
We've discussed working directly with the S3 REST API, and this has given us some useful techniques that will allow us to program similar APIs in the future.
In many cases, this will be the only way in which we can interact with a web API. However, some APIs, including AWS, have ready-to-use packages that expose the functionality of the service without having to deal with the complexities of the HTTP API. These packages generally make the code cleaner and simpler, and they should be used for production work if they're available.
The AWS package for connecting from Python is called Boto3. The boto3 package is available in PyPI, so we can install it with pip and with the following command:
pip install boto3
Now, open a Python shell and let's try it out. We need to connect to the service first:
>>> import boto3
>>> s3 = boto3.client('s3')
Use the following to display a list of the buckets:
>>> buckets = s3.list_buckets()
>>> buckets = [bucket['Name'] for bucket in response['Buckets']]
Now, let's create a bucket:
>>> s3.create_bucket('mybucket’)
This creates the bucket in the default standard US region. We can supply a different region, as shown here:
>>> conn.create_bucket('mybucket', CreateBucketConfiguration={'LocationConstraint': 'eu-west-2'})
We can see a list of acceptable region names in the official documentation at https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html#S3.Client.create_bucket.
In this screenshot, we can see the documentation for the create_bucket function and the parameters we can use:
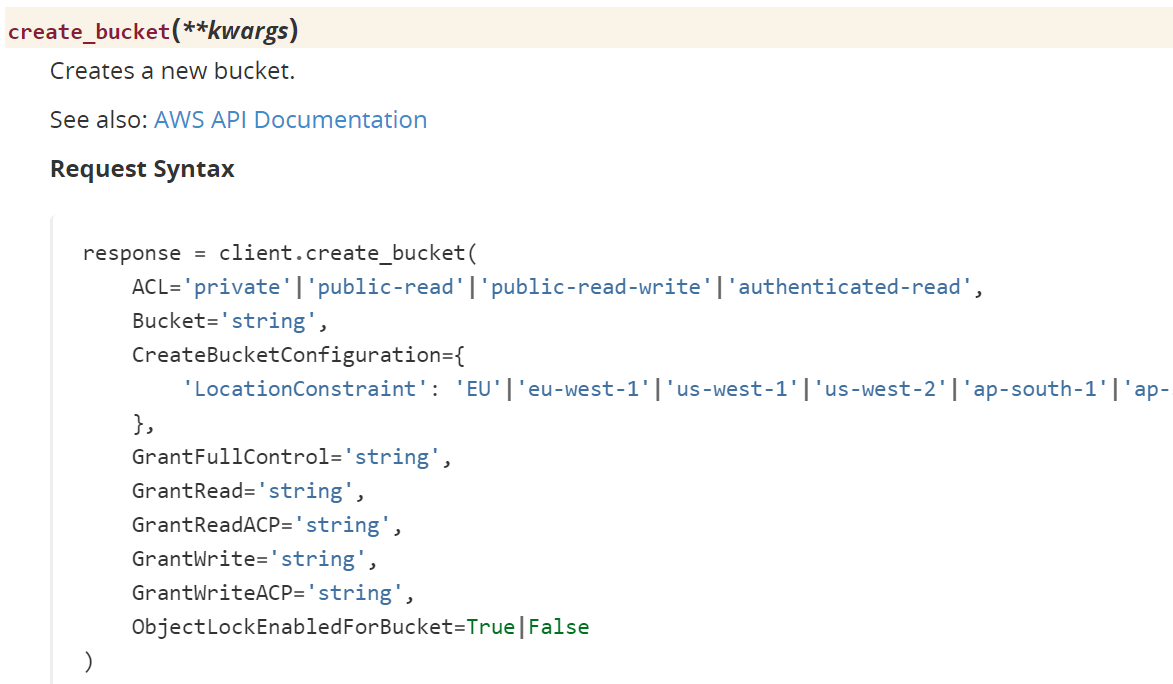
To upload a file, we can use the upload_file() method from the S3 object, passing as parameters the bucket name and the filename for upload. To download a file, first we need to get a reference to the bucket from which we want to extract the file, and then we can use the download_file() method, passing as parameter the file we want to download and the name of the file when it is stored in your system folder.
In the following script we can see how we implement two methods for doing this tasks. You can find the following code in the s3_upload_download_file_boto.py file:
import sys
import boto3
import botocore
# Create an S3 client
s3 = boto3.client('s3')
# Create an S3 bucket
s3_bucket = boto3.resource('s3')
def download_file(bucket, s3_name):
try:
s3_bucket.Bucket(bucket).download_file('Python.png', 'Python_download.png')
except botocore.exceptions.ClientError as e:
if e.response['Error']['Code'] == "404":
print("The object does not exist.")
else:
raise
def upload_file(bucket_name, filename):
# Uploads the given file using a managed uploader, which will split up large
# files automatically and upload parts in parallel.
s3.upload_file(filename, bucket_name, filename)
if __name__ == '__main__':
upload_file(sys.argv[1], sys.argv[2])
download_file(sys.argv[1], sys.argv[2])
This script uploads and downloads the Python.png S3 object in the bucket, passed as a parameter, and then stores it in the Python.png local file. For the execution of the previous script we can pass as arguments the bucket name and the file we want to upload to the bucket:
$ python s3_upload_download_file_boto.py mybucket Python.png
I'll leave you to further explore the Boto package's functionality with the help of the tutorial, which can be found at https://boto.readthedocs.org/en/latest/s3_tut.html.