
Intrusion Prevention and Detection Systems
Christopher Day, Terremark Worldwide, Inc.
With the increasing importance of information systems in today’s complex and global economy, it has become mission and business critical to defend those information systems from attack and compromise by any number of adversaries. Intrusion prevention and detection systems are critical components in the defender’s arsenal and take on a number of different forms. Formally, intrusion detection systems (IDSs) can be defined as “software or hardware systems that automate the process of monitoring the events occurring in a computer system or network, analyzing them for signs of security problems.”1 Intrusion prevention systems (IPSs) are systems that attempt to actually stop an active attack or security problem. Though there are many IDS and IPS products on the market today, often sold as self-contained, network-attached computer appliances, truly effective intrusion detection and prevention are achieved when viewed as a process coupled with layers of appropriate technologies and products. In this chapter, we will discuss the nature of computer system intrusions, those who commit these attacks, and the various technologies that can be utilized to detect and prevent them.
1. What is an “Intrusion,” Anyway?
Information security concerns itself with the confidentiality, integrity, and availability of information systems and the information or data they contain and process. An intrusion, then, is any action taken by an adversary that has a negative impact on the confidentiality, integrity, or availability of that information.
Given such a broad definition of “intrusion,” it is instructive to examine a number of commonly occurring classes of information system (IS) intrusions.
Physical Theft
Having physical access to a computer system allows an adversary to bypass most security protections put in place to prevent unauthorized access. By stealing a computer system, the adversary has all the physical access he could want, and unless the sensitive data on the system is encrypted, the data is very likely to be compromised. This issue is most prevalent with laptop loss and theft. Given the processing and storage capacity of even low-cost laptops today, a great deal of sensitive information can be put at risk if a laptop containing this data is stolen. In May 2006, for example, it was revealed that over 26 million military veterans’ personal information, including names, Social Security numbers, addresses, and some disability data, was on a Veteran Affairs staffer’s laptop that was stolen from his home.2 The stolen data was of the type that is often used to commit identity theft, and due to the large number of impacted veterans, there was a great deal of concern about this theft and the lack of security around such a sensitive collection of data.
Abuse of Privileges (The Insider Threat)
An insider is an individual who, due to her role in the organization, has some level of authorized access to the IS environment and systems. The level of access can range from that of a regular user to a systems administrator with nearly unlimited privileges. When an insider abuses her privileges, the impact can be devastating. Even a relatively limited-privilege user is already starting with an advantage over an outsider due to that user’s knowledge of the IS environment, critical business processes, and potential knowledge of security weaknesses or soft spots. An insider may use her access to steal sensitive data such as customer databases, trade secrets, national security secrets, or personally identifiable information (PII), as discussed in the sidebar, “A Definition of Personally Identifiable Information.” Because she is a trusted user, and given that many IDSs are designed to monitor for attacks from outsiders, an insider’s privileged abuse can go on for a long time unnoticed, thus compounding the damage. An appropriately privileged user may also use her access to make unauthorized modifications to systems, which can undermine the security of the environment. These changes can range from creating “backdoor” accounts to preserving access in the event of termination to installing so-called logic bombs, which are programs designed to cause damage to systems or data at some predetermined point in time, often as a form of retribution for some real or perceived slight.
2. Unauthorized Access by an Outsider
An outsider is considered anyone who does not have authorized access privileges to an information system or environment. To gain access, the outsider may try to gain possession of valid system credentials via social engineering or even by guessing username and password pairs in a brute-force attack. Alternatively, the outsider may attempt to exploit a vulnerability in the target system to gain access. Often the result of successfully exploiting a system vulnerability leads to some form of high-privileged access to the target, such as an Administrator or Administrator-equivalent account on a Microsoft Windows system or a root or root-equivalent account on a Unix- or Linux-based system. Once an outsider has this level of access on a system, he effectively “owns” that system and can steal data or use the system as a launching point to attack other systems.
3. Malware Infection
Malware (see sidebar, “Classifying Malware”) can be generally defined as “a set of instructions that run on your computer and make your system do something that allows an attacker to make it do what he wants it to do.”3 Historically, malware in the form of viruses and worms was more a disruptive nuisance than a real threat, but it has been evolving as the weapon of choice for many attackers due to the increased sophistication, stealthiness, and scalability of intrusion-focused malware. Today we see malware being used by intruders to gain access to systems, search for valuable data such as PII and passwords, monitor real-time communications, provide remote access/control, and automatically attack other systems, just to name a few capabilities. Using malware as an attack method also provides the attacker with a “stand-off” capability that reduces the risk of identification, pursuit, and prosecution. By “stand-off” we mean the ability to launch the malware via a number of anonymous methods such as an insecure, open public wireless access point. Once the malware has gained access to the intended target or targets, the attacker can manage the malware via a distributed command and control system such as Internet Relay Chat (IRC). Not only does the command and control network help mask the location and identity of the attacker, it also provides a scalable way to manage many compromised systems at once, maximizing the results for the attacker. In some cases the number of controlled machines can be astronomical, such as with the Storm worm infection, which, depending on the estimate, ranged somewhere between 1 million and 10 million compromised systems.4 These large collections of compromised systems are often referred to as botnets.
4. The Role of the “0-Day”
The Holy Grail for vulnerability researchers and exploit writers is to discover a previously unknown and exploitable vulnerability, often referred to as a 0-day exploit (pronounced zero day or oh day). Given that the vulnerability has not been discovered by others, all systems running the vulnerable code will be unpatched and possible targets for attack and compromise. The danger of a given 0-day is a function of how widespread the vulnerable software is and what level of access it gives the attacker. For example, a reliable 0-day for something as widespread as the ubiquitous Apache Web server that somehow yields root- or Administrator-level access to the attacker is far more dangerous and valuable than an exploit that works against an obscure point-of-sale system used by only a few hundred users (unless the attacker’s target is that very set of users).
In addition to potentially having a large, vulnerable target set to exploit, the owner of a 0-day has the advantage that most intrusion detection and prevention systems will not trigger on the exploit for the very fact that it has never been seen before and the various IDS/IPS technologies will not have signature patterns for the exploit yet. We will discuss this issue in more detail later.
It is this combination of many unpatched targets and the ability to potentially evade many forms of intrusion detection and prevention systems that make 0-days such a powerful weapon in the hands of attackers. Many legitimate security and vulnerability researchers explore software systems to uncover 0-days and report them to the appropriate software vendor in the hopes of preventing malicious individuals from finding and using them first. Those who intend to use 0-days for illicit purposes guard the knowledge of a 0-day very carefully lest it become widely and publically known and effective countermeasures, including vendor software patches, can be deployed.
One of the more disturbing issues regarding 0-days is their lifetimes. The lifetime of a 0-day is the amount of time between the discovery of the vulnerability and public disclosure through vendor or researcher announcement, mailing lists, and so on. By the very nature of 0-day discovery and disclosure it is difficult to get reliable statistics on lifetimes, but one vulnerability research organization claims their studies indicate an average 0-day lifetime of 348 days.6 Hence, if malicious attackers have a high-value 0-day in hand, they may have almost a year to put it to most effective use. If used in a stealthy manner so as not to tip off system defenders, vendors, and researchers, this sort of 0-day can yield many high-value compromised systems for the attackers. Though there has been no official substantiation, there has been a great deal of speculation that the Titan Rain series of attacks against sensitive U.S. government networks between 2003 and 2005 utilized a set of 0-days against Microsoft software.7,8
5. The Rogue’s Gallery: Attackers and Motives
Now that we have examined some of the more common forms computer system intrusions take, it is worthwhile to discuss the people who are behind these attacks and attempt to understand their motivations. The appropriate selection of intrusion detection and prevention technologies is dependent on the threat being defended against, the class of adversary, and the value of the asset being protected.
Though it is always risky to generalize, those who attack computer systems for illicit purposes can be placed into a number of broad categories. At minimum this gives us a “capability spectrum” of attackers to begin to understand motivations and, therefore, threats:
• Script kiddy. The pejorative term script kiddy is used to describe those who have little or no skill at writing or understanding how vulnerabilities are discovered and exploits are written, but download and utilize others’ exploits, available on the Internet, to attack vulnerable systems. Typically, script kiddies are not a threat to a well-managed, patched environment since they are usually relegated to using publicly known and available exploits for which patches and detection signatures already exist.
• Joy rider. This type of attacker is often represented by people with potentially significant skills in discovering vulnerabilities and writing exploits but who rarely have any real malicious intent when they access systems they are not authorized to access. In a sense they are “exploring” for the pleasure of it. However, though their intentions are not directly malicious, their actions can represent a major source of distraction and cost to system administrators, who must respond to the intrusion anyway, especially if the compromised system contained sensitive data such as PII where a public disclosure may be required.
• Mercenary. Since the late 1990s there has been a growing market for those who possess the skills to compromise computer systems and are willing to sell them from organizations willing to purchase these skills.9 Organized crime is a large consumer of these services. Computer crime has seen a significant increase in both frequency and severity over the last decade, primarily driven by direct, illicit financial gain and identity theft.10 In fact, so successful have these groups become that a full-blown market has emerged, including support organizations offering technical support for rented botnets and online trading environments for the exchange of stolen credit card data and PII. Stolen data has a tangible financial value, as shown in Table 18.1, which indicates the dollar-value ranges for various types of PII.
Table 18.1
PII Values
| Goods and Services | Percentage | Range of Prices |
| Financial Accounts | 22% | $10–$1,000 |
| Credit Card Information | 13% | $.40–$20 |
| Identity Information | 9% | $1–$15 |
| eBay Accounts | 7% | $1–$8 |
| Scams | 7% | $2.5–$50/week for hosting, $25 for design |
| Mailers | 6% | $1–$10 |
| Email Addresses | 5% | $.83–$10/MB |
| Email Passwords | 5% | $4–$30 |
| Drop (request or offer) | 5% | 10%–50% of drop amount |
| Proxies | 5% | $1.50–$30 |
(Compiled from Miami Electronic Crimes Task Force and Symantec Global Internet Security Threat Report (2008))
• Nation-state backed. Nations performing espionage against other nations do not ignore the potential for intelligence gathering via information technology systems. Sometimes this espionage takes the form of malware injection and system compromises such as the previously mentioned Titan Rain attack; other times it can take the form of electronic data interception of unencrypted email and other messaging protocols. A number of nations have developed or are developing an information warfare capability designed to impair or incapacitate an enemy’s Internet-connected systems, command-and-control systems, and other information technology capability.11 These sorts of capabilities were demonstrated in 2007 against Estonia, allegedly by Russian sympathizers utilizing a sustained series of denial-of-service attacks designed to make certain Web sites unreachable as well as to interfere with online activities such as email and mission-critical systems such as telephone exchanges.12
6. A Brief Introduction to TCP/IP
Throughout the history of computing, there have been numerous networking protocols, the structured rules computers use to communicate with each other, but none have been as successful and become as ubiquitous as the Transmission Control Protocol/Internet Protocol (TCP/IP) suite of protocols. TCP/IP is the protocol suite used on the Internet, and the vast majority of enterprise and government networks have now implemented TCP/IP on their networks. Due to this ubiquity almost all attacks against computer systems today are designed to be launched over a TCPI/IP network, and thus the majority of intrusion detection and prevention systems are designed to operate with and monitor TCP/IP-based networks. Therefore, to better understand the nature of these technologies it is important to have a working knowledge of TCP/IP. Though a complete description of TCP/IP is beyond the scope of this chapter, there are numerous excellent references and tutorials for those interested in learning more.13,14
Three features that have made TCP/IP so popular and widespread are15:
• Open protocol standards that are freely available. This and independence from any particular operating system or computing hardware means that TCP/IP can be deployed on nearly any computing device imaginable.
• Hardware, transmission media, and device independence. TCP/IP can operate over numerous physical devices and network types such as Ethernet, Token Ring, optical, radio, and satellite.
• A consistent and globally scalable addressing scheme. This ensures that any two uniquely addressed network nodes can communicate with each other (notwithstanding any traffic restrictions implemented for security or policy reasons), even if those nodes are on different sides of the planet.
7. The TCP/IP Data Architecture and Data Encapsulation
The best way to describe and visualize the TCP/IP protocol suite is to think of it as a layered stack of functions, as in Figure 18.1.
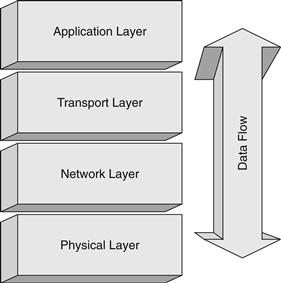
Figure 18.1 TCP/IP data architecture stack.
Each layer is responsible for a set of services and capabilities provided to the layers above and below it. This layered model allows developers and engineers to modularize the functionality in a given layer and minimize the impacts of changes on other layers. Each layer performs a series of functions on data as it is prepared for network transport or received from the network. The way those functions are performed internal to a given layer is hidden from the other layers, and as long as the agreed rules and standards are adhered to with regard to how data is passed from layer to layer, the inner workings of a given layer are isolated from any other layer.
The Application Layer is concerned with applications and processes, including those with which users interact, such as browsers, email, instant messaging, and other network-aware programs. There can also be numerous applications in the Application Layer running on a computer system that interact with the network, but users have little interaction with such as routing protocols.
The Transport Layer is responsible for handling data flow between applications on different hosts on the network. There are two Transport protocols in the TCP/IP suite: the Transport Control Protocol (TCP) and the User Datagram Protocol (UDP). TCP is a connection- or session-oriented protocol that provides a number of services to the application, such as reliable delivery via Positive Acknowledgment with Retransmission (PAR), packet sequencing to account for out-of-sequence receipt of packets, receive buffer management, and error detection. In contrast, UDP is a low-overhead, connectionless protocol that provides no delivery acknowledgment or other session services. Any necessary application reliability must be built into the application, whereas with TCP, the application need not worry about the details of packet delivery. Each protocol serves a specific purpose and allows maximum flexibility to application developers and engineers. There may be numerous network services running on a computer system, each built on either TCP or UDP (or, in some cases, both), so both protocols utilize the concept of ports to identify a specific network service and direct data appropriately. For example, a computer may be running a Web server, and standard Web services are offered on TCP port 80. That same computer could also be running an email system utilizing the Simple Mail Transport Protocol (SMTP), which is by standard offered on TCP port 25. Finally, this server may also be running a Domain Name Service (DNS) server on both TCP and UDP port 53. As can be seen, the concept of ports allows multiple TCP and UDP services to be run on the same computer system without interfering with each other.
The Network Layer is primarily responsible for packet addressing and routing through the network. The Internet Protocol (IP) manages this process within the TCP/IP protocol suite. One very important construct found in IP is the concept of an IP address. Each system running on a TCP/IP network must have at least one unique address for other computer systems to direct traffic to it. An IP address is represented by a 32-bit number, which is usually represented as four integers ranging from 0 to 255 separated by decimals, such as 192.168.1.254. This representation is often referred to as a dotted quad. The IP address actually contains two pieces of information: the network address and the node address. To know where the network address ends and the node address begins, a subnet mask is used to indicate the number of bits in the IP address assigned to the network address and is usually designated as a slash and a number, such as /24. If the example address of 192.168.1.254 has a subnet mask of /24, we know that the network address is 24 bits, or 192.168.1, and the node address is 254. If we were presented with a subnet mask of /16, we would know that the network address is 192.168 while the node address is 1.254. Subnet masking allows network designers to construct subnets of various sizes, ranging from two nodes (a subnet mask of /30) to literally millions of nodes (a subnet of /8) or anything in between. The topic of subnetting and its impact on addressing and routing is a complex one, and the interested reader is referred to16 for more detail.
The Physical Layer is responsible for interaction with the physical network medium. Depending on the specifics of the medium, this can include functions such as collision avoidance, the transmission and reception of packets or datagrams, basic error checking, and so on. The Physical Layer handles all the details of interfacing with the network medium and isolates the upper layers from the physical details.
Another important concept in TCP/IP is that of data encapsulation. Data is passed up and down the stack as it travels from a network-aware program or application in the Application Layer, is packaged for transport across the network by the Transport and Network Layer, and eventually is placed on the transmission medium (copper or fiber-optic cable, radio, satellite, and so on) by the Physical Layer. As data is handed down the stack, each layer adds its own header (a structured collection of fields of data) to the data passed to it by the above layer. Figure 18.2 illustrates three important headers: the IP header, the TCP header, and the UDP header. Note that the various headers are where layer-specific constructs such as IP address and TCP or UDP port numbers are placed, so the appropriate layer can access this information and act onit accordingly.

Figure 18.2 IP, TCP, and UDP headers.
The receiving layer is not concerned with the content of the data passed to it, only that the data is given to it in a way compliant with the protocol rules. The Physical Layer places the completed packet (the full collection of headers and application data) onto the transmission medium for handling by the physical network. When a packet is received, the reverse process occurs. As the packet travels up the stack, each layer removes its respective header, inspects the header content for instructions on which upper layer in the protocol stack to hand the remaining data to, and passes the data to the appropriate layer. This process is repeated until all TCP/IP headers have been removed and the appropriate application is handed the data. The encapsulation process is illustrated in Figure 18.3.
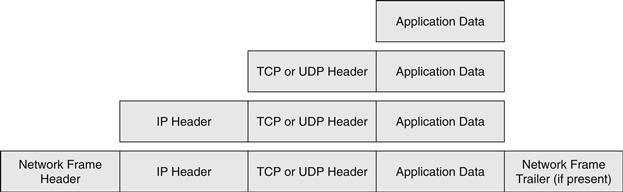
Figure 18.3 TCP/IP encapsulation.
To best illustrate these concepts, let’s explore a somewhat simplified example. Figure 18.4 illustrates the various steps in this example. Assume that a user, Alice, want to send an email to her colleague Bob at CoolCompany.com.
1. Alice launches her email program and types in Bob’s email address, [email protected], as well as her message to Bob. Alice’s email program constructs a properly formatted SMTP-compliant message, resolves Cool Company’s email server address utilizing a DNS query, and passes the message to the TCP component of the Transport Layer for processing.
2. The TCP process adds a TCP header in front of the SMTP message fields including such pertinent information as the source TCP port (randomly chosen as a port number greater than 1024, in this case 1354), the destination port (port 25 for SMTP email), and other TCP-specific information such as sequence numbers and receive buffer sizes.
3. This new data package (SMTP message plus TCP header) is then handed to the Network Layer and an IP header is added with such important information as the source IP address of Alice’s computer, the destination IP address of Cool Company’s email server, and other IP-specific information such as packet lengths, error-detection checksums, and so on.
4. This complete IP packet is then handed to the Physical Layer for transmission onto the physical network medium, which will add network layer headers as appropriate. Numerous packets may be needed to fully transmit the entire email message depending on the various network media and protocols that must be traversed by the packets as they leave Alice’s network and travel the Internet to Cool Company’s email server. The details will be handled by the intermediate systems and any required updates or changes to the packet headers will be made by those systems.
5. When Cool Company’s email server receives the packets from its local network medium via the Physical Layer, it removes the network frame and hands the remaining data to the Network Layer.
6. The Network Layer strips off the IP header and hands the remaining data to the TCP component of the Transport Layer.
7. The TCP process removes and examines the TCP header to, among other tasks, examine the destination port (again, 25 for email) and finally hand the SMTP message to the SMTP server process.
8. The SMTP application performs further application specific processing as well delivery to Bob’s email application by starting the encapsulation process all over again to transit the internal network between Bob’s PC and the server.
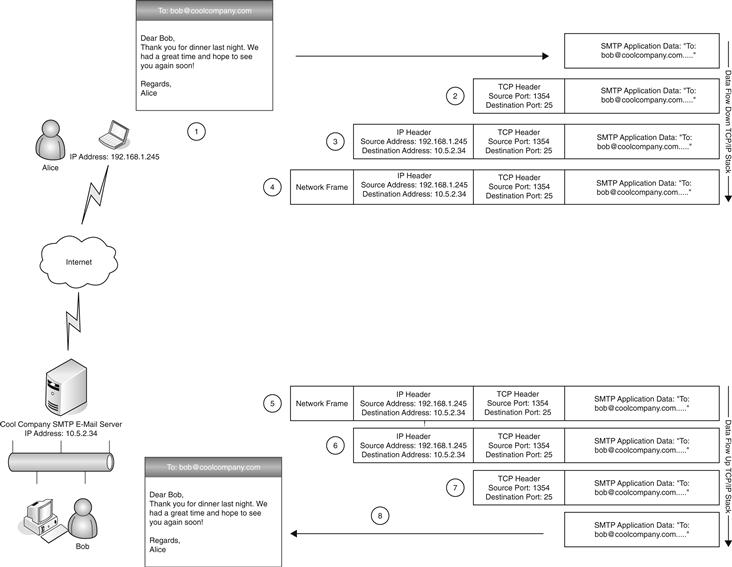
Figure 18.4 Application and network interaction example.
It is important to understand that network-based computer system attacks can occur at every layer of the TCP/IP stack and thus an effective intrusion detection and prevention program must be able to inspect at each layer and act accordingly. Intruders may manipulate any number of fields within a TCP/IP packet to attempt to bypass security processes or systems including the application-specific data, all in an attempt to gain access and control of the target system.
8. Survey of Intrusion Detection and Prevention Technologies
Now that we have discussed the threats to information systems and those who pose them as well as examined the underlying protocol suite in use on the Internet and enterprise networks today, we are prepared to explore the various technologies available to detect and prevent intrusions. It is important to note that though technologies such as firewalls, a robust patching program, and disk and file encryption (see sidebar, “A Definition of Encryption”) can be part of a powerful intrusion prevention program, these are considered static preventative defenses and will not be discussed here. In this part of the chapter, we discuss various dynamic systems and technologies that can assist in the detection and prevention of attacks on information systems.
9. Anti-Malware Software
We have discussed malware and its various forms previously. Anti-malware software (see Figure 18.5), in the past typically referred to as antivirus software, is designed to analyze files and programs for known signatures, or patterns, in the data that make up the file or program and that indicate malicious code is present. This signature scanning is often accomplished in a multitiered approach where the entire hard drive of the computer is scanned sequentially during idle periods and any file accessed is scanned immediately to help prevent dormant code in a file that has not been scanned from becoming active. When an infected file or malicious program is found, it is prevented from running and either quarantined (moved to a location for further inspection by a systems administrator) or simply deleted from the system. There are also appliance-based solutions that can be placed on the network to examine certain classes of traffic such as email before they are delivered to the end systems.
Figure 18.5 Anti-malware file scanning.
In any case, the primary weakness of the signature-based scanning method is that if the software does not have a signature for a particular piece of malware, the malware will be effectively invisible to the software and will be able to run without interference. A signature might not exist because a particular instance of the anti-malware software may not have an up-to-date signature database or the malware may be new or modified so as to avoid detection. To overcome this increasingly common issue, more sophisticated anti-malware software will monitor for known-malicious behavioral patterns instead of, or in addition to, signature-based scanning. Behavioral pattern monitoring can take many forms such as observing the system calls all programs make and identifying patterns of calls that are anomalous or known to be malicious. Another common method is to create a whitelist of allowed known-normal activity and prevent all other activity, or at least prompt the user when a nonwhitelisted activity is attempted. Though these methods overcome some of the limitations of the signature-based model and can help detect previously never seen malware, they come with the price of higher false-positive rates and/or additional administrative burdens.
While anti-malware software can be evaded by new or modified malware, it still serves a useful purpose as a component in a defense-in-depth strategy. A well maintained anti-malware infrastructure will detect and prevent known forms, thus freeing up resources to focus on other threats, but it can also be used to help speed and simplify containment and eradication of a malware infection once an identifying signature can be developed and deployed.
10. Network-based Intrusion Detection Systems
For many years, network-based intrusion detection systems (NIDS) have been the workhorse of information security technology and in many ways have become synonymous with intrusion detection.18 NIDS function in one of three modes: signature detection, anomaly detection, and hybrid.
A signature-based NIDS operates by passively examining all the network traffic flowing past its sensor interface or interfaces and examines the TCP/IP packets for signatures of known attacks, as illustrated in Figure 18.6.

Figure 18.6 NIDS device-scanning packets flowing past a sensor interface.
TCP/IP packet headers are also often inspected to search for nonsensical header field values sometimes used by attackers in an attempt to circumvent filters and monitors. In much the same way that signature-based anti-malware software can be defeated by never-before-seen malware or malware sufficiently modified to no longer possess the signature used for detection, signature-based NIDS will be blind to any attack for which it does not have a signature. Though this can be a very serious limitation, signature-based NIDS are still useful due to most systems’ ability for the operator to add custom signatures to sensors. This allows security and network engineers to rapidly deploy monitoring and alarming capability on their networks in the event they discover an incident or are suspicious about certain activity. Signature-based NIDS are also useful to monitor for known attacks and ensure that none of those are successful at breaching systems, freeing up resources to investigate or monitor other, more serious threats.
NIDS designed to detect anomalies in network traffic build statistical or baseline models for the traffic they monitor and raise an alarm on any traffic that deviates significantly from those models. There are numerous methods for detecting network traffic anomalies, but one of the most common involves checking traffic for compliance with various protocol standards such as TCP/IP for the underlying traffic and application layer protocols such as HTTP for Web traffic, SMTP for email, and so on. Many attacks against applications or the underlying network attempt to cause system malfunctions by violating the protocol standard in ways unanticipated by the system developers and which the targeted protocol-handling layer does not deal with properly. Unfortunately, there are entire classes of attacks that do not violate any protocol standard and thus will not be detected by this model of anomaly detection. Another commonly used model is to build a model for user behavior and to generate an alarm when a user deviates from the “normal” patterns. For example, if Alice never logs into the network after 9:00 p.m. and suddenly a logon attempt is seen from Alice’s account at 3:00 a.m., this would constitute a significant deviation from normal usage patterns and generate an alarm. Some of the main drawbacks of anomaly detection systems are defining the models of what is normal and what is malicious, defining what is a significant enough deviation from the norm to warrant an alarm, and defining a sufficiently comprehensive model or models to cover the immense range of behavioral and traffic patterns that are likely to be seen on any given network. Due to this complexity and the relative immaturity of adaptable, learning anomaly detection technology, there are very few production-quality systems available today. However, due to not relying on static signatures and the potential of a successful implementation of an anomaly detection, NIDS for detecting 0-day attacks and new or custom malware is so tantalizing that much research continues in this space.
A hybrid system takes the best qualities of both signature-based and anomaly detection NIDS and integrates them into a single system to attempt to overcome the weaknesses of both models. Many commercial NIDS now implement a hybrid model by utilizing signature matching due to its speed and flexibility while incorporating some level of anomaly detection to, at minimum, flag suspicious traffic for closer examination by those responsible for monitoring the NIDS alerts.
Aside from the primary criticism of signature-based NIDS their depending on static signatures, common additional criticisms of NIDS are they tend to produce a lot of false alerts either due to imprecise signature construction or poor tuning of the sensor to better match the environment, poor event correlation resulting in many alerts for a related incident, the inability to monitor encrypted network traffic, difficulty dealing with very high-speed networks such as those operating at 10 gigabits per second, and no ability to intervene during a detected attack. This last criticism is one of the driving reasons behind the development of intrusion prevention systems.
11. Network-based Intrusion Prevention Systems
NIDS are designed to passively monitor traffic and raise alarms when suspicious traffic is detected, whereas network-based intrusion prevention systems (NIPS) are designed to go one step further and actually try to prevent the attack from succeeding. This is typically achieved by inserting the NIPS device inline with the traffic it is monitoring. Each network packet is inspected and only passed if it does not trigger some sort of alert based on a signature match or anomaly threshold. Suspicious packets are discarded and an alert is generated.
The ability to intervene and stop known attacks, in contrast to the passive monitoring of NIDS, is the greatest benefit of NIPS. However, NIPS suffers from the same drawbacks and limitations as discussed for NIDS, such as heavy reliance on static signatures, inability to examine encrypted traffic, and difficulties with very high network speeds. In addition, false alarms are much more significant due to the fact that the NIPS may discard that traffic even though it is not really malicious. If the destination system is business or mission critical, this action could have significant negative impact on the functioning of the system. Thus, great care must be taken to tune the NIPS during a training period where there is no packet discard before allowing it to begin blocking any detected, malicious traffic.
12. Host-based Intrusion Prevention Systems
A complementary approach to network-based intrusion prevention is to place the detection and prevention system on the system requiring protection as an installed software package. Host-based intrusion prevention systems (HIPS), though often utilizing some of the same signature-based technology found in NIDS and NIPS, also take advantage of being installed on the protected system to protect by monitoring and analyzing what other processes on the system are doing at a very detailed level. This process monitoring is very similar to that which we discussed in the anti-malware software section and involves observing system calls, interprocess communication, network traffic, and other behavioral patterns for suspicious activity. Another benefit of HIPS is that encrypted network traffic can be analyzed after the decryption process has occurred on the protected system, thus providing an opportunity to detect an attack that would have been hidden from a NIPS or NIDS device monitoring network traffic.
Again, as with NIPS and NIDS, HIPS is only as effective as its signature database, anomaly detection model, or behavioral analysis routines. Also, the presence of HIPS on a protected system does incur processing and system resource utilization overhead and on a very busy system, this overhead may be unacceptable. However, given the unique advantages of HIPS, such as being able to inspect encrypted network traffic, it is often used as a complement to NIPS and NIDS in a targeted fashion and this combination can be very effective.
13. Security Information Management Systems
Modern network environments generate a tremendous amount of security event and log data via firewalls, network routers and switches, NIDS/NIPS, servers, anti-malware systems, and so on. Envisioned as a solution to help manage and analyze all this information, security information management (SIM) systems have since evolved to provide data reduction, to reduce the sheer quantity of information that must analyzed, and event correlation capabilities that assist a security analyst to make sense of it all.19 A SIM system not only acts as a centralized repository for such data, it helps organize it and provides an analyst the ability to do complex queries across this entire database. One of the primary benefits of a SIM system is that data from disparate systems is normalized into a uniform database structure, thus allowing an analyst to investigate suspicious activity or a known incident across different aspects and elements of the IT environment. Often an intrusion will leave various types of “footprints” in the logs of different systems involved in the incident; bringing these all together and providing the complete picture for the analyst or investigator is the job of the SIM.
Even with modern and powerful event correlation engines and data reduction routines, however, a SIM system is only as effective as the analyst examining the output. Fundamentally, SIM systems are a reactive technology, like NIDS, and because extracting useful and actionable information from them often requires a strong understanding of the various systems sending data to the SIM, the analysts’ skill set and experience become very critical to the effectiveness of the SIM as an intrusion detection system.20 SIM systems also play a significant role during incident response because often evidence of an intrusion can be found in the various logs stored on the SIM.
14. Network Session Analysis
Network session data represents a high-level summary of “conversations” occurring between computer systems.21 No specifics about the content of the conversation such as packet payloads are maintained, but various elements about the conversation are kept and can be very useful in investigating an incident or as an indicator of suspicious activity. There are a number of ways to generate and process network session data ranging from vendor-specific implementations such as Cisco’s NetFlow22 to session data reconstruction from full traffic analysis using tools such as Argus.23 However the session data is generated, there are a number of common elements constituting the session, such as source IP address, source port, destination IP address, destination port, time-stamp information, and an array of metrics about the session, such as bytes transferred and packet distribution.
Using the collected session information, an analyst can examine traffic patterns on a network to identify which systems are communicating with each other and identify suspicious sessions that warrant further investigation. For example, a server configured for internal use by users and having no legitimate reason to communicate with addresses on the Internet will cause an alarm to be generated if suddenly a session or sessions appear between the internal server and external addresses. At that point the analyst may suspect a malware infection or other system compromise and investigate further. Numerous other queries can be generated to identify sessions that are abnormal in some way or another such as excessive byte counts, excessive session lifetime, or unexpected ports being utilized. When run over a sufficient timeframe, a baseline for traffic sessions can be established and the analyst can query for sessions that don’t fit the baseline. This sort of investigation is a form of anomaly detection based on high-level network data versus the more granular types discussed for NIDS and NIPS. Figure 18.7 illustrates a visualization of network session data. The pane on the left side indicates one node communicating with many others; the pane on the right is displaying the physical location of many IP addresses of other flows.
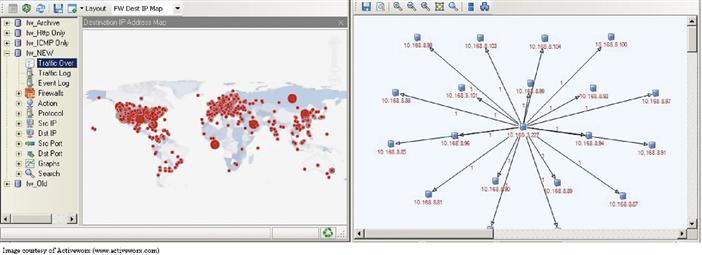
Figure 18.7 Network Session Analysis Visualization Interface.
Another common use of network session analysis is to combine it with the use of a honeypot or honeynet (see sidebar, “Honeypots and Honeynets”). Any network activity, other than known-good maintenance traffic such as patch downloads, seen on these systems is, by definition, suspicious since there are no production business functions or users assigned to these systems. Their sole purpose is to act as a lure for an intruder. By monitoring network sessions to and from these systems, an early warning can be raised without even necessarily needing to perform any complex analysis.
15. Digital Forensics
Digital forensics is the “application of computer science and investigative procedures for a legal purpose involving the analysis of digital evidence.”25 Less formally, digital forensics is the use of specialized tools and techniques to investigate various forms of computer-oriented crime including fraud, illicit use such as child pornography, and many forms of computer intrusions.
Digital forensics as a field can be divided into two subfields: network forensics and host-based forensics. Network forensics focuses on the use of captured network traffic and session information to investigate computer crime. Host-based forensics focuses on the collection and analysis of digital evidence from individual computer systems to investigate computer crime. Digital forensics is a vast topic, and a comprehensive discussion is beyond the scope of this chapter; interested readers are referred to26 for more detail.
In the context of intrusion detection, digital forensic techniques can be utilized to analyze a suspected compromised system in a methodical manner. Forensic investigations are most commonly used when the nature of the intrusion is unclear, such as those perpetrated via a 0-day exploit, but wherein the root cause must be fully understood either to ensure that the exploited vulnerability is properly remediated or to support legal proceedings. Due to the increasing use of sophisticated attack tools and stealthy and customized malware designed to evade detection, forensic investigations are becoming increasingly common, and sometimes only a detailed and methodical investigation will uncover the nature of an intrusion. The specifics of the intrusion may also require a forensic investigation such as those involving the theft of Personally Identifiable Information (PII) in regions covered by one or more data breach disclosure laws.
16. System Integrity Validation
The emergence of powerful and stealthy malware, kernel-level root kits, and so-called clean-state attack frameworks that leave no trace of an intrusion on a computer’s hard drive have given rise to the need for technology that can analyze a running system and its memory and provide a series of metrics regarding the integrity of the system. System integrity validation (SIV) technology is still in its infancy and a very active area of research but primarily focuses on live system memory analysis and the notion of deriving trust from known-good system elements.27 This is achieved by comparing the system’s running state, including the processes, threads, data structures, and modules loaded into memory, to the static elements on disk from which the running state was supposedly loaded. Through a number of cross-validation processes, discrepancies between what is running in memory and what should be running can be identified. When properly implemented, SIV can be a powerful tool for detecting intrusions, even those utilizing advanced techniques.
17. Putting it all Together
It should now be clear that intrusion detection and prevention are not single tools or products but a series of layered technologies coupled with the appropriate methodologies and skill sets. Each of the technologies surveyed in this chapter has its own specific strengths and weaknesses, and a truly effective intrusion detection and prevention program must be designed to play to those strengths and minimize the weaknesses. Combining NIDS and NIPS with network session analysis and a comprehensive SIM, for example, helps offset the inherent weakness of each technology as well as provide the information security team greater flexibility to bring the right tools to bear for an ever-shifting threat environment.
An essential element in a properly designed intrusion detection and prevention program is an assessment of the threats faced by the organization and a valuation of the assets to be protected. There must be an alignment of the value of the information assets to be protected and the costs of the systems put in place to defend them. The program for an environment processing military secrets and needing to defend against a hostile nation state must be far more exhaustive than that for a single server containing no data of any real value that must simply keep out assorted script kiddies.
For many organizations, however, their information systems are business and mission critical enough to warrant considerable thought and planning with regard to the appropriate choices of technologies, how they will be implemented, and how they will be monitored. Only through flexible, layered, and comprehensive intrusion detection and prevention programs can organizations hope to defend their environment against current and future threats to their information security.
1“NIST special publication on intrusion detection systems,” NIST, Washington, D.C., 2006.
2M. Bosworth, “VA loses data on 26 million veterans,” Consumeraffairs.com, www.consumeraffairs.com/news04/2006/05/va_laptop.html, 2006.
3E. Skoudis, Malware: Fighting Malicious Code, Prentice Hall, 2003.
4P. Gutman, “World’s most powerful supercomputer goes online,” Full Disclosure, http://seclists.org/fulldisclosure/2007/Aug/0520.html, 2007.
5P. Gutman, “World’s most powerful supercomputer goes online,” Full Disclosure, http://seclists.org/fulldisclosure/2007/Aug/0520.html, 2007.
6J.Aitel, “The IPO of the 0-day,” www.immunityinc.com/downloads/0day_IPO.pdf, 2007.
7M. H. Sachs, “Cyber-threat analytics,” www.cyber-ta.org/downloads/files/Sachs_Cyber-TA_ThreatOps.ppt, 2006.
8J. Leyden, “Chinese crackers attack US.gov,” The Register, www.theregister.co.uk/2006/10/09/chinese_crackers_attack_us/, 2006.
9P. Williams, “Organized crime and cyber-crime: Implications for business,” www.cert.org/archive/pdf/cybercrime-business.pdf, 2002.
10C. Wilson, “Botnets, cybercrime, and cyberterrorism: Vulnerabilities and policy issues for Congress,” http://fas.org/sgp/crs/terror/RL32114.pdf, 2008.
11M. Graham, “Welcome to cyberwar country, USA,” WIRED, www.wired.com/politics/security/news/2008/02/cyber_command, 2008.
12M. Landler and J. Markoff, “Digital fears emerge after data siege in Estonia,” New York Times, www.nytimes.com/2007/05/29/technology/29estonia.html, 2007.
13R. Stevens, TCP/IP Illustrated, Volume 1: The Protocols, Addison-Wesley Professional, 1994.
14D. E. Comer, Internetworking with TCP/IP Vol. 1: Principles, Protocols, and Architecture, 4th ed., Prentice Hall, 2000.
15C. Hunt, TCP/IP Network Administration, 3rd ed., O’Reilly Media, Inc., 2002.
16R. Stevens, TCP/IP Illustrated, Volume 1: The Protocols, Addison-Wesley Professional, 1994.
17B. Schneier, Applied Cryptography, Wiley, 1996.
18S. Northcutt, Network Intrusion Detection, 3rd ed., Sams, 2002.
19http://en.wikipedia.org/wiki/Security_Information_Management.
20www.schneier.com/blog/archives/2004/10/security_inform.html.
21R. Bejtlich, The Tao of Network Security Monitoring: Beyond Intrusion Detection, Addison-Wesley Professional, 2004.
22Cisco NetFlow, www.cisco.com/web/go/netflow.
23Argus, http://qosient.com/argus/.
25K. Zatyko, “Commentary: Defining digital forensics,” Forensics Magazine, www.forensicmag.com/articles.asp?pid=130, 2007.
26K. Jones, Real Digital Forensics: Computer Security and Incident Response, Addison-Wesley Professional, 2005.