
Reputation Management
Dr. Jean-Marc Seigneur, University of Geneva
Reputation management is a rather new field in the realm of computer security, mainly due to the fact that computers and software are more and more involved in open networks. In these open networks, any encountered users may become part of the user base and associated interactions, even if there is no a priori information about those new users. The greater openness of these networks implies greater uncertainty regarding the outcomes of these interactions. Traditional security mechanisms, for example, access control lists, working under the assumption that there is a priori information about who is allowed to do what, fail in these open situations.
Reputation management has been used for ages in the real world to mitigate the risk of negative interaction outcomes among an open number of potentially highly profitable interaction opportunities. Reputation management is now being applied to the open computing world of online interactions and transactions. After the introduction, this chapter discusses the general understanding of the notion of reputation. Next, we explain where this concept of reputation fits into computer security. Then we present the state of the art of robust computational reputation. In addition, we give an overview of the current market for online reputation services. The conclusion underlines the need to standardize online reputation for increased adoption and robustness.
During the past three decades, the computing environment has changed from centralized stationary computers to distributed and mobile computing. This evolution has profound implications for the security models, policies, and mechanisms needed to protect users’ information and resources in an increasingly globally interconnected, open computing infrastructure. In centralized stationary computer systems, security is typically based on the authenticated identity of other parties. Strong authentication mechanisms, such as Public Key Infrastructures (PKIs),1,2 have allowed this model to be extended to distributed systems within a single administrative domain or within a few closely collaborating domains. However, small mobile devices are increasingly being equipped with wireless network capabilities that allow ubiquitous access to corporate resources and allow users with similar devices to collaborate while on the move. Traditional, identity-based security mechanisms cannot authorize an operation without authenticating the claiming entity. This means that no interaction can take place unless both parties are known to each others’ authentication framework. Spontaneous interactions would therefore require that a single or a few trusted Certificate Authorities (CAs) emerge, which, based on the inability of a PKI to emerge over the past decade, seems highly unlikely for the foreseeable future. In the current environment, a user who wants to partake in spontaneous collaboration with another party has the choice between enabling security and thereby disabling spontaneous collaboration or disabling security and thereby enabling spontaneous collaboration.
The state of the art is clearly unsatisfactory; instead, mobile users and devices need the ability to autonomously authenticate and authorize other parties that they encounter on their way, without relying on a common authentication infrastructure. The user’s mobility implies that resources left in the home environment must be accessed via interconnected third parties. When the user moves to a foreign place for the first time, it is highly probable that the third parties of this place are a priori unknown strangers. However, it is still necessary for a user to interact with these strangers to, for example, access her remote home environment. It is a reality that users can move to potentially harmful places; for example, by lack of information or due to uncertainty, there is a probability that previously unknown computing third parties used to provide mobile computing in foreign places are malicious. The assumption of a known and closed computing environment held for fixed, centralized, and distributed computers until the advent of the Internet and more recently mobile computing. Legacy security models and mechanisms rely on the assumption of closed computing environments, where it is possible to identify and fortify a security perimeter that protects against potentially malicious entities. However, in these models, there is no room for “anytime, anywhere” mobility. Moreover, it is supposed that inside the security perimeter there is a common security infrastructure, a common security policy, or a common jurisdiction in which the notion of identity is globally meaningful. It does not work in the absence of this assumption.
A fundamental requirement for Internet and mobile computing environments is to allow for potential interaction and collaboration with unknown entities. Due to the potentially large number of previously unknown entities and for simple economic reasons, it makes no sense to assume the presence of a human administrator who configures and maintains the security framework for all users in the Internet, for example, in an online auction situation or even in proximity, as when a user moves within a city from home to workplace. This means that either the individuals or their computing devices must decide about each of these potential interactions themselves. This applies to security decisions, too, such as those concerning the enrollment of a large number of unknown entities. There is an inherent element of risk whenever a computing entity ventures into collaboration with a previously unknown party. One way to manage that risk is to develop models, policies, and mechanisms that allow the local entity to assess the risk of the proposed collaboration and to explicitly reason about the trustworthiness of the other party, to determine whether the other party is trustworthy enough to mitigate the risk of collaboration. Formation of trust may be based on previous experience, recommendations from reachable peers, or the perceived reputation of the other party. Reputation, for example, could be obtained through a reputation system such as the one used on eBay.3 This chapter focuses on this new approach to computer security—namely, reputation management.
1. The Human Notion of Reputation
Reputation is an old human notion; the Romans called it reputatio, as in “reputatio est vulgaris opinio ubi non est veritas.”4 Reputation may be considered a social control mechanism,5 where it is better to tell the truth than to have the reputation of being a liar. That social control mechanism may have been challenged in the past by the fact that people could change their physical locale to clear their reputation. However, as we move toward an information society world, changing locales should have less and less impact in this regard because reputation information is no longer bound to a specific location, which is also good news for reputable people who have to move to other regions for other reasons such as job relocation. For example, someone might want to know the reputation of a person he does not know, especially when this person is being considered to carry out a risky task among a set of potential new collaborators. Another case may be that the reputation of a person is simply gossiped about. The reputation information may be based on real, biased, or faked “facts,” perhaps faked by a malicious recommender who wants to harm the target person or positively biased by a recommender who is a close friend of the person to be recommended. The above Latin quote translates to “reputation is a vulgar opinion where there is no truth.”6 The target of the reputation may also be an organization, a product, a brand, or a location. The source of the reputation information may not be very clear; it could come from gossip or rumors, the source of which is not exactly known, or it may come from a known group of people. When the source is known, the term recommendation can be used. Reputation is different from recommendation, which is made by a known specific entity. Figure 41.1 gives an overview of the reputation primitives.
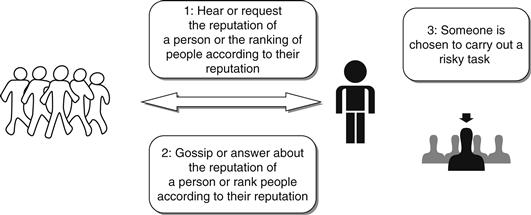
Figure 41.1 Overview of the reputation primitives.
As La Rochefoucauld wrote7 a long time ago, recommending is also a trusting behavior. It has not only an impact on the recommender’s overall trustworthiness (meaning it goes beyond recommending trustworthiness) but also on the overall level of trust in the network of the involved parties. La Rochefoucauld highlighted that when one recommends another, they should be aware that the outcome of their recommendation will reflect on their own trustworthiness and reputation, since they are partly responsible for this outcome. Benjamin Franklin noted that each time he made a recommendation, his recommending trustworthiness was impacted: “In consequence of my crediting such recommendations, my own are out of credit.”8 However, his letter underlines that still he had to make recommendations about not very well-known parties because they made the request and not making recommendations could have upset them. This is in line with Covey’s “Emotional Bank Account,”9,10 where any interaction modifies the amount of trust between the interacting parties and can be seen as favor or disfavor—a deposit or withdrawal. As Romano underlined in her thesis, there are many definitions of trust in a wide range of domains,11 for example, psychology, economics, or sociology. In this chapter, we use Romano’s definition of trust, which is supposed to integrate many aspects of previous work on trust research:
Trust is a subjective assessment of another’s influence in terms of the extent of one’s perceptions about the quality and significance of another’s impact over one’s outcomes in a given situation, such that one’s expectation of, openness to, and inclination toward such influence provide a sense of control over the potential outcomes of the situation.12
In social research, there are three main types of trust: interpersonal trust, based on the outcomes of past interactions with the trustee; dispositional trust, provided by the trustor’s general disposition toward trust, independent of the trustee; and system trust, provided by external means such as insurance or laws.13 Depending on the situation, a high level of trust in one of these types can become sufficient for the trustor to make the decision to trust. When there is insurance against a negative outcome or when the legal system acts as a credible deterrent against undesirable behavior, it means that the level of system trust is high and the level of risk is negligible; therefore the levels of interpersonal and dispositional trust are less important. It is usually assumed that by knowing the link to the real-world identity, there is insurance against harm that may be done by this entity. In essence, this is security based on authenticated identity and legal recourse. In this case, the level of system trust seems to be high, but one may argue that in practice the legal system does not provide a credible deterrent against undesirable behavior, that is, it makes no sense to sue someone for a single spam email, since the effort expended to gain redress outweighs the benefit.
The information on the outcomes of past interactions with the trustee that are used for trust can come from different sources. First, the information on the outcomes may be based on direct observations—when the trustor has directly interacted with the requesting trustee and personally experienced the observation. Another type of observation is when a third party himself observes an interaction between two parties and infers the type of outcome. Another source of information may be specific recommenders who report to the trustor the outcomes of interactions that have not been directly observed by the trustor but by themselves or other recommenders. In this case, care must be taken not to count twice or many more times the same outcomes reported by different recommenders.
Finally, reputation is another source of trust information but more difficult to analyze because generally it is not exactly known who the recommenders are, and the chance to count many times the same outcomes of interactions is higher. As said in the introduction, reputation may be biased by faked evidence or other controversial influencing means. Reputation evidence is the riskiest type of evidence to process. When the evidence recommender is known, it is possible to take into account the recommender trustworthiness. Since some recommenders are more or less likely to produce good recommendations, even malicious ones, the notion of recommending trustworthiness mitigates the risk of bad or malicious recommendations. Intuitively, recommendations must only be accepted from senders that the local entity trusts to make judgments close to those that it would have made about others. We call the trust in a given situation the trust context. For example, recommending trustworthiness happens in the context of trusting the recommendation of a recommender. Intuitively, recommendations must only be accepted from senders the local entity trusts to make judgments close to those that it would have made about others. For our discussion in the remainder of this chapter, we define reputation as follows:
Reputation is the subjective aggregated value, as perceived by the requester, of the assessments by other people, who are not exactly identified, of some quality, character, characteristic or ability of a specific entity with whom the requester has never interacted with previously.
To be able to perceive the reputation of an entity is only one aspect of reputation management. The other aspects of reputation management for an entity consist of the following:
• Monitoring the entity reputation as broadly as possible in a proactive way
• Analyzing the sources spreading the entity reputation
• Influencing the number and content of these sources to spread an improved reputation
Therefore, reputation management involves some marketing and public relations actions. Reputation management may be applied to different types of entities: personal reputation management, which is also called “personal branding,”14 or business reputation management. It is now common for businesses to employ full-time staff to influence the company’s reputation via the traditional media channels. Politicians and stars also make use of public relations services. For individuals, in the past few years media have become available to easily retrieve information, but as more and more people use the Web and leave digital traces, it now becomes possible to find information about any Web user via Google. For example, in a recent survey of 100 executive recruiters,15 77% of these executive recruiters declared that they use search engines to learn more about candidates.
2. Reputation Applied to the Computing World
Trust engines, based on computational models of the human notion of trust, have been proposed to make security decisions on behalf of their owners. For example, the EU-funded SECURE project16 has built a generic and reusable trust engine that each computing entity would run. These trust engines allow the entities to compute levels of trust based on sources of trust evidence, that is, knowledge about the interacting entities: local observations of interaction outcomes or recommendations. Based on the computed trust value and given a trust policy, the trust engine can decide to grant or deny access to a requesting entity. Then, if access is given to an entity, the actions of the granted entity are monitored and the outcomes, positive or negative, are used to refine the trust value. The computed trust value represents the interpersonal trust part and is generally defined as follows:
• A trust value is an unenforceable estimate of the entity’s future behavior in a given context based on past evidence.
• A trust metric consists of the different computations and communications carried out by the trustor (and her network) to compute a trust value in the trustee.
Figure 41.2 depicts the high-level view of a computational trust engine called when:
• A requested entity has to decide what action should be taken due to a request made by another entity, the requesting entity
• The decision has been decided by the requested entity
• Evidence about the actions and the outcomes is reported
• The trustor has to select a trustee among several potential trustees

Figure 41.2 High-level view of a computational trust engine.
A number of subcomponents are used for the preceding cases:
• A component that is able to recognize the context, especially to recognize the involved entities. Depending on the confidence level in recognition of the involved entities, for example, the face has only been recognized with 82% of confidence, which may impact the overall trust decision. Context information may also consist of the time, the location, and the activity of the user.17
• Another component that can dynamically compute the trust value, that is, the trustworthiness of the requesting entity based on pieces of evidence (for example, direct observations, recommendations or reputation).
• A risk module that can dynamically evaluate the risk involved in the interaction based on the recognized context. Risk evidence is also needed.
The chosen decision should maintain the appropriate cost/benefit ratio. In the background, another component is in charge of gathering and tracking evidence: recommendations and comparisons between expected outcomes of the chosen actions and real outcomes. This evidence is used to update risk and trust information. Thus, trust and risk follow a managed life cycle.
Depending on dispositional trust and system trust, the weight of the trust value in the final decision may be small. The level of dispositional trust may be set due to two main facts. First, the user manually sets a general level of trust, which is used in the application to get the level of trust in entities, independently of the entities. Second, the current balance of gains and losses is very positive and the risk policy allows any new interactions as long as the balance is kept positive. Marsh uses the term basic trust18 for dispositional trust; it may also be called self-trust.
Generally, as introduced by Rahman and Hailes,19 there are two main contexts for the trust values: direct, which is about the properties of the trustee, and recommend, which is the equivalent of recommending trustworthiness. In their case, recommending trustworthiness is based on consistency on the “semantic distance” between the real outcomes and the recommendations that have been made. The default metric for consistency is the standard deviation based on the frequency of specific semantic distance values: the higher the consistency, the smaller the standard deviation and the higher the trust value in recommending trustworthiness.
As said previously, another source for trust in human networks consists of real-world recourse mechanisms such as insurance or legal actions. Traditionally, it is assumed that if the actions made by a computing entity are bound to a real-world identity, the owner of the faulty computing entity can be brought to court and reparations are possible. In an open environment with no unique authority, the feasibility of this approach is questionable. An example where prosecution is ineffective occurs when email spammers do not mind moving operations abroad where antispam laws are less developed, to escape any risk of prosecution. It is a fact that worldwide there are multiple jurisdictions. Therefore, security based on authenticated identity may be superfluous. Furthermore, there is the question of which authority is in charge of certifying the binding with the real-world identity, since there are no unique global authorities. “Who, after all, can authenticate U.S. citizens abroad? The UN? Or thousands of pair wise national cross-certifications?”20
More important, is authentication of the real-world identity necessary to be able to use the human notion of trust? Indeed, a critical element for the use of trust is to retrieve trust evidence on the interacting entities, but trust evidence does not necessarily consist of information about the real-world identity of the owner; it may simply be the count of positive interactions with a pseudonym, as defended in21. As long as the interacting computing entities can be recognized, direct observations and recommendations can be exchanged to build trust, interaction after interaction. This level of trust can be used for trusting decisions. Thus, trust engines can provide dynamic protection without the assumption that real-world recourse mechanisms, such as legal recourse, are available in case of harm.
The terms trust/trusted/trustworthy, which appear in the traditional computer science literature, are not grounded on social science and often correspond to an implicit element of trust. For example, we have already mentioned the use of trusted third parties, called CAs, which are common in PKIs. Another example is trusted computing,22 the goal of which is to create enhanced hardware by using cost-effective security hardware (more or less comparable to a smart-card chip) that acts as the “root of trust.” They are trusted means that they are assumed to make use of some (strong) security protection mechanisms. Therefore they can/must implicitly be blindly trusted and cannot fail. This cannot address security when it is not known who or whether or not to blindly trust. The term trust management has been introduced in computer security by Blaze et al.,23 but others have argued that their model still relies on an implicit notion of trust because it only describes “a way of exploiting established trust relationships for distributed security policy management without determining how these relationships are formed.”24 There is a need for trust formation mechanisms from scratch between two strangers. Trust engines build trust explicitly based on evidence either personal, reported by known recommenders or through reputation mechanisms.
As said previously, reputation is different than a recommendation made by a known specific entity. However, in the digital world, it is still less easy to exactly certify the identity of the recommender and in many cases the recommender can only be recognized to some extent. The entity recognition occurs with the help of a context recognition module, and the level of confidence in recognition may be taken into account in the final trust computation—for example, as done in advanced computational trust engines.25 In the remainder of this chapter, for simplicity’s sake (since this chapter focuses on reputation rather than trust), we assume that each entity can be recognized with a perfect confidence level in recognition. Thus, we obtain the two layers depicted in Figure 41.3: the identity management layer and the reputation management layer. In these layers, although we mention the world identity, we do not mean that the real-world identity behind each entity is supposed to be certified; we assume that it is sufficient to recognize the entity at a perfect level of confidence in recognition—for example, if a recommendation is received from an eBay account, it is sure that it comes from this account and that it is not spoofed. There are different round-edged rectangles at the top of the reputation layer that represent a few of the different reputation services detailed later in the chapter. There are also a number of round-edged rectangles below the identity layer that represent the various types of authentication schemes that can be used to recognize an entity. Although password-based or OpenID26-based27 authentication may be less secure than multimodal authentication combining biometrics, smart cards, and crypto-certificates,28 since we assume that the level of confidence in recognition is perfect, as stated previously, the different identity management technologies are abstracted to a unique identity management layer for the remainder of the chapter.

Figure 41.3 Identity management and reputation management layers.
As presented previously, reputation management goes beyond mere reputation assessment and encompasses monitoring, analysis, and influence of reputation sources. It is the reason that we introduce the following categories, depicted in Figure 41.4, for online reputation services:
• Reputation calculation. Based on evidence gathered by the service, the service either computes a value representing the reputation of a specific entity or simply presents the reputation information without ranking.
• Reputation monitoring, analysis, and warnings. The service monitors Web-based media (Web sites, blogs, social networks, digitalized archived of paper-based press and trademarks) to detect any information impacting the entity reputation and warns the user in case of important changes.
• Reputation influencing, promotion, and rewards. The service takes actions to influence the perceived reputation of the entity. The service actively promotes the entity reputation, for example, by publishing Web pages carefully designed to reach a high rank in major search engines or paid online advertisements, such as, Google AdWords. Users reaching a higher reputation may gain other rewards than promotion, such as discounts. Based on the monitoring services analysis, the service may be able to list the most important reputation sources and allow the users to influence these sources. For example, in a 2006 blog bribe case, it was reported that free laptops preloaded with a new commercial operating system were shipped for free to the most important bloggers in the field of consumer-oriented software, to improve the reputation of the new operating software.
• Interaction facilitation and follow-up. The service provides an environment to facilitate the interaction and its outcome between the trustor and the trustee. For example, eBay provides an online auction system to sellers and buyers as well as monitors the follow-up of the commercial transaction between the buyer and the seller.
• Reputation certification and assurance. That type of service is closer to the notion of system trust than the human notion of reputation because it relies on external means to avoid ending up in a harmful situation. For example, an insurance is paid as part of a commercial transaction. These services might need the certification of the link between the entity and its real-world identity in case of prosecutions. Our assumption does not hold for the services that require that kind of link, but that category of services had to be covered because a few services we surveyed make use of them.
• Fraud protection, mediation, cleaning, and recovery. These promotion services aim at improving the ranking of reputation information provided by the user rather than external information provided by third parties. However, even if external information is hidden behind more controlled information, it can still be found. It is the reason that some services try to force the owners of the external sites hosting damaging reputation information to delete the damaging information. Depending on where the server is located, this goal is more or less difficult to achieve. It may be as simple as filling an online form on the site hosting the defaming information to contact the technical support employee who will check to see whether the information is really problematic. In the case of a reluctant administrator, lawyers or mediators specialized in online defamation laws have to be commissioned, which is more or less easy depending on the legislation in the country hosting the server. Generally, in countries with clear defamation laws, the administrators prefer deleting the information rather than going into a lengthy and costly legal process. Depending on the mediation and the degree of defamation, the host may have to add an apology in place of the defaming information, pay a fine, or more. Fraud protection is also needed against reputation calculation attacks. There are different types of attacks that can be carried out to flaw reputation calculation results.29 The art of attack-resistant reputation computation is covered later in the chapter.

Figure 41.4 Online reputation management services categories.
3. State of the Art of Attack-Resistant Reputation Computation
In most commercial reputation services surveyed in this chapter, the reputation calculation does not take into account the attack resistance of its algorithm. This is a pity because there are many different types of attacks that can be carried out, especially at the identity level. In addition, most of these reputation algorithms correspond more to a trust metric algorithm rather than reputation as we have defined it earlier in the chapter, because they aggregate ratings submitted by recommenders or the rater itself rather than rely on evidence for which recommenders are unknown. Based on these ratings that we can consider as either direct observations or recommendations, the services compute a reputation score that we can consider a trust value, generally represented on a scale from 0% to 100% or from 0 to 5 stars. The exact reputation computation algorithm is not publicly disclosed by all services providers, and it is difficult to estimate the attack resistance of each of these algorithms without their full specification. However, it is clear that many of these algorithms do not provide a high level of attack-resistance for the following reasons:
• Besides eBay, where each transaction corresponds to a very clear trust context with quite well-authenticated users and a real transaction that is confirmed by real money transfers, most services occur in a decentralized environment and allow for the rating of unconfirmed transactions (without any real evidence that the transaction really happened, and even worse, by anonymous users).
• Still, eBay experiences difficulties with its reputation calculation algorithm. In fact, eBay has recently changed its reputation calculation algorithm: the sellers on eBay are no longer allowed to leave unfavorable or neutral messages about buyers, to diminish the risk that buyers fear leaving negative feedback due to retaliatory negative feedback from sellers. Finally, accounts on eBay that are protected by passwords may be usurped. According to Twigg and Dimmock,30 a trust metric is γ-resistant if more than γ nodes must be compromised for the attacker to successfully drive the trust value. For example, the Rahman and Hailes’31 trust metric is not γ-resistant for γ>1 (a successful attack needs only one victim).
In contrast to the centralized environment of eBay, in decentralized settings there are a number of specific attacks. First, real-world identities may form an alliance and use their recommendation to undermine the reputation of entities. On one hand, this may be seen as collusion. On the other hand, one may argue that real-world identities are free to vote as they wish. However, the impact is greater online. Even if more and more transactions and interactions are traced online, the majority of transactions and interactions that happen in the real world are not reported online. Due to the limited number of traced transactions and interactions, a few faked transactions and interactions can have a high impact on the computed reputation, which is not fair.
Second, we focus here on attacks based on vulnerabilities in the identity approach and subsequent use of these vulnerabilities. The vulnerabilities may have different origins, for example, technical weaknesses in the authentication mechanism. These attacks commonly rely on the possibility of identity multiplicity, meaning that a real-world identity uses many digital pseudonyms. A very well-known identity multiplicity attack in the field of computational trust is Douceur’s Sybil attack.32 Douceur argues that in large-scale networks where a centralized identity authority cannot be used to control the creation of pseudonyms, a powerful real-world entity may create as many digital pseudonyms as it likes and recommend one of these pseudonyms to fool the reputation calculation algorithm. This is especially important in scenarios where the possibility to use many pseudonyms is facilitated—for example, in scenarios where pseudonym creation is provided for better privacy protection.
In his Ph. D. thesis, Levien33 says that a trust metric is attack resistant if the number of faked pseudonyms, owned by the same real-world identity and that can be introduced, is bounded. Levien argues that to mitigate the problem of Sybil-like attacks, it is required to compute “a trust value for all the nodes in the graph at once, rather than calculating independently the trust value independently for each node.” Another approach proposed to protect against the Sybil attack is the use of mandatory “entry fees”34 associated with the creation of each pseudonym. This approach raises some issues about its feasibility in a fully decentralized way and the choice of the minimal fee that guarantees protection. Also, “more generally, the optimal fee will often exclude some players yet still be insufficient to deter the wealthiest players from defecting.”35
An alternative to entry fees may be the use of once-in-a-lifetime (1L36) pseudonyms, whereby an elected party per “arena” of application is responsible to certify only 1L to any real-world entity that possesses a key pair bound to this entity’s real-world identity. The technique of blind signature37 is used to keep the link between the real-world identity and its chosen pseudonym in the arena unknown to the elected party. However, there are still two unresolved questions about this approach: how the elected party is chosen and how much the users would agree to pay for this approach. More important, a Sybil attack is possible during the voting phase, so the concept of electing a trusted entity to stop Sybil attacks does not seem practical. However, relying on real money turns the trust mechanism into a type of system trust where the use of reputation becomes almost superfluous. In the real world, tax authorities are likely to require traceability of money transfers, which would completely break privacy. Thus, when using pseudonyms, another means must be present to prevent users from taking advantage of the fact that they can create as many pseudonyms as they want.
Trust transfer38 has been introduced to encourage self-recommendations without attacks based on the creation and use of a large number of pseudonyms owned by the same real-world identity. In a system where there are pseudonyms that can potentially belong to the same real-world entity, a transitive trust process is open to abuse. Even if there is a high recommendation discounting factor due to recommending trustworthiness, the real-world entity can diminish the impact of this discounting factor by sending a huge number of recommendations from his army of pseudonyms in a Sybil attack. When someone recommends another person, she has influence over the potential outcome of interaction between this person and the trustor. The inclination of the trustor with regard to this influence “provides a goal-oriented sense of control to attain desirable outcomes.”39 So, the trustor should also be able to increase or decrease the influence of the recommenders according to his goals.
Moreover, according to Romano, trust is not multiple constructs that vary in meaning across contexts but a single construct that varies in level across contexts. The overall trustworthiness depends on the complete set of different domains of trustworthiness. This overall trustworthiness must be put in context: It is not sufficient to strictly limit the domain of trustworthiness to the current trust context and the trustee; if recommenders are involved, the decision and the outcome should impact their overall trustworthiness according to the influence they had. Kinateder et al.40 also take the position that there is a dependence between different trust contexts. For example, a chef known to have both won cooking awards and murdered people may not be a trustworthy chef after all. Trust transfer introduces the possibility of a dependence between trustworthiness and recommending trustworthiness. Trust transfer relies on the following assumptions:
• The trust value is based on direct observations or recommendations of the count of event outcomes from recognized entities (for example, the outcome of an eBay auction transaction with a specific seller from a specific buyer recognized by their eBay account pseudos).
• A pseudonym can be neither compromised nor spoofed; an attacker can neither take control of a pseudonym nor send spoofed recommendations; however, everyone is free to introduce as many pseudonyms as they wish.
Trust transfer implies that recommendations cause trust on the trustor (T) side to be transferred from the recommender (R) to the subject (S) of the recommendation. A second effect is that the trust on the recommender side for the subject is reduced by the amount of transferred trustworthiness. If it is a self-recommendation, that is, recommendations from pseudonyms belonging to the same real-world identity, then the second effect is moot, since it does not make sense for a real-world entity to reduce trust in his own pseudonyms. Even if there are different trust contexts (such as trustworthiness in delivering on time or recommending trustworthiness), each trust context has its impact on the single construct trust value: they cannot be taken separately for the calculation of the single construct trust value. A transfer of trust is carried out if the exchange of communications depicted is successful. A local entity’s Recommender Search Policy (RSP) dictates which contacts can be used as potential recommenders. Its Recommendation Policy (RP) decides which of its contacts it is willing to recommend to other entities and how much trust it is willing to transfer to an entity. Trust transfer (in its simplest form) can be decomposed into five steps:
1. The subject requests an action, requiring a total amount of trustworthiness TA in the subject, in order for the request to be accepted by the trustor; the actual value of TA is contingent upon the risk acceptable to the user, as well as dispositional trust and the context of the request; so the risk module of the trust engine plays a role in the calculation of TA.
2. The trustor queries its contacts, which pass the RSP, in order to find recommenders willing to transfer some of their positive event outcomes count to the subject. Recall that trustworthiness is based on event outcomes count in trust transfer.
3. If the contact has directly interacted with the subject and the contact’s RP allows it to permit the trustor to transfer an amount (A≤TA) of the recommender’s trustworthiness to the subject, the contact agrees to recommend the subject. It queries the subject whether it agrees to lose A of trustworthiness on the recommender side.
4. The subject returns a signed statement, indicating whether it agrees or not.
5. The recommender sends back a signed recommendation to the trustor, indicating the trust value it is prepared to transfer to the subject. This message includes the signed agreement of the subject.
Both the RSP and RP can be as simple or complex as the application environment demands. The trust transfer process is illustrated in Figures 41.5, where the subject requests an action that requires 10 positive outcomes. We represent the trust value as a tree of (s,i,c)-triples, corresponding to a mathematical event structure41: an event outcome count is represented as a (s,i,c)-triple, where s is the number of events that supports the outcome, i is the number of events that have no information or are inconclusive about the outcome, and c is the number of events that contradict the expected outcome. This format takes into account the element of uncertainty via i.


Figure 41.5 (a) Trust transfer process; (b) trust transfer process example.
The RSP of the trustor is to query a contact to propose to transfer trust if the balance (s-i-c) is strictly greater than 2TA. This is because it is sensible to require that the recommender remains more trustworthy than the subject after the recommendation. The contact, having a balance passing the RSP (s-i-c = 32-0-2 = 30), is asked by the trustor whether she wants to recommend 10 good outcomes. The contact’s RP is to agree to the transfer if the subject has a trust value greater than TA. The balance of the subject on the recommender’s side is greater than 10 (s-i-c = 22-2-2 = 18). The subject is asked by the recommender whether she agrees 10 good outcomes to be transferred. Trustor T reduces its trust in recommender R by 10 and increases its trust in subject S by 10. Finally, the recommender reduces her trust in the subject by 10.
The recommender could make requests to a number of recommenders until the total amount of trust value is reached (the search requests to find the recommenders are not represented in the figures). For instance, in the previous example, two different recommenders could be contacted, with one recommending three good outcomes and the other one seven.
A recommender chain in trust transfer is not explicitly known to the trustor. The trustor only needs to know his contacts who agree to transfer some of their trustworthiness. This is useful from a privacy point of view since the full chain of recommenders is not disclosed. This is in contrast to other recommender chains such as a public key web of trust.42 Because we assume that the entities cannot be compromised, we leave the issue surrounding the independence of recommender chains in order to increase the attack resistance of the trust metric for future work. The reason for searching more than one path is that it decreases the chance of a faulty path (either due to malicious intermediaries or unreliable ones). If the full list of recommenders must be detailed to be able to check the independence of recommender chains, the privacy protection is lost. This can be an application-specific design decision.
Thanks to trust transfer, although a real-world identity has many pseudonyms, the Sybil attack cannot happen because the number of direct observations (and hence, total amount of trust) remains the same on the trustor side. One may argue that it is unfair for the recommender to lose the same amount of trustworthiness as specified in his/her recommendation, moreover if the outcome is ultimately good. It is envisaged that a more complex sequence of messages can be put in place in order to revise the decrease of trustworthiness after a successful outcome. This has been left for future work, because it can lead to vulnerabilities (for example, based on Sybil attacks with careful cost/benefit analysis). The current trust transfer approach is still limited to scenarios where there are many interactions between the recommenders and where the overall trustworthiness in the network (that is, the global number of good outcomes) is large enough that there is no major impact to entities when they agree to transfer some of their trust (such as in the email application domain43). Ultimately, without sacrificing the flexibility and privacy enhancing potential of limitless pseudonym creation, Sybil attacks are guaranteed to be avoided.
4. Overview of Current Online Reputation Service
As explained previously, most of the current online reputation services surveyed in this part of the chapter do not really compute reputation as we defined it earlier in the chapter. Their reputation algorithms correspond more to a trust metric because they aggregate direct observations and recommendations of different users rather than base their assessment on evidence from a group of an unknown number of unknown users. However, one may consider that these services present reputations to their users if we assume that their users do not take the time to understand how it was computed and who made the recommendations.
The remainder of this part of the chapter starts by surveying the current online reputation services and finishes with a recapitulating table. If not mentioned otherwise, the reputation services do not require the users to pay a fee.
eBay
Founded in 1995, eBay has been a very successful online auction marketplace where buyers can search for products offered by sellers and buy them either directly or after an auction. After each transaction, the buyers can rate the transaction with the seller as positive, negative, or neutral. Since May 2008, sellers have only the choice to rate the buyer experience as positive, nothing else. Short comments of a maximum of 80 characters can be left with the rating. User reputation is based on the number of positive and negative ratings that are aggregated in the Feedback Score as well as the comments. Buyers or sellers can affect each other’s Feedback Scores by only one point per week. Each positive rating counts for 1 point and each negative counts for -1 point. The balance of points is calculated at the end of the week and the Feedback Score is increased by 1 if the balance is positive or decreased by 1 if the balance is negative. Buyers can also leave anonymous Detailed Seller Ratings. composed of various criteria such as “Item as described,” “Communication,” and “Shipping Time,” displayed as a number of stars from 0 to 5. Different image icons are also displayed to quickly estimate the reputation of the user—for example, a star whose color depends on the Feedback Score, as depicted in Figure 41.6. After 90 days, detailed item information is removed.

Figure 41.6 eBay’s visual reputation representation.
From a privacy point of view, on one hand it is possible to use a pseudonym; on the other hand, a pretty exhaustive list of what has been bought is available, which is quite a privacy concern. There are various auction Insertion and Final Value fees depending on the item type. eBay addresses the reputation service categories as follows:
• Reputation calculation. As detailed, reputation is computed based on transactions that are quite well tracked, which is important to avoid faked evidence. However, eBay’s reputation calculation still has some problems. For example, as explained, the algorithm had to be changed recently; the value of the transaction is not taken into account at time of Feedback Score update (a good transaction of 10 Euros should count less than a good transaction of 10 kEuros); it is limited to the ecommerce application domain.
• Monitoring, analysis, and warnings. eBay does not monitor the reputation of its users outside of its service.
• Influencing, promotion, and rewards. eBay rewards its users through their public Feedback Scores and their associated icon images. However, eBay does not promote the user reputation outside its system and does not facilitate this promotion due to a strict access to its full evidence pool, although some Feedback Score data can be accessed through eBay software developer Application Programming Interface (API).
• Interaction facilitation and follow-up. eBay provides a comprehensive Web-based site to facilitate online auctions between buyers and sellers, including a dedicated messaging service and advanced tools to manage the auction. The follow-up based on the Feedback Score is pretty detailed.
• Reputation certification and assurance. eBay does not certify a user reputation per se but, given its leading position, eBay Feedback Score can be considered, to some extent, as some certified reputation evidence.
• Fraud protection, mediation, cleaning, and recovery. eBay facilitates communication between the buyer and the seller as well as a dispute console with eBay customer support employees. A rating and comment cannot be deleted since the Mutual Feedback Withdrawal has been removed. In extreme cases, if the buyer had paid through PayPal, which is now part of eBay, the item might be refunded after some time if the item is covered and depending on the item price. Finally, eBay works with a number of escrow services that act as third parties and that do not deliver the product until the payment is made. Again, if such third-party services are used, the use of reputation is less useful because these third-party services decrease a lot the risk of a negative outcome. eBay does not offer to clean a reputation outside its own Web site.
Opinity
Founded in 2004, Opinity44 has been one of the first commercial efforts to build a decentralized online reputation for users in all contexts beyond eBay’s limited ecommerce context (see Figure 41.7). However, at time of writing (March 2009), Opinity has been inactive for quite a while. After creating an account, the users had the possibility to specify their login and passwords of other Web sites, especially eBay, to retrieve and consolidate all evidence in the user’s Opinity account. Of course, asking users to provide their passwords was risky and seems not a good security practice. Another, safer option was for the users to put hidden text in the HTML pages of their external services, such as eBay. Opinity was quite advanced at the identity layer, since it supported OpenID and Microsoft Cardspace. In addition, Opinity could retrieve professional or education background and verify it to some extent using public listings or for a fee. Opinity users could rate other users in different contexts, such as plumbing or humor. Opinity addressed the different reputation service categories as follows:
• Reputation calculation. The reputation was calculated based on all the evidence sources and could be accessed by other Opinity partner sites. The reputation could be focused to a specific context called a reputation category.
• Monitoring, analysis, and warnings. Opinity did not really cover this category of services; most evidence was pointed out by the users as they added the external accounts that they owned.
• Influencing, promotion, and rewards. Opinity had a base Opinity Reputation Score, and it was possible to include a Web badge representation of that reputation on external Web sites.
• Interaction facilitation and follow-up. Opinity did not really cover this category of services besides the fact that users could mutually decide to disclose more details of their profiles via the Exchange Profile feature.
• Reputation certification and assurance. Opinity certified educational, personal, or professional information to some extent via public listings or for a fee to check the information provided by the users.
• Fraud protection, mediation, cleaning, and recovery. One of Opinity’s relevant features in this category is its reputation algorithm. However, it is not known how strongly this algorithm was resistant to attacks, for example, against a user who creates many Opinity accounts and uses them to give high ratings to a main account. Another relevant feature was that users could appeal bad reviews via a formal dispute process. Opinity did not offer to clean the reputation outside its own Web site.
Figure 41.7 Opinity OpenID support.
Rapleaf
Founded in 2006, Rapleaf45 builds reputations around email addresses. Any Rapleaf user is able to rate any other email address, which may be open to defamation or other privacy issues because the users behind the email addresses may not have given their consent. If the email address to be rated has never been rated before, Rapleaf informs the potential rater that it has started crawling the Web to search for information about that email address and that once the crawling is finished, it will invite the rater to add a rating. As depicted in Figure 41.8, different contexts are possible: Buyers, Sellers, Swappers, and Friends. Once a rating is entered, it cannot be removed. However, new comments are possible and users can rate an email address several times.

Figure 41.8 Rapleaf rating interface.
Online social networks are also crawled, and any external profile linked to the search email address are added to the Rapleaf profile. The email address owners may also add the other email addresses that they own to their profile to provide a unified view of their reputation. Rapleaf’s investors are also involved in two other related services: Upscoop.com, which allows users to import their list of social network friends after disclosing their online social networks passwords (a risky practice, as already mentioned) and see in which other social networks their friends are subscribed (at time of writing Upscoop already has information about over 400 million profiles), and TrustFuse.com, a business that retrieves profile information for marketing businesses that submit their lists of email addresses to TrustFuse. Officially, Rapleaf will not sell its base of email addresses. However, according to its August 2007 policy, “information captured via Rapleaf may be used to assist TrustFuse services. Additionally, information collected by TrustFuse during the course of its business may also be displayed on Rapleaf for given profiles searched by email address,” which is quite worrisome from a privacy point of view. Rapleaf has addressed the different reputation service categories as follows:
• Reputation calculation. The Rapleaf Score takes into account ratings evidence in all contexts as well as how the users have rated others and their social network connections. Unfortunately, the algorithm is not public and thus its attack resistance is unknown. In contrast to eBay, the commercial transactions reported in Rapleaf are not substantiated by other facts than the rater rating information. Thus, the chance of faked transactions is higher. Apparently, a user may rate an email address several times. However, a user rating counts only once in the overall reputation of the target email address.
• Monitoring, analysis, and warnings. Rapleaf warns the target email address when a new rating is added.
• Influencing, promotion, and rewards. The Rapleaf Score can be embedded in a Web badge and displayed on external Web pages.
• Interaction facilitation and follow-up. At least it is possible for the target email address to be warned of a rating and to rate the rater back.
• Reputation certification and assurance. There is no real feature in this category.
• Fraud protection, mediation, cleaning, and recovery. There is a form that allows the owner of a particular email address to remove that email address from Rapleaf. For more important issues, such as defamation, a support email address is provided. Rapleaf does not offer to clean the reputation outside its own Web site.
Venyo
Founded in 2006, Venyo46 provides a worldwide people reputation index, called the Vindex, based on either direct ratings through the user profile on Venyo Web site or indirect ratings through contributions or profiles on partner Web sites (see Figure 41.9). Venyo is privacy friendly because it does not ask users for their external passwords and it does not crawl the Web to present a user reputation without a user’s initial consent. Venyo has addressed the different reputation service categories as follows:
• Reputation calculation. Venyo’s reputation algorithm is not public and therefore its attack resistance is unknown. At time of rating, the rater specifies a value between 1 and 5 as well as keywords corresponding to the tags contextualizing the rating. The rating is also contextualized according to where the rating has been done. For example, if the rating is done from a GaultMillau restaurant blog article, the tag “restaurant recommendation” is automatically added to the list of tags.
• Monitoring, analysis, and warnings. Venyo provides a reputation history chart, as depicted, to help users monitor the evolution of their reputation on Venyo’s and partner’s Web sites. Venyo does not monitor external Web pages or information.
• Influencing, promotion, and rewards. The Vindex allows users to search for the most reputable users in different domains specified by tags and it can be tailored to specific locations. In addition, the Venyo Web badge can be embedded in external Web sites. There is also a Facebook plug-in to port Venyo reputation into a Facebook profile.
• Interaction facilitation and follow-up. The Vindex facilitates finding the most reputable user for the request context.
• Reputation certification and assurance. There is no Venyo feature in this category yet.
• Fraud protection, mediation, cleaning, and recovery. As mentioned, Venyo’s reputation algorithm attack resistance cannot be assessed because Venyo’s algorithm is not public. The cleaning feature is less relevant because the users do not know who has rated them. An account may be closed if the user requests it. As noted, Venyo is more privacy friendly than other services that request passwords or display reputation without their consent.

Figure 41.9 Venyo reputation user interface.
TrustPlus + Xing + ZoomInfo + SageFire
Founded in 1999, ZoomInfo is more a people (and company) search directory than a reputation service. However, ZoomInfo, with its 42 million-plus users, 3.8 million companies, and partnership with Xing.com (a business social network similar to LinkedIn.com), has recently formed an alliance with Trustplus,47 an online reputation service founded in 2006. The main initial feature of TrustPlus is a Web browser plug-in that allows users to see the TrustPlus reputation of an online profile appearing on Web pages on different sites, such as, craiglist.org. At the identity layer, TrustPlus asks users to type their external accounts passwords, for example, eBay’s or Facebook’s, to validate that they own these external accounts as well as to create their list of contacts. This list of contacts can be used to specify who among the contacts can see the detail of which transactions or ratings.
As depicted in Figure 41.10, the TrustPlus rating user interface is pretty complex. There are different contexts: a commercial transaction, a relationship, and an interaction, for example, a chat or a date.

Figure 41.10 TrustPlus Rating User Interface.
The TrustPlus score is also pretty complex, as depicted in Figure 41.11. Thanks to its partnership with SageFire, which is a trusted eBay Certified Solution Provider that has access to historical archives of eBay reputation data, TrustPlus is able to display and use eBay’s reputation evidence when users agree to link their TrustPlus accounts with their eBay accounts. TrustPlus has addressed the different reputation service categories as follows:
• Reputation calculation. The TrustPlus reputation algorithm combines the different sources of reputation evidence reported to TrustPlus by its users and partner sites. However, the TrustPlus reputation algorithm is not public and thus again it is difficult to assess its attack resistance. At time of rating a commercial transaction, it is possible to specify the amount involved in the transaction, which is interesting from a computational trust point of view. Unfortunately, the risk that this transaction is faked is higher than in eBay because there are no other real facts that corroborate the information given by the rating user.
• Monitoring, analysis, and warnings. TrustPlus warns the user when a new rating has been entered or a new request for rating has been added. However, there is no broader monitoring of the global reputation of the user.
• Influencing, promotion, and rewards. TrustPlus provides different tools to propagate the user reputation: a Web badge that may include the eBay reputation, visibility once the TrustPlus Web browser plug-in viewer has been installed, and link with the ZoomInfo directory.
• Interaction facilitation and follow-up. TrustPlus provides an internal messaging service that increases the tracking quality of the interactions between the rated users and the raters.
• Reputation certification and assurance. No reputation certification is done by TrustPlus per se, but the certification is a bit more formal when the users have chosen the option to link their eBay reputation evidence.
• Fraud protection, mediation, cleaning, and recovery. As noted, the attack resistance of the TrustPlus reputation algorithm is unknown. In case of defamation or rating disputes, a Dispute Rating button is available in the Explore Reputation part of the TrustPlus site. When a dispute is initiated, the users have to provide substantiating evidence to the TrustPlus support employees via email. TrustPlus does not offer to clean the reputation outside its own Web site.
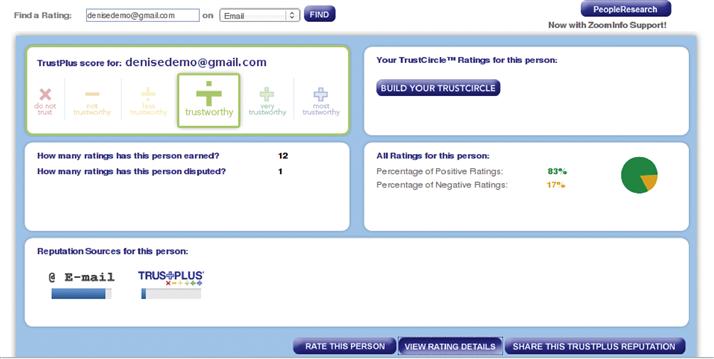
Figure 41.11 The TrustPlus score.
Naymz + Trufina
Founded in 2006, Naymz48 has formed an alliance with Trufina.com, which is in charge of certifying identity and background user information. Premium features cost $9.95 per month at time of writing. The users are asked for their passwords on external sites such as LinkedIn to invite their list of contacts on these external sites, which is a bad security practice, as we’ve mentioned several times. Unfortunately, it seems that Naymz has been too aggressive concerning its emails policy and a number of users have complained about receiving unsolicited emails from Naymz—for example, “I have been spammed several times over the past several weeks by a service called Naymz.”49Naymz has addressed the different reputation service categories as follows:
• Reputation calculation. Naymz RepScore combines a surprising set of information—not only the ratings given by other users but also points for the user profile completeness and identity verifications from Trufina. Each rating is qualitative and focused on the professional contexts of the target user (“Would you like to work on a team with the user?”), as depicted in Figure 41.12. The answers can be changed at any time. Only users who are part of the target user list of contacts are allowed to rate the user. There is no specific transaction-based rating, for example, for an ecommerce transaction.
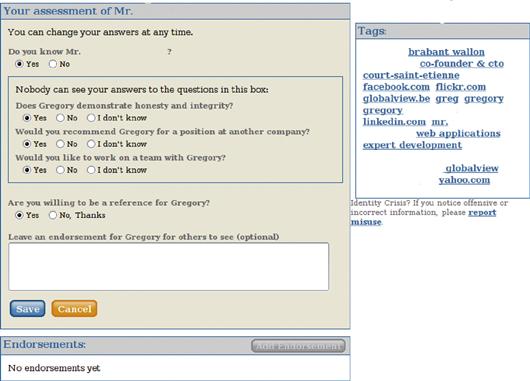
Figure 41.12 Reputation calculation on Naymz.
• Monitoring, analysis, and warnings. Naymz has many monitoring features for both inside and outside Naymz reputation evidence. There is a free list of Web sources (Web sites, forum, blogs) that mention the user’s name. A premium monitoring tool allows the user to see on a worldwide map who has accessed the user Naymz profile, including the visitor’s IP address. It is possible to subscribe to other profiles, recent Web activities if they are part of the user’s confirmed contacts.
• Influencing, promotion, and rewards. In addition to the RepScore and Web badges, the users can get ranking in Web search engines for a fee or for free if they maintain a RepScore higher than 9. The users can also get other features for free if they maintain a certain level of RepScore—for example, free detailed monitoring above 10. For a fee of $1995 at this writing, they also propose to shoot and produce high-quality, professional videos, to improve the user “personal brand.”
• Interaction facilitation and follow-up. It is possible to search for users based on keywords but the search options and index are not advanced at this writing.
• Reputation certification and assurance. As said above, Trufina is in charge of certifying identity and background user information.
• Fraud protection, mediation, cleaning, and recovery. There are links to report offensive or defaming information to the support employees. The attack resistance of the RepScore cannot be assessed because the algorithm detail is not public. They have also launched a new service called Naymz Reputation Repair whereby a user can indicate the location of external Web pages that contain embarrassing information as well as some information regarding the issues, and after analysis Naymz may offer to take action to remove the embarrassing information for a fee.
The GORB
Founded in 2006, The GORB50 allows anybody to rate any email address anonymously. Users can create an account to be allowed to display their GORB score with a Web badge and be notified of their and others’ reputation evolution. The GORB is very strict regarding their rule of anonymity: Users are not allowed to know who has rated them (see Figure 41.13). The GORB has addressed the different reputation service categories as follows:
• Reputation calculation. The GORB argues that, although they only use anonymous ratings, their reputation algorithm is attack resistant, but it is impossible to assess because it is not public. Apparently, they allow a user to rate an email address several times, but they warn that multiple ratings may decrease the GORB score of the rater. The rating has two contexts on a 0 to 10 scale, as depicted in personal and professional. Keywords called tags can be added to the rating as well as a textual comment.
• Monitoring, analysis, and warnings. The users can be notified by email when their reputation evolves or when the reputation of user-defined email addresses evolve. However, it does not monitor evidence outside The GORB.
• Influencing, promotion, and rewards. A Web browser plug-in can be installed to visualize the reputation of email addresses appearing on Web pages in the Web browser. There is a ranking of the users based on the GORB score.
• Interaction facilitation and follow-up. There is no follow-up because the ratings are anonymous.
• Reputation certification and assurance. There is no feature in this category.
• Fraud protection, mediation, cleaning, and recovery. The GORB does not allow users to remove their email address from their list of emails. The GORB asks for user passwords to import email addresses from the list of contacts of other Web sites. Thus, one may argue that The GORB, even if the ratings are anonymous, is not very privacy friendly.

Figure 41.13 The GORB rating user interface.
ReputationDefender
Founded in 2006, ReputationDefender51 has the following products at this writing:
• MyReputation and MyPrivacy, which crawl the Web to find reputation information about users for $9.95 a month and allow them to ask for the deletion of embarrassing information for $39.95 per item.
• MyChild, which does the same but for $9.95 a month and per child.
• MyEdge, starting from $99 to $499, allows the user with the help of automated and professional copywriters to improve her online presence—for example, in search engines such as Google and with third-person biographies written by professional copywriters.
ReputationDefender has addressed the different reputation service categories as follows:
• Reputation calculation. There is no feature in this category.
• Monitoring, analysis, and warnings. As noted, the whole Web is crawled and synthetic online reports are provided.
• Influencing, promotion, and rewards. The user reputation may be improved based on expert advice and better positioned in Web search engines.
• Interaction facilitation and follow-up. There is no feature in this category.
• Reputation certification and assurance. There is no feature in this category.
• Fraud protection, mediation, cleaning, and recovery. There is no reputation algorithm. Cleaning may involve automated software or real people specialized in legal reputation issues.
Summarizing Table
Table 41.1 summarizes how well each current online reputation service surveyed in this chapter addresses each reputation service category.
Table 41.1
Table Summarization
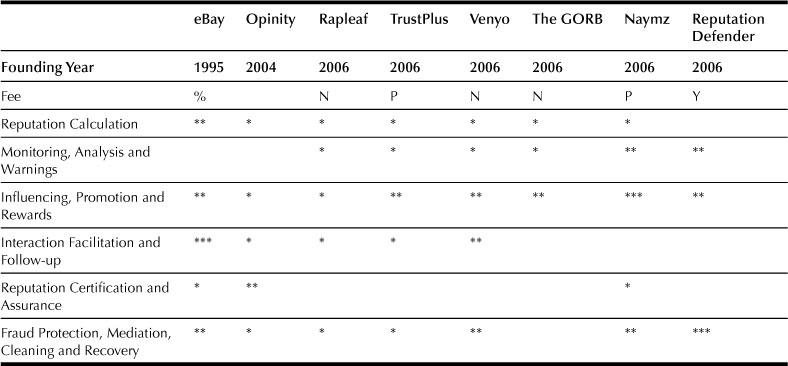
%: transaction percentage fee, P: premium services fee, N: No fee, Y: paid service
5. Conclusion
Online reputation management is an emerging complementary field of computer security whose traditional security mechanisms are challenged by the openness of the World Wide Web, where there is no a priori information of who is allowed to do what. Technical issues remain to be overcome: the attack resistance of the reputation algorithm is not mature yet; it is difficult to represent in a consistent way reputation built from different contexts (ecommerce, friendship). Sustainable business models are still to be found: Opinity seems to have gone out of business; Rapleaf had to move from a reputation service to a privacy-risky business of email address profiling; TrustPlus had to form an alliance with ZoomInfo, Xing, and SageFire; Naymz decreased its own reputation by spamming its base of users in hope of increasing its traffic.
It seems that both current technical and commercial issues may be improved by a standardization effort of online reputation management. The attack resistance of reputation algorithms cannot be certified to the degree it deserves if the reputation algorithms remain private. It has been proven in other security domains that security through obscurity gives lower results—for example, concerning cryptographic algorithms that are now open to review by the whole security research community. Open reputation algorithms will also improve the credibility of the reputation results because it will be possible to clearly explain to users how the reputation has been calculated. Standardizing the representation of reputation will also diminish confusion in the eyes of the users. The clearer understanding of which reputation evidence is taken into account in reputation calculation will improve the situation regarding privacy and will open the door to stronger regulation on the way in which reputation information flows.
1C. Ellison, and B. Schneier, “Ten risks of PKI: What you’re not being told about Public Key Infrastructure”, Computer Security Journal, Winter (2000).
2R. Housley, and T. Polk, Planning for PKI: Best Practices Guide for Deploying Public Key Infrastructure, Wiley (2001).
3P. Resnick, R. Zeckhauser, J. Swanson, and K. Lockwood, The Value of Reputation on eBay: A Controlled Experiment, Division of Research, Harvard Business School (2003).
4M. Bouvier, “Maxims of law,” Law Dictionary (1856).
5K. Kuwabara, “Reputation: Signals or incentives?” In The Annual Meeting of the American Sociological Association (2003).
6M. Bouvier, “Maxims of law,” Law Dictionary (1856).
7Original quotation in French: La confiance ne nous laisse pas tant de liberté, ses règles sont plus étroites, elle demande plus de prudence et de retenue, et nous ne sommes pas toujours libres d’en disposer: il ne s’agit pas de nous uniquement, et nos intérêts sont mêlés d’ordinaire avec les intérêts des autres. Elle a besoin d’une grande justesse pour ne livrer pas nos amis en nous livrant nous-mêmes, et pour ne faire pas des présents de leur bien dans la vue d’augmenter le prix de ce que nous donnons.
8B. Franklin, The Life and Letters of Benjamin Franklin., G. M. Hale & Co., 1940.ca
9S. R. Covey, The seven habits of highly effective people (1989).
10J. Seigneur, J. Abendroth, and C. D. Jensen, “Bank accounting and ubiquitous brokering of trustos” (2002) 7th Cabernet Radicals Workshop.
11D. M. Romano, The Nature of Trust: Conceptual and Operational Clarification (2003).
12D. M. Romano, The Nature of Trust: Conceptual and Operational Clarification (2003).
13D. H. McKnight, and N. L. Chervany, “What is trust? A conceptual analysis and an interdisciplinary model,” In The Americas conference on information systems (2000).
14T. Peters, “The brand called you,” Fast Company (1997).
15Execunet, www.execunet.com.
16J. M. Seigneur, Trust, Security and Privacy in Global Computing (2005).
17A. K. Dey, “Understanding and using context”, Personal and Ubiquitous Computing Journal (2001).
18S. Marsh, Formalizing Trust as a Computational Concept (1994).
19A. Rahman, and S. Hailes, Using Recommendations for Managing Trust in Distributed Systems (1997).
20R. Khare, What’s in a Name? Trust (1999).
21J. M. Seigneur, Trust, Security and Privacy in Global Computing (2005).
22Trusted Computing Group, https://www.trustedcomputinggroup.org.
23M. Blaze, J. Feigenbaum, and J. Lacy, “Decentralized trust management,” In The 17th ieeE Symposium on Security and Privacy (1996).
24S. Terzis, W. Wagealla, C. English, A. McGettrick, and P. Nixon, The SECURE Collaboration Model (2004).
25J. M. Seigneur, Trust, Security and Privacy in Global Computing (2005).
26Refer to Chapter 17 of this book on identity management to learn more about OpenID.
27OpenID, http://openid.net/.
28J. M. Seigneur, Trust, Security and Privacy in Global Computing (2005).
29J. M. Seigneur, Trust, Security and Privacy in Global Computing (2005).
30A. Twigg, and N. Dimmock, “Attack-resistance of computational trust models” (2003) Proceedings of the Twelfth International Workshop on Enabling Technologies: Infrastructure for Collaborative Enterprises.
31A. Rahman, and S. Hailes, Using Recommendations for Managing Trust in Distributed Systems (1997).
32J. R. Douceur, “The sybil attack”, Proceedings of the 1st International Workshop on Peer-to-Peer Systems (2002).
33R. Levien, Attack Resistant Trust Metrics (2004).
34E. Friedman, and P. Resnick, The Social Cost of Cheap Pseudonyms (2001): pp. 173–199.
35E. Friedman, and P. Resnick, The Social Cost of Cheap Pseudonyms (2001): pp. 173–199.
36E. Friedman, and P. Resnick, The Social Cost of Cheap Pseudonyms (2001): pp. 173–199.
37D. Chaum, “Achieving Electronic Privacy”, Scientific American (1992): pp. 96–100.
38J. M. Seigneur, Trust, Security and Privacy in Global Computing (2005).
39D. M. Romano, The Nature of Trust: Conceptual and Operational Clarification (2003).
40M. Kinateder, and K. Rothermel, “Architecture and Algorithms for a Distributed Reputation System”, Proceedings of the First Conference on Trust Management (2003).
41M. Nielsen, G. Plotkin, and G. Winskel, “Petri nets, event structures and domains,” Theoritical Computer Science (1981): pp. 85–108.
42P. R. Zimmermann, The Official PGP User’s Guide (1995).
43J. M. Seigneur, Trust, Security and Privacy in Global Computing (2005).
44Opinity, www.opinity.com.
45Rapleaf, www.rapleaf.com.
46Venyo, www.venyo.org.
47Trustplus, www.trustplus.com.
48Naymz, www.naymz.com.
49www.igotspam.com/50226711/naymz_sending_spamas_you.php, accessed 16 July 2008.
50The GORB, www.thegorb.com.
51ReputationDefender, www.reputationdefender.com.