
Direct Access Binary Files
Back in chapter 9 we learned about basic text files. These had the advantage of being simple. They were reasonably easy to program and the files themselves could be edited with a standard text editor. Unfortunately, they did not have any inherent meaning and they were very brittle to edit. Small mistakes could easily invalidate the whole file. These problems were corrected by using XML starting with chapter 14. Both flat text and XML have the downfall that they are slow and bloated in size. In these areas, XML is worse than flat text. To fix those problems we need to move in the opposite direction and go to binary files. Unfortunately, this move takes away the advantage that text and XML have that they can be read and edited easily with text editors. We saw how we could read and write in native binary in chapter 22 with the DataInputStream and DataOutputStream as well as how whole objects could be serialized to binary using ObjectInputStream and ObjectOutputStream.
In this chapter, we are going to take another step with binary files to make it so that they can be used like large arrays with the ability to access and read values at random locations. This makes many more things possible with files and is an essential part of applications that need to deal with extremely large data sets.
33.1 Random Access Files
Back in chapter 22 we focused on streams. The term stream matches their nature. Like water flowing by, data from a stream can be read as it goes by, but once it has gone by you can not bring it back. You also can not choose to just be at whatever position you want. For this capability we turn to a different class in the java.io package, RandomAccessFile. Looking at this class in the API will show you that it includes all the read methods from DataInputStream and the write methods from DataOutputStream. It is immediately clear that this one class gives you the ability to do both input and output in binary format. The real power of this class comes from the seek(pos:Long) method, which can jump to any location in a file. The partner of seek is getFilePointer():Long, which returns the current location in the file. Putting this all together means that you can jump around in a file and read or write data in any way that you want.
To create a new RandomAccessFile, you pass arguments of the file to open, either as a java.io.File or a String, and a mode:String. The mode specifies how that file is going to be accessed. It is only allowed to have one of the following values.
- "r" - Open the file for reading only. If this is used and any of the write methods are invoked, an IOException will be thrown.
- "rw" - Open the file for reading and writing. This mode will try to create a file if it does not exist.
- "rws" - Open the file for reading and writing with the additional requirement that calls that modify the file in any way synchronously go to the storage device. This will slow things down as it makes buffering of disk activity impossible, but is important for critical applications that need the file to be in a consistent configuration regardless of what happens to the application.
- "rwd" - Much like "rws", but only requires synchronization when the contents of the file are altered.1
If you use any other value for the mode an exception will be thrown. We will typically use "rw" as the mode so it will look like this.
val raf = new RandomAccessFile("binaryFile.bin","rw")
33.1.1 Fixed Record Length
The simplest usage of a binary file is with fixed length records. This is where you store data in blocks of the same size. This is fairly easy when your data is composed of a fixed number of fixed size elements like Int and Double. In that situation you simple add up the sizes of all the elements. Table 33.1 shows the sizes of the basic types in Scala in bytes written to a file. So if the record to be written was a point in 3-D space that has an integer value associated with it, you would write out three Doubles and one Int using a total of 3 ∗ 8 + 4 = 28 bytes.
This table shows how many bytes are written to disk for each of the basic value types using either DataOutputStream or RandomAccessFile.
Type |
Size in Bytes |
Byte |
1 |
Short |
2 |
Int |
4 |
Long |
8 |
Float |
4 |
Double |
8 |
Boolean |
1 |
Char |
2 |
Many types of data will make the process of determining a length a bit more complex. For example, table 33.1 is missing the String type. That is because strings will take up different amounts of space based on how long they are. If you want to use a fixed length record file with records that include strings, you have to determine a maximum length that you will allow your string to be, then write it out as a sequence of Char or Byte. Which you pick will depend on whether you expect to have characters outside of standard English in the text. Normal English characters are part of lower ASCII which fits completely in a Byte. If the application is going to be internationalized or include special symbols from Unicode, you should probably stick with a Char. You can use the getBytes():Array[Byte] method of String if you choose to use the Byte approach. In your code you can decide how to deal with strings that are too long, whether you want to throw an exception or silently truncate them. Either way, you have to enforce a maximum size, make sure that you are able to read back in what you write out, and never write data beyond the record boundary.
Records that contain collections have to be treated much like Strings. You pick a maximum number of elements that are going to be stored to file. Calculate the size of an element and multiply by the maximum number you will store to determine the size contribution of the collection to the total record size.
To apply this idea, we will write a class that uses a fixed length record random access file as the backing for a mutable.IndexedSeq so that data can be preserved from one run to the next. If you attach to the same file in separate runs you will automatically get access to the same data. Using a file also allows you to have an extremely large collection without consuming that much memory. The downside is that accessing this collection will be significantly slower.
package scalabook.adt
import collection.mutable
import java.io.{File, DataOutput, DataInput, RandomAccessFile}
class FixedRecordSeq[A](
file:File,
recordLength:Int,
reader:DataInput => A,
writer:(DataOutput,A) => Unit) extends mutable.IndexedSeq[A] {
private val raf = new RandomAccessFile(file,"rw")
def apply(index:Int):A = {
raf.seek(recordLength∗index)
reader(raf)
}
def update(index:Int, a:A) {
raf.seek(recordLength∗index)
writer(raf,a)
}
def length:Int = (raf.length()/recordLength).toInt
def close() = raf.close()
}
This class inherits from mutable.IndexedSeq, it has fundamentally different behavior for the update method. Assigning out of bounds on this collection does not throw an exception. Instead, it grows the collection to the size of that index. This does not technically contradict the API documentation for the supertype, but it is something that users should be aware of.
The apply method seeks to the position in the file given by the index times the record length, then does a read. This simplicity is the real advantage of fixed record length files. Given an index, a simple mathematical operation gives the location of the data in the file. The update method is equally simple with a call to seek followed by a call of the write function.
To make it clear how this class would be used we can look at some unit tests for it.
package test.scalabook.adt
import org.junit._
import org.junit.Assert._
import scalabook.adt._
import java.io.{File, DataInput, DataOutput}
class TestFixedRecordSeq {
private var file:File = null
private case class PointRec(x:Double, y:Double, z:Double, d:Int)
private case class StudentRec(first:String, last:String, grades:List[Int])
@Before def setFile {
file = new File("TextFile.bin")
file.deleteOnExit()
if(file.exists()) file.delete()
}
@Test def emptyStart {
val frs = new FixedRecordSeq[Int](file, 4, din => din.readInt(), (dout,i) =>
dout.writeInt(i))
assertTrue(frs.length==0)
}
@Test def write4 {
val frs = new FixedRecordSeq[Int](file, 4, din => din.readInt(), (dout,i) =>
dout.writeInt(i))
frs(0) = 3
frs(1) = 8
frs(2) = 2
frs(3) = 9
assertEquals(4, frs.length)
assertEquals(3, frs(0))
assertEquals(8, frs(1))
assertEquals(2, frs(2))
assertEquals(9, frs(3))
}
@Test def write100 {
val frs = new FixedRecordSeq[Double](file, 8, din => din.readDouble(), (dout,d) =>
dout.writeDouble(d))
val nums = Array.fill(100)(math.random)
for(i <- nums.indices) frs(i)=nums(i)
assertEquals(nums.length,frs.length)
for(i <- nums.indices) assertEquals(nums(i),frs(i),0)
}
private def readPoint(din:DataInput):PointRec = {
new PointRec(din.readDouble(),din.readDouble(),din.readDouble(),din.readInt())
}
private def writePoint(dout:DataOutput,p:PointRec) {
dout.writeDouble(p.x)
dout.writeDouble(p.y)
dout.writeDouble(p.z)
dout.writeInt(p.d)
}
@Test def writePoints {
val frs = new FixedRecordSeq[PointRec](file, 3∗8+4, readPoint, writePoint)
val pnts = Array.fill(10)(new PointRec(math.random, math.random, math.random,
util.Random.nextInt))
for(i <- pnts.indices) frs(i) = pnts(i)
assertEquals(pnts.length,frs.length)
for(i <- pnts.indices) assertEquals(pnts(i),frs(i))
}
@Test def rewritePoints {
val frs = new FixedRecordSeq[PointRec](file, 3∗8+4, readPoint, writePoint)
val pnts = Array.fill(10)(new PointRec(math.random, math.random, math.random,
util.Random.nextInt))
for(i <- pnts.indices) frs(i) = pnts(i)
assertEquals(pnts.length,frs.length)
for(i <- pnts.indices) assertEquals(pnts(i),frs(i))
for(i <- 0 until pnts.length/2) {
val index = util.Random.nextInt(pnts.length)
pnts(index) = new PointRec(math.random, math.random, math.random,
util.Random.nextInt)
frs(index) = pnts(index)
}
for(i <- pnts.indices) assertEquals(pnts(i),frs(i))
}
private def readStudent(din:DataInput):StudentRec = {
val buf = new Array[Byte](20)
din.readFully(buf)
val first = new String(buf.takeWhile(_>0))
din.readFully(buf)
val last = new String(buf.takeWhile(_>0))
val grades = List.fill(10)(din.readInt()).filter(_ > Int.MinValue)
new StudentRec(first,last,grades)
}
private def writeStudent(dout:DataOutput,s:StudentRec) {
dout.write(s.first.take(20).getBytes().padTo(20,0.toByte))
dout.write(s.last.take(20).getBytes().padTo(20,0.toByte))
s.grades.padTo(10,Int.MinValue).foreach(dout.writeInt)
}
@Test def writeStudents {
val frs = new FixedRecordSeq[StudentRec](file, 20+20+4∗10, readStudent,
writeStudent)
val students = Array.fill(100){
val first = Array.fill(util.Random.nextInt(15))
(('a'+util.Random.nextInt(26)).toChar).mkString
val last = Array.fill(util.Random.nextInt(15))
(('a'+util.Random.nextInt(26)).toChar).mkString
val grades = List.fill(util.Random.nextInt(5)+6) (60+util.Random.nextInt(40))
new StudentRec(first,last,grades)
}
for(i <- students.indices) frs(i) = students(i)
assertEquals(students.length,frs.length)
for(i <- students.indices) assertEquals(students(i),frs(i))
}
@Test def writeStudentsLong {
val frs = new FixedRecordSeq[StudentRec](file, 20+20+4∗10, readStudent,
writeStudent)
val students = Array.fill(100){
val first = Array.fill(10+util.Random.nextInt(15))
(('a'+util.Random.nextInt(26)).toChar).mkString
val last = Array.fill(10+util.Random.nextInt(15))
(('a'+util.Random.nextInt(26)).toChar).mkString
val grades = List.fill(util.Random.nextInt(5)+6) (60+util.Random.nextInt(40))
new StudentRec(first,last,grades)
}
for(i <- students.indices) frs(i) = students(i)
assertEquals(students.length,frs.length)
for(i <- students.indices) {
if(students(i).first.length>20 || students(i).last.length>20) {
assertEquals(students(i).copy(first=students(i).first.take(20),
last=students(i).last.take(20)), frs(i))
} else {
assertEquals(students(i),frs(i))
}
}
}
}
The first tests work with simple Ints. The others work with two different case classes. The first case class, PointRec, has the structure described above with three Doubles and an Int. The task of reading and writing the Int type is so simple that function literals can be used there. For the case classes, helper functions were used. The ones for PointRec are both simple and straightforward.
The second case class, StudentRec, includes two Strings and a List[Int]. Having three elements that all have variable sizes is pretty much a worst case scenario for a fixed record length file. The read and write methods determine how the records will be truncated. In this case, both strings are truncated to 20 characters and the list of grades is truncated to 10 grades. When writing, anything shorter than that, the extra spots are padded with placeholders to complete the record. The last test includes strings that are longer than 20 characters to make sure that the truncation works properly.
33.1.2 Indexed Variable Record Length
A bit more work must be done if it is not possible to settle on a single fixed record length. There are a few reasons that you might run into this. One is that you can not afford to lose any data and you can not put any safe upper boundary on the size of some part of the record. A second is that you can not lose data and the average case is much smaller than the maximum and you either can not or are unwilling to waste the space that you would have to if you used a fixed record length.
In these situations you have to use a variable record length. The problem with this is that you can not simply calculate the potion in the file to go and read the nth element. One way to deal with this is to keep a separate index that has fixed length records which gives locations for the variable length record data. We will do this, and to keep things as simple as possible, we will put the index values in a separate file. Here is a sample implementation of such a sequence. It is built very much like the fixed record length version except that instead of a record size there is a second file passed in.
package scalabook.adt
import collection.mutable
import java.io._
class VariableRecordSeq[A](
index:File,
data:File,
reader:DataInput => A,
writer:(DataOutput,A) => Unit) extends mutable.IndexedSeq[A] {
private val indexFile = new RandomAccessFile(index,"rw")
private val dataFile = new RandomAccessFile(data,"rw")
def apply(index:Int):A = {
indexFile.seek(12∗index)
val pos = indexFile.readLong()
dataFile.seek(pos)
reader(dataFile)
}
def update(index:Int, a:A) {
val baos = new ByteArrayOutputStream()
val dos = new DataOutputStream(baos)
writer(dos,a)
val outData = baos.toByteArray()
val (pos,len) = if(index<length) {
indexFile.seek(12∗index)
val p = indexFile.readLong()
val l = indexFile.readInt()
if(baos.size()<=l) (p,l) else (dataFile.length(),outData.length)
} else (dataFile.length(),outData.length)
dataFile.seek(pos)
dataFile.write(outData)
indexFile.seek(12∗index)
indexFile.writeLong(pos)
indexFile.writeInt(len)
}
def length:Int = (indexFile.length()/12).toInt
def close() = {
indexFile.close()
dataFile.close()
}
}
Using an index file makes the apply method a bit more complex. It starts with a seek in the index file and a read of the position of where the data is in the main data file. That value is then passed to a seek on the data file and the value we want is read from that file. You can see from this code that the index file is basically a fixed record length file with a record length of 12. The value of 12 comes from the fact that we are storing both a Long for the position in the data file and an Int for the length of the data record in that file. Storing the length is not required, but it allows us to make the update a bit more efficient in how it stores things in the data file.
Most of the effort for using variable record length files goes into the update method. When a new value is written to file, if it fits in the space of the old value, it should be written in that same space. If it is a completely new record, or if the new value needs more space than the old one, the easiest way to deal with this is to put it at the end of the data file. These criteria are easy to describe, but they have one significant challenge, you have to know the length of what will be written before it is written to file. What is more, we really do not want to force the user of this class to have to pass in an additional function that calculates the size of a record. To get get around this, the update method makes us of a ByteArrayOutputStream. This is an OutputStream that collects everything that is written to it in an Array[Byte]. This is wrapped in a DataOutputStream and passed to the writer function before anything else is done.
Doing this at the beginning of update allows us to get an array of bytes that we need to write to the data file without having an extra function for size or writing to the real data file. After this a little logic is performed to see if the data can be written over an old value or if it needs to go at the end of the file. If this is a new record, or the length of outData is longer than the length of the space in the data file, it has to be put at the end of the data file and the length is the length of this output. Otherwise it goes at the old location and we use the old length because that is the amount of space we can safely use there.
The update method ends by jumping to the proper location in the data file and writing the array out to file, then jumping to the correct position in the index file and writing the position and length there. This code will work with the same test code as the fixed record length version with only a few changes to readStudent, writeStudent, and the last test. There is no longer a reason to cut data down or pad things in this version. Here is the modified code with a stronger version of the last test to make certain the changing records works.
private def readStudent(din:DataInput):StudentRec = {
val first = din.readUTF()
val last = din.readUTF()
val num = din.readInt()
val grades = List.fill(num)(din.readInt())
new StudentRec(first,last,grades)
}
private def writeStudent(dout:DataOutput,s:StudentRec) {
dout.writeUTF(s.first)
dout.writeUTF(s.last)
dout.writeInt(s.grades.length)
s.grades.foreach(dout.writeInt)
}
@Test def rewriteStudents {
val frs = new VariableRecordSeq[StudentRec](iFile, dFile, readStudent,
writeStudent)
val students = Array.fill(100){
val first = Array.fill(10+util.Random.nextInt(15))
(('a'+util.Random.nextInt(26)).toChar).mkString
val last = Array.fill(10+util.Random.nextInt(15))
(('a'+util.Random.nextInt(26)).toChar).mkString
val grades = List.fill(util.Random.nextInt(5)+6) (60+util.Random.nextInt(40))
new StudentRec(first,last,grades)
}
for(i <- students.indices) frs(i) = students(i)
assertEquals(students.length,frs.length)
for(i <- students.indices) assertEquals(students(i),frs(i))
for(i <- 0 until students.length/2) {
val index = util.Random.nextInt(students.length)
students(index) = {
val first = Array.fill(10+util.Random.nextInt(15))
(('a'+util.Random.nextInt(26)).toChar).mkString
val last = Array.fill(10+util.Random.nextInt(15))
(('a'+util.Random.nextInt(26)).toChar).mkString
val grades = List.fill(util.Random.nextInt(5)+6)
(60+util.Random.nextInt(40))
new StudentRec(first,last,grades)
}
frs(index) = students(index)
}
for(i <- students.indices) assertEquals(students(i),frs(i))
}
Notice that this code uses readUTF and writeUTF. We could not do this with the fixed record length file because the number of bytes it writes to file can vary by string contents, not just length. This freedom to use things that we do not know the exact size of can be quite useful. With a little modification, this class could be changed to work with serializable objects. We do not have strong control over the number of bytes written when an object is serialized, but using this approach that is not a problem.
This code does have a weakness though. Every time you update a record with a longer record, the old position in the data file becomes wasted space. Nothing will ever be written there again. Over time, this wasted space can build up and become problematic. To get around that weakness, you can add another method that will build a new data file without the gaps and get rid of the old one. This is left as an exercise for the reader.
33.2 Linked Structures in Files
The two file-backed sequences that we just wrote behave like arrays. They have fast direct access, but trying to delete from or insert to any location other than the middle will be very inefficient. This discussion should remind you of a similar one in chapter 25 that motivated our initial creation of a linked list. We now want to do that same thing, but in a file. That way we can have the benefits of data retention between runs and large data sets along with the ability for inserts and deletes.
When we built the linked list in memory, the links were created by references from one node to another. The nature of those references is not explicit in Scala. However, it is likely that they are stored as addresses in memory. Languages like C and C++ explicitly expose that detail in the form of constructs called pointers. A pointer stores an address in memory, and allows mathematical operations on it that move the pointer forward or backward through the memory. The languages that expose pointers are, in many ways, ideal for binary files and random access. This is because they allow direct copies of memory to and from a disk. For most values, this is ideal and highly efficient. It does not work at all for pointers. Pointers are attached to memory and do not have meaning when they are separated from the memory of the execution of the program. The addresses of values will change from one run of a program to another and there is no simple way to go from an address in memory to another location in a file to recover the meaning of the link. For this reason, pointers have to be replaced with something that keeps a meaning in the file. The same is true of references.
Whether it is referred to as a pointer or a reference, the equivalent in a file is a position or something roughly equivalent to it. Either one would be stored as an integer value. If it were a true position in the file, it should probably be stored as a Long.
There is another detail when doing a linked list, or other linked structure, that we were able to ignore when working in memory, but which becomes fairly significant when we are responsible for dealing with things on our own in a file. The detail is what to do about space in the file that was part of a node that has been deleted. A very sloppy implementation could ignore this and always add new records to the end of the file. Such an implementation would require an extra function to compact the file that would need to be called fairly often. A much more efficient approach is to keep track of those places in the file using a separate linked list that we will call the "free list". The name comes from the fact that it is a linked list of nodes that are free to be used again.
Putting an array into a file is quite straightforward. That is why the code for the fixed record length sequence was so simple. Doing the same for a linked list requires a bit more planning as the linked list needs to keep track of certain information. Think back to our singly-linked list implementation in chapter 25 and the values it stored. It included a head reference, a tail reference, and a length. Our file version will need those as well as the head of the free list. These values will be written at the front of the file. After that will be the nodes, each having a next position at the beginning. This format is drawn out in figure 33.1.

The binary file holding the linked list has the following format. The beginning of the file is a header with four values written as Longs. They are the position of the head node, the position of the tail node, the number of nodes, and the position of the first free node.
To take advantage of the functionality of a linked list, the code will implement the Buffer trait. To make things a bit simpler, it will assume a fixed record size. The class keeps a single RandomAccessFile as well as variable to store the current head, tail, length, and first free position. These variables are not directly accessed. Instead, there are methods for getting and setting each. The setters include code that seeks to the proper part of the beginning of the file and writes the new value to the file. This way the variables and the contents of the file should always agree. There is also a method to get the position of a new node. If there are no free nodes, it returns the end of the file. Otherwise it will return the first free node, but before doing that it jumps to the node, reads its next reference, and stores that as the new firstFree.
package scalabook.adt
import collection.mutable
import java.io.{File, DataOutput, DataInput, RandomAccessFile}
class FixedRecordList[A](
file:File,
reader:DataInput => A,
writer:(DataOutput,A) => Unit) extends mutable.Buffer[A] {
private val raf = new RandomAccessFile(file,"rw")
private var (localHead,localTail,localLen,localFirstFree) = {
if(raf.length()>=3∗8) {
raf.seek(0)
val h = raf.readLong()
val t = raf.readLong()
val l = raf.readLong()
val ff = raf.readLong()
(h,t,l,ff)
} else {
raf.seek(0)
raf.writeLong(-1)
raf.writeLong(-1)
raf.writeLong(0)
raf.writeLong(-1)
(-1L,-1L,0L,-1L)
}
}
private def lhead:Long = localHead
private def lhead_=(h:Long) {
raf.seek(0)
raf.writeLong(h)
localHead = h
}
private def length_=(len:Long) {
raf.seek(8∗2)
raf.writeLong(len)
localLen = len
}
private def ltail:Long = localTail
private def ltail_=(t:Long) {
raf.seek(8)
raf.writeLong(t)
localTail = t
}
private def firstFree:Long = localFirstFree
private def firstFree_=(ff:Long) {
raf.seek(3∗8)
raf.writeLong(ff)
localFirstFree = ff
}
private def newNodePosition:Long = if(firstFree == -1L) raf.length else {
val ff = firstFree
raf.seek(ff)
firstFree = raf.readLong()
ff
}
def +=(elem:A) = {
val npos = newNodePosition
raf.seek(npos)
raf.writeLong(-1L)
writer(raf,elem)
if(lhead == -1L) {
lhead = npos
} else {
raf.seek(ltail)
raf.writeLong(npos)
}
ltail = npos
length += 1
this
}
def +=:(elem:A) = {
val npos = newNodePosition
raf.seek(npos)
raf.writeLong(lhead)
writer(raf,elem)
lhead = npos
if(ltail == -1L) ltail = npos
length += 1
this
}
def apply(n:Int):A = {
if(n>=length) throw new IllegalArgumentException("Requested index "+n+
" of "+length)
var i = 0
var pos = lhead
while(i<=n) {
raf.seek(pos)
pos = raf.readLong()
i += 1
}
reader(raf)
}
def clear() {
raf.seek(ltail)
raf.writeLong(localFirstFree)
localFirstFree = lhead
lhead = -1
ltail = -1
length = 0
}
def insertAll(n:Int, elems:Traversable[A]) {
if(n>length) throw new IllegalArgumentException("Insert at index "+n+
" of "+length)
var i = 0
var (prev,next) = if(n==0) (-1L,lhead) else {
var (pp,nn) = (lhead,-1L)
while(i<n) {
raf.seek(pp)
if(i<n-1) pp = raf.readLong()
else nn = raf.readLong()
i += 1
}
(pp,nn)
}
if(prev != -1L) raf.seek(prev)
for(elem <- elems) {
val npos = newNodePosition
if(prev == -1L) {
lhead = npos
prev = npos
} else raf.writeLong(npos)
raf.seek(npos+8)
writer(raf,elem)
raf.seek(npos)
}
if(next == -1L) ltail = raf.getFilePointer()
raf.writeLong(next)
length += elems.size
}
def iterator = new Iterator[A] {
var pos = lhead
def hasNext = lhead > -1L
def next = {
raf.seek(pos)
pos = raf.readLong()
reader(raf)
}
}
def length:Int = localLen.toInt
def remove(n:Int):A = {
if(n>=length) throw new IllegalArgumentException("Remove index "+n+
"of "+length)
var i = 0
var pos = lhead
var last,next = -1L
while(i<=n) {
raf.seek(pos)
if(i==n) {
next = raf.readLong()
} else {
last = pos
pos = raf.readLong()
}
i += 1
}
val ret = reader(raf)
if(last == -1L) {
lhead = next
} else {
raf.seek(last)
raf.writeLong(next)
}
if(pos == ltail) {
ltail = last
}
length -= 1
ret
}
def update(n:Int, elem:A) {
if(n>=length) throw new IllegalArgumentException("Updating index "+n+
" of "+length)
var i = 0
var pos = lhead while(i<=n) {
raf.seek(pos)
pos = raf.readLong()
i += 1
}
writer(raf,elem)
}
def close() = raf.close()
}
Going through this code, you will notice that there are many places that have a call to seek followed by either a readLong or a writeLong. This is because the first eight bytes in each node are used to store the position of the next value.
As with a normal linked list, this code has quite a few while loops that run through the list counting. It also has the overhead of boundary cases that deal with the head and tail references. Those special cases, combined with the fact that file access is more verbose than accessing memory makes this code fairly long though the length is largely made up of short, simple lines.
We stated above that this code uses a fixed record length, but there is no record length passed in. The way this code works, it does not have to know the length, but it will fail if a fixed length is not used for all nodes. The assumption of a fixed length is made in the fact that this code assumes that any freed node can be used for any new data. This assumption breaks down if different pieces of data have different lengths. To make this code work with different length records requires three changes. First, each node must keep a length in bytes in addition to the next reference. Second, the writer must be called using a ByteArrayOutputStream as was done earlier. Third, the newNodePosition must be passed the size that is required and it will have to walk the free list until it finds a node that is big enough. If none are found, it will use the end of the file, even when nodes have been made free. Making these alternations is left as an exercise for the reader.
B-Trees
The file-based linked list works, but it is, in many ways, a horrible way to do things in a file. Disk reads and writes are extremely slow, especially done in small pieces. Disks work much better if you read a large chunk at a time. All the seeking in this code, and the fact that over time the list is likely to evolve such that consecutive nodes are very distant in the file will cause very poor performance and likely make this unusable for most applications.
To deal with the special requirements of disk access, certain data structures have been developed that are specifically designed to access large chunks of data at a time and to do few such accesses. One of the easiest such structures is the B-tree, which was originally described in 1972. [3] The B-tree is an extension on the idea of a Binary Search Tree (BST). To make it more efficient for disk access, each node can hold multiple records and for non-leaves, there are children nodes not only for lower and higher keys, but also between each of the records. A sample B-tree is shown in figure 33.2.
Unlike a normal BST, a B-tree is always balanced. In addition, new nodes are added higher up the tree, instead of at the leaves. By default, a new record is added in a leaf. As long as that leaf still has spots left, that new record is inserted in the proper location and the add is done. This is illustrated in figure 33.3-A. If the leaf node where the new record belongs is already full, then a new node has to be made. This is done by splitting that one node into two, pushing the median record up into the parent, and putting links to the two children nodes on either side. This is shown in figure 33.3-B.
Real B-trees will typically have many more records per node than what is drawn in these figures. The fact that their average splitting factor is very high means that they can hold an extremely large number of records in very few levels. To see this, consider a B-tree with 200 records per node that is roughly half filled. That means that each node has roughly 100 records in it and each internal node has roughly 100 children.2 So the top level would hold 100 records. The next would hold 10,000. The next would hold 1,000,000. This is still O(log(n)) behavior, but it is technically O(log100(n)), which grows very slowly. A tree with a billion records will only barely crack five levels. This is significant, because each level winds up being a seek and a read when trying to find records.

The nodes of a B-tree can each store a certain number of records. The number of records is selected to match an optimal size for disk reads and writes. Non-leaf nodes have references to children at the beginning, end, and between each record. The records in a node are sorted by a key. In addition, the nodes in children have to have key values that fall between the keys of the records they are between, or just below and above for the beginning and end children. B-trees are always balanced and require few disk accesses to find a record, but they do potentially waste some space.
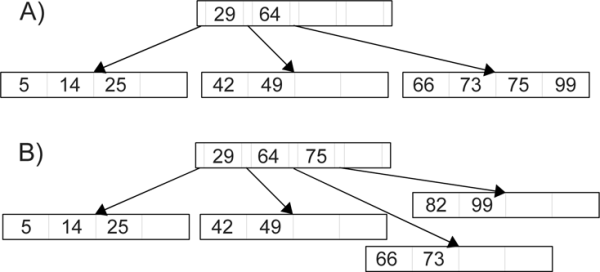
Part A on the top shows the tree from figure 33.2 with the addition of a record whose key value is 75. The 75 is simply placed in sorted order in a leaf because there is still space left in that node. For part B of this figure, a record with a key value of 82 has been added. It would go right after the 75 record, but there is no more space in that node. Of the five records that would be in the node, the 75 is the median so it is moved into the parent and the other records are split into two different nodes. This process can propagate to higher levels in the tree if the parent is also full. A new level is created when the root node fills and has to split.
33.3 End of Chapter Material
33.3.1 Summary of Concepts
- Direct access, or random access files allow you to jump from one position to another, reading and writing.
- This functionality allows them to be used as array-like data structures with extremely large capacities.
- It is easiest to deal with files where all records have the same length as that allows us to easily calculate where any given record is in the file.
- Variable record lengths can be used, but they require more bookkeeping. This is typically done by having a fixed record length index that tells us the position of elements in the data file.
- We can mimic references using file positions to create linked data structures in files.
- Putting header information in a file allows us to keep track of things like the head or tail of a list, or the root of a tree.
- Additional information can be stored with each record to include references to other nodes in the data structure.
- While we can code a linked list in a direct access file, it is very inefficient because it requires a large number of disk accesses.
- Other linked structures exist specifically to get around the problem of slow access times. The B-tree is an example of one.
33.3.2 Exercises
- Write code to do speed comparisons of different file-backed sequences (array-like and linked list-like) to one another and compare them to memory-backed sequences.
- Write a compact method for the VariableRecordSeq. This method should be called to eliminate blank space in the data file. It does this by creating a new data file and moving records from the old one to the new one, one at a time, updating the index for the new positions appropriately. Once this is done, the old data file can be deleted and the name of the new one can be changed to match the original name.
- Make appropriate changes to the FixedRecordList to make a VariableRecordList.
- Write a linearize method for the linked list that will create a new file where all the nodes have been reordered to the order they appear in the list and all free nodes have been removed.
- Write a B-tree that only works in memory.
- Convert your B-tree from the previous exercise so that it works using disk access.
33.3.3 Projects
All of the projects in this chapter have you writing direct access binary versions of some of your saved files for your project.
- One of the things you have probably noticed if you are working on the MUD project is that saving individual players out to disk either requires separate files for each player, leading to a very large number of files, or it requires writing out all all the players just to save one. A direct access binary file can fix this. You might have to make some sacrifices, such as specifying a maximum number of items that can be saved. Write code to store players in a fixed length record and change the saving and loading code so that only single records are read or written as needed.
- Depending on what data you are storing, there might be very different things that you put in a direct access binary file for the Web Spider. Things like box scores can be made much more efficient using a binary format instead of text. Images will be a bit more challenging. If you really want a challenge, try to put your data in a B-tree. The web spider is a perfect example of a project that uses enough data that having things stored on disk in a B-tree instead of in memory can be very beneficial.
- If you have a graphical game that has different boards or screens, edit the storage so that it uses a direct access file to efficiently get to any screen in O(1) time.
- The math worksheet project can benefit from saving the worksheet in a binary file so that saving can be done on individual sections of the worksheet, instead of the whole thing.
- If you are doing the Photoshop® project, you can put layers in variable-sized records of a binary file. Note that you can not use default serialization for images so you will likely have to write some form of custom serialization.
- If you are doing the simulation workbench, you should make it so that large particle simulations write out using a custom binary format where the data for each particle is written out as the proper number of binary Doubles. This will allow you to write tools for reading things in that only read specific particles.
1Files also have metadata associated with them. The "rws" mode will force synchronization when either metadata or contents are changed.
2The rough approximation of this argument allows us to ignore the fact that a node with 100 records would have 101 children.