
Multithreading and Concurrency
Our programs so far have been written based on the basic assumption that only one thing is happening at any given time. The instructions in the program execute one after another and control might jump from one method to another, but at any given time you can point to a single line of code and say that is what is happening at that time. This type of sequential processing of instructions is called a thread. Our programs so far have been written to utilize a single thread of execution. Such programs do not take full advantage of modern hardware. In this chapter we will learn how to make our programs use multiple threads. Multithreading can be used to simplify logic in some places, but most of the time we will use it to make our programs run faster.
21.1 The Multicore Future
For many decades after the development of the integrated circuit, computers got consistently faster because of a combination of two factors. The most significant was what is called Moore’s Law. This was a prediction made by Gordon Moore at Intel that the number of transistors that could be etched on a chip would double roughly every two years. This growth was enabled by technological improvements that allowed the transistors to be made at smaller and smaller scales. Associated with this was the ability to push those transistors to higher frequencies.
Figure 21.1 shows clock frequencies, number of transistors, and core counts for x86 processors released by Intel and Advanced Micro Devices (AMD) between 1978 and 2011. The log scales on the vertical axes make it so that exponential growth displays as straight lines. The dotted line shows an exponential fit to the transistor count data. From this you can see that Moore’s Law has held fairly well. Transistor counts have grown exponentially with a doubling time fairly close to the predicted two years.1
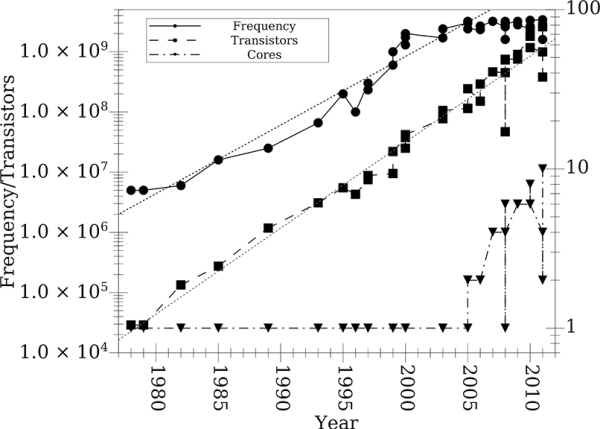
This figure shows frequencies, transistor counts, and core counts for x86 processors produced between 1978 and 2010. The log scale on the plot makes it so that exponential curves appear as straight lines. The dotted lines show fits to the full transistor count data and the frequency data through 2000. Clock speeds shown are the highest release for each chip.
From the beginning of the figure until the 2000-2005 time frame, the clock frequencies of chips grew exponentially as well. The chips available in 1978 and 1979 ran at 5 MHz. By 2000 they had crossed the 1 GHz speed. The dotted line shows an exponential fit for the clock speeds through 2000. As you can see though, clock speeds stalled at a few GHz and have not gone up much since just after 2000. This was a result of problems with heat dissipation. Above these speeds, silicon-based chips need special cooling to keep them running stably.
Much of the speed boost that computers got until 2005 came from increases in clock frequency. When that ended, chip manufactures had to look for an alternate way to improve the speed of chips. After all, no one buys new computers so they can run programs slower than the old one. So beginning in 2005 commodity computer chips started going in a different direction.2 The direction they went is shown by the dash-dot line with triangle points in figure 21.1. Instead of using additional transistors primarily to add complexity to the data paths for single instructions or just adding more cache, chip makers started making chips that had multiple cores.
When a chip has multiple cores, that means that it can be executing more than one instruction at any given time. We normally say that code can be executed in parallel. Unfortunately, a program written in the way we have done so far will not automatically take advantage of multiple cores. Instead, it has to be rewritten so that it will run faster on these newer computers. This is a significant change from what had been happening when processors were getting higher clock speeds. The significance of this change was described in an article titled "The Free Lunch is Over"[11]. The "free lunch" that is referred to is getting more speed from new processors without programmers having to do any work. To take full advantage of newer processors, programs have to be multithreaded. In this chapter we will begin to explore exactly what that means.
21.2 Basic Threads
When you imagine one of your programs running, you can picture the computer moving an arrow from one line to the next. The arrow points to the line that is currently being executed. When you call a function/method, the arrow jumps to that other part of the code, then jumps back when the function/method returns. The term we use for this behavior is a "thread". The programs we have written so far use a single thread of execution. We start this way because it is easier, but the current nature of computer hardware makes it important for you to understand the concept of multiple threads early on.
The idea of a multithreaded program is that you have two or more of those arrows pointing at different lines and moving through the program at the same time. These different threads can be run on different cores, giving us the ability to more completely utilize modern processors. Just like when multiple people cooperate on a task, there has to be some coordination between the individuals to get the maximum benefit. There are also typically limits to how many people can productively work together on a particular task. If you want to dig a small hole you probably can not efficiently use more than two or maybe three people. However, if you want to dig a large trench you can involve hundreds, if not thousands, of people productively. These same limitations can apply to programs.
There are many ways of using threads to produce parallelism in Scala. We will start off with the most basic pieces, the java.lang.Thread class and elements associated with it. This is not how you will likely do most of your parallel programming in Scala, but it provides a good foundation and can show you the basic operations that are being used at the lowest level with all the different options we will look at.
We will start with a reasonably simple example. This is a script that will ask your age and count down from 10 to 1. If you do not answer before the countdown ends, it will terminate without you answering. If you answer, it prints a message based on whether or not you are 18 years of age and stops counting.
val countThread = new Thread {
override def run {
for(i <- 10 to 1 by -1) {
println(i)
Thread.sleep(1000)
}
println("Time’s up.")
sys.exit(0)
}
}
countThread.start()
println("Enter your age.")
val age = readInt()
if(age<18) println("Sorry, you can’t come here.")
else println("Welcome.")
sys.exit(0)
A new thread is created here using new and the type Thread and overriding the run method. You can also make a new Thread and pass it an instance of the Runnable type which must have a run:Unit method defined. In the run method here we place the code that we want the other thread to execute. In this case it has a for loop that counts down from 10 to 1. After each number is printed there is a call to Thread.sleep(1000). The sleep method does what the name implies, it makes the thread pause its execution for a while. The one argument tells it how long to wait in milliseconds. The argument of 1000 here tells this thread to pause for a second between each number that is printed. After the loop, its print time is up and calls sys.exit(0). This call forcibly causes a Scala program to terminate. The 0 is the exit code. By convention, a value of 0 indicates normal termination. Some other value would indicate an error.
Creating a new Thread object does not cause it to start working. For that to happen we have to call the start method. In this case, that is done right after it is defined. This is followed by a few simple lines of code reading input with a conditional print followed by another call to sys.exit. Enter this into a file and run it as a script to see how it works.
The idea behind this script is to demonstrate how two different things can be going on at the same time in a program. One thread is doing a countdown while another is doing some basic input and output to get information from a user. You can almost picture this as two different people doing things, though perhaps in that case the prompt should be printed in the thread code. What this code demonstrates is that the threads, like people, can operate independently. In this case, we are not using it to gain speed, instead we are simply aiming for concurrency.
The use of sys.exit is pretty heavy-handed. It works in this simple example, but it is easy to imagine situations where you do not want to terminate the entire execution of a program. The call to sys.exit in the thread is needed here because readInt is a blocking method that we can not get out of once we call it. The call to sys.exit at the end is needed because of the way we structured the loop in the thread. Let’s try to see how we could get rid of both of these.
We will start with the call at the end of the script because it is easier to deal with. There are two problems involved here. One is that we need some way for the code outside the thread to "talk" to the code inside the thread so that it can know when the user has answered. The second is that the for loop in Scala does not allow you to break out in the middle. If you want to have the possibility of terminating early, you need to use a while loop. The condition in the while loop should say that we keep counting while a counter variable is greater than zero and the user has not answered. This second part tells us how to get the two parts to "talk". We simply introduce a Boolean variable that keeps track of whether the user has answered. The while loop stops if they have. The line after reading the input should change this variable to say they have answered. A possible implementation of this looks like the following.
var answered = false
val countThread = new Thread {
override def run {
var i=10
while(!answered && i>0) {
println(i)
Thread.sleep(1000)
i -= 1
}
if(!answered) {
println("Time’s up.")
sys.exit(0)
}
}
}
countThread.start()
println("Enter your age.")
val age = readInt()
answered = true
if(age<18) println("Sorry, you can’t come here.")
else println("Welcome.")
Enter this code and see that it behaves the same as the earlier version.
This version still contains one call to sys.exit. This one is a little more difficult to get rid of. The problem is that readInt is what we call a blocking method. This is a method that stops the execution of the thread until some certain state is reached. In this case, it blocks until the user has typed in an appropriate input value. That is not acceptable in this situation because we want to make it so that the countdown thread can prevent the read from happening, and more importantly blocking, if it gets to the end before the user enters their value. An approach to this is shown here.
var answered = false
var timeUp = false
val countThread = new Thread {
override def run {
var i=10
while(!answered && i>0) {
println(i)
Thread.sleep(1000)
i -= 1
}
if(!answered) {
println("Time’s up.")
timeUp = true
}
}
}
countThread.start()
println("Enter your age.")
while(!timeUp && !Console.in.ready) {
Thread.sleep(10)
}
if(!timeUp) {
val age = readInt()
answered = true
if(age<18) println("Sorry, you can’t come here.")
else println("Welcome.")
}
This code introduces another mutable Boolean variable that keeps track of whether time has expired. At the end of the countdown this variable is set to be true.
The more interesting part occurs right after the prompt for the users age. Here you find a while loop like this.
while(!timeUp && !Console.in.ready) {
Thread.sleep(10)
}
This loop will stop under one of two conditions, either time must run out, or Console.in must be ready. To understand this second condition requires some digging through the Application Programming Interface. The object scala.Console is what you read from when you do calls like readInt or what you write to when you do println. The input comes through an object called Console.in which is a java.io.BufferedReader. We will talk more about the various classes in java.io in the next chapter, but for now you can know that this type has a method called ready that will tell you when you can read from it without having it block.
Inside the loop is another call to Thread.sleep. This is here simply to prevent the while loop from doing a "busy wait" and making the processor do a lot of extra work for no real reason. It will still check if the user has input something or if time has run out 100 times each second. This is more than sufficient for the type of user interaction that we have here. After the loop the same code from before appears inside an if so that it will not happen if the loop stopped as a result of time running out.
21.2.1 Problems with Threads
This example shows how simple using threads can be. Unfortunately, a lot of that apparent simplicity masks the many problems that can occur when you are using threads. The challenges of multithreading are the reason it is not done unless it is really needed. The two main problems that one runs into are called race conditions and deadlock. We’ll look at each of these in turn.
21.2.1.1 Race Conditions
The term race condition is used to describe a situation where the outcome of a program can depend on the order in which threads get to a different point in a program. Typically, if you run a program with the same inputs, you expect to have the same outputs. This deterministic nature is part of what makes computers so useful in the everyday world. Programmers do not have full control over what threads are running at any given time. You have the ability to do things like make a thread sleep for a period of time, but in a program with many threads, you do not get to explicitly say which ones will be running at any given time. Using the human analogy, you typically do not have the fine-grained control of telling each and every person exactly where to be and what to be doing. If they are digging a trench, you can not say exactly when each shovel will cut into the ground. If you tried to exert such control, it would probably slow things down in the end and defeat the purpose of having many people/threads working on the task.
Simply lacking detailed control does not lead to race conditions. Race conditions happen when you combine that lack of control with a shared mutable state. You are probably aware that most of the time your computer is running many different programs. These different programs are often called processes and they can utilize multiple cores as well. The difference between different processes and different threads is that each process gets its own chunk of memory that it can work with, but threads share access to the same memory. To see how this leads to problems, consider the classic example of a bank account.
/∗∗
∗ A class that represents a bank account. The balance is stored as an Int
∗ representing a number of cents.
∗/
class BankAccout(private var bal:Int = 0) {
def balance:Int = bal
def deposit(amount:Int) {
assert(amount>=0)
val oldBalance = balance
val newBalance = oldBalance+amount
bal = newBalance
}
def withdraw(amount:Int) {
assert(amount>=0 && amount<=bal)
val oldBalance = balance
val newBalance = oldBalance-amount
bal = newBalance
}
}
This code has been written in a long way using local variables instead of using operators like += and -= because this is what the code will really be expanded to when it is compiled and it makes it easier to see where the problem arises.
This is such a simple little class. What could possibly go wrong? To see the answer to that question, imagine that you make a withdrawal at an ATM at the same time as your paycheck is being deposited. Both of these activities read from and write to the bal member of the object that represents your account. The result at the end depends on the exact order in which these things happen. If one of them starts and finishes completely before the other, everything will be fine. The race condition occurs when both start before either finishes. In that situation, the one that executes bal = newBalance last will have its results stored. The other one will have the work that it did wipe out. You might not mind this if your withdrawal is not recorded and you get your money for free. However, you might have a problem with losing a whole month’s salary because you happened to visit the ATM at the wrong time.
In fact, the script that we showed in the last section has the possibility for a race condition because both threads are accessing answered and timeUp with at least one writing to each. Though you could run the script many times and never see this, it is possible to answer the question, get a response, and be told that time is up in one run. To see how, picture the threads as arrows and imagine that you hit Enter at exactly the same time as the last second counts off. So the lines if(!answered) and if(!timeUp) execute at the same time. This means that both values will still be false and the program can get into both of those if statements.
Hopefully you can see how both of those examples could cause problems. However, they both require specific timing for the error to manifest. This does not make them unimportant, it just makes them hard to demonstrate. Indeed, that type of bug is one of the hardest to diagnose and fix because it is so rare and hard to reproduce. If you want to specifically see the problems that occur as a result of race conditions, the following code will do that for you.
var cnt = 0
val threads = Array.fill(100){
new Thread {
override def run {
for(i <- 1 to 1000000) cnt += 1
}
}
}
threads.foreach(_.start)
threads.foreach(_.join)
println(cnt)
This code has a counter that starts at zero and then makes and starts 100 threads that each contain a for loop which counts to one million and as it does so it adds to the counter. At the end, the counter is printed.
Between the start and the print is a line that calls join on all the threads. The join method is designed to block until the thread it is called on finishes. After the thread finishes it continues. If this line were left out of the code, the print statement could, and likely would, happen while there were still threads adding to the counter. The use of join here simply makes sure that all the threads have finished before we do the print.
Just looking at this code it should be clear that we expect the final line to print out 100 million. However, if you run it, you will find that it never does.3 Even if you run it on a machine with only a single core, the final printout will be less than 100 million. That is because on a machine with a single core, threads can not execute at exactly the same time so instead they swap from one to the other.
21.2.1.2 Deadlock
The way to prevent threads from having race conditions when there is a mutable state is to lock critical parts of code so that only one thread can be in those critical sections at a given time. There are also times when you need to have some threads wait for other threads to finish before they move on to further tasks. For example, you probably should not start filling the trench with water until after all the digging is done and everyone has gotten out.
Making it so that one thread can pause and wait for another to finish doing something is critical. However, it can also lead to a situation called deadlock where different threads are waiting on one another and as a result, none of them can proceed. Consider the following example of pseudocode.4
var l1 = new Lock
var l2 = new Lock
def processA {
l1.lock {
do stuff A
l2.lock {
do more stuff A
}
}
}
def processB {
l2.lock {
do stuff B
l1.lock {
do more stuff B
}
}
}
Now imagine that one thread calls processA while a second thread calls processB. As soon as processA starts it, locks l1 and does some work. Similarly, processB will lock l2 then do some work. Before releasing the locks they have, they try to acquire the locks they do not have yet. This can cause a deadlock, because processA can not get the lock for l2 until processB is done and processB can not get the lock for l1 until processA is done. The result is that they sit around waiting for one another forever and the code simply stops.
You might argue that this is a contrived example and that you would never put such alternating locks into real code. In reality though, the inner lock would probably be located in some function/method that is called by the outer lock so it will not be at all obvious that such an alternating lock structure is present in the code.
21.2.2 Synchronization
The first approach to dealing with race conditions is synchronization. When a block of code is synchronized, it means that when that block executes it first checks a monitor on the specified object. If the monitor is unlocked, that thread acquires the lock on the monitor and executes the body. If the monitor is locked by another thread, the thread blocks until the lock is released by that thread. This is done by calling the synchronized method in AnyRef. That method has the following signature.
def synchronized[T](body: => T): T
Note that the body is passed by name and the return type is a parametric type. This makes it so that you can write whatever code you might have normally written as a body after the call to synchronized. The fact that it is defined in AnyRef means that you can call this inside of any class, object, or trait declaration, and you often do not have to specify the object it is being called on. You do have to be careful to keep in mind what object it is being called on though as that will be the object the monitor is locked on and using the wrong one can lead to incorrect results.
As a first example, let us look at how we would fix the bank account class to be synchronized so that we do not have to worry about deposits and withdrawals happening at the same time.
/∗∗
∗ A class that represents a bank account. The balance is stored as an Int
∗ representing a number of cents.
∗/
class BankAccout(private var bal:Int = 0) {
def balance:Int = bal
def deposit(amount:Int) = synchronized {
assert(amount>=0)
val oldBalance = balance
val newBalance = oldBalance+amount
bal = newBalance
}
def withdraw(amount:Int) = synchronized {
assert(amount>=0 && amount<=bal)
val oldBalance = balance
val newBalance = oldBalance-amount
bal = newBalance
}
}
As you see, all we did here was put a call to synchronize around the full method for deposit and withdraw. An equal sign was added because we are no longer using the short syntax for a method that returns Unit. That is all that is required for that example.
You might wonder why it is that synchronization works when the code we wrote before that used an if to check a variable then automatically set it does not. The reason behind this is that the checking and setting of the lock on the monitor is an atomic operation. What does it mean for an operation to be atomic? The Greek root of the word atom means indivisible. The name was given to the particles because it was believed at the time that they were the smallest pieces of matter and could not be split. While that turns out to not really be true of atoms in nature, it is true of atomic operations on a computer. In this alternate sense, when we say it can not be split, we mean it can not be interrupted. Once an atomic operation begins, nothing else can take over before it finishes. The problem with the if followed by a set was that it was not atomic and it was possible for the value of the variable to be changed by another thread between when this thread read the value, looked at it, and set it.
So what about the example that adds to a counter in multiple threads? Given what we have seen, your first attempt might look like this.
var cnt = 0
val threads = Array.fill(100){
new Thread {
override def run {
for(i <- 1 to 1000000) synchronized {cnt += 1}
}
}
}
threads.foreach(_.start)
threads.foreach(_.join)
println(cnt)
This does nothing more than put the increment inside a synchronized block. Unfortunately, this does not work. This is one of those situations where we do have to specify what object is being synchronized on. The fact that we do not specify an object that the method is called on means it is being called on the "current" object. In this case, that is the Thread object that is being created. After all, this happens in the run method of the thread we are making. This is not good enough because each thread has its own monitor so this does not really prevent the different threads from accessing cnt at the same time.
In order to do that, we need to have all the threads synchronize on a single object. The most obvious candidate would be cnt itself. After all, what we want to prevent is having two threads attempt to increment that variable at the same time. However, this will not work because Int is not a subtype if AnyRef. If you look back at figure 19.1 on page 453, you will see that Int falls under AnyVal. As a result, it does not have a synchronized method to call. In the script form, the only other object we have is threads so that is what we will use.
var cnt = 0
val threads:Array[Thread] = Array.fill(100){
new Thread {
override def run {
for(i <- 1 to 1000000) threads.synchronized {cnt += 1}
}
}
}
threads.foreach(_.start)
threads.foreach(_.join)
println(cnt)
Note that because this version uses threads inside of the declaration of threads, it becomes a recursive definition. For that reason, the type must be specified with the name. This is the same limitation that applies to methods and functions. We have simply never run into it before with a val or a var.
Normally you will not be writing multithreaded code inside of a script. After all, scripts are intended to be used with small programs and multithreading is most appropriate to speed up large programs. For that reason it is worth seeing what this would look like. The code below shows the same script moved into the main method of an object.
object ThreadCounting {
def main(args:Array[String]) {
var cnt = 0
val threads = Array.fill(100){
new Thread {
override def run {
for(i <- 1 to 1000000) ThreadCounting.synchronized {cnt += 1}
}
}
}
threads.foreach(_.start)
threads.foreach(_.join)
println(cnt)
}
}
With this structure, the synchronization can be done on the ThreadCounting object. If ThreadCounting had been a class or a trait, you could have done ThreadCounting.this.synchronized.
At this point you might be wondering why you do not synchronize everything to avoid race conditions. The reason is that synchronization has a cost in execution speed. Checking and setting locks on monitors takes real time. In addition, it prevents multiple threads from operating. If you really did synchronize everything, you would likely make the program run very slowly with only a single thread active most of the time and have very good odds of deadlock. Instead, you have to be careful with how you synchronize things.
If you played with the different programs in this section you probably found that the programs that gave the right answer through synchronization were slower. In testing them for this book they were found to take about 10 times longer to complete than what it took with no synchronization. How do you get around this? Try not to share a mutable state. In this example, it would be much better to have one variable per thread that is incremented and at the end you add all the results together. Here is a solution that does that.
class CountThread extends Thread {
var cnt = 0
override def run {
for(i <- 1 to 1000000) cnt += 1
}
}
val threads = Array.fill(100)(new CountThread)
threads.foreach(_.start)
threads.foreach(_.join)
var cnt = threads.view.map(_.cnt).sum
println(cnt)
Notice that in this version we had to define a new class that is a subtype of Thread. This allows us to access the cnt field. The java.lang.Thread class does not have a member named cnt so we need a new type that does. This code runs very close to the same speed as the earlier version that had no synchronization and it gets the correct answer.
One last thing to note about this code is that it uses a view. This is a topic that was introduced as an advanced topic on page 197. It is used here because we are interested in timing results and it is slightly more efficient to not have map create a completely new collection.
21.2.3 Wait/Notify
The synchronized method can help you to prevent race conditions, but it is not generally sufficient to coordinate the behaviors of different threads. In the basic thread libraries this is done with wait, notify,5 and notifyAll. More advanced tools have been introduced in libraries that we will discuss below, but there is some benefit to knowing how things work at the lowest level so we will discuss these briefly.
As with the synchronized method, wait, notify, and notifyAll are methods in AnyRef and can be called on any object of that type. The wait method does exactly what the name implies, it causes the current thread to stop executing and wait for something. That something is for it to be woken up by a call to notify or notifyAll in another thread. All of these calls require that the current thread hold the lock to the monitor for the object the method is called on. In addition, notify and notifyAll only wake up threads that were set to wait on the same object. You will normally see these calls in synchronized blocks. The call to wait releases the lock on that monitor. It will be reacquired when the thread wakes back up.
To see how this can work, consider this example that has a number of different threads that use wait to count off in turns with no more than one thread active at any given time.
object WaitCounting {
def main(args:Array[String]) {
val numThreads = 3
val threads = Array.tabulate(numThreads)(i => new Thread {
override def run {
println("Start "+i)
for(j <- 1 to 5) {
WaitCounting.synchronized {
WaitCounting.wait()
println(i+" : "+j)
WaitCounting.notify()
}
}
}
})
threads.foreach(_.start)
Thread.sleep(1000)
println("First notify.")
synchronized {notify()}
}
}
Each thread has a for loop that counts to 5. In the loop to synchronize on the object the code is in and calls wait. Once the thread is woken up by another thread, it will print out the thread number and the number in the loop, then notify some other thread. After that it immediately goes back to sleep as the next time through the loop leads to another call to wait. After the threads are built they are started and the main thread sleeps for one second before calling notify.
The call to sleep makes sure that all the threads have had time to start up and call wait before the first call to notify is made. If you leave this out, it is possible that the first call to notify will happen before the threads have started. More rigorous methods of accomplishing this would be to have a counter that increments as each thread starts.
Each call to notify wakes up a single thread that is waiting on the WaitCounting object so this works like dominoes with the prints running through the threads in whatever order notify happens to wake them up. The inability to predict what thread will be woken up is a problem. The real problem arises because it is possible that in later development some other thread might start waiting on this same object and that thread might not follow the same rule of printing then calling notify. That can lead to deadlock. In this example, if you simply add the following line to the bottom after the call to notify, you can create deadlock.
synchronized {wait()}
This causes a problem because now when one of the other threads calls notify, it wakes up the main thread instead of one of the printing threads. The main thread does not do anything after it wakes up though so we are left with printing threads that remain asleep forever.
The lack of predictability in notify has led to the standard rule that you should not use it. The recommended style is to have all calls to wait appear in while loops that check some condition and to always use notifyAll. The following code shows this rule in practice.
object WaitCountingSafe {
val numThreads = 3
def main(args:Array[String]) {
var handOff = Array.fill(numThreads)(false)
val threads = Array.tabulate(numThreads)(i => new Thread {
override def run {
println("Start "+i)
for(j <- 1 to 5) {
WaitCountingSafe.synchronized {
while(!handOff(i)) {
WaitCountingSafe.wait()
}
handOff(i) = false
println(i+" : "+j)
handOff((i+1)%numThreads) = true
WaitCountingSafe.notifyAll()
}
}
}
})
threads.foreach(_.start)
Thread.sleep(1000)
println("First notify.")
handOff(0) = true
synchronized {notifyAll()}
}
}
Now each thread has its own Boolean flag telling it whether another thread has handed it control. If that flag is not true, the thread will go back to waiting. In this way we regain control over things and reduce the odds of deadlock. Indeed, adding the same call to wait at the end of this code will not cause any problems at all.
21.2.4 Other Thread Methods
There are a number of other methods Thread that are worth knowing about. We have already seen the sleep method which causes a thread to stop processing for a specified number of milliseconds. Similar to sleep is the yield method. Calling Thread.’yield’ will make the current thread give up control so that if another thread is waiting it can take over. The backticks are required in this call because "yield" is a keyword in Scala. You use it with the for loop to make it into an expression. Using backticks allows you to have Scala interpret tokens as normal even if they are keywords that are part of the language.
The dumpStack method will print out the current stack trace. This can be helpful if you are running into problems in a certain method and you are not certain what sequence of calls got you there. You can also use Thread.currentThread() to get a reference to the Thread object that represents the current thread.
If you have a Thread object that you either created or got through a call to Thread.currentThread(), you can call other methods on that thread. The join method is an example we saw previously. See the API for a complete listing. One pair that is worth mentioning are the setPriority and getPriority methods. Each thread has an integer priority associated with it. Higher-priority threads will be preferentially scheduled by the thread scheduler. If you have work that needs to happen in the background and is not critical or should not impact the function of the rest of the system you might consider making it a lower priority.
There are also a number of methods for java.lang.Thread that you can find in the API which are deprecated. This implies that they should no longer be used. This includes stop, suspend, and resume. These methods are fundamentally unsafe and should not be used. It might seem like a good idea to be able to tell a thread to stop. Indeed, the writers of the original Java library felt that was the case. However, experience showed them that this was actually a very bad thing to do. Forcibly stopping a thread from the outside will often leave things in unacceptable conditions. A simple example of this would be if you kill a thread while it is in the middle of writing to a file. This not only leaves the file open, it could very well leave the file in an inconsistent state that will make it unusable later.
Scala will give you warnings if you use deprecated library calls. You should pay attention to these, find them in your code, and look in the API to see how they should be handled. In the case of stopping threads, the proper technique is to have long running threads occasionally check Boolean flags that tell them if they should continue running. If the flag has been changed they should terminate in an appropriate manner.
21.3 Concurrency Library
Direct thread control gives you the power to do anything you want with multithreaded parallelism, but it is hard to do correctly and there can be a significant amount of code behind many common tasks. For this reason, the java.util.concurrent package was added in Java 5 to make many of the common tasks in parallel programming easier to do. In general, if you have detailed threading tasks that you can not do with the Scala libraries we will present later on, you will use elements from java.util.concurrent along with synchronized to accomplish what you want.
21.3.1 Executors and Executor Services
The process of creating new threads is expensive and is not abstract, meaning it can not be easily varied for different platforms. The java.util.concurrent package addresses this with the Executor and ExecutorService types. The Executor type is a very simple abstract type with a single method.6
def execute(command:Runnable):Unit
When this method is called, the run method of the command is called. What you do not know at this level is how that will be done. It is possible that a new thread will be created and it will run in that thread. However, it is also possible that it could be run in a thread that had been created earlier or even run in the current thread. Note that this last option implies that the current thread might not continue until after the command has finished.
The abstract type ExecutorService extends Executor and adds significantly more functionality to it. The following methods are significant for us. Look in the Java API for a full list.
- shutdown():Unit - Tells the service to start an orderly shutdown allowing current tasks to finish. New tasks will not be accepted.
- submit[T](task:Callable[T]):Future[T] - Submits the specified task for execution and returns a Future[T] object representing the computation.
- submit(task:Runnable):Future[_] - Submits the specified task for execution and returns a Future[_] object representing the computation.
There are two new types presented in these methods: Callable[T] and Future[T].
21.3.2 Callable and Futures
With normal threads, the computation can only be submitted as a Runnable. Unfortunately, the run method in Runnable does not return a value. This is a significant limitation as we often want to get results from the threads. The Callable[T] type contains one method that has a return value.
def call[T]():T
The submitted task might take a while to finish, so the submit method can not return the T object as that would require blocking. Instead, it returns a Future[T] object that can be used to check on the computation (use isDone():Boolean) and get the result when it is complete (use get():T).
Both Executor and ExecutorService are abstract. The standard way to get a concrete instance is to call one of several methods on java.util.concurrent.Executors. The methods you are likely to use are newCachedThreadPool():ExecutorService and newFixedThreadPool(nThreads:Int):ExecutorService. A cached thread pool will make as many threads as there are active tasks. Once a task has completed, the thread is stored in a wait state so that it can be reused for a later task. A fixed thread pool only has the specified number of threads. If a new task is submitted when all the threads are filled, it will wait until one of the active threads has completed.7
To demonstrate these things in action we will look at a version of factorial that uses BigInt and is multithreaded. Recall that a single threaded version of this can be written in the following way.
def fact(n:BigInt) = (BigInt(1) to n).product
If you call this for sufficiently large values of n, you will find that it can take a while to complete the calculation.8 That makes it a reasonable function of us to consider parallelizing. How should we go about doing that? We want a function that breaks the multiplications up across a number of threads using an executor service. So the question that so often comes up when creating parallel programs is, how do we break up the work?
One approach to this is to break all the numbers into groups. If n were divisible by nThreads this could be viewed as n! = 1 ∗ ... ∗ n/nThreads ∗ (n/nThreads+1) ∗ ... ∗ 2∗n/nThreads ∗ (2∗n/nThreads+1)∗... When n is not divisible by nThreads, we need to make some of the groups bigger. Here is code that does that.
def parallelFactorial(n:BigInt,es:ExecutorService,nThreads:Int):BigInt = {
val block = n/nThreads
val rem = n%nThreads
var i=BigInt(1)
val futures = Array.tabulate(nThreads)(j => es.submit(new Callable[BigInt] {
def call():BigInt = {
val start = i
val end = start + block + (if(BigInt(j)<rem) 1 else 0)
i = end
(start until end).product
}
}))
futures.map(_.get).product
}
This function starts with calculations of the base size for each block as well as how many blocks need to be one bigger. It then creates a variable i that helps us keep track of where in the range we are. A call to Array.tabulate is used to submit the proper number of tasks to the ExecutorService. Each task uses i as the start value and adds an appropriate offset to get the end value. It then updates i and uses the standard product method to multiply the values in that chunk. The last thing this code does is map the various Future[BigInt] objects with get. This will block until they are done and give us a collection of the results. Another call to product produces the final result.
You can put this in a script or load it into the REPL to test it. When you do this, you probably want to start off with an import, then make your Executor Service.
import java.util.concurrent._
val es = Executors.newCachedThreadPool()
Now you can call the function and compare it to the non-parallel version above. Ideally you would specify the number of threads to be equal to the number of cores in your computer, but you can play with this to see how it impacts execution time. Either at the end of the script or before you exit the REPL you need to call es.shutdown().
This approach to breaking up the work is not the only option we have. One potential problem with this approach is that the different threads we created really do not have equal workloads. The way the BigInt works, dealing with large numbers is slower than dealing with small numbers. Given the way the work was broken up here, the first thread winds up with a much smaller value than the last one and, as such, has a smaller work load. An alternate approach would be to have each thread work with numbers spread out through the whole range. Specifically, the first thread does 1∗(nThreads+1)∗(2∗nThreads+1)∗... while the second thread does 2∗(nThreads+2)∗(2∗nThreads+2)∗..., etc. The methods of Range types in Scala actually makes this version a lot shorter.
def parallelFactorial(n:BigInt,es:ExecutorService,nThreads:Int):BigInt = {
val futures = Array.tabulate(nThreads)(j => es.submit(new Callable[BigInt] {
def call():BigInt = {
(BigInt(j+1) to n by nThreads).product
}
}))
futures.map(_.get).product
}
The by method lets us get a range of values with the proper spacing. As long as it starts at the proper value, everything else will work the way we need.
You can use the System.nanoTime() method from Java to measure how long it actually takes to complete the calculation. Just call it before and after the calculation and take the difference to get the number of nanoseconds taken. You can divide that value by 1e9 to get a value in plain seconds.
If you play with the three versions of factorial that are presented here you should find that the parallel versions are faster than the sequential version, but it is not by all that much. If you have access to a machine with enough cores, you probably also noticed that there was a point of diminishing returns. Going from one thread to two shows a significant boost, perhaps even more than a factor of two. However, going up to four threads almost certainly does not return another factor of two improvement and further additions become less and less beneficial. There are a number of things going on here, but one of the big ones is what is know as Amdahl’s law [1].
The basic idea of Amdahl’s law is that the benefit you get from improving the speed of a section of your code depends on how much of the code you can make this improvement to. In the case of parallel processing, not all of the program will be done in parallel. Some sections are still done sequentially. If the faction of your code that is done in parallel is represented by P , and the fraction that remains sequential is (1 − P), then Amdahl’s law states that the maximum speedup you can get with N processors is
As N goes to infinity, this converges to
So no matter how many processors you have, you are limited in the speed boost you can see by how much of the code you can actually do in parallel.
How much work are our functions here doing sequentially? In the second version it is pretty clear that the only sequential work is submitting the tasks and calculating the final product. For large values of n, submitting the tasks should be fairly negligible. Unfortunately, the final product will not be. Remember that operations with BigInt take longer for bigger numbers. The biggest numbers of the calculation will be the ones at the end that come up during this sequential section. If we really wanted to make this as fast as possible, we would need to make that last product happen in parallel as well. That task is left as an exercise for the reader.
Computer Performance (Advanced)
In chapter 13, when we were looking at sorting and searching algorithms, you should have gotten some experience with the fact that measuring the performance of a computer program can be challenging. The same program running with the same input on the same computer can take varying amounts of time to execute. To deal with that you need to take a number of timing tests and average them.
The performance can also vary in odd ways depending on the input size. This might have come out with the sorts as well. The amount of time spent in a bubble sort can increase by the expected factor of four when you double the input size for a range of inputs, but there will be points where it jumps dramatically. Instead of going up by a factor of four it might jump by as much as 100. This is generally due to the memory hierarchy of the computer. At some point in your studies you should learn about cache memory and how it works. In this context, once the data you are accessing gets bigger than one of the cache levels in your machine, the speed can drop dramatically as memory has to be fetched from a more distant memory store.
Doing parallel processing can make things even more complex. It would be nice if the runtime of programs would scale as the number of threads used up to the core count of the machine. We already saw that Amdahl’s law precludes that behavior unless every line of code can be done in parallel. Things can be even odder though and not always in a bad way. On a test system, using two threads in the parallel factorial program reduced the runtime by significantly more than a factor of two. You might wonder how that is possible. Actually answering that requires detailed testing on any specific machine, but a common possibility deals with cache again. Multicore chips have some cache that is local to a core and some that is shared. Breaking up a problem across threads can lead to a situation where each thread uses only a fraction of the total memory. When this happens, the memory used by a thread might drop under one of the critical thresholds for the memory hierarchy of the chip. This can lead to abnormally good speed improvement. One the other hand, it is possible that multiple threads could be writing to adjacent pieces of memory regularly, which can slow things down because the cores have to talk to one another to make sure they have the latest version.
Modern processors are very complex and there are a lot of factors that go into how well they perform. The details of that go well beyond the scope of this book. For our purposes, we will try to find safe ways to break workloads across many threads without introducing unneeded overhead.
21.3.3 Parallel Data Structures
There are a number of different data structures provided in java.util.concurrent that help in performing common tasks. Instead of simply telling you what these do, we will consider scenarios where you want to do different things and then present the data structures that can help you to do those things.
21.3.3.1 Shared Barriers
Earlier we had the example of a large number of people working to dig a trench that would then be filled with water. This is the type of task where you have many workers, represented by threads on the computer, working on a task and there are certain critical points where no one can proceed until everyone has gotten to that point.
Consider a computer program that has to deal with collisions between moving objects in a scene. Collisions need to be handled at the exact time they occur for this to be accurate. In the program there are other things that need to be computed at certain intervals. We will call this interval the time step and it has a length of Δt. Collisions are processed in a more continuous way through the time step. So in any given step you would look for collisions that happen given the initial configuration, process collisions, with updates that happen as a result of earlier collisions, then do whatever processing is required at the end of the step.
To make things go fast, you want to break this work across as many threads as you can. You break the particles up into groups and have one thread run through and find all collisions during that time step given the initial trajectories of the particles. You can not start processing collisions until all the threads are done identifying the first round because it is possible that the last one found could be the first one you need to process. So all the threads have to finish finding collisions before the first one can be processed. There are schemes for processing collisions in parallel as well that make sure that you do not ever work on two collisions at the same time if they are too close. All collisions have to be processed and all threads have to get to the same point before the other processing can be done.
There are three different types in java.util.concurrent that can help give you this type of behavior. The first one is a type called CountDownLatch. You instantiate a CountDownLatch with new CountDownLatch(count), where count is an integer value. The two main methods of this type are countDown, which decrements the count by one, and await which will block until the count reaches zero. If the count is already at zero, a call to await does nothing.
The second type that can provide this type of behavior is the CyclicBarrier. While the CountDownLatch is only good for one use, the CyclicBarrier can be cycled many times. You make a CyclicBarrier with new CyclicBarrier(parties), where parties is an integer number specifying how many threads should be involved in the barrier. When each thread has finished doing its task, it makes a call to the await method on the CyclicBarrier. Once all "parties" have called await, they are all allowed to proceed forward.
The third type is the Phaser type. This type is more complex than the other two. It is also newer, having been added in Java 1.7. Interested readers should consult the API for usage of this type.
21.3.3.2 The Exchange
Imagine a situation where two parties work mostly independently, but they perform calculations that require some information from another party. You do not want to try reading the information at any old time as the value might not contain a valid, final result most of the time. Instead, you need to arrange a point when the parties pause and come together for an exchange.
An example might be a large simulation of a solid body like an airplane. These are often done with finite-element models. Each thread would have a chunk of the plane to work with and it would calculate the stresses on the elements in that chunk as they change over time. The stresses on one chunk will depend on what is happening with all the elements in adjacent chunks that are connected to elements in the first one. In order to do a full calculation, the threads need to meet up to exchange information about the boundary elements. This type of thing can be done with an Exchanger.
You instantiate an Exchanger with new Exchanger[A](), where A is the type of information you want to exchange. When a thread is ready to exchange, it calls exchange (x:A):A on the Exchanger. This method will block for the first thread until the second thread also calls it. At that point, both calls return and each thread gets the value that was passed in by the other one.
21.3.3.3 Assembly Line
When you picture humans working in parallel on a task, one way to break things up is the assembly line. Here you have one group of people who do some part of the work and get products to a certain point. Then they pass their results on to others in a different group who do the next step. This continues until the final result is produced. This arrangement has a critical junction at the point where the product moves from one station to the next. Generally, one person in line can not start working on something until the person before them is done. If there are not any products in the right state, then that person needs to wait until one shows up.
There are two different types in java.util.concurrent that will allow you to achieve this behavior, BlockingQueue[A] and BlockingDeque[A]. The two main methods on both of these types are put and take. The put method will add a new value in. Some implementations of these types will have limited space. If there is not space to add the new value, the call will block until space is freed up. The take method will remove a value. If no value is available, then the call will block until one becomes available.
Both of these types are abstract. In the case of BlockingDeque there is one implementation provided called LinkedBlockingDeque. For the BlockingQueue type there are a number of different implementations: ArrayBlockingQueue, DelayQueue, LinkedBlockingQueue, LinkedTransferQueue, PriorityBlockingQueue, and SynchronousQueue. We will talk about queues in general and specific implementations using arrays and linked lists in chapters 24 and 25. After covering that material you might consider revisiting the concept of the BlockingQueue.
21.3.3.4 Ticketed Passengers
Some types of work are limited by resources. If you are building a house the number of people involved in driving nails will be limited by the number of hammers that you have. If you are transporting people on a plane, there are a limited number of seats. On a computer, there might be limits to how many threads you want involved in activities that deal with hardware, like reading from the network. There might be some types of processing that are particularly memory intensive for which you need to limit the number of threads doing them at any given time. For these types of situations, the Semaphore provides a way to limits how many threads can get to a certain region of code at a given time. Unlike the monitors described with synchronized, the Semaphore is more flexible than just allowing one thread in at a time.
You can instantiate a Semaphore with new Semaphore(permits), where permits is an Int specifying how many of the resource you have. The main methods for the Semaphore are acquire and release. The acquire method will get one of the permits. If none are available, it will block until a different thread calls release to make one available. There is also a tryAcquire method that returns a Boolean that does not block. If a permit was available, it takes it and returns true. Otherwise it simply returns false.
21.3.3.5 Other Threadsafe Types
Various types in java.util.concurrent for working in applications with multiple threads. These types all begin with Concurrent. If you are using mutable data types from the Scala libraries, you can mix-in the proper synchronized traits, but because that gives you types where all methods are synchronized, the concurrent versions can provide better performance.
For example, if you are dealing with a mutable map, the Scala libraries would let you do the following.
val smmap = new mutable.HashMap[String,Data] with
mutable.SynchronizedMap[String,Data]
This would give you a mutable map that uses a String for the key with some type called Data for the values where all the methods are synchronized so that it can be safely used across threads. Alternately, you could use the Java libraries and get a ConcurrentHashMap like this.
val cmmap = new ConcurrentHashMap[String,Data]
This version will likely have better performance, but it will lack most of the methods you are used to having on collections such as map and filter. It will also lack the ability to use indexing syntax to get and set values. Instead, you will have to explicitly call get and put methods.
21.3.4 Atomic (java.util.concurrent.atomic)
There are two packages under java.util.concurrent. The first is java.util.concurrent.atomic. This package contains a number of different classes that provide you with ways of storing and manipulating data in an atomic manner.
Back in subsection 21.2.2 we looked at a number of different programs that did counting across multiple threads. One of the solutions that we considered in that section synchronized the increments. This was needed because the seemingly simple statement cnt += 1 is not atomic, it can be interrupted leading to race conditions. Indeed, without synchronization using this statement with a single mutable variable inevitably produced incorrect results.
The problem with using synchronization in that situation was that there is a lot of overhead in checking and locking monitors. The atomic package provides us with a slightly lighter weight solution. One of the classes in java.util.concurrent.atomic is AtomicInteger. Instances of this class store a single integer value. The advantage of using them is that they provide a number of different methods for dealing with that value that operates atomically without doing full synchronization. Here is code that does the counting using AtomicInteger.
import java.util.concurrent.atomic._
var cnt = new AtomicInteger(0)
val threads:Array[Thread] = Array.fill(100){
new Thread {
override def run {
for(i <- 1 to 1000000) cnt.incrementAndGet()
}
}
}
threads.foreach(_.start)
threads.foreach(_.join)
println(cnt.get)
In limited testing, this code ran about twice as fast as a version with full synchronization. That is still significantly slower than a version that uses multiple counters and combines the results at the end, but there are some situations where you truly need a single mutable value. In those situations, types like AtomicInteger are the ideal solution.
21.3.5 Locks (java.util.concurrent.locks)
The other package under java.util.concurrent is java.util.concurrent.locks. Locks were added to address a shortcoming in using synchronized. When you use synchronized you are able to lock a monitor and restrict access from other threads for one block of code or one method. However, it is not uncommon to have code where you want to restrict access beginning with one method call and not release it back until some other method is called. There is not a concise way to do this with synchronized, but there is with a Lock. Lock is an abstract type with the methods lock, unlock, and tryLock. It is much like a Semaphore with only one permit. The main concrete subclass is called ReentrantLock, which you can make by calling new ReentrantLock.
21.4 Parallel Collections
Even working with the concurrency library, parallelism can be hard to do well. For this reason, beginning with version 2.9, Scala has added another layer in the form of parallel collections. These are collections that have their basic operations performed in parallel. Not only do they do their operations in parallel, they have been written in such a way that they will automatically load balance. If one thread finishes its own work load, it will steal work from another thread that has not yet finished. For this reason, if your problem can be solved using parallel collections, you should probably use them. Not only will they be easier to write, they will probably be more efficient than anything you are going to take the time to write yourself.
The structure of the parallel collections largely mirrors the structure of the normal collections with a scala.collection.parallel package that has subpackages for immutable and mutable types. The parallel collections are not subtypes of the normal collections we have used to this point. Instead, they have mutual supertypes that begin with Gen for general. The reason for this is that the original collections had an implicit contract to go through their elements in order and in a single thread. A lot of the code we have written did not depend on this, but some of it did. The general types explicitly state that they do not have to preserve that behavior.
The parallel collections have names that begin with Par. Not all of the types we used previously have parallel equivalents. This is because some types, for example the List, are inherently sequential. If you think back to the last chapter, we saw that there were a whole set of types under the LinearSeq type that had linear access behavior. None of those types can be efficiently implemented in parallel because of that. Figure 21.2 shows a Unified Modeling Language (UML) class diagram of the parallel collections.
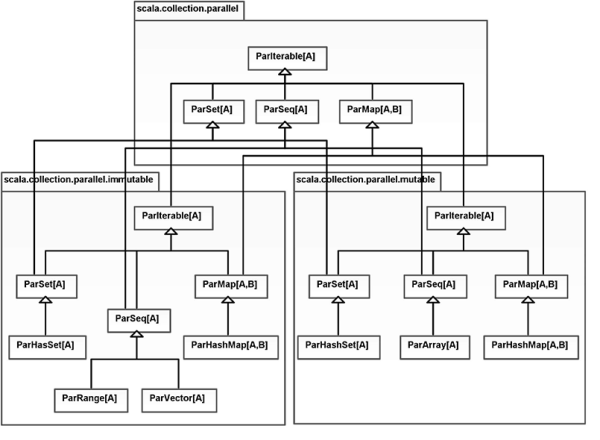
This UML diagram shows the main types in the three different parallel collection packages.
To convert from a normal collection to a parallel collection call the par method on the standard collection. To convert back, call the seq method on the parallel collection. These calls are efficient for types that have a parallel equivalent. You can convert a Range, a Vector, an Array, a HashSet, or a HashMap from sequential to parallel and back in O(1) time. For other types, the conversion will be less efficient as it has to build a completely new collection. Consider the following examples from the REPL.
scala> 1 to 10 par
res0: scala.collection.parallel.immutable.ParRange = ParRange(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> Array(1,2,3,4) par
res1: scala.collection.parallel.mutable.ParArray[Int] = ParArray(1, 2, 3, 4)
scala> List(1,2,3,4) par
res2: scala.collection.parallel.immutable.ParSeq[Int] = ParVector(1, 2, 3, 4)
The first two calls are able to simply wrap the sequential version in a parallel collection. The last one has to convert the List over the a ParVector. The choice of ParVector in this situation is made because preserving immutability is the primary consideration.
The parallel collections have all the normal methods that you are used to using. Given this, you can write a parallel version of factorial using BigInt with the following code.
def parFact(n:BigInt) = (BigInt(1) to n).par.product
This version is clearly shorter than the ones that we wrote earlier. What is more, if you test it, you will find that it is faster and scales better because it does not have as much inherently sequential code.
There is one method that is very significant for parallel collections called aggregate. In many ways, you can think of this method as being like a parallel version of the fold or reduce methods. The fact that you specifically call either foldLeft, foldRight, reduceLeft, or reduceRight tells you that those operations are sequential in their nature. A parallel version has to be able to run through the elements in whatever order it wants. Different threads will be running through different parts of the collection at the same time. For parallel, there are fold and reduce methods that will do those operations in an order-independent manner.
The reduce method is a full replacement for reduceLeft or reduceRight in situations where the order in which elements are processed does not matter. The same is not true of fold. To see why, compare the signatures of fold and foldLeft from ParIterable[T] in the API.
def fold [U >: T] (z: U)(op: (U, U) U): U
def foldLeft [S] (z: S)(op: (S, T) S): S
The fold method is more restricted in the types that it can use. While foldLeft could result in any type that you want, fold must result in a type that is a supertype of the type the collection contains. The reason for this restriction is that when a fold is done in parallel, you can have one thread apply op to one section of the collection while another thread does the same for a different section. To get your final answer, you have to be able to combine the results of the two threads. The combining operation only works with the same function if both parameters for the function have the same type as the output of that function.
The aggregate method addresses this shortcoming, but doing so requires two separate operators. Here is the signature of the method.
def aggregate [S] (z: S)(seqop: (S, T) S, combop: (S, S) S): S
The seqop is equivalent to the op that is passed into foldLeft. The combop is used to combine the results of processing the different pieces. Any time when you would use foldLeft or foldRight with a result type that is distinctly different from the type stored in the collection and the processing order is not critical to getting the correct answer, you can use aggregate instead.
As a simple example of this, consider the following code that generates a parallel array of 1000 random doubles then finds the min and max values using aggregate.
val data = ParArray.fill(1000)(math.random)
val (min,max) = data.aggregate((data(0),data(0)))(
(mm,n) => (n min mm._1,n max mm._2),
(mm1,mm2) => (mm1._1 min mm2._1,mm1._2 max mm2._2)
)
It would have been much shorter to simply write data.min and data.max, but each of those calls has to run through the full set of data. This approach only runs through the data once to find both the minimum and maximum values. Given the overhead in creating tuples it is not clear that this is a benefit when we are simply comparing Doubles, but if the values we were comparing were found via a complex calculation on the data, this approach might be beneficial. More significant is that it shows how you can use aggregate to do a fold type of operation in parallel with a result that is distinctly different from the type stored in the collection.
21.5 Introduction to Scala Actors
The creators of Scala are well aware of the challenges of multithreaded code as well as the significance of multithreading to the future of computing. For that reason, they have given a high priority to supporting multithreading in a way that is easy for programmers to use. This comes out clearly in the parallel collections. Even before the parallel collection libraries were added to Scala, there was another library supporting a different type of parallelism, the actors library in scala.actors.
Actors are an approach to parallelism that has been popularized by the Erlang programming language. In this approach, a system is built of multiple actors that communicate by sending messages to one another. You can imagine each actor doing its work in its own thread with the work being done in response to receiving a message.
The full details of actors are beyond the scope of this chapter and will be discussed in chapter 34. The actors package does provide two utility objects that are very helpful and easy to use, so we will describe them. In many situations, these objects will prevent us from having to make and use an ExecutorService. The scala.actors.Actor object has a method called actor with the following signature.
def actor (body: => Unit): Actor
This method provides a simple way to execute a block of code in a separate thread. The fact that this returns an Actor is not particularly relevant to us at this point. You can use this just like a call to submit on a cached thread executor service when we do not care about the return value. If you do want a return value, you would use the future method of the scala.actors.Futures object instead. This method has a signature like this.
def future [T] (body: T): Future[T]
Note that the Future[T] here is a scala.actors.Future, not a java.util.concurrent. Future. When you want the value of this type of object, instead of calling get you simple invoke apply by using it as a function with no arguments.
Both of these functions take a single argument that is passed by name. Remember that Scala lets you use curly braces instead of parentheses for argument lists of a single parameter. The rule exists for just this type of situation. If you have imported scala.actors._ you can start some code in a separate thread just like this.
Actor.actor {
statement1
statement2
...
statementN
}
The same will work with Futures.future though you likely want to assign the result to a val.
GPUs
Multicore chips are not the only example of computer hardware moving toward parallelism. Another significant trend is the use of the Graphics Processing Unit (GPU) to help with general purpose computing. This is commonly called GPGPU. Higherend GPUs are typically found on separate graphics cards, though there are integrated graphics on motherboard and beginning around 2010, it became more common to find GPU elements etched onto the same silicon and CPUs.
The idea of doing general purpose calculations on a graphics card might seem odd at first. To see why it works, you need to know something about how graphics cards work. Graphics is basically a lot of math. Early GPUs were built specifically to do just the math that was needed with graphics. They did this in the fastest way possible and did not adhere to floating point number standards because you honestly do not need many digits of accuracy for building an image that is on the order of 1000 pixels across.
Over time, the desire for more realistic graphics capabilities led to the creation of pixel shaders. These allowed programmers to write limited logic that could be run for each pixel in an image or on the screen. This was a significant break from earlier designs as it allowed true programmable logic on the GPU. At first this logic was still very heavily focused on graphics-related calculations, but the fact that a GPU could do floating point math extremely fast tempted people into trying to use pixel shaders for other purposes.
Since then, GPUs have become more flexible and more programmable. The support for GPGPU became a selling point, so hardware manufacturers put in proper IEEE floating point arithmetic. First this was only in single precision, but later double precision was added as well. This has culminated in cards built specifically for GPGPU. These cards have lots of memory and one or more GPU chips in them, but they often do not have any graphics output. They are designed and sold just to support GPGPU style calculations.
While multicore chips have a few cores and there are plans to take them to tens or even a few hundreds, GPUs will support thousands or tens of thousands of threads. You have to break up a problem into a lot of pieces to keep a GPU busy. In addition, the threads on a GPU are not as fully capable as those on the cores of a CPU. Typically GPU threads need to be run in groups that are all doing very nearly the same thing to different data.
At this time there are two main interfaces to support GPGPU-style programming: CUDA® and OpenCL®. CUDA is an API created by NVIDIA® which only runs on NVIDIA GPUs. OpenCL, as the name implies, is an open standard that supports GPU and other high thread count computation models. There is currently preliminary support for OpenCL in Scala through the ScalaCL package. ScalaCL works in large part through an augmented set of collections that split the work up on the GPU instead of over multiple cores like the normal parallel collections do.
If you major in Computer Science, GPGPU is probably a topic that should be on your radar and all indications are that CPUs with integrated GPUs will become common. As was shown at the beginning of this chapter, it was not long ago that most programs did not need multithreading because most computers did not require it to run at full speed. A similar change could be in the works for GPUs and programmers will have to have some understanding of what is happening in the hardware to write programs that take full advantage of the resources they have.
21.6 Multithreaded Mandelbrot (Project Integration)
Now that you have seen many of the different possibilities for multithreading as well as the challenges that it poses, let’s write a simple example that uses multithreading for our project. The code that we will write here will draw a Mandelbrot set in the drawing with the user able to specify the range to draw on the real and imaginary axes as well as the size of the region to draw. We will put this in a new class called DrawMandelbrot that extends DrawLeaf.
The Mandelbrot set is characterized by the mapping where z0 = 0 and c is a point in the plane. There is a different sequence for every point in the complex plane. For some points, the sequence will diverge to infinity. For others, it will stay bound. For our purposes here, it is not the math we are concerned with, but making the math happen in parallel while being translated to an image that we can draw.
Calculating the Mandelbrot set is an embarrassingly parallel problem. This means that it can be broken into separate pieces that can be solved completely independently. So you can put each piece in a different thread and they do not have to talk to one another. This makes it an ideal candidate for solving with the parallel collections library. This code shows just such a solution.
package scalabook.drawing
import java.awt.{Graphics2D,Color}
import java.awt.image.BufferedImage
import swing._
import event._
class DrawMandelbrot(p:DrawTransform) extends DrawLeaf {
val parent = p
private var propPanel:Component = null
private var (rmin, rmax, imin, imax) = (-1.5, 0.5, -1.0, 1.0)
private var (width, height) = (600, 600)
private var maxCount = 100
private var img:BufferedImage = null
private var changed = false
private val properties:Seq[(String,() => Any,String => Unit)] = Seq(
("Real Min", () => rmin, s => rmin = s.toDouble),
("Real Max", () => rmax, s => rmax = s.toDouble),
("Imaginary Min", () => imin, s => imin = s.toDouble),
("Imaginary Max", () => imax, s => imax = s.toDouble),
("Width", () => width, s => width = s.toInt),
("Height", () => height, s => height = s.toInt),
("Max Count", () => maxCount, s => maxCount = s.toInt)
)
def draw(g:Graphics2D) {
if(img==null || changed) {
if(img==null || img.getWidth!=width || img.getHeight!=height) {
img = new BufferedImage(width,height,BufferedImage.TYPE_INT_ARGB)
}
for(i <- 0 until width par) {
val cr = rmin + i∗(rmax-rmin)/width
for(j <- 0 until height) {
val ci = imax - j∗(imax-imin)/width
val cnt = mandelCount(cr,ci)
img.setRGB(i,j,if(cnt == maxCount) Color.black.getRGB else
new Color(1.0f,0.0f,0.0f,cnt.toFloat/maxCount).getRGB)
}
}
}
g.drawImage(img,0,0,null)
}
def propertiesPanel() : Component = {
if(propPanel==null) {
propPanel = new BorderPanel {
layout += new GridPanel(properties.length,1) {
for((propName,value,setter) <- properties) {
contents += new BorderPanel {
layout += new Label(propName) -> BorderPanel.Position.West
layout += new TextField(value().toString) {
listenTo(this)
reactions += {case e:EditDone => setter(text); changed = true}
} -> BorderPanel.Position.Center
}
}
} -> BorderPanel.Position.North
}
}
propPanel
}
override def toString() = "Mandelbrot"
private def mandelIter(zr:Double,zi:Double,cr:Double,ci:Double) =
(zr∗zr-zi∗zi+cr, 2∗zr∗zi+ci)
private def mandelCount(cr:Double,ci:Double):Int = {
var ret = 0
var (zr, zi) = (0.0, 0.0)
while(ret<maxCount && zr∗zr+zi∗zi<4) {
val (tr,ti) = mandelIter(zr,zi,cr,ci)
zr = tr
zi = ti
ret += 1
}
ret
}
}
The only part of this code that deals with making it parallel is the call to par in the outer for loop in the draw method. There is not a call to par in the inner loop based on the assumption that whole columns make a fairly good level at which to break things up for threads. To get this into a drawing you need to add the following line into the addTo method in Drawing.
("Mandebrot", () => new DrawMandelbrot(parent)),
Once you have done this you can run the program and add a Mandelbrot set. The result should look like figure 21.3.
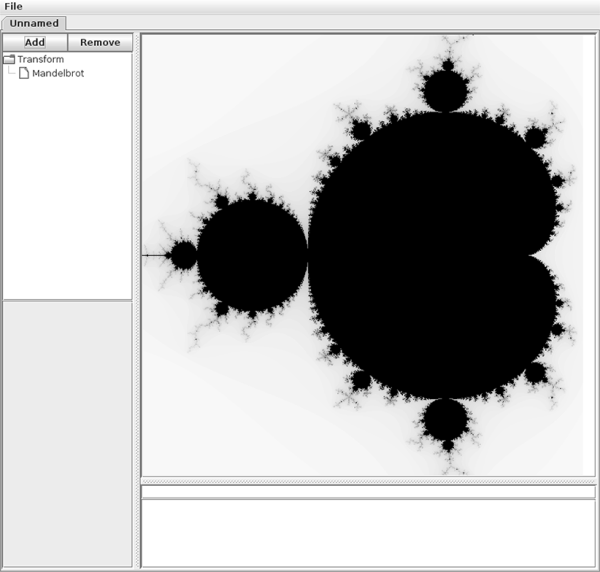
This is a screen capture of the drawing program with a Mandelbrot image drawn using the default values from the code.
While the parallelism of this code is not remarkably interesting, there is another part of this code that is worth taking a look at. This is the first Drawable type that we have written with a number of different user adjustable properties. To be specific, there are seven different properties for this. They all have a very similar style to them. The original version of this code had a much longer propertiesPanel method that contained seven different versions of the code that makes a BorderPanel with a Label and a TextField. The seven different versions were nearly identical except for one string and two variable names. This type of code hopefully strikes you as being less than ideal. It is a form of code duplication that tends to make code brittle and hard to deal with. In chapter 27 we will talk about "smells" associated with code. You might well say that the original code was "smelly". What you see here is one approach at fixing this.
The basic problem was that we had seven nearly identical pieces of code. What we want is one copy of the code that we can put in something like a loop, which abstracts the things that vary across the different versions. This goes back to the push we have in the second half of this book to emphasize abstraction as a tool to help make your programs more powerful and easier to maintain. In this case we introduced a sequence of three tuples. The choice of three values in the tuple came from the fact that there were three places in the original code that were different. The first was the String describing the name of the property. The second was where the value of that property was used to initialize the TextField. The third was the code that set the property when an EditDone event occurred. These became the three elements of the tuple. The type of the tuple is given at the declaration so that we do not have to specify that the argument s in the third element of each tuple is a String. The second element of each tuple is given as a function instead of just a value so that whenever the Graphical User Interface (GUI) is built, it will get the most up-to-date value.
21.7 Multithreading in GUIs
In reality, you have been writing multithreaded code since chapter 11. This is because code that includes GUIs is inherently multithreaded. You can demonstrate this with the following code.
val frame = new swing.MainFrame {
title = "Thread Demo"
contents = swing.Button("Click Me")(println("Button Clicked"))
}
frame.visible = true
for(i <- 1 to 20) {
println(i)
Thread.sleep(1000)
}
This will make a little frame with a single button that you can click. Any time you click the button it will print a message. After making the frame visible, the main thread goes into a for loop that counts to twenty with one-second pauses between values. When you click the button, the message is printed between numbers. This works because event handling in GUIs is done in its own thread. This other thread, called the event thread, is responsible for handling all events that happen in the GUI and for repainting what is seen on the screen. When we call repaint, it does not actually do the painting then. Instead it schedules an event for the event thread so that a repaint will be done the next time it can.
The fact that a single thread is responsible for handling all events and repaints means that you have to be careful what you do in that thread or you can stop all responses from the GUI. The following code demonstrates that fact.
val frame = new swing.MainFrame {
title = "Thread Blocking"
contents = swing.Button("Click Me")(Thread.sleep(10000))
}
frame.visible = true
readLine
If you click the button, it blocks the event thread from doing anything else for ten seconds. If you run this program you can click the button and see the effects. One effect is that the button will "stay down". More interesting is seeing what happens if you try to close or resize the window. The close will not take effect until the end of the ten seconds. The window will not repaint itself during that time either.
To see this same effect on a larger scale, add the following line into the commands map in the Commands object in the project code.
"freeze" -> ((rest,d) => Thread.sleep(rest.trim.toInt∗1000))
Now you can run the drawing program, add a drawing, and enter the command "freeze 10". After doing this, nothing you do in the GUI will take effect for ten seconds. This command will be useful in the next section as well to see how blocking the event thread impacts other things that happen in the GUI.
Much of this chapter has focused on the challenges associated with using threads. Those challenges remain for the threads associated with a GUI. As you just saw, keeping the event thread busy too long can lead to an unresponsive GUI. It is also risky to have other threads altering mutable data that is used by the event thread as that can lead to race conditions. This combination makes things a bit tricky because you need to have any significant workload happen in a separate thread, but you should not have that other thread mutate values that are used for painting or event handling. Instead, you should have the other thread notify the GUI using events. This is what happens with calls to repaint. Instead of doing the paint in the thread that makes the call, it fires off an event that tells the GUI to do a paint.
All of the different GUI components are Publishers so they have a method called publish that takes an event. To see how we can use this, we can make the command processing in Drawing so that it does the work in a separate thread and notified the GUI using an event. Consider the following alteration to the commandField declaration in Drawing.
val commandField = new TextField() {
listenTo(this)
reactions += {
case e:EditDone =>
if(!text.isEmpty) {
val t = text
Actor.actor {
publish(new ResultEvent(t,Commands(t,Drawing.this)))
}
text=""
}
case e:ResultEvent =>
commandArea append "> "+e.text+"
"+e.result+"
"
}
}
This code uses Actor.actor to start the command executing in a separate thread. When the command is finished, the result is bundled into a ResultEvent along with the text that was executed and that is published. The commandArea is updated when the ResultEvent is received. To make this work, the following declaration of ResultEvent was added above the propertiesPanel method.
private class ResultEvent(val text:String,val result:Any) extends Event
The use of publish and having the change to commandArea happen in the event thread means that we can not have the thread created by actor put the GUI in an inconsistent state at a significant time, such as a redraw.
To really see the impact of this code you need to run DrawingMain and add a drawing, then try using the "freeze" command again. What you will find is that the GUI no longer freezes up. If you do "freeze 10" you can keep using the GUI and nothing will happen for ten seconds. At the end of the ten seconds, the output area will show the proper feedback to indicate that the command completed. You can even type in other commands while a freeze command is working. If the other commands finish before the end of the freeze time, their feedback in the output panel will come before that of freeze.
The other place where threading is significant for GUIs is during animation. The easiest, safe approach to doing animation in a GUI was introduced in chapter 12 where we created a javax.swing.Timer and gave it an ActionListener. The ActionListener is a type from the Java event handling libraries so this code will run the timed code in the GUI event thread and not cause any threading problems. We will use this approach again in the following section.
21.8 Animated Bouncing Balls (Project Integration)
To illustrate the use of a javax.swing.Timer in the drawing program we will make a new Drawable that shows balls bouncing around inside of a little box. While it is not really needed at this point, we will also make the code that moves the balls around execute in parallel using parallel collection functionality. Here is the code for this new class.
package scalabook.drawing
import java.awt.{Graphics2D,Color}
import java.awt.geom._
import swing._
import event._
class DrawBouncingBalls(p:DrawTransform,drawing:Drawing) extends DrawLeaf {
val parent = p
private var propPanel:Component = null
private var (minSize, maxSize) = (0.01, 0.05)
private var balls = Vector.fill(20){
val size = minSize+math.random∗(maxSize-minSize)
new Ball(size+math.random∗(1-2∗size),size+math.random∗(1-2∗size),
(math.random-0.5)∗0.02,(math.random-0.5)∗0.02,size)
}
private case class Ball(x:Double,y:Double,vx:Double,vy:Double,size:Double)
private val timer = new javax.swing.Timer(100,Swing.ActionListener(e => {
balls = (for(Ball(x,y,vx,vy,s) <- balls par) yield {
var nvy = vy + 0.01 // gravity
var nvx = vx
var nx = x+nvx
var ny = y+nvy
if(nx-s<0.0) {
nx = 2∗s-nx
nvx = nvx.abs
} else if(nx+s>1.0) {
nx = 2.0-(nx+2∗s)
nvx = -nvx.abs
}
if(ny-s<0.0) {
ny = 2∗s-ny
nvy = nvy.abs
} else if(ny+s>1.0) {
ny = 2.0-(ny+2∗s)
nvy = -nvy.abs
}
Ball(nx,ny,nvx,nvy,s)
}).seq
drawing.refresh
}))
def draw(g:Graphics2D) {
g.setPaint(Color.black)
g.draw(new Rectangle2D.Double(0,0,100,100))
g.setPaint(Color.green)
for(Ball(x,y,_,_,s) <- balls) {
g.fill(new Ellipse2D.Double((x-s)∗100,(y-s)∗100,s∗200,s∗200))
}
}
def propertiesPanel() : Component = {
if(propPanel==null) {
propPanel = new BorderPanel {
layout += new GridPanel(1,1) {
val button = new Button("Start")
button.action = Action("Start"){
if(button.text == "Start") {
timer.start()
button.text="Stop"
} else {
timer.stop()
button.text="Start"
}
}
contents += button
} -> BorderPanel.Position.North
}
}
propPanel
}
override def toString = "Bouncing Balls"
}
The balls are represented by a case class called Ball. The box they are bouncing in goes from (0.0, 0.0) to (1.0, 1.0). The drawing scales that up by a factor of 100 so that it covers a reasonable range of pixels.
The properties panel includes a single button that controls the timer and alternates its text between "Start" and "Stop". The code to move the balls around is found in the timer itself, which is declared at the top of the class. Note the use of patterns on the case class to pull out values.
Currently this code does not have balls bouncing off of one another. That would add significant computation and potentially make the parallelism a real benefit. We will leave that as a task for a later chapter when we can talk about not just how to do it, but how to do it intelligently if the number of particles were to be very large.
21.9 End of Chapter Material
21.9.1 Summary of Concepts
- Multicore processors have become the norm and core counts are growing exponentially without increases in chip clock speed. This means that programs have to include parallelism to take full advantage of the hardware. Multithreading is on the primary ways to doing this.
- Through the Java libraries, Scala programs have access to basic thread operations. You can easily create instances of java.lang.Thread and start work running in the various threads.
- One of the main problems with threads is that they all access the same memory. That means that if different threads are mutating parts of the memory, you can have race conditions where the outcome of the computation depends on the details of thread handling.
- Another problem you run into with threads is that if you start pausing them to improve their cooperation, you run the risk of making a number of threads freeze up in a state called deadlock where they are all waiting around for the others to finish.
- The primary way of dealing with race conditions is through synchronization. Critical blocks of code where values are mutated can be synchronized. Only one thread can be executing code that is synchronized on a particular object at any given time. Unfortunately, synchronization is a bit slow and too much of it can lead to deadlock.
- Another way to control threads to help them work together is with wait and notifyAll. The wait method causes a thread to pause. It will stay paused until a notification wakes it up.
- The Thread class has other methods like sleep and yield that can be quite useful.
- There are many tasks that are common to a lot of parallel programs. For this reason, a concurrency library was added to Java in the java.util.concurrent package.
- Executors and ExecutorServices abstract away the task of picking a method for running a piece of code. There are some useful methods in Executors that will provide ExecutorService objects which behave in generally useful ways. Many of these allow for the reuse of threads as there is significant overhead in creating Thread objects.
- The Callable type allows you to run a task on an ExecutorService that gives you back a value. When such a task is submitted, you are given a Future object that will provide the result.
- The concurrency library includes a number of parallel data structures as well.
- The CyclicBarrier and CountDownLatch classes make it easy to have multiple threads pause at a point in the code until all threads have gotten there.
- An Exchanger can be used to pass a value between threads at some particular point.
- The BlockingQueue is a data structure that lets one group of threads exchange objects with another group of threads and blocks in situations when there is not space to put something or nothing is available.
- A Semaphore provides a way to control how many threads are working in a particular part of the code at any given time.
- The java.util.concurrent.atomic package provides classes for basic types that have operations which can not be interrupted. These often provide a simpler and more efficient approach to preventing race conditions than synchronization.
- The java.util.concurrent.locks package defines locks that can be used for synchronization type behaviors that can span beyond a single method call or code block.
- Scala makes certain types of parallelism simple with parallel collections. These collections have methods that automatically split the work across multiple threads. Calling par on a regular collection gives you a parallel version. Calling seq on the parallel version gives you back a sequential one.
- There is another parallel library in Scala for Actor-based parallelism. For our current purposes, it provides easy, Scala-style methods for creating threads using Actor.actor and Futures.future.
21.9.2 Exercises
- In the discussion of the parallel factorial and Amdahl’s law we concluded that the primary limitation in the code we had written for scaling was the final product. Using techniques from java.util.concurrent, write code to make that operation happen in parallel.
- A good way to make sure you understand parallelism is to work on implementing a number of different simple problems using each of the different techniques that were presented in this chapter. The problems you should solve are listed below. For each of them, try to write a solution using the following methods.
- Normal java.lang.Threads or calls to Actor.actor with synchronized and wait/notifyAll.
- Elements from java.util.concurrent such as ExecutorServices, thread-safe data structures, and atomic values.
- Scala parallel collections. (Note that this is is not flexible enough to handle all problems so only use it for those that work.)
For each solution that you write, you should do timing tests to see how the different solutions compare for speed using the highest core count machine you have access to. For speed comparisons, you should consider writing a sequential version as well. For most of these to be of interest for parallel, the inputs will need to be fairly large.
- (a) Find the minimum value in a sequence of Doubles.
- (b) Given a Seq[Int], find the value for which the following function returns the largest value.
def goldbach(num:Int):Int = {var ret = 0var n = numwhile(n>1) {n = if(n%2==1) 3∗n-1 else n/2ret += 1}ret} - (c) Matrix addition using two matrices stored as Array[Array[Double]].
- (d) Matrix multiplication using two matrices stored as Array[Array[Double]].
- (e) Find all occurrences of a substring in a given String.
21.9.3 Projects
As you would expect, all of the projects for this chapter have you adding multithreading to your project. How you do this depends a lot on the project. There are two aspects of this that are worth noting in general. First, you can not generally multithread drawing to the screen. That is because the graphics is being done by a single device. Often, drawing to different images in parallel will not help either because drawing to images often involves the graphics pipeline on your graphics card so it is a bottleneck, even when you have separate threads doing separate work on separate images.
The other thing to note is not to overdo multithreading. Spawning many threads with little work for each to do will only slow your program down. Spawning too many can even consume enough resources to bring your machine to its knees. It is easy to spawn threads with things like Actor.actor, but you need to think about what you are doing when you use it. Overuse of threading can also lead to race conditions that are extremely difficult to debug. Appropriate usage of the thread-safe collections from java.util.concurrent can help dramatically with that problem.
- Text adventures typically did not do anything unless the user entered a command. The code you have written at this point is probably the same. The call to readLine is blocking and nothing happens without that. This is not the case with a MUD. For one thing, there will be multiple players that could all be trying to do things at different rates. In addition, the other characters in a MUD have the ability to walk around even if the user is simply standing in one place doing nothing.
Now that you know how to multithread, you can change this behavior. You will have the logic for the game run in one thread and the task of collecting input happen in another. The game thread will be like a GUIs timer. It will run through updating everything that needs to be updated, then sleep for a while before doing it again. The updates of the other characters can just be random walks at this point though you should consider how you will add combat or other features as well. The update of the player will interact with the input reading thread in some thread-safe manner. Some of the collections from java.util.concurrent could come in handy for this.
The thread the takes user input will still block on readLine. When the user inputs a line, that line will be put into whatever you are using to pass information across so that the main game thread can get it and execute it the next time through. The input thread then loops around and does another readLine.
- Networking, like reading from and writing to a disk, can be a significant bottleneck. Unlike the disk though, it is possible that the bottleneck is not related to your machine. For this reason, there can be significant speed benefits to having multiple threads reading from the network all at once. If you are working on the web spider, this is exactly what you should do for this project. You can also set the stage for multiple threads processing data as well, in case that becomes a bottleneck.
To do this, you can basically make two pools of threads, one that reads data and another that processes the data. Over time you can balance the number of threads in each to get maximum performance. Data needs to be passed between these threads in a thread-safe manner. One or more java.util.concurrent.BlockingQueues would probably work well. As the data collecting threads pull down the data and get them into a form with minimal processing, they put their results on a queue. The analysis threads pull data off the queue and do the proper analysis on it. In the final version of this, the analysis will inevitably find more data that needs to be collected. That will be put on a different queue that the reading threads will pull from.
You can stick with pulled data from files for this project, though it is unlikely the threading will help in that situation or that you have a large enough data set. In the next two chapters we will introduce concepts that will make it easier to pull the data from the web or other network sources.
- If you are writing a networked game, you will be forced to put in multithreading to deal the networking. However, you can start preparing for that now. You can put in code to handle two players from the keyboard where the different players get messages from a single keyboard handler and a main thread runs the primary game logic. You might also be able to think of ways to split up the game logic across multiple threads.
- For a non-networked game, the threading will primarily be done to help with the computer-controlled entities in the game. Care must be taken to avoid race conditions, but you should look for intelligent ways to split up the work across different threads. This could include grouping active entities if they have complex decision-making needs. It could also be just breaking things up by type. Note that the second option generally does not scale to high core counts as well.
- If you are doing the Math worksheet problem, you have quite a few options for parallelism. Worksheets do not have to be linear. If one section of a worksheet does not depend on the results of another, they can be processed in parallel. In addition, complex calculations can often be done in parallel by working on different data values using different threads.
If you have not done so already, you should consider integrating code for formula parsing and evaluation like that from project 16.1 into this program. The fact that the String parsing evaluator written there is remarkably slow provides a motivation for trying to do multiple evaluations in separate threads.
- The Photoshop® project runs into some challenges with multithreading because most of the work that it is doing involves graphics and, as was described in the introduction to these projects, normal graphics does not generally benefit from multithreading. It is probably worth you spending a little bit of time to test this hypothesis though. You could render layers to separate BufferedImages using separate threads. If you make the scenes complex enough, you can really see if multithreading provides any benefit.
There are some other things that could be done which would definitely benefit from multithreading. The getRGB and setRGB methods on BufferedImage to not use normal graphics operations. They work with direct access to the memory behind the image. For this reason, any operations that you can do using only those methods will benefit from multithreading. An example of something that can be done this way is filters. Many effects that you might want to apply to an image can be done with only the Red, Green, Blue (RGB) values of a pixel and those around it.
Depending on what projects you did in the first half of the book, you might want to add some more complex and interesting elements to the things you can add to drawings. That could include fractals like the Mandebrot shown in this chapter, Julia sets, L-Systems, or even ray-tracing elements. All of those could benefit from some or all parts being done in parallel.
- The simulation workbench is also a plentiful area for parallelization because it is processor intensive and can be arranged in ways that do not conflict. This does not mean it is easy to do efficiently though. Using the simple gravity simulation, devise at least three different ways of calculating the forces in parallel, then do a speed comparison between those approaches and your original code.
1The low outlying points in 2008 and 2011 are chips specifically aimed at low-energy, mobile computing. This is why they have low transistor counts compared to other chips being made at the same time.
2High-end server chips had started doing this a few years earlier.
3Technically it could, but the odds of that happening are vanishingly small.
4The syntax shown here is not proper Scala code. We'll see how this type of thing should really be done in the following sections.
5Use of notify is typically discouraged because you have no control over which thread it will wake up. This has a tendency to lead to deadlock.
6The signature of the method is really void execute(Runnable command) in Java form.
7You must be careful when using a fixed thread pool if you add new tasks to the pool inside of other tasks. It is possible for the second task to be stuck waiting for the first to finish. If this happens and the first task has code to get the result of the second task you will get deadlock.
8Depending on your computer, suficiently large will be at least several tens of thousands.