
Other Collection Types
Back in chapter 7 we talked about the most basic sequence collections in Scala, the Array and the List. Since then we have seen other similar types. These collections share a large number of different methods that we have used to great effect. The sequences are not the only type of collection though. The Scala collections library is far more extensive than what we have seen so far. In this chapter we will examine the inheritance hierarchy of the entire collections library and look at three other types of collections in detail.
20.1 The scala.collection Packages
At this point you have likely seen in the Application Programming Interface (API) that there are a number of packages that start with scala.collection including one called simply scala.collection. A class diagram showing the inheritance relationships in this top-level package is shown in figure 20.1. At the top of the hierarchy is the Traversable[A] type. This is a trait that underlies the rest of the hierarchy and can be used to represent anything that has the capability for running through it.
![Figure showing This is a UML diagram of the main types in the scala.collection package. The collection types we have dealt with, including List[A] and Array[A], have been under the Seq[A] part of the hierarchy.](http://imgdetail.ebookreading.net/software_development/6/9781439896679/9781439896679__introduction-to-the__9781439896679__image__020x001.png)
This is a UML diagram of the main types in the scala.collection package. The collection types we have dealt with, including List[A] and Array[A], have been under the Seq[A] part of the hierarchy.
Below Traversable[A] is the Iterable[A] trait. As the name implies, this type, and its subtypes, have the ability to provide Iterators. Anything that is Iterable[A] will have a method called iterator that will give you an Iterator[A]. Though not shown in the figure, the Iterator[A] is also in scala.collection and it inherits from a type called TraversableOnce[A]. Both of these types represent collections that are consumed as they are read.
There are three main subtypes of Iterable[A] in the Scala libraries. These are Seq[A], which we have worked with previously, Set[A], and Map[A]. The latter two allow you to run through their contents, hence they are subtypes of Iterable[A], but they handle their contents in a very different way than does a sequence. The sections below will go into the details of those types.
In this top package there are two subtypes of Set and Seq. The BitSet type is optimized to work with sets of Int. It stores one bit for each integer. If the value is in the set, the bit will be on, otherwise it will be off. The SortedSet type is a specialized version of Set that works when the contents have a natural ordering.
The two subtypes of Seq are IndexedSeq and LinearSeq. These two types differ in how the elements can be efficiently accessed. A List is an example of a LinearSeq. This type has the property that to get to an element, you have to run through all the ones before it. On the other hand, an IndexedSeq allows you to quickly get to elements at arbitrary indexes, like an Array. Each of these types implements their methods in a different way, depending on what is the most efficient way to get to things.
These types are implemented in two different way in the Scala libraries based on whether the implementations are immutable or mutable. To keep these separate, there are packages called scala.collection.immutable and scala.collection.mutable.
20.1.1 scala.collection.immutable
The scala.collection.immutable package stores various types of collections that are all immutable and which have been optimized so that common operations can be done efficiently with them. This means that "updates" can be made without making complete copies. Of course, because these collections are immutable, no object is really updated, instead, a new, modified version is created. To be efficient, this new object will share as much memory as possible with the original. This type of sharing is safe because the objects are immutable. A simple class diagram showing the inheritance relationships between the main classes and traits in this package are shown in figure 20.2.

This is a UML diagram of the main types in the scala.collection.immutable package. This image is significantly simplified. If you look in the API you will see that most of the types inherit from multiple other types.
The top part of the hierarchy looks the same as that shown in figure 20.1 for the scala.collection package. It begins with Traverable and Iterable then has three main subtypes in the form of Set, Seq, and Map. The difference is that there are many more subtypes of those three listed here. We will not go into details on most of these, but it is worth noting a few. First there is List. This is the immutable sequence collection that we have been using for most of the book. You can see here that it is a LinearSeq. This means that you can’t efficiently jump to random elements. We will see exactly why that is in chapter 25.
If you want an immutable collection that has efficient indexing, your default choice would generally be Vector. The other immutable subtypes of IndexedSeq include Range, which we saw in chapter 8, and a type called StringOps. The StringOps type provides Scala collection operations on strings. Many of the methods that you have been using with strings are not defined on the java.lang.String type. Instead, there is an implicit conversion from java.lang.String to scala.collection.immutable.StringOps. That is how you can do things like this.
val (upper,lower) = "This is a String.".filter(_.isLetter).partition(_.isUpper)
The java.lang.String type does not actually have methods called filter or partition. You can verify this looking in the Java API. When Scala sees this line of code, it sees that those methods are missing and looks for an implicit conversion that will give a type that has the needed methods. In this case, the conversion will be to StringOps.
There are a number of different types listed under Map as well. Two of these are optimized specifically to work with Int and Long. For most applications the HashMap will probably be ideal. The details of HashMap are beyond the scope of this book. You should cover those in a course on data structures. We will cover possible implementations of the TreeMap in chapter 29.
20.1.2 scala.collection.mutable
The last package under scala.collection that we will concern ourselves with right now is the scala.collection.mutable package. As the name implies, this package includes collections that are mutable. This is the most extensive of the three packages. It is worth scanning through the API to look at the various types in this package and to see what they are used for. Figure 20.3 shows a UML diagram with the main types in this package.
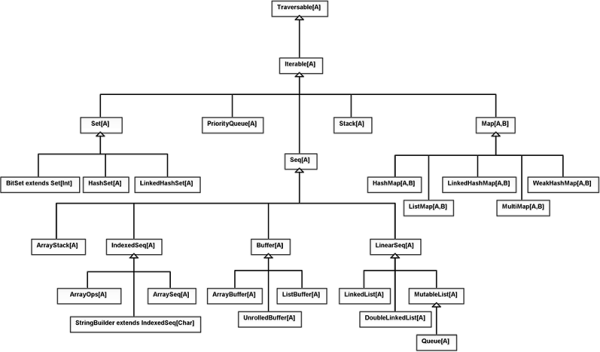
This is a UML diagram of the main types in the scala.collection.mutable package. This image is significantly simplified. If you look in the API you will see that most of the types inherit from multiple other types.
The fact that these types are mutable implies that they include methods that will change their values. When using them you need to try to remember that the "standard" methods, those we have been using regularly to this point, are still non-mutating methods. For example, filter does not change the contents of a collection, even if the collection is mutable. Instead, they introduce a few additional methods that do perform mutations. We’ll talk about these a bit more below.
It is also worth noting that one of the mutable types is ArrayOps. This class is much like StringOps. In truth, the Array type that we have been using is scala.Array and it has very few methods defined on it. When you use the various sequence operations an implicit conversion is invoked to convert the Array object to an ArrayOps object.
Now we will look at the Set, Map, and Buffer types. These types can give you a significant boost in your programming and make it much easier to do certain tasks.
20.2 Sets
The concept of a set comes from math. There are two main differences between the Set type and the Seq type. The most important one is that a Set does not allow duplicate values. If you add something to a Set and there is already something there that is equal to it, it does not add a new value and the size of the resulting set is the same as what you had before. The other difference is that the order of elements in a Set is not guaranteed.1 We can see both of these effects in the following sequence of REPL commands.
scala> Set(1,2,3)
res0: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
scala> res0 + 4
res1: scala.collection.immutable.Set[Int] = Set(1, 2, 3, 4)
scala> res1 + 2
res2: scala.collection.immutable.Set[Int] = Set(1, 2, 3, 4)
scala> res1 + -10
res3: scala.collection.immutable.Set[Int] = Set(-10, 4, 1, 2, 3)
This begins with a set that has the values 1, 2, and 3. As with the List and Array types, Scala figures out that this is a Set[Int]. You can also see from the inferred type that by default we get an immutable set.
You can add to a set with +, you get back a new set that has the element after the plus sign added in. The second statement gives us back a set that includes 4 in addition to the 1, 2, and 3. In the third command we add a 2 to this new set. The result looks the same as the set before the 2 was added. This is because the set can not contain duplicate elements.
The last statement adds the value -10 into the set from res1. This value goes into the resulting set because there had not been a -10 previously. However, the result shows that order is not preserved in sets. Adding the -10 into the set not only put it in an odd place at the beginning, it also altered the location of the 4 in the set. From this you can see that you want to use sets when what you care about is the uniqueness of elements, not the order in which you get them.
The fact that the order can change means that "indexing" into a set in the manner we have done with an Array or a List do not have much meaning. You can perform that type of operation on a Set, but the meaning is a bit different. Consider the following examples.
scala> res3(2)
res4: Boolean = true
scala> res3(5)
res5: Boolean = false
scala> res3(-10)
res6: Boolean = true
This type of operation on a set does not give you back a value at a particular location. Instead, it returns a Boolean that tells you whether or not the specified value is in the set. This works equally well if the set contains values other than Ints. Consider the following.
scala> val strSet=Set("Mark","Jason","Kevin")
strSet: scala.collection.immutable.Set[java.lang.String] = Set(Mark, Jason, Kevin)
scala> strSet("Jason")
res7: Boolean = true
scala> strSet("Bill")
res8: Boolean = false
In this example, the set contains Strings and the "indexing" is done by passing in Strings. The meaning is the same either way. The return value is true if the argument passed in is in the set and false if it is not. To see why this works this way, go look in the Scala API at one of the versions of Set. They all have a type parameter called A and they define the following method.
def apply (elem: A): Boolean
Remember that apply is a special method that is invoked when an object is used with function call notation. So f(5) in Scala gets expanded to f.apply(5). Here the apply takes one argument, elem, which must have the type A. That is the type parameter of the set as a whole, so you have to pass in an object of the type that the set contains. This method then returns to you a Boolean telling you whether or not that value is in the set.
20.2.1 Running Through Sets
In addition to the standard higher order methods like map, filter, and foreach, that are available for both Set and the sequences that we have worked with previously, the Set type works perfectly well with for loops as well.
scala> for(v <- res3) println(v)
1
2
-10
3
4
In fact, you can not really use a while loop to run through a Set, because you can not index by position. Also, the order in which the loop runs through the set values is not something you can predict. It does not even have to match the order that the values are displayed when the Set is converted to a String for printing.
20.2.2 Mutable vs. Immutable
The examples above showed the default immutable Set type. Like the List type that we saw previously, an immutable set does not change after it is created. When we add elements to the set with the + operator, we get back a new set and the original set is unaltered. We can demonstrate this by calling back up the original set.
scala> res0
res9: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
All of the operations that were done have not altered it in any way.
As we saw earlier, there is another Set type in the scala.collection.mutable package. You could get to this type using the fully specified name of scala.collection.mutable.Set. However, doing so not only requires a lot of typing, it also makes code difficult to read. You could import scala.collection.mutable.Set and then refer to it as just Set. The problem with this approach is that you can no longer easily refer to the immutable Set type. A recommended style for dealing with this is to import scala.collection.mutable. The packages in Scala are truly nested. As a result, this import will allow us to refer to a mutable set by the name mutable.Set and the immutable set as just Set.
All the operations that you can do with an immutable set are available on a mutable set as well. Above we used the + operator on the immutable set and it works equally well on the mutable set.
scala> import scala.collection.mutable
import scala.collection.mutable
scala> val mset=mutable.Set(1,2,3)
mset: scala.collection.mutable.Set[Int] = Set(1, 2, 3)
scala> mset + 4
res10: scala.collection.mutable.Set[Int] = Set(1, 4, 2, 3)
scala> mset
res11: scala.collection.mutable.Set[Int] = Set(1, 2, 3)
This code shows you the import statement, the declaration of a mutable set after the import, and the creation of a new set by adding an element to the old one. Just using + does not change the mutable set. The way in which the mutable set differs from the immutable version is that it includes additional operators and methods.
To see this we will call one of those extra operators. On a mutable set we can use += the same way we might with an Int that was declared as a var.
scala> mset += 4
res12: mset.type = Set(1, 4, 2, 3)
scala> mset
res13: scala.collection.mutable.Set[Int] = Set(1, 4, 2, 3)
You can see from this that the use of += actually changes the original set. The += does not exist on the immutable set type. If you try to call it, you will get a syntax error. The list of methods/operators on the mutable set that mutate them includes the following for Set[A].
- +=(elem : A) - Adds the specified element to the set.
- -=(elem : A) - Removes the specified element from the set. Does nothing if it was not there initially.
- ++=(xs : TraversableOnce[A]) - Adds all the elements from a collection into the set. The TraversableOnce type is the most basic type for Scala collections so this can be used with any of the collections in Scala. Traversable inherits from TraversableOnce.
- --=(xs : TraversableOnce[A]) - Removes all the elements in xs from the set.
- add(elem : A) : Boolean - Adds the specified element to the set. Returns true if it was not there before the call and false otherwise.
- clear():Unit - Removes all elements from the set.
- remove(elem : A) : Boolean - Removes the specified element from the set and returns true if it was there to remove or false otherwise.
- retain(p : (A) => Boolean) : Unit - Removes all elements that do not satisfy the predicate from the set.
Mutable sets can also be updated using assignment. This is basically the inverse operation of "indexing" that we saw before using apply. The index is the value you are adjusting in the set and the assignment is either to true or false. To see how this works, consider the following examples.
scala> mset(7)=true
scala> mset(2)=false
scala> mset
res14: scala.collection.mutable.Set[Int] = Set(1, 4, 7, 3)
The first line adds 7 to the set while the second removes 2. This works because the scala.collection.mutable.Set type defines an update method that looks like this.
def update (elem: A, included: Boolean): Unit
So the line mset(7)=true gets expanded to mset.update(7,true).
Earlier in this section it was mentioned that the standard methods, like map and filter, will do the same thing on a mutable set as they do on an immutable set. This was very intentional. The same operations on subtypes types like this should always have the same outward appearance and significant effects. This reduces the chances of programmers making silly mistakes. If you want to mutate the set you have to call one of the specific methods for doing so. For example, you would call retain instead of filter. If you accidentally try to use one of these operations on an immutable type the code will not compile. If the operations with the same name had different behaviors, it would be very easy for the programmer to introduce logic errors because he/she believed an object was one type when it was actually another, or for bugs to be introduced later on by a programmer changing the specific type that is assigned to a variable.
20.2.3 Using a Set
To see how the Set type can be useful we will write a function that tells us all the unique words in a text file. The function will take the name of the file as an argument and return a Set[String] that has all the words in lowercase. As with any function of any significance, this can be done in many ways. We are going to do it making heavy use of the Scala collection methods. The fact that we are using the collection methods makes it more sensible to use a Source than a Scanner. Here is code that will do this.
def uniqueWords(fileName:String):Set[String] = {
val source = io.Source.fromFile(fileName)
val words = source.getLines.toSeq.flatMap(_.split(" +")).
map(_.filter(_.isLetter).toLowerCase).toSet
source.close()
words
}
A function is defined using the signature that was described. This function includes only four statements. The first and third statements in the function open the file and close it. The last statement is just an expression for the set that was created from the source. The second statement is where all the work is done and is worth looking at in detail.
This line declares the variable words and makes it equal to a set of the words. To do that it gets the lines from the source and turns them into a sequence. The toSeq call makes types work out better with flatMap. As you might recall, getLines returns an Iterator. The Iterator type is a collection that you can only pass through once. It is consumed during that pass. By bumping it up to a sequence we get something that works better with the Array[String] that we get from the split method.
After the lines are converted to a sequence there is a call to flatMap. This is one of the standard higher-order methods on collections. We have not used it much so it is worth taking a minute to discuss. As you can tell from the name, flatMap is closely related to map. The map method takes each element of a collection, applies some function, and makes a new collection that has the results of that function application. The flatMap does basically the same thing only it expects that the function passed in is going to return collections. Instead of returning a collection of collections, as map would do, flatMap will flatten out all of the inner collections into one long collection. If you use map on the sequence of lines and use the same map function, you will get a Seq[Array[String]]. Each element of the sequence will contain an array of the words from that line. However, that is not quite what we want. We want a simple sequence of words, not a sequence of arrays of words. This is what flatMap does for us. It puts each of the arrays end to end in the new sequence so that we get a Seq[String].
If we knew that the file only included simple words in lowercase we could stop there. However, most text files will includes capitalization and punctuation as well. This would mess up the set because "Hi" is not equal to "hi" and the both would appear in the result when we want only one. Similarly, the word "dog" would be different than "dog." or "dog," if the word happened to appear directly before a punctuation mark. The second line of the second statement includes logic to deal with this. Each of the words that the file was broken into is passed through a map. That map filters out any non-letter characters and converts the resulting strings to lower case. The filtering of non-letter characters is perhaps too aggressive because it removes things like apostrophes in contractions, but the result it provides is sufficiently correct for our purposes.
The last thing that happens in the second statement is that the sequence is converted to a Set. This gives us the type we desired and removes any non-unique elements by virtue of being a Set.
20.3 Maps
Another collection type that is extremely useful, probably more so than the Set in most programs, is the Map. Like the Set, the term Map has origins in math. A mapping in mathematics is something that takes values from one set and gives back values from another set. A function in math is technically a mapping. The Map collection type is not so different from this. It maps from value of one type, called the key type, to another type called the value type. The key and value types can be the same, but they are very often different.
To help you understand maps, let’s look at some examples. We will start with a statement to create a new map.
scala> val imap=Map("one" -> 1, "two" -> 2, "three" -> 3)
imap: scala.collection.immutable.Map[java.lang.String,Int] = Map((one,1), (two,2),
(three,3))
The Map type takes two parameters. In this example they are String and Int. The values passed in to build the Map are actually tuples where the key is the first element and the value is the second element. In this example we used the –> syntax that was discussed in chapter 3. This syntax was added to the Scala libraries for this exact purpose. You can read this as making a map where the String "one" maps to the Int 1 and so on.
When you index into a map you do so with values of the key type. What you get in return is the corresponding value object.
scala> imap("two")
res0: Int = 2
If you like, you can think of a map as a collection that can be indexed by any type that you want instead of just the integer indexes that were used for sequences. If you try to pull out a key that is not in the map, you will get an exception. This works because the Map type defined an apply method like this.
def apply (key: A): B
The types A and B are the type parameters on Map with A being the key type and B being the value type.
In addition to allowing any type for the key, the map also has the benefit that it does not require any particular "starting" value for the indexes. For this reason, you might sometimes want to build a map that uses an Int as the index. Consider this example.
scala> val imap2=Map(10 -> "ten", 100 -> "hundred", 1000 -> "thousand")
imap2: scala.collection.immutable.Map[Int,java.lang.String] = Map((10,ten),
(100,hundred), (1000,thousand))
Technically you could build a sequence that has the values "ten", "hundred", and "thousand" at the proper indexes. However, this is very wasteful because there are many indexes between 0 and 1000 that you will not be using and they would have null references in them.
As with the Set type, you can add new key, value pairs to the map with the + operator.
scala> imap + ("four" -> 4)
res1: scala.collection.immutable.Map[java.lang.String,Int] = Map((one,1), (two,2),
(three,3), (four,4))
The key and value need to be in a tuple, just like when the original map was built. The parentheses in this sample are required for proper order of operation. Otherwise the + happens before the –> and the result is a (String,Int) that will look rather unusual.
You can also use the – operator to get a map with fewer elements. For this operation, the second argument is just the key you want to remove. You do not have to have or even know the value associated with that key.
scala> imap - "two"
res2: scala.collection.immutable.Map[java.lang.String,Int] = Map((one,1),
(three,3))
Here we remove the value 2 from the map by taking out the key "two".
As with the Set type, there are mutable and immutable flavors. As you can see from the examples above, the default for Map, like for Set, is immutable. To use the mutable version you should follow the same recommendation as was given above and import scala.collection.mutable and then refer to it as mutable.Map.
20.3.1 Looping Through a Map
You can use the higher-order methods or a for loop to run through the contents of a Map, but there is a significant difference between this and the other collections we have looked at. This is because the contents of the map are effectively tuples. To illustrate this, we’ll look at a simple for loop.
scala> for(tup <- imap) println(tup)
(one,1)
(two,2)
(three,3)
Each element that is pulled off the map is a tuple. This has significant implications when using higher order methods like map. The argument to map is a function that takes a single argument, but that argument is a tuple with a key-value pair in it. Consider the following code.
scala> imap.map(tup => tup._2∗2)
res3: scala.collection.immutable.Iterable[Int] = List(2, 4, 6)
Because the argument, tup, is a tuple, we have to use the _2 method to get a value out of it. The _1 method would give us the key. The alternative is to make the body of the function longer and use a pattern in an assignment to pull out the values. For many situations this is not significantly better.
Running through a map works much better with a for loop because the for loop does pattern matching automatically as was discussed in section 8.3.5. This syntax is shown here.
scala> for((k,v) <- imap) yield v∗2
res4: scala.collection.immutable.Iterable[Int] = List(2, 4, 6)
This syntax is not significantly shorter for this example though it can be in others and it is easier for most people to read. The real advantage is that you can easily use meaningful variable names. This example used k and v for key and value, but in a full program you could use names that carry significantly more meaning.
You might have noticed that both the example with map and with the for loop gave back lists. This is also a bit different as we are used to seeing this type of operation give us back the same type that was passed in. The problem is that to build a map we would need key, value pairs. The way the libraries for Scala are written, you will automatically get back a map any time that you use a function that produces a tuple.
scala> imap.map(tup => tup._1 -> tup._2∗2)
res5: scala.collection.immutable.Map[java.lang.String,Int] = Map((one,2), (two,4),
(three,6))
scala> for((k,v) <- imap) yield k -> v∗2
res6: scala.collection.immutable.Map[java.lang.String,Int] = Map((one,2), (two,4),
(three,6))
These two examples show how that can work using either map or the for loop with a yield.
20.3.2 Using Maps
The example we will use for illustrating a use of a Map is closely related to the one we used for the Set. Instead of simply identifying all the words, we will count how many times each one occurs. This function will start off very similar to what we did before. We’ll start with this template.
def wordCount(fileName:String):Map[String,Int] = {
val source = io.Source.fromFile(fileName)
val words = source.getLines.toSeq.flatMap(_.split(" +")).
map(_.filter(_.isLetter).toLowerCase)
val counts = // ???
source.close()
counts
}
Here words will just be a sequence of the words and we will use it to build the counts and return a Map with those counts. We will do this last part in two different ways.
The first approach will use a mutable map. The logic here is that we want to run through the sequence of words and if the word has not been seen before we add a count of 1 to the map. If it has been seen before, we add the same key back in, but with a value that is one larger than what we had before. The code for this looks like the following.
def wordCount(fileName:String):mutable.Map[String,Int] = {
val source = io.Source.fromFile(fileName)
val words = source.getLines.toSeq.flatMap(_.split(" +")).
map(_.filter(_.isLetter).toLowerCase)
val counts = mutable.Map[String,Int]()
for(w <- words) {
if(counts.contains(w)) counts += w -> (counts(w)+1)
else counts += w -> 1
}
source.close()
counts
}
Note that the for loop to run through the words here occurs after the declaration of counts. Because counts is mutable this approach works. You should also note that the return type for the function has been altered to be a mutable.Map[String,Int]. If you leave this off, you have to add a call to .toMap at the end, after counts, so that the counts will be converted to an immutable type. This distinction between mutable and immutable types is very significant for safety in programs. In general there could be other references to the Map you are given that are retained in other parts of the code. If it were possible for you to get a mutable map when you were expecting an immutable one, those other parts of the code could alter the map when you were not expecting it. This would lead to very hard to track down logic errors.
Using the mutable version is fairly logical and can have some efficiency advantages, but as was just alluded to, mutable values come with risks. For this reason, we will write a second version that uses an immutable map and the foldLeft method. The foldLeft method is a more complex method that we have not really dealt with before. However, it is ideal for what we are doing here as it effectively does what we wrote previously, but without the need for a for loop. The foldLeft method runs through the collection from left to right and applies a function to each element, compiling a result as it goes. The function is curried and the first argument list is a single value that tells what the compiled value should start off as. In this case, we are compiling a Map so we will start off with an empty one. The code we want to apply is very much like what was in the for loop previously. This is what it all looks like when put together.
def wordCount2(fileName:String):Map[String,Int] = {
val source = io.Source.fromFile(fileName)
val words = source.getLines.toSeq.flatMap(_.split(" +")).
map(_.filter(_.isLetter).toLowerCase)
val counts = words.foldLeft(Map[String,Int]())((m,w) => {
if(m.contains(w)) m + (w -> (m(w)+1))
else m + (w -> 1)
})
source.close()
counts
}
The function that is passed into foldLeft takes two arguments. The first is the compiled value so far and the second is the value that is being operated on. In this case the compiled value is a Map and we use the variable m to represent it. The value being passed in is the next word that we want to count and is represented by the name w as it was in the for loop previously.
The body of the function passed into foldLeft as the second argument list differs from what was inside the for loop previously in two ways. First, instead of referring to the mutable map counts, we use the argument name m. Second, we do not use +=. Instead we just use +. The += operator is not defined for the immutable map and what we are doing here is building a new immutable map that is passed forward to be used with the next word.
If you really want to push things a little harder you can get rid of the declaration of words all together. After all, the only thing it is used for is as the argument to foldLeft to build counts. Doing this and getting rid of some curly braces that are not technically needed produces the following code.
def wordCount3(fileName:String):Map[String,Int] = {
val source = io.Source.fromFile(fileName)
val counts = source.getLines.toSeq.flatMap(_.split(" +")).
map(_.filter(_.isLetter).toLowerCase).
foldLeft(Map[String,Int]())((m,w) =>
if(m.contains(w)) m + (w -> (m(w)+1))
else m + (w -> 1))
source.close()
counts
}
This code is compact, but whether you really want to do things this way or not is debatable. The introduction of the variable words did add extra length to the code, but for most readers it probably also made things more understandable.
Having any version of wordCount implicitly gives us a set of the words as well. This is because the Map type has a method called keySet that returns a Set of all of the keys used in the Map. Because each key can only occur once, nothing is lost when you get the keys as a set. For efficiency reasons you would probably want to keep the uniqueWords function around if you were going to be using it often instead of replacing calls to it with wordCount("file.txt").keySet because the counting of the words does extra work that is not needed to produce the set.
A more general use case for maps is using them as a fast way to look up groups of data like case classes by a particular key value. An example of this would be looking up a case class that represents a student by the student’s ID or perhaps their unique login number. The real power of the Map type comes from the fact that the key and value types can be anything that you want.
20.4 Buffers
The last of the new collection types that we will look at in detail in this chapter is the Buffer. The Buffer type is like an Array that can change size. As a result, the Buffer type is implicitly mutable. There is no immutable Buffer. If you are using other mutable types, the rule of importing scala.collection.mutable and referring to a Buffer as mutable.Buffer will still work well and it makes it perfectly clear to anyone reading the code that you are using a mutable type. However, because the Buffer type is only mutable you could also consider doing an import of scala.collection.mutable.Buffer and simply calling it a Buffer in your code.
There are several subtypes of Buffer in the Scala libraries. The two most significant ones are ArrayBuffer and ListBuffer. One uses an array to store values. The other uses a structure called a linked list. The List type in Scala is also a linked list, though it is not directly used by the ListBuffer because the ListBuffer needs to be mutable. We will use the ArrayBuffer in this chapter. The nature of the ListBuffer and how it is different will become more apparent in chapter 25.
You can create a buffer in exactly the way that you would expect.
scala> val buf = mutable.Buffer(1,2,3,4,5)
buf: scala.collection.mutable.Buffer[Int] = ArrayBuffer(1, 2, 3, 4, 5)
You can also use some of the methods we learned about for Array and List like fill and tabulate.
scala> val rbuf=mutable.Buffer.fill(10)(math.random)
rbuf: scala.collection.mutable.Buffer[Double] = ArrayBuffer(0.061947605764430924,
0.029870283928219443, 0.5457301708447658, 0.7098206843826819,
0.8619215922836797, 0.5401420250956313, 0.6249953821782052,
0.1376217145656472, 0.26995766937532295, 0.8716257556831167)
You can index into a buffer and change values the same way you did for an array.
scala> rbuf(3)
res0: Double = 0.7098206843826819
scala> buf(3)=99
scala> buf
res1: scala.collection.mutable.Buffer[Int] = ArrayBuffer(1, 2, 3, 99, 5)
The way in which the Buffer type differs from the Array type is that it can easily grow and shrink. There are a whole set of methods that take advantage of this. Here are some of them.
- +=(elem: A): Buffer[A] - Append the element to the buffer and return the same buffer.
- +=:(elem: A): Buffer[A] - Prepend the element to the buffer and return the same buffer.
- ++=(xs: TraversableOnce[A]): Buffer[A] - Append the elements in xs to the buffer and return the same buffer.
- ++=:(xs: TraversableOnce[A]): Buffer[A] - Prepend the elements in xs to the buffer and return the same buffer.
- -=(elem: A): Buffer[A] - Remove the element from the buffer and return the same buffer.
- --=(xs: TraversableOnce[A]): Buffer[A] - Remove all the elements in xs from the buffer and return the buffer.
- append(elem: A): Unit - Append the element to the buffer.
- appendAll(xs: TraversableOnce[A]): Unit - Append the elements in xs to the buffer.
- clear(): Unit - Remove all the elements from the buffer.
- insert(n: Int, elems: A∗): Unit - Insert the specified elements at the specified index.
- insertAll(n: Int, elems: Traversable[A]): Unit - Insert all the elements in elems at index n.
- prepend(elems: A∗): Unit - Prepend the elements to this buffer.
- prependAll(xs: TraversableOnce[A]): Unit - Prepend all the elements in xs to this buffer.
- remove(n: Int, count: Int): Unit - Remove count elements starting with the one at index n.
- remove(n: Int): A - Remove the one element at index n and return it.
- trimEnd(n: Int): Unit - Remove the last n elements from this buffer.
- trimStart(n: Int): Unit - Remove the first n elements from this buffer.
Most of these should be fairly self-explanatory. The only methods that you might question are the ones that involve symbol characters. There are two things of interest here. The first is that they all return the buffer that they are called on. The reason for this is that it allows you to string them together to append or prepend multiple elements in a row. Consider this example with appending.
scala> buf += 6 += 7
res2: buf.type = ArrayBuffer(1, 2, 3, 99, 5, 6, 7)
Here both 6 and 7 are appended in a single line.
The other operations that might seem odd are +=: and ++=:. These operations say that they prepend. What is interesting about them is their usage. Here is an example.
scala> 0 +=: buf
res3: buf.type = ArrayBuffer(0, 1, 2, 3, 99, 5, 6, 7)
The value to be prepended is to the left of the operator and the buffer is on the right. In some ways that makes sense given where it is in the buffer after the prepending. We have seen something like this before as well. The cons operator on a list is :: and it prepends the element to the list. That operator also ends with a colon. This is one of the more esoteric rules of Scala. Any symbolic operator method that ends in a colon is right associative instead of being left associative the way most operators are. This means that the object the operator works on is to the right of the operator and the operations are grouped going from the right to the left.
20.5 Collections as Functions
The different collection types all inherit from PartialFunction, which inherits from the standard function types. This means that you can use collections in places where you would normally be expected to use functions. For example, the Seq[A] type will work as a Int => A. Similarly, a Map[A,B] can be used as a A => B.
A simple example usage of this is to take every third elements of an array by mapping over a range with the desired indexes and using the array as the function argument.
val nums = Array.fill(30)(math.random)
val everyThird = (nums.indices by 3).map(nums)
In this way, applying map with a collection as the argument gives us the ability to do arbitrary indexing into a collection.
20.6 Project Integration
There are quite a few places where we can use these different collections. In the previous chapter the type mutable.Buffer was used in DrawTransform to hold children. This made it easy to include code that adds and removes children. In this section we are going to use the Map type to help with text commands. After that, we will make use of an Array to clean up adding Drawables to a Drawing. This is something we could have done before, but it fits better here when looking at different uses of collections.
20.6.1 Commands
The command processor is a part of the code that could be implemented with inheritance. It would be possible to make a type called Command that we have other types inherit from. That type of construct would make logical sense, but might not be what we really need. One of the aspects you want to learn about inheritance is to not use it when it is not required. To know if we need it, we have to do some analysis.
You might wonder why we would want to put a text-based command processor into a drawing program. Perhaps the best analogy for this is why you would want to include a command-line interface in an Operating System (OS) that has a Graphical User Interface (GUI). There are certain operations that simply work better when they are typed in than they would when you have to point and click them. For now we will start with some simple examples that we can use as use-cases for the command tool. There are three three commands that we will start with:
- echo - prints whatever follows the command,
- add - should be followed by a bunch of space separated numbers and prints the sum,
- refresh - takes no arguments and causes the drawing to refresh.
So the user might type in "echo Hello, World!", "add 1 2 3 4 5", or "refresh". The first two take arguments and the only result of calling them is that something is displayed in the output. The last one is very different in that it does not take arguments or display anything. Instead, it needs to cause the Drawing object that is displayed to repaint itself.
To make this happen in the code, we will need a listener on the TextField for the user input that reacts to an EditDone event. When that happens, the line that is typed in needs to have the first word identified and based on what it is, appropriate functionality needs to be invoked.
One way to implement this functionality is to have each command include a function of the form (String,Drawing) => Any. The first parameter to this function will be the rest of the line after the command. The second parameter is the Drawing object the command was invoked on. This is needed so that a command like refresh can cause something to happen associated with the drawing. The return value is anything we want to give back. For most things this object will be converted to a String and appended to the output.
Having these functions is not quite enough. We also need to have the ability to quickly identify which of these functions should be invoked based on the first word of the input. This is a perfect usage of a Map. More specifically, we want to use a Map[String, (String,Drawing)=>Any]. This is a map from each command String to the function that command should invoke.
Using this approach, we can declare an object that contains the command functionality. An implementation that includes the three commands described above might look like the following.
package scalabook.drawing
/∗∗
∗ This object defines the command processing features for the drawing.
∗ Use apply to invoke a command.
∗/
object Commands {
private val commands = Map[String,(String,Drawing)=>Any](
"add" -> ((rest,d) => rest.trim.split(" +").map(_.toInt).sum),
"echo" -> ((rest,d) => rest.trim),
"refresh" -> ((rest,d) => d.refresh)
)
def apply(input:String,drawing:Drawing):Any = {
val spaceIndex = input.indexOf(‘ ‘)
val (command,rest) = if(spaceIndex < 0) (input.toLowerCase(),"")
else (input.take(spaceIndex).toLowerCase(),input.drop(spaceIndex))
if(commands.contains(command)) commands(command)(rest,drawing)
else "Not a valid command."
}
}
This object contains an apply method that is used to invoke various commands. It takes two arguments. The first is the full input from the user and the second is the Drawing object for calls to be made back on. This method finds the location of the first space, assuming there is one, then breaks the input into a command part and the rest of the input around that space. If there is no space, the entire input is the command. Once it has split the input, it checks to see if the command is one that it knows.
The Map called commands is used to identify known commands and to invoke the command. A call to contains tells us if the command is a known command. If it is, then the apply method is called using function notation. If not, an appropriate String is returned.
To make this code function, two things must be done in the Drawing class. First, we need to add the refresh method that is called by the refresh command. It can be declared in the following way.
private[drawing] def refresh {drawPanel.repaint()}
This method is added to the class and does nothing more than tell the drawPanel to repaint. It does have one interesting feature, the visibility is modified with [drawing]. Putting square brackets after the private or protected visibility modifiers allows you to restrict that visibility to parts of the code. In this case, it says that it is private outside of the drawing package. Inside of that package it is effectively public.
The addition of refresh lets the code compile, but it still is not invoked. For it to be actively used, we need to modify the declaration of the commandField variable in Drawing in the following way.
val commandField = new TextField() {
listenTo(this)
reactions += {
case e:EditDone =>
if(!text.isEmpty) {
commandArea append "> "+text+"
"+Commands(text,Drawing.this)+"
"
text=""
}
}
}
This code tells the field to listen to itself and when an EditDone events occurs, it executes the command and appends the result to the command area then clears the text. This code has two interesting aspects. First, the call to the append method is done using operator syntax. This means that the dot and parentheses are left off. This is a completely stylistic choice here. The more significant piece of code is the second argument to Commands. You already know that the keyword this is used to refer to the current object. At this point in code, the current object is the TextField. We utilize that fact in the call to listenTo. The second argument to Commands needs to be of the type Drawing. This code is inside of the Drawing class so such an object is available. We just have to tell Scala that we want the this associated with one of the surrounding types. That is specified with dot notation so Drawing.this refers to the current instance of the Drawing class we are in.
The primary advantage of this design is that it makes it very easy to add new commands. Simply add a new member to the command map and you are done. For these commands, the code for the function could be done in line. Longer functions could easily be written as methods in the Commands object. If needed, the functionality for commands could even be placed in other parts of the code, as long as it is reachable from Commands or through the Drawing object that is passed in.
20.6.2 Adding Drawables
There is another place where we might use a collection in an interesting way to clean up the code so that it is more extensible and less error prone. This is in the code to add a new Drawable. The method we had in chapter 18 looked like this.
private def addTo(d:Drawable) = {
assert(d!=null)
val parent = d match {
case dt:DrawTransform => dt
case _ => d.getParent
}
val options = Seq("Ellipse","Rectangle","Transform")
val choice = Dialog.showInput(propPanel,
"What do you want to add?","Draw Type",Dialog.Message.Question,
null,options,options(0))
if(choice.nonEmpty) {
parent.addChild(options.indexOf(choice.get) match {
case 0 => new DrawEllipse(parent)
case 1 => new DrawRectangle(parent)
case _ => new DrawTransform(parent)
})
drawPanel.repaint
tree.getModel match {
case m:javax.swing.tree.DefaultTreeModel => m.reload
case _ =>
}
}
}
This method is not all that long, but it contains one significant part that is particularly error prone and that could lead to irritating errors later in development as more Drawable types are added to the project. The weak point in this code is that the order of the match cases is correlated to the order of the strings in options. Imagine what happens over time as more options are added. You have to add a string to options, then add a new case in the same position. If you decide you want to keep the strings in alphabetical order this will get challenging as the numbers on all the cases need to be changed. Even if that were not the case, it is too easy to get things out of order using this mechanism and the checking of order between the two will be time consuming when the lists get long.
An alternate approach is to group the names with the functionality to make the Drawable objects. In this case, we will use an array of tuples for this because the showOptionDialog method needs an array to be passed in and gives us back an Int. If instead of giving back an Int, it gave back the value that was selected, then a Map might be preferred.
private def addTo(d:Drawable) = {
assert(d!=null)
val parent = d match {
case dt:DrawTransform => dt
case _ => d.getParent
}
val options = Array[(String, ()=>Drawable)](
("Ellipse", () => new DrawEllipse(parent)),
("Rectangle", () => new DrawRectangle(parent)),
("Transform", () => new DrawTransform(parent))
).toMap
val choice = Dialog.showInput(propPanel,
"What do you want to add?","Draw Type",Dialog.Message.Question,
null,options.keys.toSeq,options.keys.head)
choice match {
case Some(ch) =>
val newChild = options(ch)()
parent.addChild(newChild)
drawPanel.repaint
tree.getModel match {
case m:javax.swing.tree.DefaultTreeModel => m.reload
case _ =>
}
case _ =>
}
}
The options array here is an Array[(String, ()=>Drawable)]. You might be tempted to use just an Array[String, Drawable] to get this. The problem with that approach is that any time an object is added, the code will create a new instance of every type of Drawable in the array. That is extremely wasteful since we only need one and some of the subtypes of Drawable that we create later might be fairly large objects with significant overhead in their creation.
Using ()=>Drawable instead of just Drawable means that we do not actually create any of the objects unless we invoke the method. In this case, the code options(ch)() does that for us on the one function associated with the choice that was selected.
Of course, the real benefit of this approach is that the names and the code to create them are grouped together in such a way that they can be easily reordered or added to with very little chance of the programmer messing things up. Having the string and the type appear on the same line means that they can be moved around and a simple visual inspection can tell you whether or not they have been set up correctly.
Visibility Options
As was mentioned in the section above, you can put bounds on the visibility restrictions implied by private and protected using square brackets. Inside the square brackets you can put the name of a bounding scope that you want to have public access to that member. This can be the name of a package, class, or trait that the code is inside of. This allows you to make something visible to the closely related code in a package without opening it up to the whole world.
You can also specify the visibility of private[this], which implies that the member can only be seen by the object it is in. This is more restrictive than plain private which will allow it to be seen by all instances of that class or trait.
20.7 End of Chapter Material
20.7.1 Summary of Concepts
- The Scala collections libraries go far beyond the sequences like Array and List that we have looked at previously. There is a significant type hierarchy in related different parts of the hierarchy.
- The Set type is based on the mathematical concept of a set. All values in the Set are unique and order does not matter. The advantage over a sequence is that the check for membership is fast. There are mutable and immutable Set types.
- A Map is a collection that allows you to store and look up values using an arbitrary key type. This allows you to store and index values by Strings, tuples, or anything else. The type used for keys should really be immutable. There are mutable and immutable Map types.
- The Buffer is the ultimate mutable sequence type. Values can be mutated like an Array, but you are also able to insert or remove elements in a way that alters the size.
20.7.2 Exercises
- Implement the following function that will build a Map from any sequence of a type with a function that can make keys from values.
def buildMap[A,B](data:Seq[A], f: A => B):Map[B,A] - Write code to represent a deck of cards. Use the following as a starting point.
case class Card(suite:String,value:Char)class Deck {private val cards = mutable.Buffer[Card]()def dealHand(numCards:Int):List[Card] = ...def shuffle() {...}def split(where:Int) {...}}Note that cards is a mutable.Buffer so dealing a hand really moves cards and the other two methods should change the ordering of elements.
- In math discussions of probability, it is common to use a "bag of marbles" with different colored marbles as a mental image for illustrating certain concepts. The "bag" is not a Seq because there is no ordering. In Scala, it is better modeled as a Set.
Write a little script to make a Set[Marble] and try using these two definitions of Marble.
case class Marble(color:String)class Marble(val color:String)For each try making a set of three red and two blue marbles. How do those implementations differ? Why do you think that is?
- This exercise is a continuation of project 2 (p.345) on the BASIC programming language from the first half of the book. In that project you will simply use a Map to store variable values. A Map[String,Double] will work nicely as an efficient way to store and lookup variables. The rest of the functionality for the project can remain the same.
- A standard example of a Map is a telephone book. The key is the name. The value would be a case class with telephone number, address, etc. You should make a GUI to display the telephone book and store the data in an XML file. For the first cut you can make it so that there can only be one person with a given name and use a Map[String,Person].
If you want a bit of a challenge, make it so that there can be multiple people with the same name. For that you could use a Map[String,mutable.Buffer[Person]].
- If you did the graphics and ray-tracing projects in the first half of the book, you can alter your program to use a Buffer (or two) to store geometry. Put this into the GUI you wrote for project 4 (p.281) and keep whatever the most recent saving and loading options are. Also change your rendering code to work with a Buffer.
20.7.3 Projects
The project ideas for this chapter all have you adding functionality to what you had done before using one of the new types that was introduced.
- If you are working on the MUD projects, one obvious use of the Map type is to look up commands that a user types in to get functions that execute the required actions. You could also consider using a Map for any other place where something will need to be indexed by a value other than a simple number. For example, items or characters in a room could be indexed by their name, with some care for the fact that you should allow multiples. The ability to have multiple values could be provided by a Map[String,mutable.Buffer[Item]].
Your program is also keeping track of things like all the rooms in the world and possibly all the players currently logged in. These are both things that would make good use of a Buffer because the number of them will change.
- If you are working on the web spider you should probably keep a Buffer of the data that you have collected from the various pages. In addition, you definitely need a way to not repeat visiting pages and perhaps to associate data with the page that it came from. The former can be nicely done using a Set as it can efficiently tell you if a value is already a member or not. If you want to have the ability to see what data was associated with a particular URL, you could use a Map with the URL as the key. The fact that the keys of a Map are themselves a Set, means that you do not need a separate Set if you use a Map in this way.
- The broad variety of possibilities for games, networked or not, makes it hard to predict the ways in which these new collections might be useful. However, the vast majority of possibilities will have entities in them whose numbers vary and could be implemented well with a Buffer. You might also find uses for Maps for efficient look-up or Sets to efficiently demonstrate uniqueness.
- The math worksheet project will have commands, much like the MUD. At this point, that makes a clear case for using a Map. In addition, the worksheet itself is going to be a sequence of different elements that will grow as the user adds things, or possibly shrink when the user takes things away. After reading this chapter, that should sound like a Buffer.
- The Photoshop® project is filled with different aspects that can be nicely implemented with Buffers. For example, one of the standard features of software like Photoshop is to include multiple layers that can be worked on independently. The elements that are drawn on the layers could also be stored in Buffers.
- If you are working on the simulation workbench project, it makes sense to use a Buffer for different simulations that are running at one time. You could link that to a TabbedPane that shows the different simulations.
Having a Buffer of particles could be interesting for some simulations, but probably not the gravity ones that you have right now.
Another way to add more collections to this project is to add another simulation type all together. One that you can consider include adding a particle-mesh for doing cloth simulations. The way this works is that you have a number of particles that each have a small amount of mass. They are connected with "springs" so that if they move too close to one another or too far away, there is a restoring force. In many ways, this works just like the gravity simulation, the only difference is that the forces only occur between particles that are connected in the mesh, and the force is not a 1/r2 type of force.
The most basic implementation of this would use a standard Hook’s Law with Fs = −kx, where k is the spring constant and x is the offset from the rest length of the spring. The force is directed along the segment joining the particles. A grid of particles with springs between each particle and its neighbors in the same row and column provides a simple setup that you can test. To make it dynamic, consider fixing one or two particles so that forces can not move them. You might also add a somewhat random forcing to mimic wind.
A more accurate simulation can be obtained by the addition of extra, weaker springs. These would go between each particle and the ones immediately diagonal from it on the grid, as well as those two down along the same row or column. These additional springs give the fabric some "strength" and will make it bend in a more natural way. The simple grid configuration can completely fold over with an unnatural crease.
1If you happen to be using a SortedSet, then the order of the objects will match the natural ordering of the type, but this is more the exception than the rule.