
5.2 Hierarchical Object Search with Top-down Instructions
Most visual attention models are based on low-level features that may not concern a complete object and they aim to find some salient locations namely space-based saliency. However, in some scenes these salient locations may not represent any significant object. In the other words, salient locations are probably speckle noise or blemishes on the image that is unrelated to any interesting object. A lot of recent literature [35–40] suggests an object-based attention to directly locate significant objects. For an example of object-based attention, two overlapped objects or a blocked object in a scene, which are difficult to pop out in space-based attention, can still draw observers' attention in some cases. In addition, one object probably has very complex structure: several features constituting the same object or an object group maybe includes several small objects. In that case, space-based visual attention will not be effectual. For example, some salient locations extracted from these low-level features do not contain any significant object, and thereby object-based visual attention models and the models integrating both object-based and location-based attentions have been proposed in the literature of psychophysics and computer vision [35–38].
A hierarchical object search model [13] proposed in 2003 is a typical object-based computational model with top-down instructions of a simple binary code flag. All competition in the model is not only based on pixels, but also based on object groupings. The object groupings in a scene are not always salient, but if an object grouping is related to the features of the observer's requirement its salience will be enhanced through top-down controlling of the competition between different groupings and between a grouping and its surroundings. An interesting issue [13] is to simulate a hierarchical object search in different scales when a large object grouping at a coarse resolution becomes an attention focus which is of interest to the observers. Each small object grouping within the large object grouping is attentive at the fine resolution at almost the same location, and then the smaller object grouping is searched by the observers at the finer scale if necessary and so on until the required object grouping or object is found. Taking the example of looking for your son in a park as mentioned above, if you know that your son is playing with his friends. You first search the group of children with the similar ages as him in the square, and then search each child in the selected group in details. This search process (from coarse to fine resolution) is like the covert search case (covert attention). Of course, this model can also carry out overt attention as most bottom-up and top-down computational models do; when the top-down signal representing the observer's idea indicates that a deep search is not needed, the inhibition of return will reset the current focus and then the eye will move to other salient object groupings. Consequently, a hierarchical object search model covers both overt and covert attention that will be determined by top-down instructions. In this section, we mainly introduce object-based covert attention.
The hierarchical object search model includes (1) perceptual grouping; (2) bottom-up information extraction and computation of the grouping-based saliency map; (3) top-down instruction and integrated competition; (4) hierarchical selection from top-down instructions.
5.2.1 Perceptual Grouping
In object-based attention, the grouping processes and perceptual organization play an integral role. The groupings are the primary perceptual units that embed object and space in saliency estimation. However, perceptual grouping is a complex issue which involves in a lot of facts related to bottom-up and top-down information. In a bottom-up process, spatial proximity, feature similarity, continuity and shared properties are often considered as a grouping or an attention unit. For instance, two boats on a river can be classified as two groupings because of the different colours of the surrounding (water) and the discontinuity of the two boats. The water in the river and the bank on both sides of the river can be regarded as two other groupings. In a top-down process, the prior knowledge, experience and required task guide the grouping of the scene. Actually, the bottom-up and top-down processes are interlaced with each other. In [13], the grouping is generated by manual preprocessing on gestalt principles. An example of finding some persons (as top-down heuristic knowledge) in a scene is shown in Figure 5.3. By sharing common features (colour or orientation) and by separating from their surroundings with different features (water), under top-down guidance (with the aim being searching for persons), the image of Figure 5.3 is organized into two groupings related to the persons: one is the person grouping on the boat and the other is the person grouping on the bank, denoted as 1 and 2 in the rings of Figure 5.3, respectively. Two objects (persons) belonging to each of the two large groupings respectively may be segmented into a multilevel structure, from person groupings, single person, face of each person and so on. In Figure 5.3 we only draw two levels: person grouping (marked as 1 and 2) and single person (marked 1–1, 1–2, 2–1 and 2–2), with the number after the hyphen denoting the objects in the next level.
Figure 5.3 Perceptual grouping in two levels

In the following description of the hierarchical object search model, we suppose that the grouping has been segmented in the preprocessing stage.
5.2.2 Grouping-based Salience from Bottom-up Information
Suppose all grouping segmentations in the input colour image have been finished. The calculation of a grouping saliency map from bottom-up information includes extraction of primary features (colour, intensity and orientation) at different scales, contrast computation of the grouping at each feature channel in the same scale and the combination of the salient components in all features of the grouping:

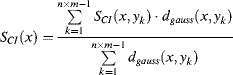
The computation of orientation salience is more complicated than the salience of colour intensity, because it needs to consider the situation of homogeneity/heterogeneity of each neighbourhood point. Here we do not explain it in detail, in order to concentrate on the model's main idea. The detailed equations can be found in [13].
If θx,y is the orientation difference between pixels x and y, the orientation contrast of x to y is defined as
where sin(.) is sine function for the angle θx,y. After the computation for neighbourhood pixels of x and considering the case of homogeneity/heterogeneity in the neighbourhood, the orientation salience of the pixel x can be expressed as
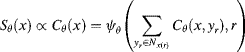
where ![]() is the neighbourhood of pixel x in the radius r (r = 1, the neighbourhood of x is eight pixels, and r ≠ 1,
is the neighbourhood of pixel x in the radius r (r = 1, the neighbourhood of x is eight pixels, and r ≠ 1, ![]() has 8r2 pixels in the neighbourhood of x), the function
has 8r2 pixels in the neighbourhood of x), the function ![]() represents a complex computation for orientation salience. Equations 5.8–5.12 show the neighbour inhibited effect if the properties of neighbour pixels are similar to the pixel under consideration.
represents a complex computation for orientation salience. Equations 5.8–5.12 show the neighbour inhibited effect if the properties of neighbour pixels are similar to the pixel under consideration.
Suppose xi is a component within a grouping ![]() , where xi may be either a pixel (point) or a subgrouping within the grouping
, where xi may be either a pixel (point) or a subgrouping within the grouping ![]() . The integrated grouping salience can defined as
. The integrated grouping salience can defined as
where ![]() and
and ![]() are the weighting coefficients that denote the contributions of the colour intensity and the orientation properties to the grouping saliency. The more generalized equation for the grouping salience representing the inhibited effect or contrast computation between the groupings or between the subgroupings is described as follows.
are the weighting coefficients that denote the contributions of the colour intensity and the orientation properties to the grouping saliency. The more generalized equation for the grouping salience representing the inhibited effect or contrast computation between the groupings or between the subgroupings is described as follows.
Suppose R is an arbitrary given grouping at the current resolution scale at time t, Θ is the surroundings of R and the subgroupings in ![]() and in Θ is denoted as
and in Θ is denoted as ![]() i and
i and ![]() j respectively which satisfies
j respectively which satisfies ![]() ,
, ![]() , the salience for colour intensity SCI and the salience for orientation Sθ of subgrouping Ri can be calculated by
, the salience for colour intensity SCI and the salience for orientation Sθ of subgrouping Ri can be calculated by
where fCI and fθ are the functions to calculate colour intensity salience and orientation salience between ![]() i and
i and ![]() j, respectively, as the computation of pixel salience mentioned above. Here the subgroupings
j, respectively, as the computation of pixel salience mentioned above. Here the subgroupings ![]() i and
i and ![]() j can be object, region or pixel. The final salience of the grouping
j can be object, region or pixel. The final salience of the grouping ![]() i is given as
i is given as
where ![]() is normalization and integration function.
is normalization and integration function.
Consequently, the salience of a grouping is to integrate all components of spatial location, features and objects in the grouping together, which includes the calculated contrast within a grouping (each pixel with its neighbour pixels, each subgrouping with other surrounding subgroupings) and the competition between the grouping and other surrounding groupings. It is illustrated by the following example. A garden with many flowers in full bloom and a group of persons on the background of a green lawn is regarded as two groupings, 1 and 2. Each single flower of grouping 1 or each single person in grouping 2 are regarded as the subgrouping in their respective groupings. Without loss generality, we first consider the salience of grouping 1. All the pixels' salience (contrast between the pixels) within grouping 1 and outside of the grouping 1 (pixels in the green lawn or in grouping 2) and all single flowers' salience (contrast between the subgroupings) within grouping 1 and out of grouping 1 are integrated together to generate the salience of grouping 1. The salience of grouping 2 can also be computed in the same manner.
We need to bear in mind that Equations 5.8–5.15 operate at a given resolution scale and in a given time, each scale of the pyramid has the saliency map with their groupings. In addition, the computation of groupings' salience is only based on bottom-up information.
5.2.3 Top-down Instructions and Integrated Competition
In the model, the bottom-up salience of various groupings at each pyramid level is dynamically generated via the competition between these groupings, and the visual saliency interaction with top-down attentive bias. How does the top-down bias influence the competition? If the competition is implemented by a WTA neural network mentioned in Chapter 3, then one method is that the top-down control signal influences the dynamic threshold for neuron firing on each pyramid level and each location, the activity on the neuron with high threshold will be suppressed and otherwise will be enhanced. However, the adaptation for each neuron at each pyramid level is time-consuming. Another idea is the top-down bias for special objects or groupings in the scene, which is also complicated since it is related to object recognition in the high-level processing of the brain. In the model, the top-down bias only acts on the level of two basic features (colour intensity and orientation), which is set to four states encoded by the flag with a binary code for the current bottom-up input at any competition moment:
The code (00, 01, 10, 11) as the top-down instruction is set to each feature channel on each pyramid level by the observer and is integrated in the course of competition. Another kind of top-down instruction is a flag for ‘view details’ which finishes the hierarchical selectivity in the different resolutions, as follows.
5.2.4 Hierarchical Selection from Top-down Instruction
Hierarchical selectivity is implemented on the interaction between grouping salience and top-down instruction (flag 1 and flag 0). Flag ‘0’ means that the winner grouping will continue to explore its details, where ‘details’ refers to the subgroupings within the winner grouping, if the salient object exists at the current resolution or the finer resolution (covert attention). Flag ‘1’ means that the attention focus is shifted from the current winner grouping to the next potential winner grouping at the same resolution if the potential winner groupings exist. The competition between the groupings first occurs at the coarsest resolution and the winner grouping pops out at the coarsest resolution, and then a top-down control flag determines if the search continues to view the details within the winner grouping or to shift attention out of the winner grouping. There are four states for the hierarchical attention selectivity:
Figure 5.4 shows an example of the hierarchical search from a coarse resolution to a fine resolution. The groupings 1 and 2 in coarser resolution are a boat with several people and the people on the bridge, respectively. In the coarser resolution the two groupings have high salience since the people are wearing coloured clothes in a sombre environment. First, in coarser resolution the grouping 1 is the winner and the top-down flag shows ‘0’, so it needs a detailed search in subgroupings within the boat. Subgrouping 1–1 is a girl wearing flamboyant clothing. She can pop out in the coarser resolution, but other people on the boat need to be searched at fine resolution. The order of the search is subgrouping 1–1, 1–2, 1–3 and 1–4 via inhibition of the return mechanism. After that, there are no salient objects, so the search is backtracked to grouping 2 and continues the subgroupings 2–1 to 2–2 if the ‘view details’ flag rises.
Figure 5.4 Hierarchical searching of an object from coarser resolution to fine resolution

In summary, the hierarchical object search model has two specialties compared with other models: one is that it integrates object-based and space-based attention by using grouping-based salience to treat the dynamic visual task, and the other is hierarchical selectivity from low resolution to high resolution which is coincident with human behaviour. The weakness of the model is that the top-down instruction needs the observer's intervention, and the determination of the perceptual grouping needs preprocessing such as image segmentation or the subject's intervention and so on.