
3.7 Saliency Using More Comprehensive Statistics
Let us review the basic problem raised in the earlier part of this book: what is the attentional location in the visual field? There are many different points of view. Some models simulate the biological visual system (e.g., the BS model and its variations), and some are mainly based on statistical signal processing theory such as information theory (the AIM model) and decision theory (the DISC model), although biological plausibility is also appreciably considered. A model of saliency using natural statistics abbreviated as SUN by taking the first letter of ‘saliency using natural’ statistics [9, 50] belongs to the second type, that is based on information theory in a Bayesian framework. It is somewhat similar to the AIM model while working in a pure bottom-up fashion, but the statistics of the SUN model are based on whole lifetime in the world; that is, the statistics have to span all time and space, not for some data sets or for the current period as with the AIM model. Consequently, the SUN model is more comprehensive for probability estimation that is independent of the test image. In addition, the standpoint of the SUN model is to search the object's position, and hence both top-down and bottom-up attentions in the statistical model are considered in an integrated manner.
Its idea is very basic: the goal of development for the HVS is to find potential targets (food and prey) for primitive humans' or animals' survival [50]. On this premise, the attention focus in the scene for the HVS should be the location where the target appears with high probability or some feature of that target can be easily distinguished, for example, the attention of a ravenous tiger focuses on the place where prey often appears or where the objects (rabbits or sheep) are in motion. Although the tiger does not know which prey will appear (maybe it has a different shape and colour), the occurrence of motion (associated with a higher chance of capturing prey) attracts more attention from the tiger than other features. Thereby, the probability or information of arising from the object is closely related to visual attention. Apparently, the potential targets are related to top-down knowledge as well. The SUN model therefore combines top-down and bottom-up attention in a Bayesian framework with proper formulation, and in this chapter we lay great stress on the bottom-up attention model.
3.7.1 The Saliency in Bayesian Framework
Since the interesting (potential) target is related to locations and features, the probability estimation of a target at each location in a given observed feature is obligatory. Let z be a point (pixel) in input scene, and c denotes the class label: c = 1 (the point under consideration belongs to a target class), and c = 0 (otherwise). Since the HVS is to catch a potential target, here we only consider the case of c = 1. Clearly the probability of the target being present in the scene is the joint probability with the target's location and the observed features. Two random variables l and x denote the location and feature, respectively. Note that here we only consider a feature in the following equations (symbol x is not a bold letter), since it is easy to extend for a set of features later, using bold letter x instead of x. According to the aforementioned concept, the attention focus is at which the target probably appears or the outstanding feature, and the saliency of point z is directly proportional to the conditional probability density on the location and the feature ![]() , where xz represents the feature value observed at location z and lz is the coordinate of z. By using the Bayesian rule, the conditional probability density is expressed as
, where xz represents the feature value observed at location z and lz is the coordinate of z. By using the Bayesian rule, the conditional probability density is expressed as
In general, the probability density of a feature in natural images is not related to location, so the independence between location and feature is considered to simplify the Equation 3.51.
From Equations 3.51 and 3.52 the saliency at point z for a feature is rewritten as
where SMz is a scalar quantity that denotes the salient value at location lz for a feature, the symbol ∝ represents direct proportionality. The first term on the right side of Equation 3.53 is an inverse probability density independent of the target that may be considered as bottom-up saliency, and the second and third terms represent the likelihood of the target's presence for the feature and the location, respectively, which may be related to the subject's intention and can be considered as top-down saliency in the following analysis. Since the logarithm function is monotonically ascending, for consistency with the previous computational model (AIM and DISC models), take the logarithm function for Equation 5.53:
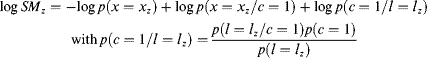
where the symbol ∝ in Equation 3.53 is replaced by the equal sign because saliency is a relative scalar. Equation 3.54 gives an expression for both bottom-up and top-down information. A familiar form appears as the first term on the right side of Equation 3.54, ![]() , which is the self-information as mentioned in the AIM model. The smaller the probability of feature xz,
, which is the self-information as mentioned in the AIM model. The smaller the probability of feature xz, ![]() , the more salient is point z. It is obvious that self-information represents bottom-up information if all the features in point, z, are considered. The next term,
, the more salient is point z. It is obvious that self-information represents bottom-up information if all the features in point, z, are considered. The next term, ![]() , favours the feature's value with the target's knowledge. The tiger prefers the white colour to green when it waits for its prey (white rabbit or sheep) in green luxuriant undergrowth, because a rare feature carries more information. The premise is that the tiger knows the colour of its target. The third term,
, favours the feature's value with the target's knowledge. The tiger prefers the white colour to green when it waits for its prey (white rabbit or sheep) in green luxuriant undergrowth, because a rare feature carries more information. The premise is that the tiger knows the colour of its target. The third term, ![]() , is prior knowledge about location from the tiger's experience, if it has often captured its food (small animals) in this place. Of course, the third is also related to the top-down effect. The second and third terms of Equation 3.54 are related to the likelihood of target appearance, which are called likelihood terms. It is interesting that under the Bayesian framework two kinds of attention effect are expressed in a mathematical equation. What is more interesting is that when omitting likelihood terms the results are reduced to the previous computational models based on information or decision theory.
, is prior knowledge about location from the tiger's experience, if it has often captured its food (small animals) in this place. Of course, the third is also related to the top-down effect. The second and third terms of Equation 3.54 are related to the likelihood of target appearance, which are called likelihood terms. It is interesting that under the Bayesian framework two kinds of attention effect are expressed in a mathematical equation. What is more interesting is that when omitting likelihood terms the results are reduced to the previous computational models based on information or decision theory.
Without regard to the prior location, Equation 3.54 is a combination of self-information and log-likelihood terms, as
Comparing this equation with Equation 3.41, their forms are very similar. Equation 3.55 is just the point-wise mutual information between the visual feature and the presence of a target. However, the meanings of Equations 3.41 and 3.55 have some differences: the class c of Equation 3.41 is defined on the centre or surround windows c ![]() {0, 1}, and here class c = 1 representing the presence of a target. Another discrepancy is that the estimation of the probability density in Equation 3.55 includes wholly natural images (as will be seen in the next section), but it is not like Equation 3.41 which considers the area (the centre and surround windows) in the current image.
{0, 1}, and here class c = 1 representing the presence of a target. Another discrepancy is that the estimation of the probability density in Equation 3.55 includes wholly natural images (as will be seen in the next section), but it is not like Equation 3.41 which considers the area (the centre and surround windows) in the current image.
When potential targets specified by top-down knowledge do not exist (i.e., the free viewing case), the log-likelihood terms are unknown (unspecified target), and only one term in Equation 3.54 remains, which is pure bottom-up attention result at the point z:
Equation 3.56 is just the self-information of a feature at point z, and it implies that the points with rare features attract much more visual attention or, as discussed with the AIM model, the most salient points in the scene are the positions that maximize information. Although Equation 3.56 is almost the same as the concept of the AIM model, the important difference is that all the probability densities in the SUN model's equations are learned with comprehensive statistics in a large natural image set, rather than the statistics in the current input image. To illustrate this difference, let us first review the aforementioned computational models related to information or decision theory. In the AIM model, the probability density estimation of each image patch is based on its surrounding patches in the current image, and in the DISC model, the statistical property of each location for the current input image is estimated with its centre and surround windows. That is, the discrimination of the centre and the surround is performed with the statistical result in the current input image only. In the SUN model, the statistical property is estimated with a large number of natural images in the training set, and the saliency in each point does not depend on the information of its neighbour pixels in the current image. This is based on two considerations: (1) the SUN model is formularized with searching potential targets in natural environment through long-time experience (represented by the large-size database). A single current image cannot cover complete statistical characteristics. (2) Top-down knowledge requires accumulation in history; for example, a young tiger may not know where its prey appears often and what property its prey has when it is just starting to find food. With its mother's teaching or its own experience, the understanding of the necessary statistical property in its life is gradually constituted. The probability density function based on the natural image set only relates to an organism with some experience, not to beginners.
Despite the fact that the SUN model considers both top-down and bottom-up attention, in this section we only discuss the bottom-up saliency computation, that is computing the saliency map using task-independent part in Equation 3.54, due to the scope of this chapter (i.e., we concentrate on bottom-up attention models.)
3.7.2 Algorithm of SUN Model
Considering a colour static image as the input of the computational model we compute the saliency map by first calculating the saliency in each pixel of the image by using Equation 3.56, the bottom-up portion of Equation 3.54. There are two steps: one is feature extraction, and the other is estimation of the probability density over all features. In the equations above, feature xz denotes only a single feature in point z for convenience of presentation; in fact, each pixel in the input image may have many features. In most computational models, the low-level features include colour opponents, orientations and intensity that are widely used in the BS model, variations of BS models, the GBVS model, the DISC model and so on. Other feature filters include ICA basis functions implemented by learning natural images in the AIM. The two kinds of features are considered in the SUN model which form two algorithms as follows, using DoG and ICA filters, respectively, resulting in different processes for feature extraction, probability density estimation and saliency computation.
Algorithm 3.1 SUN based on DoG filter [9]
(3.57) ![]()
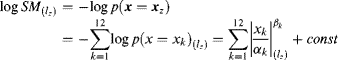
Figure 3.16 The block diagram of the SUN model based on DoG
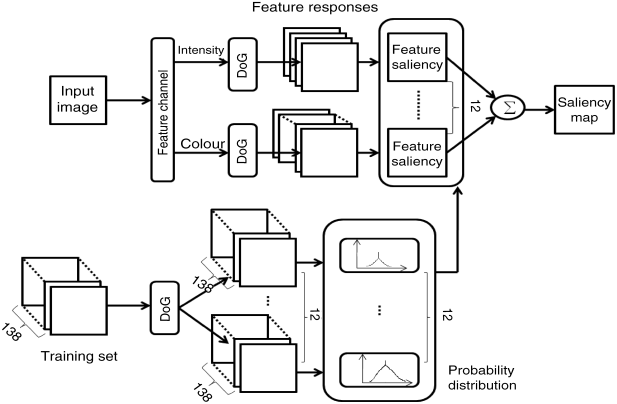
Algorithm 3.2 SUN based on ICA filters [9]
Equation 3.60 is based on the assumption of independence among different feature responses. However, in real applications the assumption does not hold. The responses of the DoG filters are often correlative. This means that multivariable GGD estimation is required. Unfortunately, the estimate for joint probability density of multivariables is complex and difficult. A promising method for feature extraction is ICA filtering that has been used in the AIM model. The natural independent property makes the tough issue solvable. The steps of this Algorithm 3.2 are shown as follows.