kinds of bias: biasing in terms of contour and biasing in terms of colours. For the contour bias, the top-down biasing is estimated by a comparison between the top-down template and the contour feature in the scene. First, the centre of task object
Qo is shifted to the centre of each segmented region in the segmentation module (2) of the method and the state vector
Xp is predicted by using a Brownian motion model [101]. The optimal prediction of the state vector in the scene over all segmented regions (
Rj, ∀
j) is obtained by maximal likelihood represented as
(7.45) 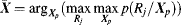
where
p(
Rj/
Xp) is the conditional probability which can be computed by prior shape and possible predicted curves. From
Equation 7.45, the estimated contour is obtained by
(7.46) 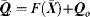
The contour top-down bias map for each pixel is represented as
(7.47) 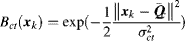
where
xk is the coordinate of pixel on the image, σ
ct is a selected variance. The bias map is inversely proportional to the distance between
xk and the estimated contour. The combination of the contour motion feature and the top-down bias map at location
xk is denoted as
(7.48) 
For the salient features, the top-down bias maps can be represented as
(7.49) 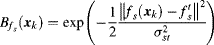
where
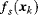
and
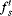
are the salient feature at location
xk, and the top-down feature for the task object respectively,
s {intensity, colour pair (R/G), colour pair (B/Y)}. The feature with top-down bias is similar with
Equation 7.48:
(7.50) 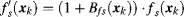
The final saliency map is the weighted summation of all the feature dimensions. It should be noted that if the feature does not distinguish the task object, the top-down bias map will be set to zero while only keeping the bottom-up part; for instance, to find a moving human regardless their clothing colour, the top-down bias maps of salient features (colour and intensity) may be set to zero. In addition, the top-down bias can be incorporated into each feature of the Gaussian pyramid, and then these biased features are processed by the centre–surround, competition and summation operations to generate the final saliency map.
Experiments in [32–35, 98] show that the model can precisely detect moving human objects in the environment of a moving robot. The characteristics of the visual attention based model are: (1) the moving contour feature is considered in the robot system, which combines motion energy from the optical flow field and total edge energy in order to detect all close contour information (object contour) with motion in the scene; (2) the deformed contour of an object is modelled as top-down information for object matching; (3) pre-attention segmentation gives object-based salient and top-down representation of task-specific objects: global (contour) representation (
Qo in
Equation 7.46) and local features (
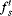
in
Equation 7.49) can tune the moving object related to a task-specific object, so the target-object can be enhanced in the saliency map.
In the model, the resultant saliency map can pop out the task-driven moving object in a moving background without the estimation of background motion.

