
1
A Comprehensive Review on Text Classification and Text Mining Techniques Using Spam Dataset Detection
Tamannas Siddiqui and Abdullah Yahya Abdullah Amer⋆
Department of Computer Science, Aligarh Muslim University, Aligarh, UP, India
Abstract
Text data mining techniques are an essential tool for dealing with raw text data (future fortune). The Text data mining process of securing exceptional knowledge and information from the unstructured text is a fundamental principle of Text data mining to facilitate relevant insights by analyzing a huge volume of raw data in association with Artificial Intelligence natural language processing NLP Machine Learning algorithms. The salient features of text data mining are attracted by the contemporary business applications to have their extraordinary benefits in global area operations. In this, a brief review of text mining techniques, such as clustering, information extraction, text preprocessing, information retrieval, text classification, and text mining applications, that demonstrate the significance of text mining, the predominant text mining techniques, and the predominant contemporary applications that are using text mining. This review includes various existing algorithms, text feature extractions, compression methods, and evaluation techniques. Finally, we used a spam dataset for classification detection data and a three classifier algorithm with TF-IDF feature extraction and through that model achieved higher accuracy with Naïve Bayes. Illustrations of text classification as an application in areas such as medicine, law, education, etc., are also presented.
Keywords: Text mining, text classification, spam detection, text preprocessing, text analysis
1.1 Introduction
Text data mining techniques are predominantly used for extracting relevant and associated patterns based on specific words or sets of phrases. Text data mining is associated with text clustering, text classification, and the product of granular taxonomy, sentiment analysis, entity relation modeling, and document summarization [1]. Prominent techniques in text mining techniques include extraction, summarization, categorization, retrieval, and clustering. These techniques are used to infer distinguished, quality knowledge from text from previously unknown information and different written resources obtained from books, emails, reviews, emails, and articles with the help of information retrieval, linguistic analysis, pattern recognition, information extraction, or information extraction tagging and annotation [2]. Text preprocessing is the predominant functionality in text data mining. Text preprocessing is essential to bring the text into a form that can be predictable and analyzable for text data mining. Text preprocessing can be done in different phases to formulate the text into predictable and analyzable forms. These are namely lowercasing, lemmatization, stemming, stop word removal, and tokenization. These important text preprocess steps are predominantly performed by machine learning algorithms for natural language processing tasks. These preprocessing steps implement data cleaning and transformation to eliminate outliers and make it standardized to create a suitable model to incorporate the text data mining process [3]. Text data mining techniques are predominantly used for records management, distinct document searches, e-discovery, organizing a large set of a text data, analysis and monitoring of understandable online text in internet communication and blogs, identification of large textual datasets associated with patients during a clinical area, and clarification of knowledge for the readers with more extraordinary search experience [4]. Text data mining techniques are predominantly used in scientific literature mining, business, biomedical, and security applications, computational sociology, and digital humanities as shown in Figure 1.1 below.
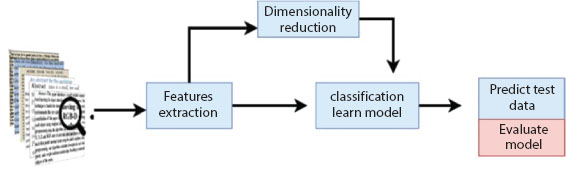
Figure 1.1 Overview of text classification.
Table 1.1 Text classification compared model classifiers.
| Model classifiers | Authors | Architecture | Features extraction | Corpus |
|---|---|---|---|---|
| SVM and KNN | C. W. Lee et al. [7] | Gravity Inverse Moment | Similarity TF-IDF vectorizer | Wikipedia |
| Logistic Regression | L. Kumar et al. [13] | Bayesian Logistic Regression | TF-IDF | RCV1-v2 |
| Naive Bayes NB | A. Swapna et al. [9] | Weight Enhancing Method | Weights words | Reuters-31678 |
| SVM | T. Singh et al. [11] | String Subsequence Kernel | TF-IDF vectorizer | 20 Newsgroups |
The paper reviews text data mining techniques, various steps involved in text preprocessing, and multiple applications that implement text data mining methods discussed in Table 1.1.
1.2 Text Mining Techniques
Text Mining (TM) indicates informational content involved in several sources like newspapers, books, social media posts, email, and URLs. Text data summary and classification are typical applications of text mining, particularly among different fields. It is appropriate to discuss some of the techniques applied to achieve them through the step set shown in Figure 1.2 below.
1.2.1 Data Mining
Text mining is empowered in big data analytics to analyze unstructured textual data to extract new knowledge and distinguish significant patterns and correlations hidden in the huge amount of data sets. Big data analytics are predominantly used for extracting the information and patterns that are hidden implicitly in the data sets in the form of automatic or semi-automatic unstructured formats or natural language texts. To perform this test, mining operations, unsupervised learning algorithms, and supervised learning algorithms or methods are predominantly used. These methods’ functionality is used for classification and prediction by using a set of predictors to reveal hidden structures in the information database [5]. In this process, text mining is performed using pattern matching on regular documents and unstructured manuscripts [6].
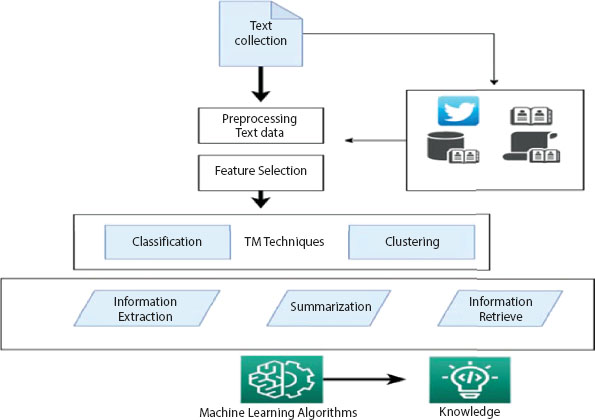
Figure 1.2 Text data mining techniques.
1.2.2 Information Retrieval
Information Retrieval [IR] is a prominent method in text data mining techniques. The fundamental principle of IR is identifying documents stored in the database in unstructured formats, which meets the requirements of the information needed from the large collection of documents stored in the datasets. IR is available in three models: Boolean Model, Vector Model, and Probabilistic Model. In text data mining techniques, IR plays a vital role with the indexing system and collection of documents [7]. This method is predominantly used for locating a specific item in natural language documents. IR is used for learned knowledge extraction to convert text within structured data for interesting mining relationships [8]. It has been identified as a big issue to discover the appropriate designs and analyze text records from huge amounts of data. Text data mining technique IR has resolved the issue and successfully selected attractive patterns from the greatest knowledge data sets. IR techniques are predominantly used for choosing the appropriate text documents from the huge volume of databases with enhanced speed within a short period. The text data mining technique IR extracts the exact required text documents from the greatest databases and presents the accuracy and relevance of results [9].
1.2.3 Natural Language Processing (NLP)
NLP linguistics is subfield of computer science and AI. The fundamental principle of NLP is to deal with the connection between computer machines and humans with an assistant of NLP to read, interpret, learn, and make sense of languages spoken by humans in a valuable way. It is powered by AI, which can facilitate the machines to read, understand, interpret, manipulate, and derive meaning from human languages [10]. It is a prominent AI technology used in text data mining to transform the unstructured text depicted in documents and databases into normalized, structured data suitable for performing analysis or implementing machine learning algorithms [11]. Long Short-Term Memory [LSTM] is one of the predominant AI Machine Learning algorithms to remember values with a recurrent neural network’s help. Seq2seq model is another predominant model used in the NLP technique, which works with encoder-decoder structure. In this model, it initially built the vocabulary list to identify the correct grammar syntax. It works with some tags to identify the structured and unstructured language identified in the documents. The named entity recognition model is another predominant model to identify relevant names and classify names by their entity. It is used to find the names of people, names of places, and any other important entity in the given dataset in text or documents. The NLP process features a Preferences’ Graph [12]. It is utilized to build a set of user preferences. While the document is written, the repetitively chosen tense, adjectives, conjunctions, and prepositions are identified and NLP creates a User Preference Graph. Based on the graph, it predicts the next word of the sentence to calculate the probability theory. Word embedding is another inbuilt mechanism obtained from the feature training and language model of NLP. The terms and idioms are planned into a vector of the actual number of graphs during this process. The model is designed from big unstructured text to generate the most probable output from the input text searched from the documents’ database [13].
1.2.4 Information Extraction
Information Extraction [IE] is the beginning point for a computer to estimate unstructured language documents. IE is predominantly used to distinguish the important relationships involved in the document as shown in Figure 1.3. It is working to distinguish the predefined arrangements in a text with the pattern matching method. Information that cannot be utilized for mining is processed and evaluated by Information Extraction when the documents consist of information. IE is rich with a fundamental mechanism to distinguish the unstructured text available in the articles, blogs, emails, reviews, and other documents with predefined arrangements for post-processing. Post-processing is essential for performing web mining and searching tools. IE is associated with the quality of extracting knowledge from text. IE performs the extracting knowledge from text operations from the unstructured text instead of abstract knowledge. IE performs text mining tasks and further methods to explore the information from the text data in hand [14].
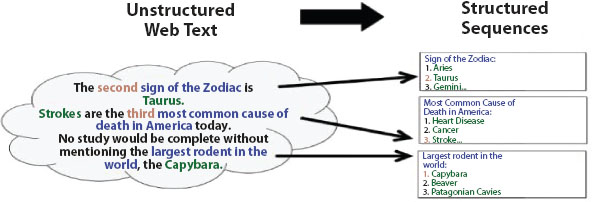
Figure 1.3 Information extraction.
1.2.5 Text Summarization
Text summarization is the part of text data mining techniques used to distill the predominant data from a source to generate an abridged version for a specific user and related task. The process of summarization is a step-by-step process. Step one is converting the paragraph into sentences. Step two is text processing. Step three is tokenization. Step four evaluates the weighted occurrence frequency of the words and finally, step five substitutes the words with the respective weighted frequencies. The process of summarization occurs in two ways. These are extractive summarization and abstractive summarization. The fundamental utility of summarization is to reduce the text’s content while preserving the meaning of the text. Abstractive summarization is a technique the summary produces by generating new sentences by rephrasing or using novel words. The process finally extracts the important sentences from the document. The extractive summarization extracts the important information or sentence from the given text document or original document. A statistical method is needed to be implemented on the original document [19].
1.2.6 Text Categorization
The fundamental objective of text categorization in text mining is to sort the documents into groups. This can be done automatically by employing the technique to perform the classification using natural language processing and machine learning. This process categorizes consumer reviews, customer support tickets, blogs, complaints, and other content-rich text documents [20]. Text categorization has several features made from attributes of the documents. Predominantly, the features are developed from words and broader content of the corpus for higher dimensional features. Text categorization plays a vital role in performing news classification, sentiment analysis, and web page classification. Text categorization can be implemented along with Linear Support Vector Machine algorithms to achieve the best results [21].
1.2.7 Clustering
In clustering, the main objective is to perform cluster analysis of content-based text records. It uses ML and NLP to recognize and classify unstructured text data using extracted descriptors from a targeted document available in the database. Word clustering is part and parceling of text clustering for part sets of information in subsets of semantically related words. It is aimed to perform duties ranging from word sense or basic disambiguation to knowledge retrieval [22]. Unsupervised text clustering is widely used in NLP to group similar data. It obtains the distance between the points. The predominant clustering methods are namely soft clustering and hard clustering. Hard clustering performs the grouping task for every object that belongs to exactly one cluster. Hard clustering allows an object to be grouped with one or more clusters based on its meaning and nature [23].
1.2.8 Information Visualization
Information Visualization is meant for information analysis and enables knowledge discovery via interactive graphical representations of textual data. It enables exploration and understanding. It can be formulated in the form of a tag or a word with varied size, position based on frequency, categorization, or importance of the tag. Information visualization or data visualization can be performed by employing seeing factors as maps, graphs, and charts to understand the pattern extracted from text data. These main objectives of text visualization are used to summarize large amounts of text, formulate text data that is easy to understand, identify the insights in qualitative data, and discover hidden trends and patterns of the text. Text visualization can be done with the help of machine learning. This can be performed to make sense of qualitative data quickly, easily, and at scale. Word clouds are a great initiation for visualizing qualitative data. World clouds facilitate insights useful for exploratory analysis to learn the insights of the dataset and define labeling criteria for more advanced text analysis. AI Machine Learning algorithms are used for sorting the data into categories. Text visualization enables the extraction of the data’s actionable insights and reveals the trends of the data [24].
1.2.9 Question Answer
Question answering is a subfield of information retrieval and NLP linguistic computer science is concerned with creating systems in order to automatically answer questions modeled through human language. Implementing machine learning algorithms for the process of Question/Answer in a full data-driven architecture can produce a practical solution for answering the question with the right short answer rather than giving a list of possible answers. This can be implemented in the NLP to generate an accurate answer with the knowledge database’s text similarity. Implementing machine learning algorithms can produce the administration of the documents, analyze profiles and phrases, and perform marketing activities to generate alerts to post the company branding information. A QA system can be built with the help of python code and facilitate the user to post the question, developing the internal mechanism to extract the question and search for the matching documents with approximate string-matching function from the knowledge base and extract the exact answer for the question as shown in Figure 1.4 below [25].

Figure 1.4 Question answering system.
1.3 Dataset and Preprocessing Steps
In this review, we are utilizing a ‘spam_ham_dataset’ from Kaggle. This is data set contains a total of 5172 documents with four columns. In the dataset, emails were considered spam (1) or not (0), i.e., unwanted business e-mail. The dataset is split into two parts: 70% is the training set and 30% is the testing set. The experiment was conducted on the required dataset of both the training set and testing set [15].
1.3.1 Text Preprocess
Text preprocessing is predominant in text data mining for dimensionality reduction. Once the text is available in the knowledge database, it should be preprocessed to implement the Machine Learning model. It is essential to perform preprocessing on the data with essential steps, namely Tokenization, Lower Casing, Filtering, Stemming, and Lemmatization [16]. The documents available in the knowledge database are described as a vector in a multi-dimensional area. Every single word has a unique dimension discussed below in Table 1.2 [33].
1.4 Feature Extraction
Text feature extraction involves carrying out a dictionary of terms from the textual data then converting them into a feature set available to the classifier. Next, we will show some techniques that can be applied to extract features from text data.
Table 1.2 Preprocessing steps.
| Preprocessing | Description |
|---|---|
| 1. Tokenization | Is the method of dividing the sentence within terms [26] |
| 2. Filtering | Token filtering is the process of filtering out any tokens that are not useful for application. The token filtering process eliminates the digits, punctuation marks, stop-word tokens, and other unnecessary tokens in the text [27]. |
| 3. Lemmatization | Lemmatization is the process of resolving the term to Lemma, meaning the part of speech of the term. Lemmatization transforms the word into a proper root form with a part of the speech tagger [28]. |
| 4. Stemming | Is the method used for transforming a term to its root; this process is associated with the normalization task associated with bluntly removing word affixes [29] |
1.4.1 Term Frequency – Inverse Document Frequency
A difficulty with the BoW method is that the terms with high-frequency display control in the data cannot provide much information about the model. Also, due to that difficulty, control-specified words that have a lower score may be ignored. To resolve that difficulty, the frequency of words is rescaled by analyzing where the words frequently happen compared to the total text document. Here, we applied TF-IDF. Term Frequency measures frequency of the word in a popular text and the Inverse Document Frequency IDF number represents words within the whole text document [30].
1.4.2 Bag of Words (BoW)
BoW is common among different feature extraction techniques and it forms a word as the port feature set of total word instance. It is then recognized as a “bag” of words for a process that does not mind the orders of the words or how many times a word occurs, but just represents words already within a record of words discussed below in Table 1.3 [31].
Table 1.3 Advantages and disadvantages of feature extraction.
| Model | Advantages | Disadvantages |
|---|---|---|
| TF-IDF | Simple to calculate Simple to divide the similarity among recognized TFIDF Easy to extract a descriptive word within the text document General items do not impact an outcome because of IDF (for example, “are”, “is”, etc.) | BoW does not catch situations in the text (syntactic) BoW does not catch purpose meaning in the text (semantics) |
| BoW | Simple to compute Simple to count a similarity among documents using the BoW Easy extraction and metric descriptive words by a document Task within unknown terms | It does not capture the place in the text (syntactic)
|
1.5 Supervised Machine Learning Classification
In this part, we summarize existing text dataset classification algorithms. We define the KNN [17] algorithm which is utilized for data classification. Then, we describe other methods like logistic regression and Naïve Bayes [18], which are commonly utilized in the scientific community as classification techniques. Classification algorithms associated with the linear support vector machine have achieved high accuracy in the classification of data and performance evaluation text data mining operations.
1.6 Evaluation
The experimental evaluation of text classifiers measures efficiency (i.e., capacity to execute the correct classification). Accuracy, recall, and precision are generally employed to measure the effectiveness of a text classifier. Accuracy (FP+FN/TP+TN+FP+FN = 1-accuracy), on the other hand, is not w idely used for text classification applications because it is insensitive to variations in the number of correct decisions due to the large value of the denominator (TP + TN), as discussed below in Table 1.4.
1.7 Experimentation and Discussion Results for Spam Detection Data
In the experimental part of the review study, we used spam data to classify files as either spam or non-spam by using machine learning algorithms. Our experimental was done on the Windows system in a Python virtual environment with Anaconda Jupyter to implement the code to build a machine learning model. These steps are executed in five phases. The first phase is to import the library, the second is to load and preprocess the dataset, the third phase uses TF-IDF feature extraction techniques, the fourth phase is to train and test our model (after dividing the dataset into two parts: 70% training set and 30% testing set to fit the model), and the last phase is to predict and evaluate the model by using amusement precision, recall, accuracy, and f score confusion matrix, as shown in Table 1.5 and Figure 1.5 below.
Table 1.4 Confusion matrix in machine learning.
| Accuracy | TP+TN/TP+TN+FP+FN |
| Recall | TP/TP+FN |
| Precision | TP/TP+FP |
| F1-Measure | 2(P⋆R)/(P+R) |
Table 1.5 shows the outcome of three classifier models. Through accuracy, recall, precision, and F1-Measure, Naïve Bayes achieved the higher accuracy at around 97.06% among classifier models for detection of spam files from a data set.
As shown in the Figure 1.5, Naïve Bayes achieved higher results and higher improvement accuracy with a data trained spam model using K-Nearest Neighbor and Logistic Regression algorithms.
Table 1.5 Spam dataset classification.
| Algorithm used | Accuracy (%) | Recall (%) | Precision (%) | F1-measure |
|---|---|---|---|---|
| Naïve Bayes | 97.06 | 97.76 | 95.65 | 97.78 |
| K-Nearest Neighbor | 93.12 | 92.55 | 92.01 | 93.09 |
| Logistic Regression | 94.89 | 91.32 | 93.21 | 94.76 |
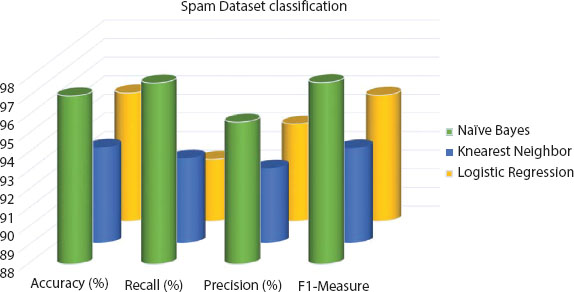
Figure 1.5 Spam dataset classification.
1.8 Text Mining Applications
Text data mining is predominantly used in different applications. Text mining’s fundamental objective is information extraction, information retrieval, categorization, clustering, and summarization. These activities are helping business applications with extensive operational capacity. The main applications have already implemented text data mining techniques. These are namely risk management applications, knowledge management applications, content enrichment applications, business intelligence applications, contextual advertising applications, customer care services applications, cybercrime prevention applications, spam filtering, data analysis from social media, and fraud detection through claims investigation applications, as shown in Figure 1.6 below [32, 34].
1.9 Text Classification Support
1.9.1 Health
Most text data in the health and medical domain displays unstructured patient information by vague terms with typographical errors. Here, the role of text classification process data and dealing with it in order to predict illness uses machine learning algorithms. The medical field consists of selecting medical diagnoses to special class values taken from many categories and this is a field of healthcare where text classification techniques can be deeply valuable [24].
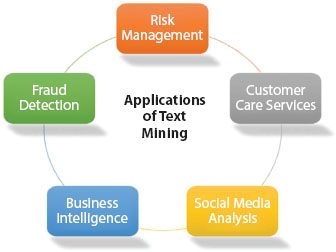
Figure 1.6 Applications of text data mining [32].
1.9.2 Business and Marketing
Profitable organizations and companies use social networks such as Facebook and Twitter for marketing purposes such as shopping, buying, selling, etc. Through mining and sentiments analysis, businesses know what a customer desires about the producer in order to improve and increase product from the producer. Additionally, text classification in organizations and companies is an important tool for businesses to obtain more customers efficiently.
1.9.3 Law
Government institutions have generated large volumes of legal record text documents. Analysis and retrieving that data manually is so difficult. Here, a system is required to deal with information and process it automatically in order to help lawyers and their clients [22]. Organization of those record text documents is the foremost difficulty to the law community. Building a system to classify documents is helpful for the law community.
1.10 Conclusions
In this review paper, we present a review of text data mining techniques with relevant descriptions. Text data mining techniques are applied to extract readable knowledge from raw text data sets regularly into the unstructured data. So, in this paper we presented the gist of various previous research works presented on the predominant text mining techniques, namely Data Mining, Text Classification, Information Extraction, Question Answering, Topic Tracking, Natural Language Processing, Information Retrieval, Text Summarization, Text Categorization, Clustering, and Information Visualization. The paper has presented the important mechanism of preprocessing text data mining with four steps: Tokenization, Filtering, Lemmatization, and Stemming. We have discussed the process of text data mining by presenting the fields that use text mining applications. Lastly, we compared the most popular text classification algorithms. Finally, we used a spam dataset for classification detection data and a three classifier algorithm with TF-IDF feature extraction, achieving higher accuracy with Naïve Bayes around 97.06%. Illustrations of the usage of text classification as support for applications in medicine, law, education, etc. are related in a separate part.
References
- 1. S. S. Kermode and V. B. Bhagat, “A Review: Detection and Blocking Social Media Malicious Posts,” Int. J. Mod. Trends Eng. Res., vol. 3, no. 11, pp. 130–136, 2016, doi: 10.21884/IJMTER.2016.3133.Q4M8O.
- 2. M. Allahyari et al., “A Brief Survey of Text Mining: Classification, Clustering and Extraction Techniques,” 2017, [Online]. Available: http://arxiv.org/abs/1707.02919.
- 3. C. C. Aggarwal and C. X. Zhai, “Mining text data,” Min. Text Data, vol. 9781461432, pp. 1–522, 2013, doi: 10.1007/978-1-4614-3223-4.
- 4. M. A. Zende, M. B. Tuplondhe, S. B. Walunj, and S. V. Parulekar, “Text mining using python,” no. 3, pp. 2393–2395, 2016.
- 5. N. F. F. Da Silva, E. R. Hruschka, and E. R. Hruschka, “Tweet sentiment analysis with classifier ensembles,” Decis. Support Syst., vol. 66, pp. 170–179, 2014, doi: 10.1016/j.dss.2014.07.003.
- 6. A. Nielsen, “Python programming — text and web mining,” Aust. J. Plant Physiol., vol. 21, pp. 507–516, 2011, [Online]. Available: http://www2.imm.dtu.dk/pubdb/views/edoc_download.php/5781/pdf/imm5781.pdf.
- 7. C. W. Lee, S. A. Licorish, B. T. R. Savarimuthu, and S. G. Macdonell, “Augmenting text mining approaches with social network analysis to understand the complex relationships among users’ requests: A case study of the android operating system,” Proc. Annu. Hawaii Int. Conf. Syst. Sci., vol. 2016-March, pp. 1144–1153, 2016, doi: 10.1109/HICSS.2016.145.
- 8. N. U. Pannala, C. P. Nawarathna, J. T. K. Jayakody, L. Rupasinghe, and K. Krishnadeva, “Supervised Learning-Based Approach to Aspect Based Sentiment Analysis,” 2016 IEEE Int. Conf. Comput. Inf. Technol., pp. 662–666, 2016, doi: 10.1109/CIT.2016.107.
- 9. A. Swapna, K. G. Guptha, and K. Geetha, “Efficient Approach for Web Search Personalization in User Behavior Supported Web Server Log Files Using Web Usage Mining,” vol. 2, no. 4, pp. 189–196,
- 10. G. Barbier, “Social Network Data Analytics,” 2011, doi: 10.1007/978-1-4419-8462-3.
- 11. T. Singh, M. Kumari, T. L. Pal, and A. Chauhan, “Current Trends in Text Mining for Social Media,” Int. J. Grid Distrib. Comput., vol. 10, no. 6, pp. 11–28, 2017, doi: 10.14257/ijgdc.2017.10.6.02.
- 12. A. Shahrestani, M. Feily, R. Ahmad, and S. Ramadass, “Architecture for applying data mining and visualization on network flow for botnet traffic detection,” ICCTD 2009 - 2009 Int. Conf. Comput. Technol. Dev., vol. 1, pp. 33–37, 2009, doi: 10.1109/ICCTD.2009.82.
- 13. L. Kumar and P. K. Bhatia, “Available Online at www.jgrcs.info TEXT MINING: CONCEPTS, PROCESS, AND APPLICATIONS,” vol. 4, no. 3, pp. 36–39, 2013.
- 14. K. N. S. S. V Prasad, S. K. Saritha, and D. Saxena, “A Survey Paper on Concept Mining in Text Documents,” Int. J. Comput. Appl., vol. 166, no. 11, pp. 7–10, 2017.
- 15. p. Anitha and C. Guru Rao, “ Email Spam Filtering Using Machine Learning Based Xgboost Classifier Method,” Int. J. Adv. Comput. Sci. Appl., Vol.12 No.11 (2021), pp. 2182-2190, doi: 10.14569/IJACSA.2015.060121.
- 16. N. T. and A. M., “Investigating Crimes using Text Mining and Network Analysis,” Int. J. Comput. Appl., vol. 126, no. 8, pp. 19–25, 2015, doi: 10.5120/ ijca2015906134.
- 17. M. Zareapoor and S. K. R, “Feature Extraction or Feature Selection for Text Classification: A Case Study on Phishing Email Detection,” Int. J. Inf. Eng. Electron. Bus., vol. 7, no. 2, pp. 60–65, 2015, doi: 10.5815/ijieeb.2015.02.08.
- 18. D. Saxena, S. K. Saritha, and K. N. S. S. V. Prasad, “Survey on Feature Extraction methods in Object,” Int. J. Comput. Appl., vol. 166, no. 11, pp. 11–17, 2017.
- 19. S. A. Salloum, M. Al-Emran, A. A. Monem, and K. Shaalan, “A Survey of Text Mining in Social Media: Facebook and Twitter Perspectives,” Adv. Sci. Technol. Eng. Syst. J., vol. 2, no. 1, pp. 127–133, 2017, doi: 10.25046/aj020115.
- 20. M. Neeraja and J. Prakash, “Detecting Malicious Posts in Social Networks Using Text Analysis,” vol. 5, no. 6, pp. 2015–2017, 2016.
- 21. G. S. L. Vishal Gupta, “A Survey of Text Mining Techniques and Applications,” J. Emerg. Technol. web Intell., vol. 1, no. 1, p. 17, 2009, doi: 10.4304/jetwi.1.1.60-76.
- 22. M. Sukanya and S. Biruntha, “Techniques on text mining,” Proc. 2012 IEEE Int. Conf. Adv. Commun. Control Comput. Technol. ICACCCT 2012, no. 978, pp. 269–271, 2012, doi: 10.1109/ICACCCT.2012.6320784.
- 23. T. Siddiqui, A. Y. A. Amer, and N. A. Khan, “Criminal Activity Detection in Social Network by Text Mining: Comprehensive Analysis,” 2019 4th Int. Conf. Inf. Syst. Comput. Networks, ISCON 2019, pp. 224–229, 2019, doi: 10.1109/ISCON47742.2019.9036157.
- 24. A. Yahya, A. Amer, and T. Siddiqui, “Detection of Covid-19 Fake News text data using Random Forest and Decision tree Classifiers Abstract:,” vol. 18, no. 12, pp. 88–100, 2020.
- 25. M. R. Begam, “Survey: Tools and Techniques implemented in Crime Data Sets,” vol. 2, no. 6, pp. 707–710, 2015.
- 26. M. Ramageri, “DATA MINING TECHNIQUES AND APPLICATIONS,” vol. 1, no. 4, pp. 301.
- 27. G. Nandi and a. Das, “A Survey on Using Data Mining Techniques for Online Social Network Analysis.,” Int. J. Comput. Sci. Issues, vol. 10, no. 6, pp. 162–167, 2013, [Online]. Available: http://search.ebscohost.com/login.aspx?direct=true&profile=ehost&scope=site&authtype=crawler&jrnl=16940784&AN=93404019&h=MWYzsNVeP2Q8klAFiWFHW3PUpgJLZxRIpB1jfSK4qJfBbaMUEp4nY/oJdYPRHc4xHL0dBYfuGxhZsmiP7ToLBg==&crl=c.
- 28. T. Siddiqui, N. A. Khan, and M. A. Khan, “PMKBEA: A Process Model Using Knowledge Base Software Engineering Approach,” pp. 5–7, 2011.
- 29. S. Alami and O. Elbeqqali, “Cybercrime profiling: Text mining techniques to detect and predict criminal activities in microblog posts,” 2015 10th Int. Conf. Intell. Syst. Theor. Appl. SITA 2015, 2015, doi: 10.1109/SITA.2015.7358435.
- 30. “Build Your First Text Classifier in Python with Logistic Regression | Kavita Ganesan.” https://kavita-ganesan.com/news-classifier-with-logistic-regression-in-python/#.X4xyddD7Q7e (accessed Oct. 18, 2020).
- 31. V. Kumar and L. Velide, “A DATA MINING APPROACH FOR PREDICTION AND TREATMENT Supervised machine learning algorithm:” vol. 3, no. 1. pp. 73–79, 2014.
- 32. P. C. Thirumal and N. Nagarajan, “Utilization of data mining techniques for the diagnosis of diabetes mellitus - A case study,” ARPN Journal of Engineering and Applied Sciences, vol. 10, no. 1. pp. 8–13, 2015.
- 33. E. M. G. Younis, “Sentiment Analysis and Text Mining for Social Media Microblogs using Open Source Tools: An Empirical Study,” Int. J. Comput. Appl., vol. 112, no. 5, pp. 44–48, 2015, doi: 10.1093/ojls/gqi017.
- 34. Amer A.Y.A., Siddiqui T. (2021) Detecting Text-Bullying on Twitter Using Machine Learning Algorithms. In: Bhattacharya M., Kharb L., Chahal D. (eds) Information, Communication and Computing Technology. ICICCT 2021. Communications in Computer and Information Science, vol 1417. Springer, Cham. https://doi.org/10.1007/978-3-030-88378-2_17
Note
- ⋆ Corresponding author: [email protected]