
This chapter discusses details to consider when you plan more complex configurations of Operations Manager 2007. Complexity in this context refers to a variety of concepts, including the following:
Adding components
Multihomed configurations
Connected management groups
Multiple domains
Active Directory integration
Impact of component faults in OpsMgr 2007
Highly available configurations
As part of planning complex configurations for OpsMgr 2007, remember the Assessment, Design, Planning, Proof of Concept (POC), Pilot, Implementation, and Maintenance stages. You should follow these stages, introduced in Chapter 4, “Planning Your Operations Manager Deployment,” when planning your OpsMgr implementation.
An Operations Manager 2007 deployment includes several components that are required for any installation. These components include the Root Management Server (RMS), Operations Database Server, Operations Console, and the Operations Manager Agents. For some organizations, these components may provide all the functionality required. However, a variety of additional components are available (introduced in Chapter 4) that can be used and should be considered part of your planning process. You should identify the requirements to use any or all of these components during the Assessment stage, in which you gather functional, business, and technical requirements for the OpsMgr design.
The business requirements we want to achieve with these additional functions include the following:
Reporting and Trending
Audit Collection
Large Numbers of OpsMgr Agents
Agents in Workgroups or DMZs
Client Crash Monitoring
Web-based Administration
We will review each of these concepts and discuss any planning-specific aspects of how to deploy them into an Operations Manager 2007 solution.
With OpsMgr 2007, reporting is more closely integrated than it was with the Microsoft Operations Manager (MOM) 2005 product. Data now flows directly from the management server to the Operations database and the Data Warehouse database (if installed). It is important to understand that reporting is an optional component, and is not required. Once you install the reporting component, data begins to flow to the Data Warehouse database.
Although Operations Manager 2007 can function without the reporting features, there is a very limited subset of situations where this would be the recommended design. We can think of several examples:
A nonproduction OpsMgr environment, used as a testing environment.
An environment where server monitoring hardware is severely constrained that cannot effectively provide the additional functionality.
An environment that does not function proactively or think it is important to understand utilization or historic trends.
If you remember the basic stage of the Infrastructure Optimization (IO) model discussed in Chapter 1, “Operations Management Basics,” there are customers who choose to stay in the basic stage and install only what they need. Those organizations may not consider reporting to be necessary functionality.
Although all these are potential cases where you might not deploy OpsMgr reporting capabilities; reporting is a core piece of functionality for the vast majority of OpsMgr deployments.
The OpsMgr 2007 reporting components provide both short-term reporting of data and long-term reporting of data (known as trending). Figure 5.1 shows an example of short-term reporting of data using information from the Operations database, which shows system uptime for agents in the environment. (Looks like we did a reboot on the Juggernaut server recently!)
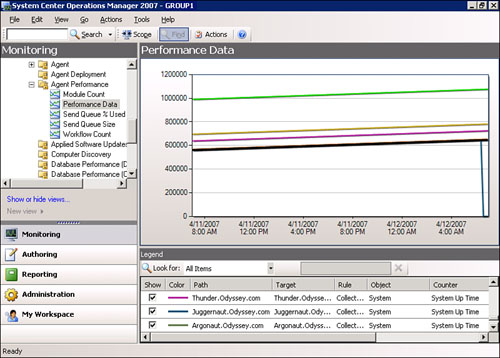
By changing the default interval that OpsMgr uses to report data (performed in the Actions pane by clicking the Select Time Range button), we can also provide trending information within the Operations console. Figure 5.2 shows the number of SQL connections occurring on multiple SQL servers over a 1-week period.

The Reporting Server Component and Data Warehouse Server Component provide the Operations Manager 2007 reporting functionality for that information stored outside of the Operations database. These two components often run on the same physical system, but you can split them onto different systems. When planning to implement reporting within Operations Manager, you have the following items to consider:
What hardware will be necessary? In Chapter 4, we discussed recommended hardware for these components and provided methods to estimate sizing for the Data Warehouse database.
Is high availability required? With MOM 2005, it was common to have a highly available Operational environment (multiple management servers, clustered Operations database), but to not provide highly available reporting functionality. This was due to the nature of how MOM 2005 transferred data on a scheduled basis to its reporting database.
OpsMgr 2007 writes data directly to the data warehouse from the management server (this differs from MOM 2005, where data was moved using a DTS transaction). Because Operations Manager manages the data differently, we can now provide more real-time information for reporting.
With data now written in near real time (instead of batched nightly via DTS) to a data warehouse, the need to have a highly available Data Warehouse database becomes more important than it was in MOM 2005. We will review high availability options for all components within the “Planning for Highly Available Configurations” section of this chapter.
As a rule, we recommend that you deploy both the Reporting Server Component and the Data Warehouse Server Component in your environment unless there is a specific reason not to deploy them.
Audit Collection Services (ACS) provides a way to gather Windows Security logs and consolidate them to provide analysis and reporting. From a planning perspective, it is important to understand that there are actually three components required for ACS to function:
ACS Database Server—. The centralized database repository for security information gathered from the servers in your environment.
ACS Forwarder—. This is a service deployed with the OpsMgr agent but not enabled by default.
ACS Collector—. Receives information from the ACS forwarders. The collector receives the events, processes them, and sends them to the ACS database server.
If ACS is a requirement for your OpsMgr environment, it should be one of the areas to focus on when working on the Proof of Concept (POC) stage. During the POC stage, you should determine design factors such as resource impacts on the OpsMgr agents and the ACS collector. The POC stage also provides a good starting point to identify sizing requirements for your ACS database. Additionally, the POC stage is an excellent time to determine any network impacts resulting from gathering security information from your OpsMgr agents.
Each of the three ACS components needs to be included in the OpsMgr design. The ACS collector and ACS database server both need to have sufficient hardware (see Chapter 4 for details on this). The number of forwarders that can report to a single collector varies depending on several items:
The number of events the audit policy generates.
The role of the computer that the forwarder is monitoring. (As an example, domain controllers will most likely create more events than member servers do.)
The hardware specifications of the ACS collector server.
You can install multiple ACS collectors and multiple ACS database servers, but each ACS collector will report to its own ACS database server. Chapter 15, “Monitoring Audit Collection Services,” provides recommendations around sizing for the ACS database, including a discussion on how to estimate database size based on projected loading scenarios.
The decision to deploy ACS as part of OpsMgr 2007 really depends on the requirements of your particular organization. Although the addition of ACS to the OpsMgr 2007 environment increases the complexity of the design, it also brings some significant functionality benefits, which should be seriously considered.
With a single-management group design, if the requirements identified during the Assessment phase indicate that you will monitor more than 2000 agents or that redundancy is necessary, you will want to deploy additional management servers.
The first item to consider when adding multiple management servers is identifying the hardware requirements for those additional management servers. See Chapter 4 for recommended hardware specifications for the Management Server Component.
The next thing to consider is how you will distribute the agent load in your environment. Assign each management server a maximum of one-half of the agents it will be responsible for monitoring. As an example, in an environment where OpsMgr will be monitoring 4000 servers, the RMS would be primary for 2000 of the servers and secondary for the other 2000 servers. The additional management server would be primary for the second set of monitored servers, and secondary for the first set of agents. Figure 5.3 illustrates this example.
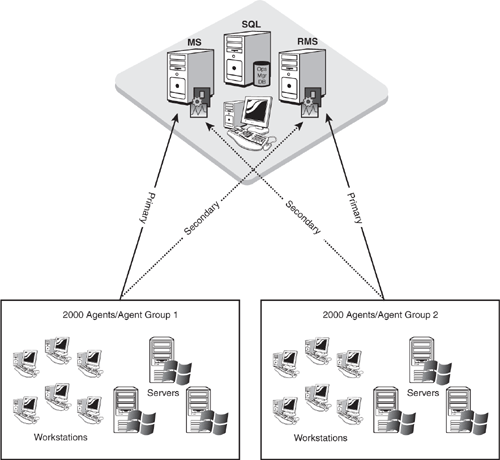
The ability to use multiple management servers in a management group increases the scalability Operations Manager can provide for your environment, and it increases the redundancy options available for your OpsMgr solution. The “Planning for Highly Available Configurations” section of this chapter provides further discussions on redundancy for all of the OpsMgr components.
Operations Manager 2007 introduced the Gateway Server Component to provide the ability to monitor agents within untrusted domains or workgroups. MOM 2005 recommends, but does not require, using mutual authentication between the management server and the agent.
Mutual authentication is now required in Operations Manager 2007. Using the Gateway Server Component makes this viable in a DMZ, untrusted domains, and workgroup environments. This component gathers communications from the agents and forwards them to a management server on the other side of the firewall using port 5723.
To effectively plan to monitor agents with a gateway server, you need to provide hardware for that server (see Chapter 4 for hardware recommendations on this component) and consider the additional design impacts on OpsMgr. If you have a gateway server, it needs to report to a management server. We recommend that the specified management server handle only gateway server communication; because of load issues, we do not recommend that agents report directly to the same management server as a gateway server. However, you can configure multiple gateway servers to report to a single management server.
From a design perspective, be sure to plan for additional hardware for those management servers your gateway servers will report to. Figure 5.4 shows an example of an architecture using gateway servers.
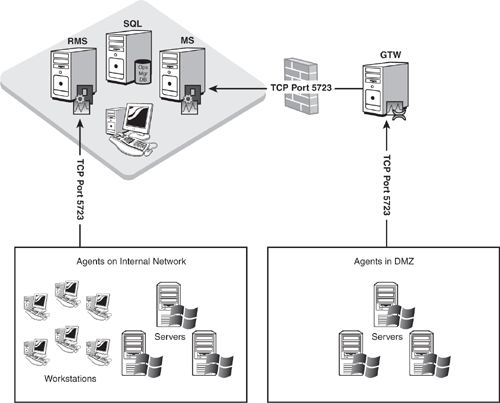
The ability to monitor agents within workgroups, untrusted domains, or a DMZ in a secure manner is an important feature to consider when designing your OpsMgr solution. Chapter 10, “Complex Configurations,” discusses gateway server implementation and configuration, and Chapter 11, “Securing Operations Manager 2007,” discusses using certificates to communicate with workgroups, untrusted domains, and DMZs.
Note: Reduced Traffic when Deploying Agents with a Gateway Server Configuration
If you are deploying agents and going through a gateway server to the other domain, know that although the RMS sends the command to deploy the agents to the gateway server, the gateway server does the actual agent deployment. This means there is minimal traffic on the link between the RMS and the gateway server.
Operations Manager 2007 adds functionality that captures, aggregates, and reports on application crashes (Dr. Watson errors). This functionality uses the OpsMgr 2007 feature called Agentless Exception Monitoring (AEM).
From a planning perspective, if there is a requirement to deploy AEM, there needs to be a plan that provides a server that stores the crash information and deploys a group policy to redirect the errors to the AEM server.
Clients running Windows 2000 or Windows XP use SMB (Server Message Block Protocol) to write crash information to a folder that you specify. Windows Vista clients use HTTP to send crash information. From a planning viewpoint, the server you will use must be identified and have sufficient space to store crash information. (Crash information can range from very small up to 8GB.)
The initial reaction to gathering Dr. Watson crash information and analyzing it is often a question of, why bother? The application crashes; the user restarts it. What’s the big deal? The big deal here is that every crash affects end-user productivity and has an effect on the bottom line for a company. By collecting this information, identifying patterns, and working to resolve them, an organization can take a large step forward to becoming more proactive in situations affecting the end users in the organization, which in turn affects the productivity of that organization. An example of how we can use the data collected by AEM is shown in Figure 5.5, where we display a sample AEM report showing the top applications crashing over time.
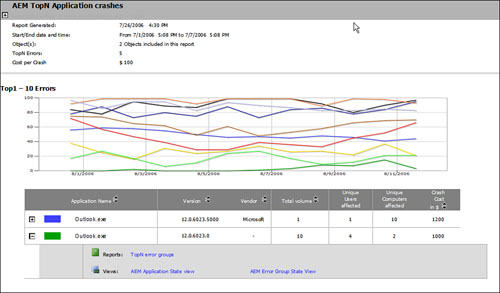
Note: Collecting Crash Information for Server Applications
You also want to consider the case of server application crashes. In most organizations, if there were a major outage in a mission-critical application, nontechnical executives will be aware of the situation and will typically ask two questions: “What happened? And how are we going to prevent it in the future?” Collecting the information helps you answer “what happened,” and working with support staff will help you answer “how to prevent it in the future.”
The Web Console Server provides a web-based version of the Operations console. This console provides monitoring-only functionality, not the full functionality available within the Operations console. The Web console does not provide Administration, Authoring, or Reporting functionality.
Adding this component means that the various management servers providing web-based administration must have IIS installed and sufficient resources to provide the additional functionality. The Web console uses port 51908, so there may also need to be port exceptions made if this functionality is required outside the local area network (LAN).
From a planning point of view, the Web console is most likely installed on the RMS and any other management servers in your environment. This component is often used to provide access to OpsMgr for users who are either monitoring OpsMgr (helpdesk, or peripheral users of OpsMgr) or will not be using the Operations console regularly.
Figure 5.6 shows a sample architecture where each of the optional functions for OpsMgr is integrated, including reporting and trending, ACS, multiple management servers, servers in the DMZ, AEM, and Web console functionality. The graphic shows each component running on a separate server, but you can combine them in certain situations. Chapter 6, “Installing Operations Manager 2007,” discusses in detail how to deploy these configurations.
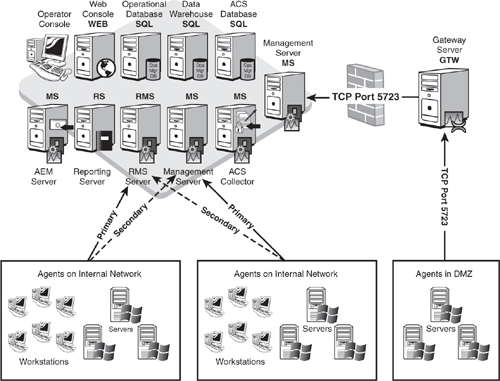
For quick reference, Table 5.1 shows each of the different Operations Manager components and whether they can coexist on the same machine with other components (an “X” indicates that the two specific components can coexist on the same system).
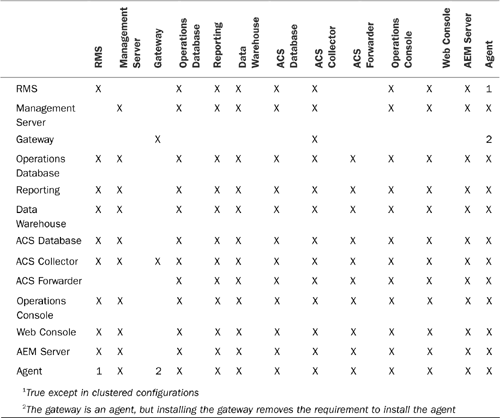
As we have discussed, a variety of additional components are available that provide additional functionality in Operations Manager 2007. Properly planning for their deployment will go a long way toward developing a solid OpsMgr architecture that meets the requirements of your organization.
Chapter 4 discussed the concepts of multihomed architectures and considerations for deploying multihoming. Examples when multihomed architectures may be appropriate include the following:
Providing horizontal support silos (one group focusing on applications, another on services)
Transitioning to OpsMgr 2007 from MOM 2005
Testing or pre-production environments
By definition, a multihomed architecture is based on the concept of an agent reporting to two management groups; if we’re considering multihoming, we must plan for a multiple-management group configuration. Deploying multiple management groups increases the number of servers required to provide the OpsMgr functionality.
Another item to consider when planning a multihomed deployment is the impact on the agent. Although Microsoft officially supports up to four management groups for multihoming (it may work beyond that, but Microsoft supports four), each additional management group an agent reports to increases the load on the client. This increase is because the agent is sandboxed (it keeps a separate area of memory) for each management group to which it is multihomed.
Testing multihomed architectures should focus on determining the resource impacts on the client as well as validating that rules from each management group do not impact each other.
As we discussed in Chapter 4, connected management groups in OpsMgr 2007 have replaced the functionality referred to as tiering in MOM 2005.
There are a number of reasons for using a connected management group design when you have multiple management groups:
The number of agents to monitor exceeds supported limits.
You need total separation of administration control to match geographic locations or to address bandwidth limits in your network environment.
There is a requirement to facilitate communication between two OpsMgr environments in the case of a merger of two organizations.
Unlike MOM 2005 tiering, connected management groups do not forward alerts between management groups. This greatly simplifies the planning requirements for this type of a configuration. Because alerts are not forwarded, there is no increase in the volume of data sent from a lower-level management group (which was the case with MOM 2005).
From a planning perspective, here are the important items to remember
This is a multiple-management group design.
Each management group must be designed and have the hardware necessary to provide its required functions.
Tip: What Can Be Seen in a Connected Management Group
When you open the Operations console and connect to another management group, you can see the alert information and can perform tasks on the connected management group. You cannot see performance data or state data for the connected management group.
From a networking perspective, a connected management group connects to the SDK service on the RMS in the other management group. When connected to the Operations console, your console is communicating with the RMS in the management group you connected to, which in turn talks to the RMS of the connected management group.
Figure 5.7 shows the communication between these connected management groups.
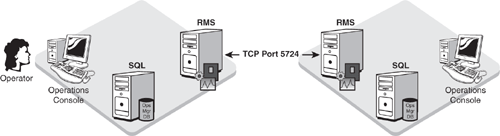
Communication occurs via TCP port number 5724, so any firewall configurations must have this port open between the RMS in the first management group and the RMS in the second management group.
During the POC phase, you should spend time validating the ability to access alert information, performing tasks from each of the connected management groups, and validating communication between each of these environments.
In summary, connected management groups provide a simple method to bring together multiple management groups in OpsMgr 2007. If you plan your management groups properly, the amount of additional planning required to support connected management groups is minimal.
When planning to deploy Operations Manager 2007 in a multiple-domain environment, you have two primary areas to focus on:
Providing secure authentication for all agents being monitored
Identifying the accounts to use to perform functions in each of the domains
As we discuss in the “Agents in Workgroups or DMZs” section of this chapter, OpsMgr 2007 requires mutual authentication. Mutual authentication, in turn, depends on either Kerberos or certificate authentication.
Kerberos authentication is available within a domain, within a multidomain configuration where a two-way trust exists, or across a cross-forest trust. Figure 5.8 shows these authentication scenarios.

You can use certificates to provide mutual authentication for environments that cannot use Kerberos authentication, such as a DMZ, untrusted domains, and workgroup scenarios, which we discuss in the “Agents in Workgroups or DMZs” section of this chapter.
Tip: Communications Across Trust Boundaries
Chapter 11 discusses the gateway server and using certificates for mutual authentication.
The other concept to remember when planning for multiple domains is that each domain requires implementing security accounts with the necessary access rights. Keep the following points in mind:
You will need an account with permissions to deploy agents to each system you will monitor. This often translates to a user account that is a member of the Local Administrators group on all systems or is a Domain Admin.
You will also need accounts to perform the functions the management packs execute (as an example, the Active Directory management pack will need rights to perform specific checks on information within Active Directory).
To summarize, deploying OpsMgr into an environment with multiple domains requires mutual authentication and user accounts with access rights to perform the actions required in each domain that has monitored agents.
As part of planning your OpsMgr environment, you will want to determine what approach to use for deploying agents. In MOM 2005, the recommended method to deploy agents used the MOM user interface. This approach placed the console in the software distribution business, rather than embracing existing technologies to deploy the agent. OpsMgr 2007 includes multiple approaches to agent deployment. Methods include an enhanced push of the agent from the Operations console, manual installation, deployment via Systems Management Server/Configuration Manager, and automated configuration through Active Directory integration.
Active Directory Integration provides a method to auto-assign those agents to management servers. Assignment is dynamic, based on the configuration you define within the Operations console. If you have a medium to large-sized enterprise environment, we strongly suggest considering Active Directory integration as a primary deployment technique.
Requirements and prerequisites for using Active Directory integration include the following:
You must configure AD integration in every domain that has agents.
Each domain must be at the Windows 2000 Native or Windows Server 2003 functional mode.
Run the MOMADAdmin tool to prepare each domain. This tool makes changes within Active Directory to create the required container, folder, and objects, and to assign the appropriate security rights. To run the tool, you must be a domain administrator with .NET Framework 2.0 installed on the system the tool will run on. Active Directory integration does not require any schema extensions.
In Chapter 9, “Installing and Configuring Agents,” we review each of the available options for deploying the OpsMgr agent. In this chapter, we are focusing specifically on the planning aspects necessary for setting up Active Directory integration in your OpsMgr environment.
The out-of-the box functionality that comes with Operations Manager 2007 includes strong management capabilities for Microsoft-based products. However, most organizations are heterogeneous and require monitoring functionality beyond what is available with a Microsoft-specific solution. Using product connectors, the OpsMgr Software Development Kit (SDK), and PowerShell can help address expanding functionality beyond a Microsoft-specific environment:
Product connectors exist to connect OpsMgr to third-party products such as management solutions or helpdesk solutions.
The OpsMgr SDK is a .NET library for developers to use when programming integration with OpsMgr 2007.
The Command Shell is a customized instance of PowerShell and provides an extremely powerful command shell interface to Operations Manager.
Depending on the requirements identified for your Operations Manager solution, you may need to integrate OpsMgr with other systems. Examples of this often include integrating with other management products or a trouble ticketing system.
As part of integrating with a trouble ticketing system, specific OpsMgr-generated alerts will create tickets within the ticketing system. As the status of the OpsMgr alert changes, the status of the trouble ticket updates as well. Finally, if the ticket closes out in the trouble ticketing system, the alert is also resolved in OpsMgr.
Product connectors can be either unidirectional or bidirectional. Unidirectional connectors only forward alerts from OpsMgr to another product. Bidirectional connectors forward alerts from OpsMgr to another product and keep the products synchronized, as illustrated in the example of the trouble ticketing system.
Based on the deployment stages we discussed in Chapter 4 (Assessment, Design, Planning, POC, Pilot, Implementation, and Maintenance) there are multiple points where you would need to consider product connectors during your OpsMgr planning:
Consider product connectors during the Assessment phase, and determine if there is a business requirement for their deployment. If a particular product connector is necessary, also assess the specifics of the connection—including which connector is required, the server OpsMgr will communicate with, the product and version of the product OpsMgr will connect to, and whether alerts will be forwarded in one or both directions. Integrate this information into the design document to describe how to implement the product connector.
The Planning stage is where the majority of the work takes place related to deploying the product connector. The tasks that occur during the POC, Pilot, and Implementation steps are also determined in the Planning stage. To deploy a product connector effectively, we recommend you also deploy it as part of your POC environment. In the case of a product connector, this requires that a server in the POC environment run the third-party management solution. We suggest testing the product connector during a POC rather than first trying to incorporate it into a production environment!
Tasks during the POC include downloading, installing, configuring, and documenting the process for the product connector. After the product connector is functional, test the connector to verify that alerts are forwarding between OpsMgr and the third-party management tool. You will want to stress-test the connector to determine how many alerts it can forward in a given period of time and to see if it can handle the load expected in the production environment.
Finally, during the Pilot stage, use the document you created that describes the process used in the POC. This document should provide the steps needed to configure the connector in the pilot environment.
There are times when OpsMgr cannot match the business requirements without having to extend its functionality. To address this, Microsoft has provided both the Operations Manager SDK and the Command Shell.
Before we discuss the Operations Manager SDK, we want to avoid any confusion on the topic by clarifying the difference between the Operations Manager SDK and the Operations Manager SDK service:
The Operations Manager SDK provides the ability to extend the capabilities of Operations Manager 2007.
The Operations Manager SDK service (OpsMgr SDK service) primarily provides connectivity to database resources (see Chapter 3, “Looking Inside OpsMgr,” for details on the OpsMgr SDK service).
If the SDK needs to be part of your OpsMgr solution, identify this requirement during the Assessment stage. As an example, if your OpsMgr requirements include a custom solution (such as a custom management console), you should identify the SDK as a potential tool. During the Assessment phase, identify in detail as much as possible regarding SDK requirements to provide effective information for the design. During the Design stage, these custom requirements should be included as part of the design document.
Actually creating the customized solution should occur during the POC stage. Within the POC, you can create and test the solution without potential impact to a production environment. Evaluate and update the solution during the POC phase to validate that it effectively meets your business requirements. You should deploy the custom solution into the production environment as part of the Pilot stage and roll it into full production during the Implementation phase.
As you evaluate how to meet the requirements identified for your OpsMgr solution, consider the Command Shell as a potential tool. The Operations Manager Command Shell is a customized instance of Windows PowerShell functionality that is available within Operations Manager. The Command Shell is extremely powerful and can perform multiple tasks, including tasks not available within the Operations Manager User Interface (UI). To provide effective information for your design, during the Assessment phase you will want to identify and specify as much information as possible regarding Command Shell requirements. These custom requirements for Command Shell would also be included within the design document.
You can use the Command Shell to do things that are difficult within the UI, such as enabling proxying on your Exchange servers, creating new management group connections, discovering Windows computers, and importing and exporting management packs. An excellent resource for information on Command Shell is available at http://blogs.msdn.com/scshell/.
As with the SDK, any customized solutions you identify should be created during the POC so they can be tested without affecting production systems. Deploy the customized solution during the Pilot phase and roll it into full production during the Implementation phase.
To ensure a highly available OpsMgr 2007 configuration, you should assess each of its components to determine the best method to make it highly available for your environment. We will review each of the components, discuss the impacts of an outage of each component, review high availability solutions for the component, and provide a recommended approach to provide high availability.
The requirement for a highly available configuration should be identified during the Assessment stage and integrated into the OpsMgr design document. Test these available configurations in POC, deploy them as part of the Pilot stage, and finally roll them into full production.
It is important to note that while high availability may be a business requirement, it may not apply to all components. As an example, if the need is to provide a high-availability solution on the monitoring aspects of OpsMgr only, you may not need to provide high availability for the ACS components of OpsMgr. In addition, high-availability requirements will only apply to those components you deploy in your particular OpsMgr configuration.
As we previously discussed in Chapter 4, the RMS is the first management server installed. The RMS performs specific functions within the OpsMgr environment. At first glance, the role that this system provides seems similar in concept to that of an Active Directory FSMO (Flexible Single Master Operations) role. However, Active Directory can often function for some time without available FSMO roles. The impacts of an outage on the RMS are more apparent and include the following:
You cannot open the Operations console (as shown in Figure 5.9). However, OpsMgr itself is still functioning, and information is still being gathered and stored in the Operations and Data Warehouse databases.
Communication with gateway servers is interrupted.
Connected management groups will not function because they connect via the RMS servers in each management group.
The RMS may be providing management server functionality to agents that will need to be able to fail over to another management server in the management group to continue monitoring.
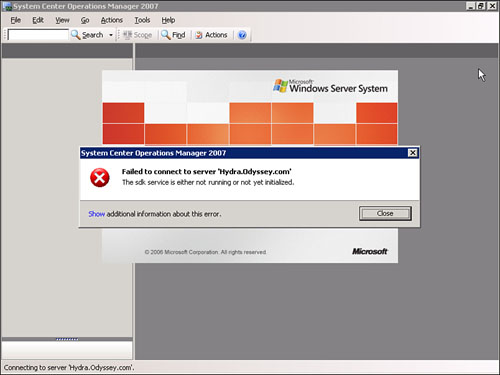
Based on the impacts to your OpsMgr installation when the RMS is not available, we strongly recommend providing a form of redundancy for this component.
A single redundancy option is available that provides automated failover of the RMS services: clustering. Microsoft supports an Active/Passive RMS cluster configuration that provides failover of the RMS service (as a generic resource type) to the passive node of the cluster. This capability offers a method for providing redundancy on this role to address situations such as patch management or temporary system outages. In the base version of OpsMgr 2007, if you do not initially install your environment with a clustered RMS, the only way to make the RMS clustered is by reinstalling Operations Manager 2007. It currently appears that this will change with OpsMgr Service Pack (SP) 1, and Microsoft will support that particular functionality approximately a month after releasing SP 1.
Tip: Monitoring RMS Clustered Nodes
Prior to SP 1, you cannot install an agent on the RMS clustered nodes. These nodes must be configured as agentless managed.
A nonautomated method for addressing the loss of RMS functionality is to promote another management server to become the RMS. The ManagementServerConfigTool utility, located on the Operations Manager installation media in the SupportTools directory, provides this functionality. The tool provides the ability to promote a management server to an RMS using the PromoteRMS option. Using this tool involves exporting the key from the RMS, importing it on a designated management server, promoting that management server to the RMS role, restarting services on the original RMS, and reconnecting to the console. We describe this procedure in detail in Chapter 12, “Backup and Recovery.”
Note: RMS Promotion Issues
The original released version of Operations Manager 2007 has an issue in promoting a management server to the RMS role. The issue is that data warehouse processing does not move correctly to the new RMS. The only workaround available prior to SP 1 is to continue to run the SDK service on the machine that was the previous RMS.
The recommended approach for providing a high-availability solution for the RMS is to deploy it on an Active/Passive cluster. Moving the RMS role to another management server is a manual (and not a trivial) process.
The Management Server Component provides redundancy and increased scalability for Operations Manager. The approach for providing redundancy for management servers is to have multiple servers, such that you can split the agent load if there is a server failure. The impact of a single management server failing is minor if other management servers are available to handle the load. Management servers (other than the RMS) do not support other redundancy approaches such as clustering and load balancing.
Gateway servers can be configured to use secondary management servers should their primary management server fail (we do not recommend using the RMS as a secondary management server).
In summary, the recommended approach for redundant management servers is to install sufficient management servers to distribute the agent load among them without exceeding the recommended limit of 2000 agents per management server.
The gateway server functionality provides a secure method for monitoring agents in untrusted domains or workgroups. Similar to the Management Server Component, redundancy is available by deploying multiple gateway servers.
If a gateway server is offline, the agents in the remote domain or workgroup will be unable to provide information to OpsMgr until a gateway server is available. Agents will queue up the data until the gateway server is available again, but if an agent queue fills up, data will be lost.
The gateway servers themselves can be configured to fail over to multiple management servers using the Command Shell Set-ManagedServer-GatewayManagementServer command.
To summarize, the recommended approach for redundancy is to install enough gateway servers to distribute the load of agents in the DMZ or workgroup and to not exceed the recommended limit of 200 agents per gateway server (see the Operations Manager 2007 Performance and Scalability White Paper at http://technet.microsoft.com/en-us/library/bb735308.aspx). You should also configure the gateway server to fail over to multiple different management servers.
The Reporting Server Component uses SQL 2005 Reporting Services to provide web-based reports for Operations Manager. MOM 2005 reporting servers could be highly available by installing multiple servers into a web farm or through using a load-balancing solution (such as Microsoft Network Load Balancing, or NLB).
In OpsMgr 2007, the reporting server integrates directly with the Operations console, introducing another level of complexity into the equation. If you try to access the Reports space while the server is unavailable, an error message is generated about a failure loading the reporting hierarchy (shown in Figure 5.10). To avoid this type of message, it would be better to provide a more highly available reporting solution. You can configure the reporting server settings in the Operations console by navigating to Administration -> Settings -> Reporting.
Although it is not optimal or supported, you can access reports from outside the Operations console with a web browser at http://<servername>/reports. As long as reports are accessible outside of the Operations console, we can deploy multiple reporting servers and use NLB to provide redundancy. The major issue with this is keeping the reports synchronized between the various reporting servers; Chapter 10 discusses the available options.
There are currently no officially supported options to provide high availability for the Reporting Server Component in Operations Manager 2007.
The Operations Database Component can be a single point of failure for the management group. If the management server loses connectivity to the Operations database, the management server buffers the data from the agents it manages. The size of this queue is 100MB by default. If the buffer fills, the management server stops taking data from agents until it reconnects with the database. Once the connection with the database is reestablished, the management server uploads the buffered information and resumes accepting data from its agents. If the Operations console is opened while the Operations database is down, no message is generated, but the Operations console hangs or “gets stuck” on loading, as shown in Figure 5.11.

The recommended method that provides a high-availability solution for the Operations Database Component is clustering. Microsoft supports an Active/Passive Operations database using SQL Server clustering, providing database failover to the passive node of the cluster. Database clustering provides the ability to maintain the functionality of the Operations database in situations such as patch management and temporary outages.
The Data Warehouse Component provides the long-term repository for Operations Manager 2007, similar to the Reporting Component used with MOM 2005. The impact of an outage is much more visible than it was in MOM 2005:
If the MOM 2005 Reporting database was down, you could not pull up reports and could not transfer data from the Operations database to the Reporting database. Data transfer was a nightly job.
In OpsMgr 2007, the Data Warehouse Component is part of the Operations console and written to in real time. This makes the impact of a failure much more apparent.
If you select the Reporting button in the Operations console while the database is down, a message appears (displayed in Figure 5.12) stating that the loading of the reporting hierarchy failed. To reconnect, close and reopen the Operations console after the data warehouse is back online.
The recommended method that provides a high-availability solution for the Data Warehouse Component is clustering. Microsoft supports an Active/Passive Operations database (SQL Server clustering), which provides failover of the database to the passive node of the cluster.
The ACS Database Server Component provides the central repository for audit information gathered by Operations Manager. If the ACS database is unavailable, information continues to gather in the ACS collector’s queue. The size of the ACS collector queue is configurable through Registry settings. See Appendix C, “Registry Settings,” for details on Operations Manager Registry settings.
As the ACS collector queue fills, it will begin to stop accepting new connections from the forwarders and eventually disconnect additional forwarders. This leaves the forwarders holding the data until the ACS collector is available again.
The only currently supported method to provide a high-availability solution for the ACS Database Component is clustering. Microsoft supports using an Active/Passive ACS database (SQL Server clustering) providing database failover to the passive node of the cluster.
The ACS Collector Component gathers events from the ACS forwarders, processes them, and sends the data to the ACS database. If a collector is down, it cannot take events from its forwarders or send them to the database. The agents (forwarders) do not have queues for ACS forwarding, because the Windows NT Security Event log provides that functionality. Several options are available for redundancy on the ACS Collector Component, although Microsoft does not support these:
Establish a backup ACS collector server. At first, this seems like the logical approach, but the problem is that you cannot have two collectors reporting to the same ACS database. Because each collector writes to a different ACS database, using a backup during a collector outage means security events are sent to a different database server during that outage. An additional ACS database server would also be required to provide this type of functionality.
Provide redundancy for the collector with a cold standby collector. This computer is configured as a collector where the service is not running. This can be a cold server configured to report to the same ACS database server at the same time. To activate the server, you would turn on the service and copy over the AcsConfig.xml file (which controls the state of all the forwarders). This option provides a method to avoid adding a redundant ACS database server to provide high availability for the ACS Collector Server Component.
Cluster the collector as a generic cluster service. The problem here is that this is not a supported configuration.
Overall, none of the options available for redundancy on the ACS collector server are optimal. Our recommended approach for providing redundancy on this component is to use a cold standby collector.
OpsMgr’s capability to capture, aggregate, and report on application crashes requires an AEM share and a communications port for the Vista clients. If these are unavailable, clients will not be able to report crash data.
There are currently no supported (or recommended) methods to provide high availability for this file share. Chapter 10 discusses potential approaches to provide redundancy for the AEM functionality.
The Operations console is the primary interface to access your Operations Manager environment. Loss of the console prevents performing any of the major actions available within the console, such as monitoring, authoring, reporting, and administration.
You can achieve high availability for the Operations console by installing multiple consoles. Install an Operations console on each management server (including the RMS) and on your OpsMgr administrators’ workstations.
The Web console provides monitoring capabilities for OpsMgr for systems without an installed Operations console. Helpdesk personnel and subject matter experts (SMEs) will typically use the Web console. These groups require monitoring functionality only for their particular areas of focus.
During the time the Web Console Component is unavailable, the impact would be the inability for anyone to access this console. You can mitigate the impact of losing the Web console by installing the Operations console for primary Operations Manager users.
The recommended method for providing a highly available Web console solution is by installing multiple Web console servers and leveraging Network Load Balancing (NLB) or other load-balancing solutions. Using a load-balanced configuration, the Web console is accessible even if one of the Web console servers is unavailable.
The last major components to discuss from a high-availability perspective are the agent itself and the ACS forwarder functionality, which is configurable with the agent. A nonfunctioning agent is unable to report information to the management servers, which in turn makes it unable to provide any current information for the Operations console.
Redundancy on the agent itself should not be required, because the agent’s function is only to report information to the management servers. You can obtain high availability for the agent by configuring multiple management servers for the agent to report to.
However, the forwarder functionality has additional complexities when it comes to highly available configurations. If a forwarder is assigned to a collector that is unavailable, the forwarder cannot send its information and will rely on the Security Event log to store the information, which is sent to the ACS collector when it becomes available. You can define multiple collectors by changing the Registry settings on the forwarder. The change is at HKLMSOFTWAREPoliciesMicrosoftAdtAgentParameters, within the AdtServers value. List each available collector in this key, with a hard return entered after each entry. To fail the forwarder back to the original collector, stop the service on the new collector so that the agent will fail itself back over to the original machine.
A commonly asked question is whether one can “virtualize” the various Operations Manager 2007 components. There are two short answers for this: yes and no. Before delving into how to answer this for your environment, let’s review the benefits to virtualization:
Virtualization can reduce IT costs by consolidating multiple server operating systems onto a single physical server. Using a single server reduces the hardware costs and the space required to store your servers (thus decreasing the datacenter costs such as power and air conditioning).
You can move virtual machines between different physical hardware easily, and it can be easier to back out changes made to the operating system than with a physical machine. For more details on the concepts and products available for virtualization, see Chapter 20, “Automatically Adapting Your Environment.”
You will also want to consider your organization’s policy regarding server virtualization. We include the following sidebar as an example of a virtualization policy.
From an Operations Manager 2007 supportability perspective, Microsoft officially supports virtualization of the Operations Database Component, Data Warehouse Component, RMS, Management Server Component, Reporting Server Component, Gateway Server Component, and agents on virtual machines running Virtual Server 2005.
As you consider virtualization of these components, it is important to think about any limitations in the virtualization product. As an example, Virtual Server 2005 R2 is currently limited to a single processor and 3.6GB of memory. A single processor cannot effectively take advantage of multithreaded applications. Both of these restrictions may represent bottlenecks to the Operations Manager 2007 components. Both VMWare and updates to the Microsoft virtualization functionality should address these limitations (the Microsoft virtualization functionality is scheduled for release approximately 6 months after the release of Windows Server 2008).
Smaller environments, such as those with fewer than 100 agents, or lab/testing environments will make good candidates for virtualization. The smaller environments are not as likely to push the limits of the virtualized operating systems, and for the lab and testing environments performance does not generally have to be optimal.
Finally, when considering whether to use virtualization technologies, do not forget System Center Virtual Machine Manager (SCVMM), combined with Operations Manager 2007. The Virtual Machine Manager can identify likely candidates for virtualization and assist with the Physical-to-Virtual (PtoV) conversion of these systems. We discuss SCVMM more in Chapter 20.
Our own recommendation is that you not virtualize any of the database components of Operations Manager 2007 (Operations database, Data Warehouse database, and ACS database) because these are disk intensive and may also be processor intensive. A good document on SQL 2005 virtualization is available for download at http://download.microsoft.com/download/a/c/d/acd8e043-d69b-4f09-bc9e-4168b65aaa71/SQLVirtualization.doc. (We include this link in Appendix E, “Reference URLs,” for your convenience.) We also do not recommend virtualization of the Root Management Server Component, because this component is memory and processor intensive.
Some components we do recommend as candidates for virtualization include the following:
Gateway Server—. The gateway server is a good candidate for virtualization because it is not a very intensive OpsMgr component. As with other components, you should monitor it for bottleneck conditions. If the server is bottlenecked, consider the addition of another gateway server to split the load between the systems.
Management Server—. Management servers can be virtualized to provide failover capabilities for agents without adding additional hardware. The number of agents reporting to the management server should be determined by how much of a load can be sustained before the server starts to bottleneck. The number of agents reporting to the management server will vary depending on the performance of the host hardware and the type of agents being monitored, but will most likely be less than 2000 agents.
Reporting Server—. The SQL Server 2005 Reporting Server Component is an intensive application, but because it provides reporting functionality (which may not require the highest levels of performance given that reports can be scheduled), it may make a good candidate for virtualization.
Agents—. If your agents are virtualized, OpsMgr can monitor them, so that doesn’t need to be a concern.
Determining whether you should virtualize any of the servers in your OpsMgr environment ultimately depends on the virtualization policy you have in place and the business requirements for your Operations Manager 2007 environment.
This chapter discussed the planning considerations when working with optional components and complex Operations Manager 2007 configurations.
With all of the different components available within Operations Manager 2007, it can be extremely complex or impossible to provide an OpsMgr configuration that is fully redundant and highly available. The good news is that for most organizations, highly available configurations are not required for all of the OpsMgr components. Chapter 10 moves from planning to detailed discussions of the steps involved in deploying complex configurations.
The next chapter discusses steps to implement OpsMgr, including optional components discussed in this chapter.