
7.4 Image Retrieval via Visual Attention
Along with the rapid development of computer internet and multimedia techniques, a huge amount of the digital images are generated every day, from both military and civilian equipment, which include much useful information. However, since these digital images are randomly distributed around the world, the useful information cannot be accessed and used by users if there is no technique to solve the problem. Image retrieval is a method to quickly and accurately retrieve required images. With the growing size of digital image collections, image retrieval became a very hot research area in the 1970s. The development of image retrieval is based on the promotion of database and computer vision, thus it combines both characteristics of them and forms a new research area.
Early image retrieval was mainly based on text [77–79], where images were annotated by text or keywords in a database, and then the description of the required image was used for retrieval with the aid of exact text match or a match based on probability. However, this image retrieval method faces some difficulties. One is that manual image annotation needs a vast amount of labour, especially for the collection of hundreds and thousands of images. Second, the manual image annotation, in general, is not accurate or complete, since different people have different views to the same image. Therefore the subjective difference between individuals results in mismatch error in retrieval. In addition, many features or contents in images cannot be objectively described by keywords or text.
As larger databases become available, these problems become increasingly acute. In the early 1990s content based image retrieval was proposed [80–82] in which an image is indexed by its own visual content, such as colour, texture and shape in the whole image or in a part of the image. Some visually perceptive features replace text or keywords for retrieving the required images in a large database, and the enquiry of users depends on the similarity of visual features or the content of the image in the database. Many techniques in computer vision are incorporated in content based image retrieval, and this has caused a rapid development of content based image retrieval [83–86].
Visual attention can capture the salient region of an image that is, in general, related to the content of image. It can be used in content based image retrieval as a part of the retrieving system, and it can improve retrieval accuracy and speed [21–23]. This section mainly introduces image retrieval with visual attention. Although content based image retrieval is related to computer vision, it is different from pure computer vision since image retrieval faces many kinds of images with variable sensing conditions and should be able to deal with users' incomplete query specifications.
In this section, we first introduce the elements of general image retrieval, and then present the visual attention model related to image retrieval.
7.4.1 Elements of General Image Retrieval
A content based image retrieval system includes user interface, image database (or image feature extracted database), similarity computation between images, retrieval results and feedback. The intention of an image retrieval system is to rapidly find a useful image subset or even a specific image from a large image source. Since the definition of useful information is diverse for different users, a man–machine interaction is necessary. Figure 7.8 shows the simple structure of a general image retrieval system.
Figure 7.8 Sketch of content based image retrieval system
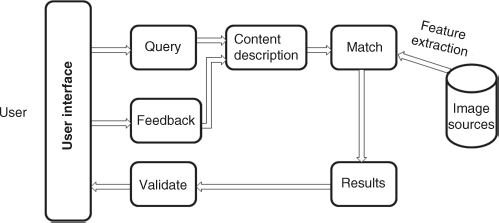
The image source (on the right of Figure 7.8) is an image database or the images distributed anywhere in the world collected via the internet. So the size of the image source can be massive. In general, the images in the image source are clustered into many groups by the similarity of features or categories, which is implemented offline in order to search the data conveniently. Many search strategies in a computer based database can be used for the search, and we will not explain them here in detail.
In Figure 7.8, the user is commonly a human user, but sometimes the user may be the intelligent agent wanting to get the returned results. The user in a retrieval system needs to compose a query, evaluate the retrieval results while some images are retrieved, modify the query and give feedback via the user interface. The user interface is the gateway from the users to the image source, through which the user can exchange information with the retrieval system. Thus, the three modules, query, validation and feedback are implemented on the user interface.
The query module in Figure 7.8 is to generate a request by the user in order to select a subset of images from the image source. There are many ways to generate queries. A narrow query asks to return a specific image from the image source, but in most cases, the user asks to return a subset of images that satisfies some requirements. In general, the following methods of image retrieval systems are used. (1) Query by example image [21]: the user provides a sample image with given requirements and hopes to retrieve similar images from the image source. For instance, a bridge-builder gives an image of a bridge cross a river in the interface to ask for all images related to the bridge in the image source. If the image source is the internet, then the pictures of famous bridges in the world may be returned to the interface. The user can select the required image from the image subset and then continue to provide a specific category of image, for example the image of cable-stayed bridge as a new query. The exchange between the user and the retrieval system is carried out on the platform of the human–computer interaction, and finally the bridge-builder can find the requisite information. (2) Query by visual sketch [21]: when the user does not have the example image, they can create an arbitrary image by drawing a sketch, according which the system will retrieve the required image or image subset. (3) Query by visual features [21], where the user knows the features of the image or the spatial distribution. For example, when asking for an image with a sea view, the colour feature (blue) in the bottom part of the image can be used to compose a query, and a subset of seascape images is retrieved. (4) Query by image region [21]: this query is often related to target search, because a target is located in a region of an image. This kind of query can improve the retrieval results since more accurate positions related to the required target in the images are found.
As well as the four methods above, there are others queries such as the keyword query, query by multiple example images and so on.
According to the queries of the user, the features of an example image (whole image, visual sketch or region of image) are extracted, which results in a new representation. The module of content description in Figure 7.8 contains the new representation. These features mainly include colour features or colour histogram in different colour space, texture feature (representations of Fourier power spectrum, first- or second-order grey level statistics, Gabor filtering results, etc.), and shape features obtained by wavelet descriptor, finite element method, turning function, convex and concave polygons and boundary based features and so on. For different queries and databases, the system should select appropriate features to search images in order to distinguish the required image subset from other images in the data source.
The match module in Figure 7.8 is used to compare the query image (or query image region) with every image in the image source based on these extracted features. It will be noted that each image in the image source must be represented in the same manner as the query image. The similarity scores between the required image and the images in the image source are calculated. The similarity score adopts L1 distance, L2 distance, cosine distance or histogram distance. These similar images in the image source are collected and ranked according to the score of similarity. The images closer to the required image are expected to give the better results [21].
The validate module in Figure 7.8 is a part of the user interface. The user can check the retrieval images displayed on the interface to decide if these images are consistent with the user's requirement. If they are, the retrieval ends, otherwise the user can modify the query and feed back the information to the content description module, and the retrieving procedure continues.
Image retrieval aims to rapidly and accurately search for the required images, and the speed and accuracy rate of retrieval are important criteria. The criteria: true positive (TP), false positive (FP) and false negative (FN) mentioned in Chapter 6 are often used to test a content based image retrieval system. An objective of information retrieval system is to maximize the number of TPs and minimize both the number of FPs and FNs [21]. That is, the retrieval results (a subset of images) should include more required images (true positive images) and fewer unwanted images (false images).
Although content based image retrieval is somewhat like target search in computer vision, it has many new challenges [82]. One is that the image retrieval has to search an image or subset of images among a huge amount of targets under the conditions of incomplete query specification, incomplete image description and variability of sensing condition and target states [82]. The other is that the retrieving process needs interaction between the retrieval system (searching results) and the user, although it does not need an explicit training phase.
7.4.2 Attention Based Image Retrieval
As mentioned above, the query by image region can locate the target position, and it improves the effect of image retrieval. However, most methods of regional division are based on image segmentation which is still a difficult problem, especially for a huge amount of different kinds of images. This causes non-ideal searching results. Therefore, most image retrieval systems prefer features of the whole image to the local features of an image region. The focus of visual attention is just the interesting parts of an image in most cases. It is natural to think that the visual attention model can be applied in image retrieval. Recently much literature has suggested the idea of content based image retrieval with local regions [21–23,] [21–23, 87, 88]. The example introduced below was proposed by [21, 22, 88] and is only for demonstrating how to apply bottom-up visual attention to image retrieval.
In [21, 22], two bottom-up models were employed in an image retrieval system in order to compute the salient region of interest. One is the BS model introduced in Chapter 3 (Section 3.1), which produces a saliency map of an image. The most salient locations (points) are found on the saliency map. The other is referred to as the attention-based similarity model proposed in [89]. The latter can accurately compute the salient value at each pixel so that the salient region can be drawn precisely. The computational result of an attention-based similarity model produces a map called a visual attention map, in order to distinguish it from the saliency map of the BS model. The difference between a saliency map and a visual attention map is that the saliency map finds the most salient points in an image, but it cannot get the covered regions, while a visual attention map aims to find the accurately salient regions, but may not locate the most salient positions. By combining both saliency map and visual attention map, the salient regions around the most salient locations (points) will provide the precise regions of interest in an image. These regions of interest may be the places where the target is located. The procedure for generating the visual attention map in an attention-based similarity model is as follows.
The visual attention map is based on the attention score of each pixel. This model assigns a high score of visual attention to a pixel in an image when its neighbour pixels do not match randomly selected pixels' neighbourhood in the image [88]. In other words, if the features or texture of a small pixel subset around a pixel are common in whole image, the attention score of the pixel is suppressed. Otherwise, the attention score is higher.
The configuration of neighbour pixels for a pixel is shown in Figure 7.9, where the grids represent pixels in an image: x is the pixel under consideration and the randomly selected circles in the neighbourhood (5 × 5 pixels) of x form a configuration.
Figure 7.9 Sketch map of computing attention score
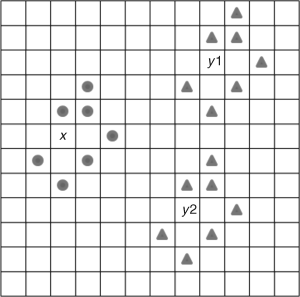
The process of computing the attention score for a pixel x in the input image has five steps: (1) create a random set of neighbour pixels (m pixels) within a radius r of pixel x as a configuration (in Figure 7.9, m = 7 and r = 2 in a 5 × 5 patch); (2) randomly select another pixel y1 elsewhere in the input image; (3) compare the pixel configuration surrounding pixel x with the same configuration around pixel y1 (triangles in the neighbour of pixel y1 shown in Figure 7.9) and test the mismatch (note that the neighbour pixels of y1 under consideration have the same position as those of pixel x); (3) if the result of testing is a mismatch then the attention score of pixel x is increased, and the process (steps 2 and 3) is repeated for another randomly selected y2, y3, . . . until k random pixels are compared, where k is the repeating number and its value is set in advance; (4) if the configurations match, the score of the pixel is not increased and a new random configuration around x is generated, and the process (steps 2 and 3) continues; (5) after all iterations, the accumulated attention score of pixel x is obtained. It is worth noting that the comparison of mismatch may be colour, shape or both. This method for mismatch measurement has been commonly used in pattern recognition or object detection, so we will not elaborate it further here.
For each pixel in the input image, the process of the five steps repeats, and finally a visual attention map of the input image is generated. From the process above, the regions with high score possess features that are not present elsewhere in the image and low-score regions often have common features.
However, sometimes the background region of an image may have higher scores if its features are different from its surrounding in the visual attention map, and the saliency map calculated from the BS model is considered in the system to extract the final regions of interest. This method is proposed in [21, 22]. Assume that the input is a single source image, and both the saliency map from the BS model and the visual attention map from the attention-based similarity model are generated in parallel. For the saliency map, a threshold is selected to apply to the greyscale saliency map and a binary map with the most salient points can be obtained. For the visual attention map, a binarizing operation is also added to get the binary image. A morphological operation is used in both binary images, in order to fill some cavities and remove noise. The integration of the two binary maps is first dependent on the salient peaks (most salient points) of the saliency map, and then these peaks overlap with the salient regions of the visual attention map to get a mask with regions of interest (the pixels in regions of interest are set as one and others are set as zero). This means that the visual attention map is used to extract the salient regions around the salient point. Finally, the binary map of the integration is logical ANDed with the original image to get the regions of interest for the original image. Figure 7.10 gives a flowchart for extracting regions of interest.
Figure 7.10 Flowchart of the regions of interest extraction
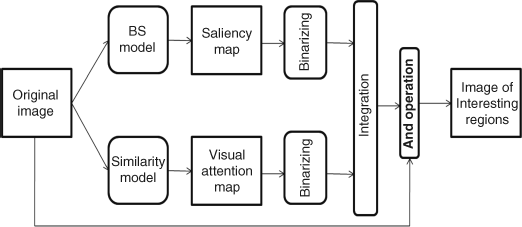
Two problems need to be noted. (1) Extraction of the interesting region has to combine both the BS model and the similarity model to attain the mutual complementation. The saliency map of the BS model has the ability of discriminating between salient locations but it cannot exactly partition the salient region from others. The visual attention map of the similarity model can segment regions but it is less discriminatory. The combination model is able to handle relatively large regions. (2) Different threshold values result in different numbers of peaks in the binary saliency map. In the proposed model [21], the choice of threshold is to guarantee at least one salient point in the design region for each image. In most cases, one image may have several regions of interest.
When the regions of interest of each original image in the image source are extracted according to the above method, the features (colour, shape, texture, etc.) of these regions are extracted, and the feature extraction is similar to the processing for the whole image. These features of regions in the image source are clustered together. The operations are offline. In the retrieval stage, the user can give the query as feature related regions of the image and then is to find the image in the image source by using the online interface. The flowchart of the image retrieval system with regions of interest is shown in Figure 7.11.
Figure 7.11 Image retrieval system with regions of interest
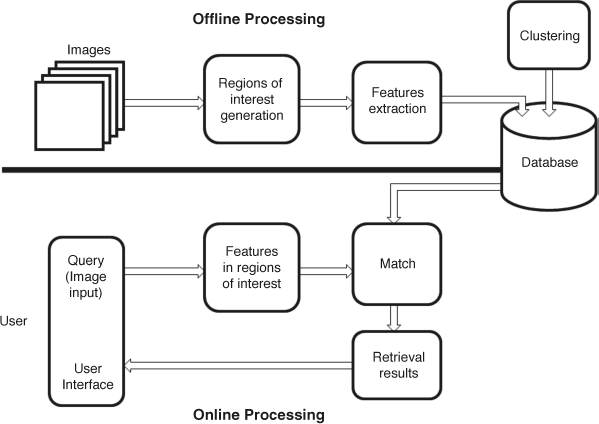
In Figure 7.11, the retrieval system is similar to a general image retrieval system comparing the online process of Figure 7.11 with that of Figure 7.8; however, in Figure 7.11, the module ‘Regions of interest generation’ in the offline processing, and the module ‘Features in regions of interest’ in the online processing include visual attention computation. There are two merits of the visual attention aided retrieval system. One is that using salience regions as clues to do retrieval helps to remove the influence of the background, and then the extracted regions match the target better. For instance, retrieving a person target in a landscape picture, the global features (e.g., blue sky) are removed after visual attention calculation, and the target can better match the user's intention. The other merit is that the salience regions can be automatically and exactly extracted in both the offline and the online stages so that the difficulty of image segmentation is avoided.