
Scrapy allows us to recursively scan the contents of a website and apply a set of rules on said contents to extract information that may be useful to us. These are the main architecture elements:
- Interpreter: Allows quick tests, as well as the creation of projects with a defined structure.
- Spiders: Code routines that are responsible for making HTTP requests to a list of domains given by the client and applies rules in the form of regular expressions or XPath on the content returned from HTTP requests.
- XPath expressions: With XPath expressions, we can get to a fairly detailed level of the information we want to extract. For example, if we want to extract the download links from a page, it is enough to obtain the XPath expression of the element and access the href attribute.
- Items: Scrapy uses a mechanism based on XPath expressions called Xpath selectors. These selectors are responsible for applying XPath rules defined by the developer and composing Python objects that contain the information extracted. The items are such as containers of information and allow us to store the information that the rules that we apply return on the contents that we are obtaining.
In this image, you can see an overview of the Scrapy architecture:
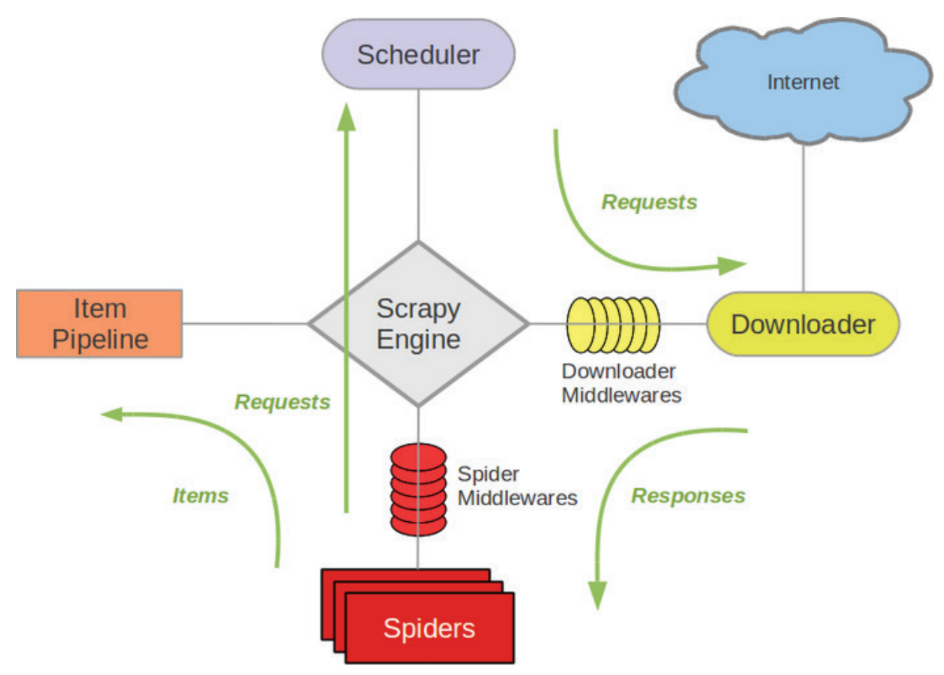
As you can see in the preceding image, the spiders use the items to pass the data to the item. Scrapy can have several spiders—the spiders do the requests, which are scheduled in the scheduler, and these are what make the requests to the server. Finally, when the server responds, these responses are sent back to the spiders, so that the spider is fed back with each request.