
CHAPTER 8
Linear Algebra: Matrix Eigenvalue Problems

A matrix eigenvalue problem considers the vector equation
![]()
Here A is a given square matrix, λ an unknown scalar, and x an unknown vector. In a matrix eigenvalue problem, the task is to determine λ's and x's that satisfy (1). Since x = 0 is always a solution for any λ and thus not interesting, we only admit solutions with x ≠ 0.
The solutions to (1) are given the following names: The λ's that satisfy (1) are called eigenvalues of A and the corresponding nonzero x's that also satisfy (1) are called eigenvectors of A.
From this rather innocent looking vector equation flows an amazing amount of relevant theory and an incredible richness of applications. Indeed, eigenvalue problems come up all the time in engineering, physics, geometry, numerics, theoretical mathematics, biology, environmental science, urban planning, economics, psychology, and other areas. Thus, in your career you are likely to encounter eigenvalue problems.
We start with a basic and thorough introduction to eigenvalue problems in Sec. 8.1 and explain (1) with several simple matrices. This is followed by a section devoted entirely to applications ranging from mass–spring systems of physics to population control models of environmental science. We show you these diverse examples to train your skills in modeling and solving eigenvalue problems. Eigenvalue problems for real symmetric, skew-symmetric, and orthogonal matrices are discussed in Sec. 8.3 and their complex counterparts (which are important in modern physics) in Sec. 8.5. In Sec. 8.4 we show how by diagonalizing a matrix, we obtain its eigenvalues.
COMMENT. Numerics for eigenvalues (Secs. 20.6–20.9) can be studied immediately after this chapter.
Prerequisite: Chap. 7.
Sections that may be omitted in a shorter course: 8.4, 8.5.
References and Answers to Problems: App. 1 Part B, App. 2.
The following chart identifies where different types of eigenvalue problems appear in the book.
| Topic | Where to find it |
| Matrix Eigenvalue Problem (algebraic eigenvalue problem) | Chap. 8 |
| Eigenvalue Problems in Numerics | Secs. 20.6–20.9 |
| Eigenvalue Problem for ODEs (Sturm–Liouville problems) | Secs. 11.5, 11.6 |
| Eigenvalue Problems for Systems of ODEs | Chap. 4 |
| Eigenvalue Problems for PDEs | Secs. 12.3–12.11 |
8.1 The Matrix Eigenvalue Problem. Determining Eigenvalues and Eigenvectors
Consider multiplying nonzero vectors by a given square matrix, such as

We want to see what influence the multiplication of the given matrix has on the vectors. In the first case, we get a totally new vector with a different direction and different length when compared to the original vector. This is what usually happens and is of no interest here. In the second case something interesting happens. The multiplication produces a vector [30 40]T = 10 [3 4]T, which means the new vector has the same direction as the original vector. The scale constant, which we denote by λ is 10. The problem of systematically finding such λ's and nonzero vectors for a given square matrix will be the theme of this chapter. It is called the matrix eigenvalue problem or, more commonly, the eigenvalue problem.
We formalize our observation. Let A = [ajk] be a given nonzero square matrix of dimension n × n. Consider the following vector equation:

The problem of finding nonzero x's and λ's that satisfy equation (1) is called an eigenvalue problem.
Remark. So A is a given square (!) matrix, x is an unknown vector, and λ is an unknown scalar. Our task is to find λ's and nonzero x's that satisfy (1). Geometrically, we are looking for vectors, x, for which the multiplication by A has the same effect as the multiplication by a scalar λ; in other words, Ax should be proportional to x. Thus, the multiplication has the effect of producing, from the original vector x, a new vector λx that has the same or opposite (minus sign) direction as the original vector. (This was all demonstrated in our intuitive opening example. Can you see that the second equation in that example satisfies (1) with λ = 10 and x = [3 4]T, and A the given 2 × 2 matrix? Write it out.) Now why do we require x to be nonzero? The reason is that x = 0 is always a solution of (1) for any value of λ, because A0 = 0. This is of no interest.
We introduce more terminology. A value of λ, for which (1) has a solution x ≠ 0, is called an eigenvalue or characteristic value of the matrix A. Another term for λ is a latent root. (“Eigen” is German and means “proper” or “characteristic.”). The corresponding solutions x ≠ 0 of (1) are called the eigenvectors or characteristic vectors of A corresponding to that eigenvalue λ. The set of all the eigenvalues of A is called the spectrum of A. We shall see that the spectrum consists of at least one eigenvalue and at most of n numerically different eigenvalues. The largest of the absolute values of the eigenvalues of A is called the spectral radius of A, a name to be motivated later.
How to Find Eigenvalues and Eigenvectors
Now, with the new terminology for (1), we can just say that the problem of determining the eigenvalues and eigenvectors of a matrix is called an eigenvalue problem. (However, more precisely, we are considering an algebraic eigenvalue problem, as opposed to an eigenvalue problem involving an ODE or PDE, as considered in Secs. 11.5 and 12.3, or an integral equation.)
Eigenvalues have a very large number of applications in diverse fields such as in engineering, geometry, physics, mathematics, biology, environmental science, economics, psychology, and other areas. You will encounter applications for elastic membranes, Markov processes, population models, and others in this chapter.
Since, from the viewpoint of engineering applications, eigenvalue problems are the most important problems in connection with matrices, the student should carefully follow our discussion.
Example 1 demonstrates how to systematically solve a simple eigenvalue problem.
EXAMPLE 1 Determination of Eigenvalues and Eigenvectors
We illustrate all the steps in terms of the matrix
Solution. (a) Eigenvalues. These must be determined first. Equation (1) is
Transferring the terms on the right to the left, we get

This can be written in matrix notation
![]()
because (1) is Ax − λx = Ax − λIx = (A − λI)x = 0, which gives (3*). We see that this is a homogeneous linear system. By Cramer's theorem in Sec. 7.7 it has a nontrivial solution x ≠ 0 (an eigenvector of A we are looking for) if and only if its coefficient determinant is zero, that is,
We call D(λ) the characteristic determinant or, if expanded, the characteristic polynomial, and D(λ) = 0 the characteristic equation of A. The solutions of this quadratic equation are λ1 = −1 and λ2 = −6. These are the eigenvalues of A.
(b1) Eigenvector of A corresponding to λ1. This vector is obtained from (2*) with λ = λ1 = −1, that is,
![]()
A solution is x2 = 2x1, as we see from either of the two equations, so that we need only one of them. This determines an eigenvector corresponding to λ1 = −1 up to a scalar multiple. If we choose x1 = 1, we obtain the eigenvector
![]()
(b2) Eigenvector of A corresponding to λ2. For λ = λ2 = −6, equation (2) becomes
![]()
A solution is x2 = −x1/2 with arbitrary x1. If we choose x1 = 2, we get x2 = −1. Thus an eigenvector of A corresponding to λ2 = −6 is
![]()
For the matrix in the intuitive opening example at the start of Sec. 8.1, the characteristic equation is λ2 − 13λ + 30 = (λ − 10)(λ − 3) = 0. The eigenvalues are {10, 3}. Corresponding eigenvectors are [3 4]T and [−1 1]T, respectively. The reader may want to verify this.
This example illustrates the general case as follows. Equation (1) written in components is

Transferring the terms on the right side to the left side, we have
In matrix notation,

By Cramer's theorem in Sec. 7.7, this homogeneous linear system of equations has a nontrivial solution if and only if the corresponding determinant of the coefficients is zero:
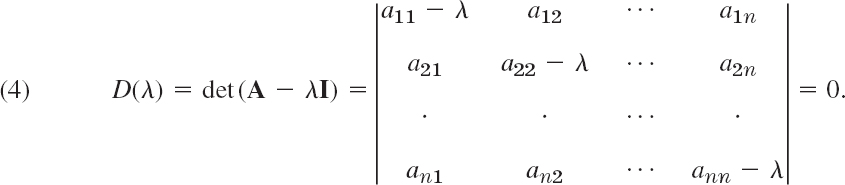
A − λI is called the characteristic matrix and D(λ) the characteristic determinant of A. Equation (4) is called the characteristic equation of A. By developing D(λ) we obtain a polynomial of nth degree in λ. This is called the characteristic polynomial of A.
This proves the following important theorem.
The eigenvalues of a square matrix A are the roots of the characteristic equation (4) of A.
Hence an n × n matrix has at least one eigenvalue and at most n numerically different eigenvalues.
For larger n, the actual computation of eigenvalues will, in general, require the use of Newton's method (Sec. 19.2) or another numeric approximation method in Secs. 20.7–20.9.
The eigen values must be determined first. Once these are known, corresponding eigen vectors are obtained from the system (2), for instance, by the Gauss elimination, where λ is the eigenvalue for which an eigenvector is wanted. This is what we did in Example 1 and shall do again in the examples below. (To prevent misunderstandings: numeric approximation methods, such as in Sec. 20.8, may determine eigen vectors first.)
Eigenvectors have the following properties.
THEOREM 2 Eigenvectors, Eigenspace
If w and x are eigenvectors of a matrix A corresponding to the same eigenvalue λ, so are w + x (provided x ≠ −w) and kx for any k ≠ 0.
Hence the eigenvectors corresponding to one and the same eigenvalue λ of A, together with 0, form a vector space (cf. Sec. 7.4), called the eigenspace of A corresponding to that λ.
PROOF
Aw = λw and Ax = λx imply A(w + x) = Aw + Ax = λw + λx = λ(w + x) and A(kw) = k(Aw) = k(λw) = λ(kw); hence A(kw + ![]() x) = λ(kw +
x) = λ(kw + ![]() x).
x).
In particular, an eigenvector x is determined only up to a constant factor. Hence we can normalize x, that is, multiply it by a scalar to get a unit vector (see Sec. 7.9). For instance, x1 = [1 2]T in Example 1 has the length ![]() ; hence
; hence ![]() is a normalized eigenvector (a unit eigenvector).
is a normalized eigenvector (a unit eigenvector).
Examples 2 and 3 will illustrate that an n × n matrix may have n linearly independent eigenvectors, or it may have fewer than n. In Example 4 we shall see that a real matrix may have complex eigenvalues and eigenvectors.
EXAMPLE 2 Multiple Eigenvalues
Find the eigenvalues and eigenvectors of

Solution. For our matrix, the characteristic determinant gives the characteristic equation
![]()
The roots (eigenvalues of A) are λ1 = 5, λ2 = λ3 = −3. (If you have trouble finding roots, you may want to use a root finding algorithm such as Newton's method (Sec. 19.2). Your CAS or scientific calculator can find roots. However, to really learn and remember this material, you have to do some exercises with paper and pencil.) To find eigenvectors, we apply the Gauss elimination (Sec. 7.3) to the system (A − λI)x = 0, first with λ = 5 and then with λ = −3. For λ = 5 the characteristic matrix is

Hence it has rank 2. Choosing x3 = −1 we have x2 = 2 from ![]() and then x1 = 1 from −7x1 + 2x2 − 3x3 = 0. Hence an eigenvector of A corresponding to λ = 5 is x1 = [1 2 −1]T.
and then x1 = 1 from −7x1 + 2x2 − 3x3 = 0. Hence an eigenvector of A corresponding to λ = 5 is x1 = [1 2 −1]T.
For λ = −3 the characteristic matrix

Hence it has rank 1. From x1 + 2x2 − 3x3 = 0 we have x1 = −2x2 + 3x3. Choosing x2 = 1, x3 = 0 and x2 = 0, x3 = 1, we obtain two linearly independent eigenvectors of A corresponding to λ = −3 [as they must exist by (5), Sec. 7.5, with rank = 1 and n = 3],

and
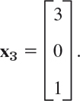
The order Mλ of an eigenvalue λ as a root of the characteristic polynomial is called the algebraic multiplicity of λ. The number mλ of linearly independent eigenvectors corresponding to λ is called the geometric multiplicity of λ. Thus mλ is the dimension of the eigenspace corresponding to this λ.
Since the characteristic polynomial has degree n, the sum of all the algebraic multiplicities must equal n. In Example 2 for λ = −3 we have mλ = Mλ = 2. In general, mλ ![]() Mλ, as can be shown. The difference Δλ = Mλ − mλ is called the defect of λ. Thus Δ−3 = 0 in Example 2, but positive defects Δλ can easily occur:
Mλ, as can be shown. The difference Δλ = Mλ − mλ is called the defect of λ. Thus Δ−3 = 0 in Example 2, but positive defects Δλ can easily occur:
EXAMPLE 3 Algebraic Multiplicity, Geometric Multiplicity. Positive Defect
The characteristic equation of the matrix
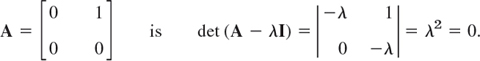
Hence λ = 0 is an eigenvalue of algebraic multiplicity M0 = 2. But its geometric multiplicity is only m0 = 1, since eigenvectors result from −0x1 + x2 = 0, hence x2 = 0, in the form [x1 0]T. Hence for λ = 0 the defect is Δ0 = 1.
Similarly, the characteristic equation of the matrix
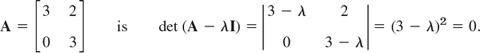
Hence λ = 3 is an eigenvalue of algebraic multiplicity M3 = 2, but its geometric multiplicity is only m3 = 1, since eigenvectors result from 0x1 + 2x2 = 0 in the form [x1 0]T.
EXAMPLE 4 Real Matrices with Complex Eigenvalues and Eigenvectors
Since real polynomials may have complex roots (which then occur in conjugate pairs), a real matrix may have complex eigenvalues and eigenvectors. For instance, the characteristic equation of the skew-symmetric matrix
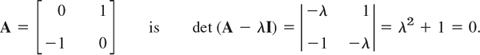
It gives the eigenvalues ![]() . Eigenvectors are obtained from −ix1 + x2 = 0 and ix1 + x2 = 0, respectively, and we can choose x1 = 1 to get
. Eigenvectors are obtained from −ix1 + x2 = 0 and ix1 + x2 = 0, respectively, and we can choose x1 = 1 to get

In the next section we shall need the following simple theorem.
THEOREM 3 Eigenvalues of the Transpose
The transpose AT of a square matrix A has the same eigenvalues as A.
PROOF
Transposition does not change the value of the characteristic determinant, as follows from Theorem 2d in Sec. 7.7.
Having gained a first impression of matrix eigenvalue problems, we shall illustrate their importance with some typical applications in Sec. 8.2.
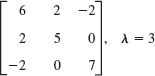
1–16 EIGENVALUES, EIGENVECTORS
Find the eigenvalues. Find the corresponding eigenvectors. Use the given λ or factor in Probs. 11 and 15.





17–20 LINEAR TRANSFORMATIONS AND EIGENVALUES
Find the matrix A in the linear transformation y = Ax, where x = [x1 x2]T (x = [x1 x2 x3]T) are Cartesian coordinates. Find the eigenvalues and eigenvectors and explain their geometric meaning.
- 17. Counterclockwise rotation through the angle π/2 about the origin in R2.
- 18. Reflection about the x1-axis in R2.
- 19. Orthogonal projection (perpendicular projection) of R2 onto the x2-axis.
- 20. Orthogonal projection of R3 onto the plane x2 = x1.
21–25 GENERAL PROBLEMS
- 21. Nonzero defect. Find further 2 × 2 and 3 × 3 matrices with positive defect. See Example 3.
- 22. Multiple eigenvalues. Find further 2 × 2 and 3 × 3 matrices with multiple eigenvalues. See Example 2.
- 23. Complex eigenvalues. Show that the eigenvalues of a real matrix are real or complex conjugate in pairs.
- 24. Inverse matrix. Show that A−1 exists if and only if the eigenvalues λ1, …, λn are all nonzero, and then A−1 has the eigenvalues 1/λ1, …, 1/λn.
- 25. Transpose. Illustrate Theorem 3 with examples of your own.
8.2 Some Applications of Eigenvalue Problems
We have selected some typical examples from the wide range of applications of matrix eigenvalue problems. The last example, that is, Example 4, shows an application involving vibrating springs and ODEs. It falls into the domain of Chapter 4, which covers matrix eigenvalue problems related to ODE's modeling mechanical systems and electrical networks. Example 4 is included to keep our discussion independent of Chapter 4. (However, the reader not interested in ODEs may want to skip Example 4 without loss of continuity.)
EXAMPLE 1 Stretching of an Elastic Membrane
An elastic membrane in the x1x2-plane with boundary circle ![]() (Fig. 160) is stretched so that a point P: (x1, x2) goes over into the point Q: (y1, y2) given by
(Fig. 160) is stretched so that a point P: (x1, x2) goes over into the point Q: (y1, y2) given by

Find the principal directions, that is, the directions of the position vector x of P for which the direction of the position vector y of Q is the same or exactly opposite. What shape does the boundary circle take under this deformation?
Solution. We are looking for vectors x such that y = λx. Since y = Ax, this gives Ax = λx, the equation of an eigenvalue problem. In components, Ax = λx is

The characteristic equation is

Its solutions are λ1 = 8 and λ2 = 2. These are the eigenvalues of our problem. For λ = λ1 = 8, our system (2) becomes

For λ2 = 2, our system (2) becomes

We thus obtain as eigenvectors of A, for instance, [1 1]T corresponding to λ1 and [1 −1]T corresponding to λ2 (or a nonzero scalar multiple of these). These vectors make 45° and 135° angles with the positive x1-direction. They give the principal directions, the answer to our problem. The eigenvalues show that in the principal directions the membrane is stretched by factors 8 and 2, respectively; see Fig. 160.
Accordingly, if we choose the principal directions as directions of a new Cartesian u1u2-coordinate system, say, with the positive u1-semi-axis in the first quadrant and the positive u2-semi-axis in the second quadrant of the x1x2-system, and if we set u1 = r cos φ, u2 = r sin φ, then a boundary point of the unstretched circular membrane has coordinates cos φ, sin φ. Hence, after the stretch we have
![]()
Since cos2φ + sin2φ = 1, this shows that the deformed boundary is an ellipse (Fig. 160)

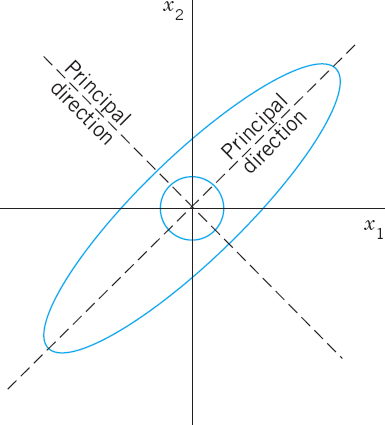
Fig. 160. Undeformed and deformed membrane in Example 1
EXAMPLE 2 Eigenvalue Problems Arising from Markov Processes
Markov processes as considered in Example 13 of Sec. 7.2 lead to eigenvalue problems if we ask for the limit state of the process in which the state vector x is reproduced under the multiplication by the stochastic matrix A governing the process, that is, Ax = x. Hence A should have the eigenvalue 1, and x should be a corresponding eigenvector. This is of practical interest because it shows the long-term tendency of the development modeled by the process.
In that example,

Hence AT has the eigenvalue 1, and the same is true for A by Theorem 3 in Sec. 8.1. An eigenvector x of A for λ = 1 is obtained from

Taking x3 = 1, we get x2 = 6 from −x2/30 + x3/5 = 0 and then x1 = 2 from −3x1/10 + x2/10 = 0. This gives x = [2 6 1]T. It means that in the long run, the ratio Commercial:Industrial:Residential will approach 2:6:1, provided that the probabilities given by A remain (about) the same. (We switched to ordinary fractions to avoid rounding errors.)
EXAMPLE 3 Eigenvalue Problems Arising from Population Models. Leslie Model
The Leslie model describes age-specified population growth, as follows. Let the oldest age attained by the females in some animal population be 9 years. Divide the population into three age classes of 3 years each. Let the “Leslie matrix” be

where l1k is the average number of daughters born to a single female during the time she is in age class k, and lj,j−1(j = 2, 3) is the fraction of females in age class j − 1 that will survive and pass into class j. (a) What is the number of females in each class after 3, 6, 9 years if each class initially consists of 400 females? (b) For what initial distribution will the number of females in each class change by the same proportion? What is this rate of change?
Solution. (a) Initially, ![]() . After 3 years,
. After 3 years,

Similarly, after 6 years the number of females in each class is given by ![]() , and after 9 years we have
, and after 9 years we have ![]() .
.
(b) Proportional change means that we are looking for a distribution vector x such that Lx = λx, where λ is the rate of change (growth if λ > 1, decrease if λ < 1). The characteristic equation is (develop the characteristic determinant by the first column)
![]()
A positive root is found to be (for instance, by Newton's method, Sec. 19.2) λ = 1.2. A corresponding eigenvector x can be determined from the characteristic matrix

where x3 = 0.125 is chosen, x2 = 0.5 then follows from 0.3x2 − 1.2x3 = 0, and x1 = 1 from −1.2x1 + 2.3x2 + 0.4x3 = 0. To get an initial population of 1200 as before, we multiply x by 1200/(1 + 0.5 + 0.125) = 738. Answer: Proportional growth of the numbers of females in the three classes will occur if the initial values are 738, 369, 92 in classes 1, 2, 3, respectively. The growth rate will be 1.2 per 3 years.
EXAMPLE 4 Vibrating System of Two Masses on Two Springs (Fig. 161)
Mass–spring systems involving several masses and springs can be treated as eigenvalue problems. For instance, the mechanical system in Fig. 161 is governed by the system of ODEs
where y1 and y2 are the displacements of the masses from rest, as shown in the figure, and primes denote derivatives with respect to time t. In vector form, this becomes
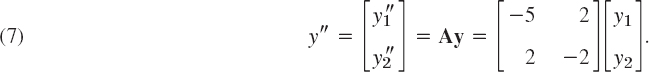

Fig. 161. Masses on springs in Example 4
We try a vector solution of the form
![]()
This is suggested by a mechanical system of a single mass on a spring (Sec. 2.4), whose motion is given by exponential functions (and sines and cosines). Substitution into (7) gives
![]()
Dividing by eωt and writing ω2 = λ, we see that our mechanical system leads to the eigenvalue problem
![]()
From Example 1 in Sec. 8.1 we see that A has the eigenvalues λ1 = −1 and λ2 = −6. Consequently, ![]() , respectively. Corresponding eigenvectors are
, respectively. Corresponding eigenvectors are

From (8) we thus obtain the four complex solutions [see (10), Sec. 2.2]
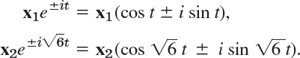
By addition and subtraction (see Sec. 2.2) we get the four real solutions
![]()
A general solution is obtained by taking a linear combination of these,
![]()
with arbitrary constants a1, b1, a2, b2 (to which values can be assigned by prescribing initial displacement and initial velocity of each of the two masses). By (10), the components of y are
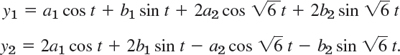
These functions describe harmonic oscillations of the two masses. Physically, this had to be expected because we have neglected damping.
1–6 ELASTIC DEFORMATIONS
Given A in a deformation y = Ax, find the principal directions and corresponding factors of extension or contraction. Show the details.
7–9 MARKOV PROCESSES
Find the limit state of the Markov process modeled by the given matrix. Show the details.
- 7.

- 8.

- 9.

Find the growth rate in the Leslie model (see Example 3) with the matrix as given. Show the details.
- 10.

- 11.

- 12.

13–15 LEONTIEF MODELS1
- 13. Leontief input–output model. Suppose that three industries are interrelated so that their outputs are used as inputs by themselves, according to the 3 × 3 consumption matrix

where ajk is the fraction of the output of industry k consumed (purchased) by industry j. Let pj be the price charged by industry j for its total output. A problem is to find prices so that for each industry, total expenditures equal total income. Show that this leads to Ap = p, where p = [p1 p2 p3]T, and find a solution p with nonnegative p1, p2, p3.
- 14. Show that a consumption matrix as considered in Prob. 13 must have column sums 1 and always has the eigenvalue 1.
- 15. Open Leontief input–output model. If not the whole output but only a portion of it is consumed by the industries themselves, then instead of Ax = x (as in Prob. 13), we have x − Ax = y, where x = [x1 x2 x3]T is produced, Ax is consumed by the industries, and, thus, y is the net production available for other consumers. Find for what production x a given demand vector y = [0.1 0.3 0.1]T can be achieved if the consumption matrix is

16–20 GENERAL PROPERTIES OF EIGENVALUE PROBLEMS
Let A = [ajk] be an n × n matrix with (not necessarily distinct) eigenvalues λ1, …, λn Show.
- 16. Trace. The sum of the main diagonal entries, called the trace of A, equals the sum of the eigenvalues of A.
- 17. “Spectral shift.” A − kI has the eigenvalues λ1 − k, …, λn − k and the same eigenvectors as A.
- 18. Scalar multiples, powers. kA has the eigenvalues kλ1, …, kλn. Am (m = 1, 2, …) has the eigenvalues
 . The eigenvectors are those of A.
. The eigenvectors are those of A. - 19. Spectral mapping theorem. The “polynomial matrix”
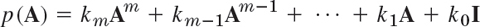
has the eigenvalues

where j = 1, …, n, and the same eigenvectors as A.
- 20. Perron's theorem. A Leslie matrix L with positive l12, l13, l21, l32 has a positive eigenvalue. (This is a special case of the Perron–Frobenius theorem in Sec. 20.7, which is difficult to prove in its general form.)
8.3 Symmetric, Skew-Symmetric, and Orthogonal Matrices
We consider three classes of real square matrices that, because of their remarkable properties, occur quite frequently in applications. The first two matrices have already been mentioned in Sec. 7.2. The goal of Sec. 8.3 is to show their remarkable properties.
DEFINITIONS Symmetric, Skew-Symmetric, and Orthogonal Matrices
A real square matrix A = [ajk] is called
symmetric if transposition leaves it unchanged,

skew-symmetric if transposition gives the negative of A,

orthogonal if transposition gives the inverse of A,

EXAMPLE 1 Symmetric, Skew-Symmetric, and Orthogonal Matrices
The matrices

are symmetric, skew-symmetric, and orthogonal, respectively, as you should verify. Every skew-symmetric matrix has all main diagonal entries zero. (Can you prove this?)
Any real square matrix A may be written as the sum of a symmetric matrix R and a skew-symmetric matrix S, where
![]()

THEOREM 1 Eigenvalues of Symmetric and Skew-Symmetric Matrices
- The eigenvalues of a symmetric matrix are real.
- The eigenvalues of a skew-symmetric matrix are pure imaginary or zero.
This basic theorem (and an extension of it) will be proved in Sec. 8.5.
EXAMPLE 3 Eigenvalues of Symmetric and Skew-Symmetric Matrices
The matrices in (1) and (7) of Sec. 8.2 are symmetric and have real eigenvalues. The skew-symmetric matrix in Example 1 has the eigenvalues 0, −25i, and 25i. (Verify this.) The following matrix has the real eigenvalues 1 and 5 but is not symmetric. Does this contradict Theorem 1?

Orthogonal Transformations and Orthogonal Matrices
Orthogonal transformations are transformations
![]()
With each vector x in Rn such a transformation assigns a vector y in Rn. For instance, the plane rotation through an angle θ
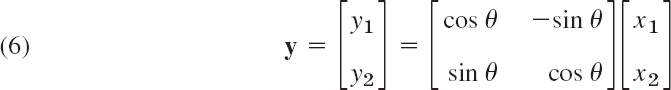
is an orthogonal transformation. It can be shown that any orthogonal transformation in the plane or in three-dimensional space is a rotation (possibly combined with a reflection in a straight line or a plane, respectively).
The main reason for the importance of orthogonal matrices is as follows.
THEOREM 2 Invariance of Inner Product
An orthogonal transformation preserves the value of the inner product of vectors a and b in Rn, defined by
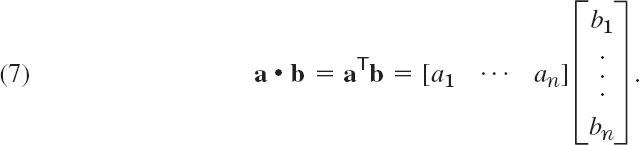
That is, for any a and b in Rn, orthogonal n × n matrix A, and u = Aa, v = Ab we have u • v = a • b.
Hence the transformation also preserves the length or norm of any vector a in given by Rn given by
![]()
PROOF
Let A be orthogonal. Let u = Aa and v = Ab. We must show that u • v = a • b. Now (Aa)T = aTAT by (10d) in Sec. 7.2 and ATA = A−1A = I by (3). Hence
![]()
From this the invariance of ![]() follows if we set b = a.
follows if we set b = a.
Orthogonal matrices have further interesting properties as follows.
THEOREM 3 Orthonormality of Column and Row Vectors
A real square matrix is orthogonal if and only if its column vectors a1, …, an (and also its row vectors) form an orthonormal system, that is,
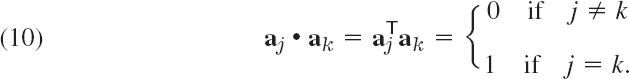
PROOF
(a) Let A be orthogonal. Then A−1A = ATA = I. In terms of column vectors a1, …, an,

The last equality implies (10), by the definition of the n × n unit matrix I. From (3) it follows that the inverse of an orthogonal matrix is orthogonal (see CAS Experiment 12). Now the column vectors of A−1 (=AT) are the row vectors of A. Hence the row vectors of A also form an orthonormal system.
(b) Conversely, if the column vectors of A satisfy (10), the off-diagonal entries in (11) must be 0 and the diagonal entries 1. Hence ATA = I, as (11) shows. Similarly, AAT = I. This implies AT = A−1 because also A−1A = AA−1 = I and the inverse is unique. Hence A is orthogonal. Similarly when the row vectors of A form an orthonormal system, by what has been said at the end of part (a).
THEOREM 4 Determinant of an Orthogonal Matrix
The determinant of an orthogonal matrix has the value +1 or −1.
PROOF
From det AB = det A det B (Sec. 7.8, Theorem 4) and det AT = det A (Sec. 7.7, Theorem 2d), we get for an orthogonal matrix
![]()
EXAMPLE 4 Illustration of Theorems 3 and 4
The last matrix in Example 1 and the matrix in (6) illustrate Theorems 3 and 4 because their determinants are −1 and +1, as you should verify.
THEOREM 5 Eigenvalues of an Orthogonal Matrix
The eigenvalues of an orthogonal matrix A are real or complex conjugates in pairs and have absolute value 1.
The first part of the statement holds for any real matrix A because its characteristic polynomial has real coefficients, so that its zeros (the eigenvalues of A) must be as indicated. The claim that |λ| = 1 will be proved in Sec. 8.5.
EXAMPLE 5 Eigenvalues of an Orthogonal Matrix
The orthogonal matrix in Example 1 has the characteristic equation
![]()
Now one of the eigenvalues must be real (why?), hence +1 or −1. Trying, we find −1. Division by λ + 1 gives −(λ2 − 5λ/3 + 1) = 0 and the two eigenvalues ![]() , which have absolute value 1. Verify all of this.
, which have absolute value 1. Verify all of this.
Looking back at this section, you will find that the numerous basic results it contains have relatively short, straightforward proofs. This is typical of large portions of matrix eigenvalue theory.
1–10 SPECTRUM
Are the following matrices symmetric, skew-symmetric, or orthogonal? Find the spectrum of each, thereby illustrating Theorems 1 and 5. Show your work in detail.

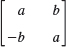
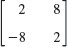

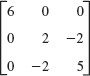
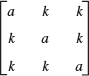

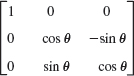

- WRITING PROJECT. Section Summary. Summarize the main concepts and facts in this section, giving illustrative examples of your own.
- CAS EXPERIMENT. Orthogonal Matrices.
(a) Products. Inverse. Prove that the product of two orthogonal matrices is orthogonal, and so is the inverse of an orthogonal matrix. What does this mean in terms of rotations?
(b) Rotation. Show that (6) is an orthogonal transformation. Verify that it satisfies Theorem 3. Find the inverse transformation.
(c) Powers. Write a program for computing powers Am(m = 1, 2, …) of a 2 × 2 matrix A and their spectra. Apply it to the matrix in Prob. 1 (call it A). To what rotation does A correspond? Do the eigenvalues of Am have a limit as m → ∞?
(d) Compute the eigenvalues of (0.9A)m, where A is the matrix in Prob. 1. Plot them as points. What is their limit? Along what kind of curve do these points approach the limit?
(e) Find A such that y = Ax is a counterclockwise rotation through 30° in the plane.
13–20 GENERAL PROPERTIES
- 13. Verification. Verify the statements in Example 1.
- 14. Verify the statements in Examples 3 and 4.
- 15. Sum. Are the eigenvalues of A + B sums of the eigenvalues of A and of B?
- 16. Orthogonality. Prove that eigenvectors of a symmetric matrix corresponding to different eigenvalues are orthogonal. Give examples.
- 17. Skew-symmetric matrix. Show that the inverse of a skew-symmetric matrix is skew-symmetric.
- 18. Do there exist nonsingular skew-symmetric n × n matrices with odd n?
- 19. Orthogonal matrix. Do there exist skew-symmetric orthogonal 3 × 3 matrices?
- 20. Symmetric matrix. Do there exist nondiagonal symmetric 3 × 3 matrices that are orthogonal?
8.4 Eigenbases. Diagonalization. Quadratic Forms
So far we have emphasized properties of eigenvalues. We now turn to general properties of eigenvectors. Eigenvectors of an n × n matrix A may (or may not!) form a basis for Rn. If we are interested in a transformation y = Ax, such an “eigenbasis” (basis of eigenvectors)—if it exists—is of great advantage because then we can represent any x in Rn uniquely as a linear combination of the eigenvectors x1, …, xn say,
![]()
And, denoting the corresponding (not necessarily distinct) eigenvalues of the matrix A by λ1, …, λn, we have Axj = λjxj, so that we simply obtain
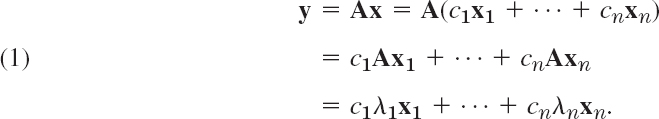
This shows that we have decomposed the complicated action of A on an arbitrary vector x into a sum of simple actions (multiplication by scalars) on the eigenvectors of A. This is the point of an eigenbasis.
Now if the n eigenvalues are all different, we do obtain a basis:
THEOREM 1 Basis of Eigenvectors
If an n × n matrix A has n distinct eigenvalues, then A has a basis of eigenvectors x1, … xn for Rn.
PROOF
All we have to show is that x1, …, xn are linearly independent. Suppose they are not. Let r be the largest integer such that {x1, …, xr} is a linearly independent set. Then r < n and the set {x1, …, xr, xr+1} is linearly dependent. Thus there are scalars c1, …, cr+1, not all zero, such that
![]()
(see Sec. 7.4). Multiplying both sides by A and using Axj = λjxj, we obtain
![]()
To get rid of the last term, we subtract λr+1 times (2) from this, obtaining
![]()
Here c1(λ1 − λr+1) = 0, …, cr(λr − λr+1) = 0 since {x1, …, xr} is linearly independent. Hence c1 = … = cr = 0, since all the eigenvalues are distinct. But with this, (2) reduces to cr+1xr+1 = 0, hence cr+1 = 0, since xr+1 ≠ 0 (an eigenvector!). This contradicts the fact that not all scalars in (2) are zero. Hence the conclusion of the theorem must hold.
EXAMPLE 1 Eigenbasis. Nondistinct Eigenvalues. Nonexistence
The matrix ![]() has a basis of eigenvectors
has a basis of eigenvectors ![]() corresponding to the eigenvalues λ1 = 8, λ2 = 2. (See Example 1 in Sec. 8.2.)
corresponding to the eigenvalues λ1 = 8, λ2 = 2. (See Example 1 in Sec. 8.2.)
Even if not all n eigenvalues are different, a matrix A may still provide an eigenbasis for Rn. See Example 2 in Sec. 8.1, where n = 3.
On the other hand, A may not have enough linearly independent eigenvectors to make up a basis. For instance, A in Example 3 of Sec. 8.1 is

Actually, eigenbases exist under much more general conditions than those in Theorem 1. An important case is the following.
For a proof (which is involved) see Ref. [B3], vol. 1, pp. 270–272.
EXAMPLE 2 Orthonormal Basis of Eigenvectors
The first matrix in Example 1 is symmetric, and an orthonormal basis of eigenvectors is ![]() ,
, ![]() .
.
Similarity of Matrices. Diagonalization
Eigenbases also play a role in reducing a matrix A to a diagonal matrix whose entries are the eigenvalues of A. This is done by a “similarity transformation,” which is defined as follows (and will have various applications in numerics in Chap. 20).
DEFINITION Similar Matrices. Similarity Transformation
An n × n matrix ![]() is called similar to an n × n matrix A if
is called similar to an n × n matrix A if
![]()
for some (nonsingular!) n × n matrix P. This transformation, which gives ![]() from A, is called a similarity transformation.
from A, is called a similarity transformation.
The key property of this transformation is that it preserves the eigenvalues of A:
THEOREM 3 Eigenvalues and Eigenvectors of Similar Matrices
If ![]() is similar to A, then
is similar to A, then ![]() has the same eigenvalues as A.
has the same eigenvalues as A.
Furthermore, if x is an eigenvector of A, then y = P−1x is an eigenvector of ![]() corresponding to the same eigenvalue.
corresponding to the same eigenvalue.
From Ax = λx (λ an eigenvalue, x ≠ 0) we get P−1Ax = λP−1x. Now I = PP−1. By this identity trick the equation P−1Ax = λP−1x gives
![]()
Hence λ is an eigenvalue of ![]() and P−1x a corresponding eigenvector. Indeed, P−1x ≠ 0 because P−1x = 0 would give x = Ix = PP−1x = P0 = 0, contradicting x ≠ 0.
and P−1x a corresponding eigenvector. Indeed, P−1x ≠ 0 because P−1x = 0 would give x = Ix = PP−1x = P0 = 0, contradicting x ≠ 0.
EXAMPLE 3 Eigenvalues and Vectors of Similar Matrices

Here P−1 was obtained from (4*) in Sec. 7.8 with det P = 1. We see that ![]() has the eigenvalues λ1 = 3, λ2 = 2. The characteristic equation of A is (6 − λ)(−1 − λ) + 12 = λ2 − 5λ + 6 = 0. It has the roots (the eigenvalues of A) λ1 = 3, λ2 = 2, confirming the first part of Theorem 3.
has the eigenvalues λ1 = 3, λ2 = 2. The characteristic equation of A is (6 − λ)(−1 − λ) + 12 = λ2 − 5λ + 6 = 0. It has the roots (the eigenvalues of A) λ1 = 3, λ2 = 2, confirming the first part of Theorem 3.
We confirm the second part. From the first component of (A − λI)x = 0 we have (6 − λ)x1 − 3x2 = 0. For λ = 3 this gives 3x1 − 3x2 = 0, say, x1 = [1 1]T. For λ = 2 it gives 4x1 − 3x2 = 0, say, x2 = [3 4]T. In Theorem 3 we thus have
![]()
Indeed, these are eigenvectors of the diagonal matrix ![]() .
.
Perhaps we see that x1 and x2 are the columns of P. This suggests the general method of transforming a matrix A to diagonal form D by using P = X, the matrix with eigenvectors as columns.
By a suitable similarity transformation we can now transform a matrix A to a diagonal matrix D whose diagonal entries are the eigenvalues of A:
THEOREM 4 Diagonalization of a Matrix
If an n × n matrix A has a basis of eigenvectors, then

is diagonal, with the eigenvalues of A as the entries on the main diagonal. Here X is the matrix with these eigenvectors as column vectors. Also,
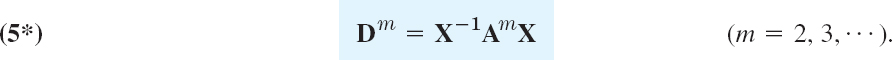
Let x1, …, xn be a basis of eigenvectors of A for Rn. Let the corresponding eigenvalues of A be λ1, …, λn, respectively, so that Ax1 = λ1x1, …, Axn = λnxn. Then X = [x1 … xn] has rank n, by Theorem 3 in Sec. 7.4. Hence X−1 exists by Theorem 1 in Sec. 7.8. We claim that
![]()
where D is the diagonal matrix as in (5). The fourth equality in (6) follows by direct calculation. (Try it for n = 2 and then for general n.) The third equality uses Axk = λkxk. The second equality results if we note that the first column of AX is A times the first column of X, which is x1, and so on. For instance, when n = 2 and we write x1 = [ x11 x21], x2 = [x12 x22], we have

If we multiply (6) by X−1 from the left, we obtain (5). Since (5) is a similarity transformation, Theorem 3 implies that D has the same eigenvalues as A. Equation (5*) follows if we note that
![]()
Diagonalize

Solution. The characteristic determinant gives the characteristic equation −λ3 − λ2 + 12λ = 0. The roots (eigenvalues of A) are λ1 = 3, λ2 = −4, λ3 = 0. By the Gauss elimination applied to (A − λI)x = 0 with λ = λ1, λ2, λ3 we find eigenvectors and then X−1 by the Gauss–Jordan elimination (Sec. 7.8, Example 1). The results are

Calculating AX and multiplying by X−1 from the left, we thus obtain

Quadratic Forms. Transformation to Principal Axes
By definition, a quadratic form Q in the components x1, …, xn of a vector x is a sum of n2 terms, namely,

A = [ajk] is called the coefficient matrix of the form. We may assume that A is symmetric, because we can take off-diagonal terms together in pairs and write the result as a sum of two equal terms; see the following example.
EXAMPLE 5 Quadratic Form. Symmetric Coefficient Matrix
Let
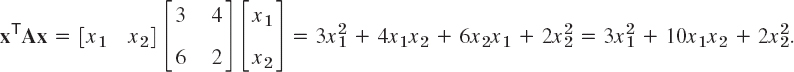
Here 4 + 6 = 10 = 5 + 5. From the corresponding symmetric matrix C = [cjk], where ![]() , thus c11 = 3, c12 = c21 = 5, c22 = 2, we get the same result; indeed,
, thus c11 = 3, c12 = c21 = 5, c22 = 2, we get the same result; indeed,
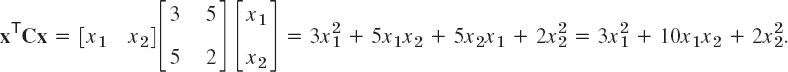
Quadratic forms occur in physics and geometry, for instance, in connection with conic sections (ellipses ![]() , etc.) and quadratic surfaces (cones, etc.). Their transformation to principal axes is an important practical task related to the diagonalization of matrices, as follows.
, etc.) and quadratic surfaces (cones, etc.). Their transformation to principal axes is an important practical task related to the diagonalization of matrices, as follows.
By Theorem 2, the symmetric coefficient matrix A of (7) has an orthonormal basis of eigenvectors. Hence if we take these as column vectors, we obtain a matrix X that is orthogonal, so that X−1 = XT. From (5) we thus have A = XDX−1 = XDXT. Substitution into (7) gives
![]()
If we set XTx = y, then, since XT = X−1, we have X−1x = y and thus obtain
![]()
Furthermore, in (8) we have xTX = (XTx)T = yT and XTx = y, so that Q becomes simply
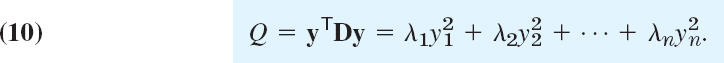
This proves the following basic theorem.
THEOREM 5 Principal Axes Theorem
The substitution (9) transforms a quadratic form
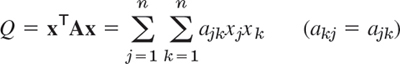
to the principal axes form or canonical form (10), where λ1, …, λn are the (not necessarily distinct) eigenvalues of the (symmetric!) matrix A, and X is an orthogonal matrix with corresponding eigenvectors x1, …, xn, respectively, as column vectors.
EXAMPLE 6 Transformation to Principal Axes. Conic Sections
Find out what type of conic section the following quadratic form represents and transform it to principal axes:
![]()
Solution. We have Q = xTAx, where
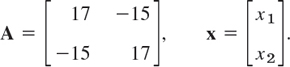
This gives the characteristic equation (17 − λ)2 − 152 = 0. It has the roots λ1 = 2, λ2 = 32. Hence (10) becomes
![]()
We see that Q = 128 represents the ellipse ![]() , that is,
, that is,
![]()
If we want to know the direction of the principal axes in the x1x2-coordinates, we have to determine normalized eigenvectors from (A − λI)x = 0 with λ = λ1 = 2 and λ = λ2 = 32 and then use (9). We get

hence
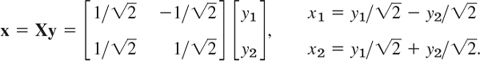
This is a 45° rotation. Our results agree with those in Sec. 8.2, Example 1, except for the notations. See also Fig. 160 in that example.
1–5 SIMILAR MATRICES HAVE EQUAL EIGENVALUES
Verify this for A and A = P−1AP. If y is an eigenvector of P, show that x = Py are eigenvectors of A. Show the details of your work.


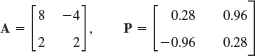
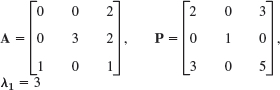
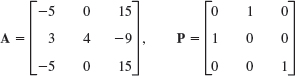
- PROJECT. Similarity of Matrices. Similarity is basic, for instance, in designing numeric methods.
(a) Trace. By definition, the trace of an n × n matrix A = [ajk] is the sum of the diagonal entries,

Show that the trace equals the sum of the eigenvalues, each counted as often as its algebraic multiplicity indicates. Illustrate this with the matrices A in Probs. 1, 3, and 5.
(b) Trace of product. Let B = [bjk] be n × n. Show that similar matrices have equal traces, by first proving
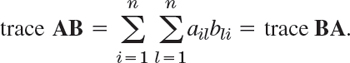
(c) Find a relationship between
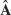 in (4) and
in (4) and 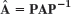 .
.(d) Diagonalization. What can you do in (5) if you want to change the order of the eigenvalues in D, for instance, interchange d11 = λ1 and d22 = λ2?
- No basis. Find further 2 × 2 and 3 × 3 matrices without eigenbasis.
- Orthonormal basis. Illustrate Theorem 2 with further examples.
9–16 DIAGONALIZATION OF MATRICES
Find an eigenbasis (a basis of eigenvectors) and diagonalize. Show the details.
- 9.

- 10.
- 11.

- 12.

- 13.

- 14.

- 15.
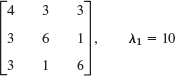
- 16.
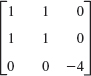
17–23 PRINCIPAL AXES. CONIC SECTIONS
What kind of conic section (or pair of straight lines) is given by the quadratic form? Transform it to principal axes. Express xT = [x1 x2] in terms of the new coordinate vector yT = [y1 y2], as in Example 6.
- 17.
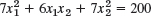
- 18.
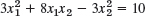
- 19.

- 20.
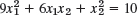
- 21.
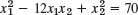
- 22.
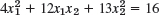
- 23.

- 24. Definiteness. A quadratic form Q(x) = xTAx and its (symmetric!) matrix A are called (a) positive definite if Q(x) > 0 for all x ≠ 0, (b) negative definite if Q(x) < 0 for all x ≠ 0, (c) indefinite if Q(x) takes both positive and negative values. (See Fig. 162.) [Q(x) and A are called positive semidefinite (negative semidefinite) if Q(x)
 0 (Q(x)
0 (Q(x)  0) for all x.] Show that a necessary and sufficient condition for (a), (b), and (c) is that the eigenvalues of A are (a) all positive, (b) all negative, and (c) both positive and negative. Hint. Use Theorem 5.
0) for all x.] Show that a necessary and sufficient condition for (a), (b), and (c) is that the eigenvalues of A are (a) all positive, (b) all negative, and (c) both positive and negative. Hint. Use Theorem 5. - 25. Definiteness. A necessary and sufficient condition for positive definiteness of a quadratic form Q(x) = xTAx with symmetric matrix A is that all the principal minors are positive (see Ref. [B3], vol. 1, p. 306), that is,
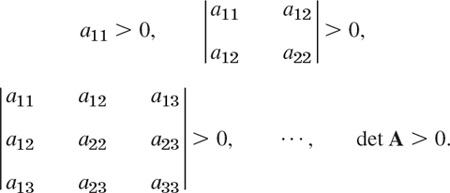
Show that the form in Prob. 22 is positive definite, whereas that in Prob. 23 is indefinite.

8.5 Complex Matrices and Forms. Optional
The three classes of matrices in Sec. 8.3 have complex counterparts which are of practical interest in certain applications, for instance, in quantum mechanics. This is mainly because of their spectra as shown in Theorem 1 in this section. The second topic is about extending quadratic forms of Sec. 8.4 to complex numbers. (The reader who wants to brush up on complex numbers may want to consult Sec. 13.1.)
Notations
![]() = [
= [![]() jk] is obtained from A = [ajk] by replacing each entry ajk = α + iβ (α, β real) with its complex conjugate
jk] is obtained from A = [ajk] by replacing each entry ajk = α + iβ (α, β real) with its complex conjugate ![]() jk = α − iβ. Also,
jk = α − iβ. Also, ![]() T = [
T = [![]() kj] is the transpose of
kj] is the transpose of ![]() , hence the conjugate transpose of A.
, hence the conjugate transpose of A.

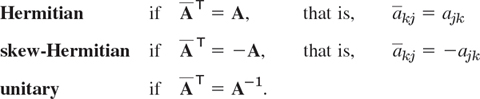
The first two classes are named after Hermite (see footnote 13 in Problem Set 5.8).
From the definitions we see the following. If A is Hermitian, the entries on the main diagonal must satisfy ![]() jj = ajj; that is, they are real. Similarly, if A is skew-Hermitian, then
jj = ajj; that is, they are real. Similarly, if A is skew-Hermitian, then ![]() jj = −ajj. If we set ajj = α + iβ, this becomes α − iβ = −(α + iβ). Hence α = 0, so that ajj must be pure imaginary or 0.
jj = −ajj. If we set ajj = α + iβ, this becomes α − iβ = −(α + iβ). Hence α = 0, so that ajj must be pure imaginary or 0.
EXAMPLE 2 Hermitian, Skew-Hermitian, and Unitary Matrices

are Hermitian, skew-Hermitian, and unitary matrices, respectively, as you may verify by using the definitions.
If a Hermitian matrix is real, then ![]() T = AT = A. Hence a real Hermitian matrix is a symmetric matrix (Sec. 8.3).
T = AT = A. Hence a real Hermitian matrix is a symmetric matrix (Sec. 8.3).
Similarly, if a skew-Hermitian matrix is real, then ![]() T = AT = −A. Hence a real skew-Hermitian matrix is a skew-symmetric matrix.
T = AT = −A. Hence a real skew-Hermitian matrix is a skew-symmetric matrix.
Finally, if a unitary matrix is real, then ![]() T = AT = A−1. Hence a real unitary matrix is an orthogonal matrix.
T = AT = A−1. Hence a real unitary matrix is an orthogonal matrix.
This shows that Hermitian, skew-Hermitian, and unitary matrices generalize symmetric, skew-symmetric, and orthogonal matrices, respectively.
Eigenvalues
It is quite remarkable that the matrices under consideration have spectra (sets of eigenvalues; see Sec. 8.1) that can be characterized in a general way as follows (see Fig. 163).

Fig. 163. Location of the eigenvalues of Hermitian, skew-Hermitian, and unitary matrices in the complex λ-plane
(a) The eigenvalues of a Hermitian matrix (and thus of a symmetric matrix) are real.
(b) The eigenvalues of a skew-Hermitian matrix (and thus of a skew-symmetric matrix) are pure imaginary or zero.
(c) The eigenvalues of a unitary matrix (and thus of an orthogonal matrix) have absolute value 1.

PROOF
We prove Theorem 1. Let λ be an eigenvalue and x an eigenvector of A. Multiply Ax = λx from the left by ![]() , thus
, thus ![]() , and divide by
, and divide by ![]()
![]() , which is real and not 0 because x ≠ 0. This gives
, which is real and not 0 because x ≠ 0. This gives

(a) If A is Hermitian, ![]() T = A or AT =
T = A or AT = ![]() and we show that then the numerator in (1) is real, which makes λ real.
and we show that then the numerator in (1) is real, which makes λ real. ![]() Ax is a scalar; hence taking the transpose has no effect. Thus
Ax is a scalar; hence taking the transpose has no effect. Thus
![]()
Hence, ![]() equals its complex conjugate, so that it must be real. (a + ib = a − ib implies b = 0.)
equals its complex conjugate, so that it must be real. (a + ib = a − ib implies b = 0.)
(b) If A is skew-Hermitian, AT = −![]() and instead of (2) we obtain
and instead of (2) we obtain
![]()
so that ![]() equals minus its complex conjugate and is pure imaginary or 0. (a + ib = −(a − ib) implies a = 0.)
equals minus its complex conjugate and is pure imaginary or 0. (a + ib = −(a − ib) implies a = 0.)
(c) Let A be unitary. We take Ax = λx and its conjugate transpose
![]()
and multiply the two left sides and the two right sides,
![]()
But A is unitary, ![]() T = A−1, so that on the left we obtain
T = A−1, so that on the left we obtain
![]()
Together, ![]() . We now divide by
. We now divide by ![]() to get |λ|2 = 1. Hence |λ| = 1.
to get |λ|2 = 1. Hence |λ| = 1.
This proves Theorem 1 as well as Theorems 1 and 5 in Sec. 8.3.
Key properties of orthogonal matrices (invariance of the inner product, orthonormality of rows and columns; see Sec. 8.3) generalize to unitary matrices in a remarkable way.
To see this, instead of Rn we now use the complex vector space Cn of all complex vectors with n complex numbers as components, and complex numbers as scalars. For such complex vectors the inner product is defined by (note the overbar for the complex conjugate)

The length or norm of such a complex vector is a real number defined by
![]()
THEOREM 2 Invariance of Inner Product
A unitary transformation, that is, y = Ax with a unitary matrix A, preserves the value of the inner product (4), hence also the norm (5).
PROOF
The proof is the same as that of Theorem 2 in Sec. 8.3, which the theorem generalizes. In the analog of (9), Sec. 8.3, we now have bars,
![]()
The complex analog of an orthonormal system of real vectors (see Sec. 8.3) is defined as follows.
DEFINITION Unitary System
A unitary system is a set of complex vectors satisfying the relationships
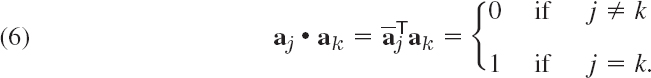
Theorem 3 in Sec. 8.3 extends to complex as follows.
THEOREM 3 Unitary Systems of Column and Row Vectors
A complex square matrix is unitary if and only if its column vectors (and also its row vectors) form a unitary system.
The proof is the same as that of Theorem 3 in Sec. 8.3, except for the bars required in ![]() T = A−1 and in (4) and (6) of the present section.
T = A−1 and in (4) and (6) of the present section.
THEOREM 4 Determinant of a Unitary Matrix
Let A be a unitary matrix. Then its determinant has absolute value one, that is, |det A| = 1.
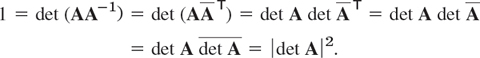
EXAMPLE 4 Unitary Matrix Illustrating Theorems 1c and 2–4
For the vectors aT = [2 −i] and bT = [1 + i 4i] we get ![]() T = [2 i] and
T = [2 i] and ![]() Tb = 2(1 + i) − 4 = −2 + 2i and with
Tb = 2(1 + i) − 4 = −2 + 2i and with
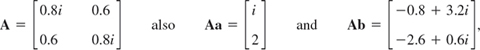
as one can readily verify. This gives (![]()
![]() )TAb = −2 + 2i, illustrating Theorem 2. The matrix is unitary. Its columns form a unitary system,
)TAb = −2 + 2i, illustrating Theorem 2. The matrix is unitary. Its columns form a unitary system,
![]()
and so do its rows. Also, det A = −1. The eigenvalues are 0.6 + 0.8i and −0.6 + 0.8i, with eigenvectors [1 1]T and [1 −1]T, respectively.
Theorem 2 in Sec. 8.4 on the existence of an eigenbasis extends to complex matrices as follows.
THEOREM 5 Basis of Eigenvectors
A Hermitian, skew-Hermitian, or unitary matrix has a basis of eigenvectors for Cn that is a unitary system.
For a proof see Ref. [B3], vol. 1, pp. 270–272 and p. 244 (Definition 2).
The matrices A, B, C in Example 2 have the following unitary systems of eigenvectors, as you should verify.
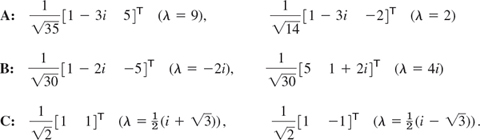
Hermitian and Skew-Hermitian Forms
The concept of a quadratic form (Sec. 8.4) can be extended to complex. We call the numerator ![]() in (1) a form in the components x1, …, xn of x, which may now be complex. This form is again a sum of n2 terms
in (1) a form in the components x1, …, xn of x, which may now be complex. This form is again a sum of n2 terms
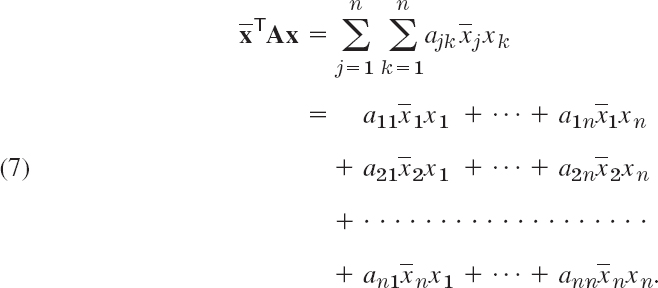
A is called its coefficient matrix. The form is called a Hermitian or skew-Hermitian form if A is Hermitian or skew-Hermitian, respectively. The value of a Hermitian form is real, and that of a skew-Hermitian form is pure imaginary or zero. This can be seen directly from (2) and (3) and accounts for the importance of these forms in physics. Note that (2) and (3) are valid for any vectors because, in the proof of (2) and (3), we did not use that x is an eigenvector but only that ![]() is real and not 0.
is real and not 0.
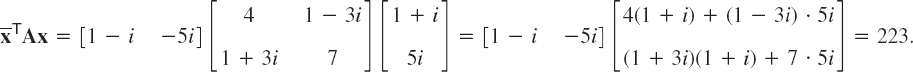
Clearly, if A and x in (4) are real, then (7) reduces to a quadratic form, as discussed in the last section.
1–6 EIGENVALUES AND VECTORS
Is the given matrix Hermitian? Skew-Hermitian? Unitary? Find its eigenvalues and eigenvectors.
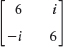
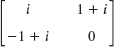
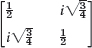


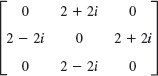
- Pauli spin matrices. Find the eigenvalues and eigenvectors of the so-called Pauli spin matrices and show that
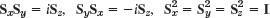 , where
, where

- Eigenvectors. Find eigenvectors of A, B, C in Examples 2 and 3.
Is the matrix A Hermitian or skew-Hermitian? Find ![]() . Show the details.
. Show the details.
- 9.
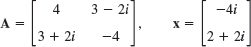
- 10.

- 11.
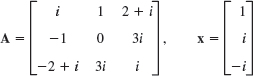
- 12.

13–20 GENERAL PROBLEMS
- 13. Product. Show that
 for any n × n Hermitian A, skew-Hermitian B, and unitary C.
for any n × n Hermitian A, skew-Hermitian B, and unitary C. - 14. Product. Show
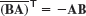 for A and B in Example 2. For any n × n Hermitian A and skew-Hermitian B.
for A and B in Example 2. For any n × n Hermitian A and skew-Hermitian B. - 15. Decomposition. Show that any square matrix may be written as the sum of a Hermitian and a skew-Hermitian matrix. Give examples.
- 16. Unitary matrices. Prove that the product of two unitary n × n matrices and the inverse of a unitary matrix are unitary. Give examples.
- 17. Powers of unitary matrices in applications may sometimes be very simple. Show that C12 = I in Example 2. Find further examples.
- 18. Normal matrix. This important concept denotes a matrix that commutes with its conjugate transpose, A
 T = TA. Prove that Hermitian, skew-Hermitian, and unitary matrices are normal. Give corresponding examples of your own.
T = TA. Prove that Hermitian, skew-Hermitian, and unitary matrices are normal. Give corresponding examples of your own. - 19. Normality criterion. Prove that A is normal if and only if the Hermitian and skew-Hermitian matrices in Prob. 18 commute.
- 20. Find a simple matrix that is not normal. Find a normal matrix that is not Hermitian, skew-Hermitian, or unitary.
CHAPTER 8 REVIEW QUESTIONS AND PROBLEMS
- In solving an eigenvalue problem, what is given and what is sought?
- Give a few typical applications of eigenvalue problems.
- Do there exist square matrices without eigenvalues?
- Can a real matrix have complex eigenvalues? Can a complex matrix have real eigenvalues?
- Does a 5 × 5 matrix always have a real eigenvalue?
- What is algebraic multiplicity of an eigenvalue? Defect?
- What is an eigenbasis? When does it exist? Why is it important?
- When can we expect orthogonal eigenvectors?
- State the definitions and main properties of the three classes of real matrices and of complex matrices that we have discussed.
- What is diagonalization? Transformation to principal axes?
11–15 SPECTRUM
Find the eigenvalues. Find the eigenvectors.
- 11.
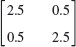
- 12.

- 13.

- 14.

- 15.
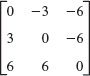
16–17 SIMILARITY
Verify that A and ![]() have the same spectrum.
have the same spectrum.
- 16.
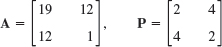
- 17.
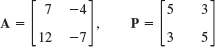
- 18.

Find an eigenbasis and diagonalize.
- 9.

- 20.

- 21.

22–25 CONIC SECTIONS. PRINCIPAL AXES
Transform to canonical form (to principal axes). Express [x1 x2]T in terms of the new variables [y1 y2]T.
- 22.
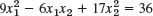
- 23.
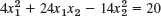
- 24.
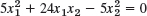
- 25.
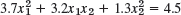
SUMMARY OF CHAPTER 8 Linear Algebra: Matrix Eigenvalue Problems
The practical importance of matrix eigenvalue problems can hardly be overrated. The problems are defined by the vector equation
![]()
A is a given square matrix. All matrices in this chapter are square. λ is a scalar. To solve the problem (1) means to determine values of λ, called eigenvalues (or characteristic values) of A, such that (1) has a nontrivial solution x (that is, x ≠ 0), called an eigenvector of A corresponding to that λ. An n × n matrix has at least one and at most n numerically different eigenvalues. These are the solutions of the characteristic equation (Sec. 8.1)
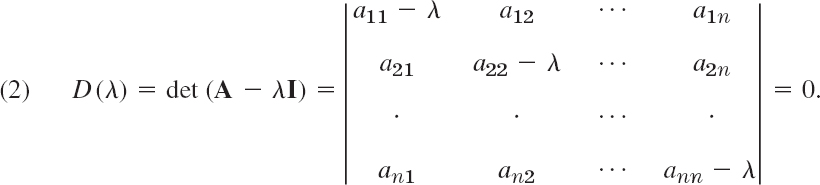
D(λ) is called the characteristic determinant of A. By expanding it we get the characteristic polynomial of A, which is of degree n in λ. Some typical applications are shown in Sec. 8.2.
Section 8.3 is devoted to eigenvalue problems for symmetric (AT = A), symmetric (AT = −A), and orthogonal matrices (AT = A−1). Section 8.4 concerns the diagonalization of matrices and the transformation of quadratic forms to principal axes and its relation to eigenvalues.
Section 8.5 extends Sec. 8.3 to the complex analogs of those real matrices, called Hermitian (AT = A), skew-Hermitian (AT = −A), and unitary matrices (![]() T = A−1). All the eigenvalues of a Hermitian matrix (and a symmetric one) are real. For a skew-Hermitian (and a skew-symmetric) matrix they are pure imaginary or zero. For a unitary (and an orthogonal) matrix they have absolute value 1.
T = A−1). All the eigenvalues of a Hermitian matrix (and a symmetric one) are real. For a skew-Hermitian (and a skew-symmetric) matrix they are pure imaginary or zero. For a unitary (and an orthogonal) matrix they have absolute value 1.