
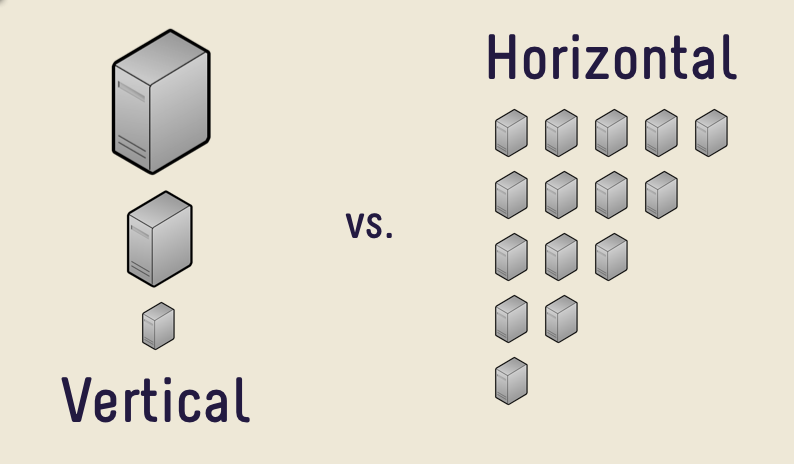
In database systems and computing systems in general, we have two ways to improve performance. The first one is to simply replace our servers with more powerful ones, keeping the same network topology and systems architecture. This is called vertical scaling.
An advantage of vertical scaling is that it is simple, from an operational standpoint, especially with cloud providers such as Amazon making it a matter of a few clicks to replace an m2.medium with an m2.extralarge server instance. Another advantage is that we don't need to make any code changes, and so there is little to no risk of something going catastrophically wrong.
The main disadvantage of vertical scaling is that there is a limit to it; we can only get servers that are as powerful as those that our cloud provider can give to us.
A related disadvantage is that getting more powerful servers generally comes with an increase in cost that is not linear but exponential. So, even if our cloud provider offers more powerful instances, we will hit the cost effectiveness barrier before we hit the limit of our department's credit card.
The second way to improve performance is by using the same servers with the same capacity and increase their number. This is called horizontal scaling.
Horizontal scaling offers the advantage of theoretically being able to scale exponentially while remaining practical enough for real-world applications. The main disadvantage is that it can be operationally more complex and requires code changes and the careful design of the system upfront. Horizontal scaling is also more complex when it comes to the system because it requires communication between the different servers over network links that are not as reliable as inter-process communication on a single server. The following diagram shows the difference between horizontal and vertical scaling:

{kind=link}
To understand scaling, it's important to understand the limitations of single-server systems. A server is typically bound by one or more of the following characteristics:
- CPU: A CPU-bound system is one that is limited by our CPU's speed. A task such as the multiplication of matrices that can fit in RAM will be CPU bound because there is a specific number of steps that have to be performed in the CPU without any disk or memory access needed for the task to complete. In this case, CPU usage is the metric that we need to keep track of.
- I/O: Input-output bound systems are similarly limited by the speed of our storage system (HDD or SSD). A task such as reading large files from a disk to load into memory will be I/O bound as there is little to do in terms of CPU processing; the great majority of the time is spent reading the files from the disk. The important metrics to keep track of are all the metrics related to disk access, the reads per second, and the writes per second, compared to the practical limit of our storage system.
- Memory and cache: Memory-bound and cache-bound systems are restricted by the amount of available RAM memory and/or the cache size that we have assigned to them. A task that multiplies matrices larger than our RAM size will be memory bound, as it will need to page in/out data from the disk to perform the multiplication. The important metric to keep track of is the memory used. This may be misleading in MongoDB MMAPv1, as the storage engine will allocate as much memory as possible through the filesystem cache.
In the WiredTiger storage engine, on the other hand, if we don't allocate enough memory for the core MongoDB process, out-of-memory errors may kill it, and this is something that we want to avoid at all costs.
Monitoring memory usage has to be done both directly through the operating system and indirectly by keeping a track of page in/out data. An increasing memory paging number is often an indication that we are running short of memory and the operating system is using virtual address space to keep up.
MongoDB's sharding is simple enough to set up and operate, and this has contributed to its huge success over the years as it provides the advantages of horizontal scaling without requiring a large commitment of engineering and operations resources.
That being said, it's really important to get sharding right from the beginning, as it is extremely difficult from an operational standpoint to change the configuration once it has been set up. Sharding should not be an afterthought, but rather a key architectural design decision from an early point in the design process.