Portia is a visual web scraping tool available in the Scrapinghub platform: https://github.com/scrapinghub/portia.
Portia is a tool that allows you to visually scrape websites annotating a web page to identify the data you wish to extract. Portia will understand how to scrape data from similar pages based on these annotations.
You can run and deploy Portia in your local machine through some environments such as Docker, Vagrant, and Ubuntu virtual machine following the official documentation: https://portia.readthedocs.io/en/latest/installation.html. Also, you can access this Portia service at https://portia.scrapinghub.com, following is the screenshot to run and deploy Portia:

Portia has the capacity to find similar items for each page. This process will continue until it has finished checking every page or has reached the limit of your Scrapinghub plan.
The first step is set up the website that you want to scrape in the Portia site:

Next, you need to create a new spider:

Portia has the capacity to add the page's URL as a start page automatically. The crawling process will start with start pages and Portia will visit them to find more links when the spider is executed.
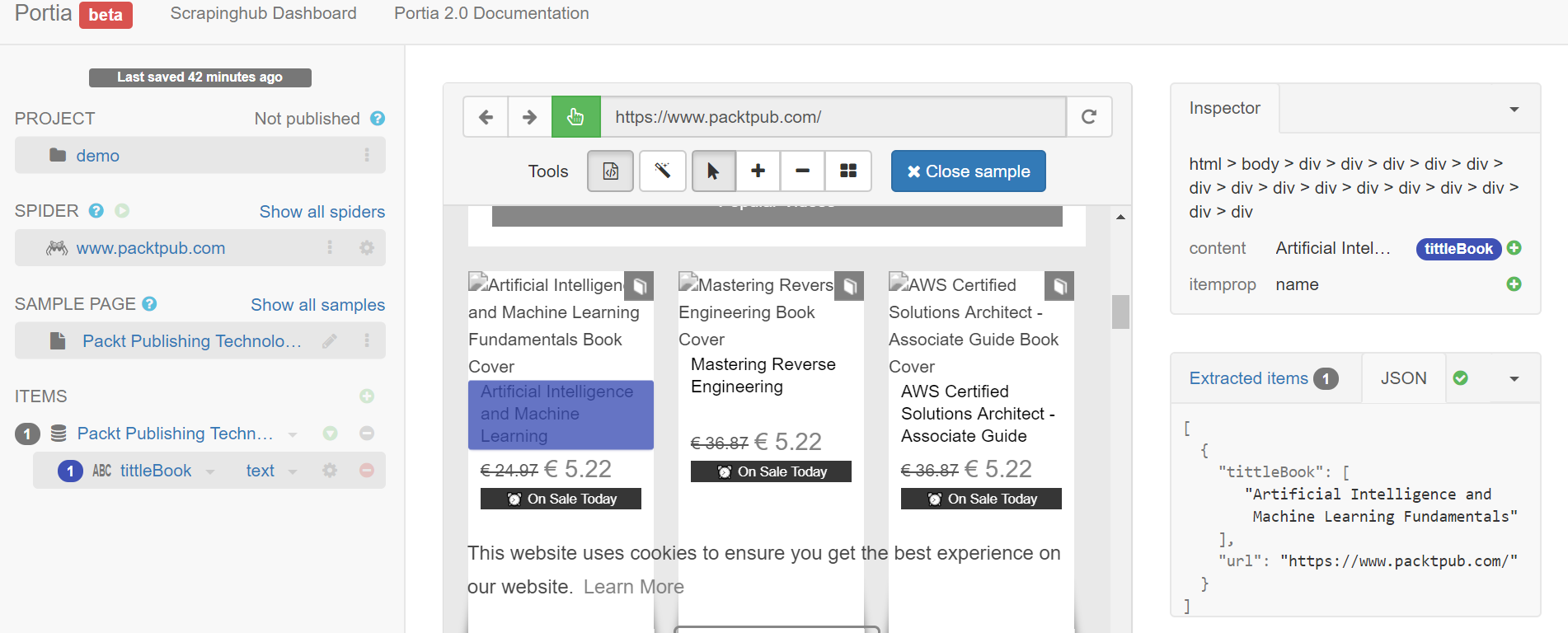
In this example, we are extracting the titles of the books from the packtpub.com domain: