
CHAPTER 21
Numerics for ODEs and PDEs

Ordinary differential equations (ODEs) and partial differential equations (PDEs) play a central role in modeling problems of engineering, mathematics, physics, aeronautics, astronomy, dynamics, elasticity, biology, medicine, chemistry, environmental science, economics, and many other areas. Chapters 1–6 and 12 explained the major approaches to solving ODEs and PDEs analytically. However, in your career as an engineer, applied mathematicians, or physicist you will encounter ODEs and PDEs that cannot be solved by those analytic methods or whose solutions are so difficult that other approaches are needed. It is precisely in these real-world projects that numeric methods for ODEs and PDEs are used, often as part of a software package. Indeed, numeric software has become an indispensable tool for the engineer.
This chapter is evenly divided between numerics for ODEs and numerics for PDEs. We start with ODEs and discuss, in Sec. 21.1, methods for first-order ODEs. The main initial idea is that we can obtain approximations to the solution of such an ODE at points that are a distance h apart by using the first two terms of Taylor's formula from calculus. We use these approximations to construct the iteration formula for a method known as Euler's method. While this method is rather unstable and of little practical use, it serves as a pedagogical tool and a starting point toward understanding more sophisticated methods such as the Runge–Kutta method and its variant the Runga–Kutta–Fehlberg (RKF) method, which are popular and useful in practice. As is usual in mathematics, one tends to generalize mathematical ideas. The methods of Sec. 21.1 are one-step methods, that is, the current approximation uses only the approximation from the previous step. Multistep methods, such as the Adams–Bashforth methods and Adams–Moulton methods, use values computed from several previous steps. We conclude numerics for ODEs with applying Runge–Kutta–Nyström methods and other methods to higher order ODEs and systems of ODEs.
Numerics for PDEs are perhaps even more exciting and ingenious than those for ODEs. We first consider PDEs of the elliptic type (Laplace, Poisson). Again, Taylor's formula serves as a starting point and lets us replace partial derivatives by difference quotients. The end result leads to a mesh and an evaluation scheme that uses the Gauss–Seidel method (here also know as Liebmann's method). We continue with methods that use grids to solve Neuman and mixed problems (Sec. 21.5) and conclude with the important Crank–Nicholson method for parabolic PDEs in Sec. 21.6.
Sections 21.1 and 21.2 may be studied immediately after Chap. 1 and Sec. 21.3 immediately after Chaps. 2–4, because these sections are independent of Chaps. 19 and 20.
Sections 21.4–21.7 on PDEs may be studied immediately after Chap. 12 if students have some knowledge of linear systems of algebraic equations.
Prerequisite: Secs. 1.1–1.5 for ODEs, Secs. 12.1–12.3, 12.5, 12.10 for PDEs.
References and Answers to Problems: App. 1 Part E (see also Parts A and C), App. 2.
21.1 Methods for First-Order ODEs
Take a look at Sec. 1.2, where we briefly introduced Euler's method with an example. We shall develop Euler's method more rigorously. Pay close attention to the derivation that uses Taylor's formula from calculus to approximate the solution to a first-order ODE at points that are a distance h apart. If you understand this approach, which is typical for numerics for ODEs, then you will understand other methods more easily.
From Chap. 1 we know that an ODE of the first order is of the form F(x, y, y′) = 0 and can often be written in the explicit form y′ = f(x, y). An initial value problem for this equation is of the form
![]()
where x0 and y0 are given and we assume that the problem has a unique solution on some open interval a < x < b containing x0.
In this section we shall discuss methods of computing approximate numeric values of the solution y(x) of (1) at the equidistant points on the x-axis
![]()
where the step size h is a fixed number, for instance, 0.2 or 0.1 or 0.01, whose choice we discuss later in this section. Those methods are step-by-step methods, using the same formula in each step. Such formulas are suggested by the Taylor series
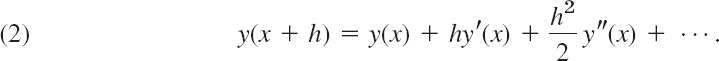
Formula (2) is the key idea that lets us develop Euler's method and its variant called—you guessed it—improved Euler method, also known as Heun's method. Let us start by deriving Euler's method.
For small h3, h3, … in (2) are very small. Dropping all of them gives the crude approximation
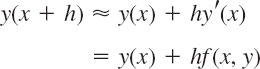
and the corresponding Euler method (or Euler–Cauchy method)
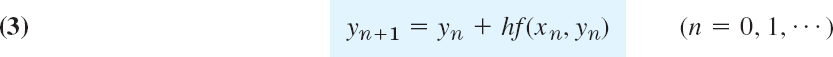
discussed in Sec. 1.2. Geometrically, this is an approximation of the curve of by a polygon whose first side is tangent to this curve at (see Fig. 8 in Sec. 1.2).
Error of the Euler Method. Recall from calculus that Taylor's formula with remainder has the form
![]()
(where x ![]() ξ
ξ ![]() x + h). It shows that, in the Euler method, the truncation error in each step or local truncation error is proportional to h2, written O(h2), where O suggests order (see also Sec. 20.1). Now, over a fixed x-interval in which we want to solve an ODE, the number of steps is proportional to 1/h. Hence the total error or global error is proportional to h2(1/h) = h1. For this reason, the Euler method is called a first-order method. In addition, there are roundoff errors in this and other methods, which may affect the accuracy of the values y1, y2, … more and more as n increases.
x + h). It shows that, in the Euler method, the truncation error in each step or local truncation error is proportional to h2, written O(h2), where O suggests order (see also Sec. 20.1). Now, over a fixed x-interval in which we want to solve an ODE, the number of steps is proportional to 1/h. Hence the total error or global error is proportional to h2(1/h) = h1. For this reason, the Euler method is called a first-order method. In addition, there are roundoff errors in this and other methods, which may affect the accuracy of the values y1, y2, … more and more as n increases.
Automatic Variable Step Size Selection in Modern Software. The idea of adaptive integration, as motivated and explained in Sec. 19.5, applies equally well to the numeric solution of ODEs. It now concerns automatically changing the step size h depending on the variability of y′ = f determined by
![]()
Accordingly, modern software automatically selects variable step sizes hn so that the error of the solution will not exceed a given maximum size TOL (suggesting tolerance). Now for the Euler method, when the step size is h = hn, the local error at is xn is about ![]() . We require that this be equal to a given tolerance TOL,
. We require that this be equal to a given tolerance TOL,
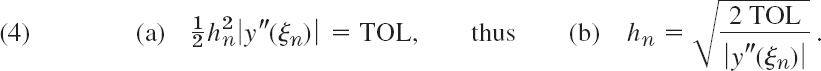
y″(x) must not be zero on the interval J: x0 ![]() x = xN on which the solution is wanted. Let K be the minimum of |y″(x)| on J and assume that K > 0. Minimum |y″(x)| corresponds to maximum
x = xN on which the solution is wanted. Let K be the minimum of |y″(x)| on J and assume that K > 0. Minimum |y″(x)| corresponds to maximum ![]() by (4). Thus,
by (4). Thus, ![]() . We can insert this into (4b), obtaining by straightforward algebra
. We can insert this into (4b), obtaining by straightforward algebra

For other methods, automatic step size selection is based on the same principle.
Improved Euler Method. Predictor, Corrector. Euler's method is generally much too inaccurate. For a large h (0.2) this is illustrated in Sec. 1.2 by the computation for
![]()
And for small h the computation becomes prohibitive; also, roundoff in so many steps may result in meaningless results. Clearly, methods of higher order and precision are obtained by taking more terms in (2) into account. But this involves an important practical problem. Namely, if we substitute y′ = f(x, y(x)) into (2), we have
![]()
Now y in f depends on x, so that we have f′ as shown in (4*) and f″, f″′ even much more cumbersome. The general strategy now is to avoid the computation of these derivatives and to replace it by computing f for one or several suitably chosen auxiliary values of (x, y). “Suitably” means that these values are chosen to make the order of the method as high as possible (to have high accuracy). Let us discuss two such methods that are of practical importance, namely, the improved Euler method and the (classical) Runge–Kutta method.
In each step of the improved Euler method we compute two values, first the predictor

which is an auxiliary value, and then the new y-value, the corrector

Hence the improved Euler method is a predictor–corrector method: In each step we predict a value (7a) and then we correct it by (7b).
In algorithmic form, using the notations k1 = hf(xn, yn) in (7a) and ![]() in (7b), we can write this method as shown in Table 21.1.
in (7b), we can write this method as shown in Table 21.1.
Table 21.1 Improved Euler Method (Heun's Method)

EXAMPLE 1 Improved Euler Method. Comparison with Euler Method.
Apply the improved Euler method to the initial value problem (6), choosing h = 0.2 as in Sec. 1.2.
Solution. For the present problem we have in Table 21.1
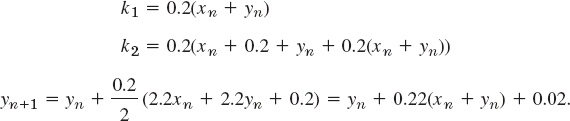
Table 21.2 shows that our present results are much more accurate than those for Euler's method in Table 21.1 but at the cost of more computations.
Table 21.2 Improved Euler Method for (6). Errors

Error of the Improved Euler Method. The local error is of order h3 and the global error of order h2, so that the method is a second-order method.
PROOF
Setting ![]() and using (2*) (after (6)), we have
and using (2*) (after (6)), we have
![]()
Approximating the expression in the brackets in (7b) by ![]() and again using the Taylor expansion, we obtain from (7b)
and again using the Taylor expansion, we obtain from (7b)

(where ′ = d/dxn, etc.). Subtraction of (8b) from (8a) gives the local error

Since the number of steps over a fixed x-interval is proportional to 1/h, the global error is of order h3/h = h2, so that the method is of second order.
Since the Euler method was an attractive pedagogical tool to teach the beginning of solving first-order ODEs numerically but had its drawbacks in terms of accuracy and could even produce wrong answers, we studied the improved Euler method and thereby introduced the idea of a predictor–corrector method. Although improved Euler is better than Euler, there are better methods that are used in industrial settings. Thus the practicing engineer has to know about the Runga–Kutta methods and its variants.
Runge–Kutta Methods (RK Methods)
A method of great practical importance and much greater accuracy than that of the improved Euler method is the classical Runge–Kutta method of fourth order, which we call briefly the Runge–Kutta method.1 It is shown in Table 21.3. We see that in each step we first compute four auxiliary quantities k1, k2, k3, k4 and then the new value yn+1. The method is well suited to the computer because it needs no special starting procedure, makes light demand on storage, and repeatedly uses the same straightforward computational procedure. It is numerically stable.
Note that, if f depends only on x, this method reduces to Simpson's rule of integration (Sec. 19.5). Note further that k1, …, k4 depend on n and generally change from step to step.
Table 21.3 Classical Runge–Kutta Method of Fourth Order

EXAMPLE 2 Classical Runge–Kutta Method
Apply the Runge–Kutta method to the initial value problem in Example 1, choosing h = 0.2, as before, and computing five steps.
Solution. For the present problem we have f(x, y) = x + y. Hence

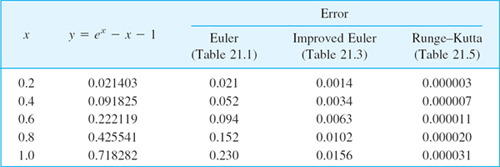
Table 21.4 shows the results and their errors, which are smaller by factors 103 and 104 than those for the two Euler methods. See also Table 21.5. We mention in passing that since the present k1, … k4 are simple, operations were saved by substituting k1 into k2, then k2 into k3, etc.; the resulting formula is shown in Column 4 of Table 21.4. Keep in mind that we have four function evaluations at each step.
Table 21.4 Runge–Kutta Method Applied to (4)

Table 21.5 Comparison of the Accuracy of the Three Methods under Consideration in the Case of the Initial Value Problem (4), with h = 0.2
Error and Step Size Control.
RKF (Runge–Kutta–Fehlberg)
The idea of adaptive integration (Sec. 19.5) has analogs for Runge–Kutta (and other) methods. In Table 21.3 for RK (Runge–Kutta), if we compute in each step approximations ![]() and
and ![]() with step sizes h and 2h, respectively, the latter has error per step equal to 25 = 32 times that of the former; however, since we have only half as many steps for 2h, the actual factor is 25/2 = 16, so that, say,
with step sizes h and 2h, respectively, the latter has error per step equal to 25 = 32 times that of the former; however, since we have only half as many steps for 2h, the actual factor is 25/2 = 16, so that, say,
![]()
Hence the error ![]() =
= ![]() (h) for step size h is about
(h) for step size h is about

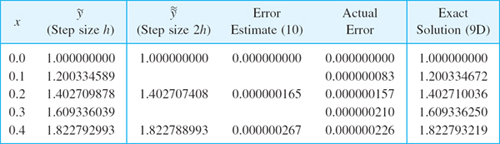
where ![]() , as said before. Table 21.6 illustrates (10) for the initial value problem
, as said before. Table 21.6 illustrates (10) for the initial value problem
![]()
the step size h = 0.1 and 0 ![]() x
x ![]() 0.4. We see that the estimate is close to the actual error. This method of error estimation is simple but may be unstable.
0.4. We see that the estimate is close to the actual error. This method of error estimation is simple but may be unstable.
Table 21.6 Runge–Kutta Method Applied to the Initial Value Problem (11) and Error Estimate (10). Exact Solution y = tan x + x + 1
RKF. E. Fehlberg [Computing 6 (1970), 61–71] proposed and developed error control by using two RK methods of different orders to go from (xn, yn) to (xn+1, yn+1). The difference of the computed y-values at xn+1 gives an error estimate to be used for step size control. Fehlberg discovered two RK formulas that together need only six function evaluations per step. We present these formulas here because RKF has become quite popular. For instance, Maple uses it (also for systems of ODEs).
Fehlberg's fifth-order RK method is
![]()
with coefficient vector γ = [γ1 … γ6],
![]()
His fourth-order RK method is
![]()
with coefficient vector
![]()
In both formulas we use only six different function evaluations altogether, namely,

The difference of (12) and (13) gives the error estimate
![]()
EXAMPLE 3 Runge–Kutta–Fehlberg
For the initial value problem (11) we obtain from (12)–(14) with h = 0.1 in the first step the 12S-values

and the error estimate
![]()
The exact 12S-value is y(0.1) = 1.20033467209. Hence the actual error of y1 is −4.4 · 10−10, smaller than that in Table 21.6 by a factor of 200.
Table 21.7 summarizes essential features of the methods in this section. It can be shown that these methods are numerically stable (definition in Sec. 19.1). They are one-step methods because in each step we use the data of just one preceding step, in contrast to multistep methods where in each step we use data from several preceding steps, as we shall see in the next section.
Table 21.7 Methods Considered and Their Order (= Their Global Error)

Backward Euler Method. Stiff ODEs
The backward Euler formula for numerically solving (1) is

This formula is obtained by evaluating the right side at the new location (xn+1, yn+1); this is called the backward Euler scheme. For known yn it gives yn+1 implicitly, so it defines an implicit method, in contrast to the Euler method (3), which gives yn+1 explicitly. Hence (16) must be solved for yn+1. How difficult this is depends on f in (1). For a linear ODE this provides no problem, as Example 4 (below) illustrates. The method is particularly useful for “stiff” ODEs, as they occur quite frequently in the study of vibrations, electric circuits, chemical reactions, etc. The situation of stiffness is roughly as follows; for details, see, for example, [E5], [E25], [E26] in App. 1.
Error terms of the methods considered so far involve a higher derivative. And we ask what happens if we let h increase. Now if the error (the derivative) grows fast but the desired solution also grows fast, nothing will happen. However, if that solution does not grow fast, then with growing h the error term can take over to an extent that the numeric result becomes completely nonsensical, as in Fig. 451. Such an ODE for which h must thus be restricted to small values, and the physical system the ODE models, are called stiff. This term is suggested by a mass–spring system with a stiff spring (spring with a large k; see Sec. 2.4). Example 4 illustrates that implicit methods remove the difficulty of increasing h in the case of stiffness: It can be shown that in the application of an implicit method the solution remains stable under any increase of h, although the accuracy decreases with increasing h.
EXAMPLE 4 Backward Euler Method. Stiff ODE
The initial value problem
![]()
has the solution (verify!)
![]()
The backward Euler formula (16) is
![]()
Noting that xn+1 = xn + h, taking the term −20yn+1 to the left, and dividing, we obtain

The numeric results in Table 21.8 show the following.
Stability of the backward Euler method for h = 0.05 and also for h = 0.2 with an error increase by about a factor 4 for h = 0.2,
Stability of the Euler method for h = 0.05 but instability for h = 0.1 (Fig. 451),
Stability of RK for h = 0.1 but instability for h = 0.2.
This illustrates that the ODE is stiff. Note that even in the case of stability the approximation of the solution near x = 0 is poor.
Stiffness will be considered further in Sec. 21.3 in connection with systems of ODEs.

Fig. 451. Euler method with h = 0.1 for the stiff ODE in Example 4 and exact solution
Table 21.8 Backward Euler Method (BEM) for Example 6. Comparison with Euler and RK

1–4 EULER METHOD
Do 10 steps. Solve exactly. Compute the error. Show details.
- y′ + 0.2y = 0, y(0) = 5, h = 0.2
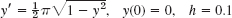
- y′ = (y − x)2, y(0) = 0, h = 0.1
- y′ = (y + x)2, y(0) = 0, h = 0.1
5–10 IMPROVED EULER METHOD
Do 10 steps. Solve exactly. Compute the error. Show details.
- 5. y′ = y, y(0) = 1, h = 0.1
- 6. y′ = 2(1 + y2), y(0) = 0, h = 0.05
- 7. y′ − xy2 = 0, y(0) = 1, h = 0.1
- 8. Logistic population model. y′ = y − y2, y(0) = 0.2, h = 0.1
- 9. Do Prob. 7 using Euler's method with h = 0.1 and compare the accuracy.
- 10. Do Prob. 7 using the improved Euler method, 20 steps with h = 0.02. Compare.
11–17 CLASSICAL RUNGE–KUTTA METHOD OF FOURTH ORDER
Do 10 steps. Compare as indicated. Show details.
- 11. y′ − xy2 = 0, y(0) = 1, h = 0.1. Compare with Prob. 7. Apply the error estimate (10) to y10.
- 12. y′ = y − y2, y(0) = 0.2, h = 0.1. Compare with Prob. 8.
- 13. y′ = 1 + y2, y(0) = 0, h = 0.1
- 14. y′ = (1 − x−1)y, y(1) = 1, h = 0.1
- 15. y′ + y tan x = sin 2x, y(0) = 1, h = 0.1
- 16. Do Prob. 15 with h = 0.2, 5 steps, and compare the errors with those in Prob. 15.
- 17. y′ = 4x3y2, y(0) = 0.5. h = 0.1
- 18. Kutta's third-order method is defined by
 with k1 and k2 as in RK (Table 21.3) and
with k1 and k2 as in RK (Table 21.3) and  Apply this method to (4) in (6). Choose h = 0.2 and do 5 steps. Compare with Table 21.5.
Apply this method to (4) in (6). Choose h = 0.2 and do 5 steps. Compare with Table 21.5. - 19. CAS EXPERIMENT. Euler–Cauchy vs. RK. Consider the initial value problem
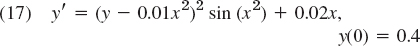
(solution: y = 1/[2.5 − S(x)] + 0.01x2 where S(x) is the Fresnel integral (38) in App. 3.1).
- Solve (17) by Euler, improved Euler, and RK methods for 0
 x 5 with step h = 0.2. Compare the errors for x = 1, 3, 5 and comment.
x 5 with step h = 0.2. Compare the errors for x = 1, 3, 5 and comment. - Graph solution curves of the ODE in (17) for various positive and negative initial values.
- Do a similar experiment as in (a) for an initial value problem that has a monotone increasing or monotone decreasing solution. Compare the behavior of the error with that in (a). Comment.
- Solve (17) by Euler, improved Euler, and RK methods for 0
- 20. CAS EXPERIMENT. RKF. (a) Write a program for RKF that gives xn, yn, the estimate (10), and, if the solution is known, the actual error
 n.
n.
(b) Apply the program to Example 3 in the text (10 steps, h = 0.1).
(c)
n in (b) gives a relatively good idea of the size of the actual error. Is this typical or accidental? Find out, by experimentation with other problems, on what properties of the ODE or solution this might depend.
21.2 Multistep Methods
In a one-step method we compute yn+1 using only a single step, namely, the previous value yn. One-step methods are “self-starting,” they need no help to get going because they obtain from the initial value etc. All methods in Sec. 21.1 are one-step.
In contrast, a multistep method uses, in each step, values from two or more previous steps. These methods are motivated by the expectation that the additional information will increase accuracy and stability. But to get started, one needs values, say, y0, y1, y2, y3 in a 4-step method, obtained by Runge–Kutta or another accurate method. Thus, multistep methods are not self-starting. Such methods are obtained as follows.
Adams–Bashforth Methods
We consider an initial value problem
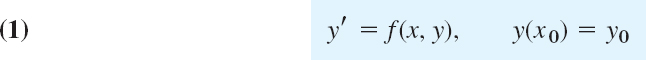
as before, with f such that the problem has a unique solution on some open interval containing x0. We integrate y′ = f(x, y) from xn to xn+1 = xn + h. This gives

Now comes the main idea. We replace f(x, y(x)) by an interpolation polynomial p(x) (see Sec. 19.3), so that we can later integrate. This gives approximations yn+1 of y(xn+1)and yn of y(xn),

Different choices of p(x) will now produce different methods. We explain the principle by taking a cubic polynomial, namely, the polynomial p3(x) that at (equidistant)
![]()
has the respective values

This will lead to a practically useful formula. We can obtain p3(x) from Newton's backward difference formula (18), Sec. 19.3:
![]()
where

We integrate p3(x) over x from xn to xn+1 = xn + h, thus over r from 0 to 1. Since
![]()
The integral of ![]() is
is ![]() and that of
and that of ![]() is
is ![]() . We thus obtain
. We thus obtain
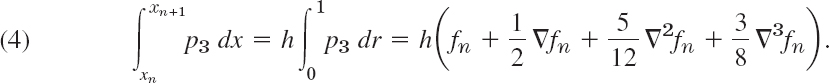
It is practical to replace these differences by their expressions in terms of f:

We substitute this into (4) and collect terms. This gives the multistep formula of the Adams–Bashforth method2of fourth order
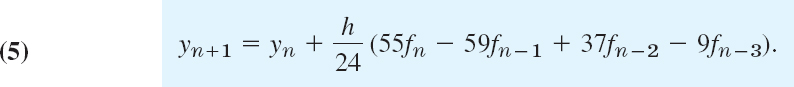
It expresses the new value yn+1 [approximation of the solution y of (1) at xn+1] in terms of 4 values of f computed from the y-values obtained in the preceding 4 steps. The local truncation error is of order h5, as can be shown, so that the global error is of order h4; hence (5) does define a fourth-order method.
Adams–Moulton Methods
Adams–Moulton methods are obtained if for p(x) in (2) we choose a polynomial that interpolates f(x, y(x)) at xn+1,xn, xn−1, … (as opposed to xn, xn−1, … used before; this is the main point). We explain the principle for the cubic polynomial ![]() that interpolates at xn+1, xn, xn−1, xn−2. (Before we had xn, xn−1, xn−2, xn−3.) Again using (18) in Sec. 19.3 but now setting r = (x − xn+1)/h, we have
that interpolates at xn+1, xn, xn−1, xn−2. (Before we had xn, xn−1, xn−2, xn−3.) Again using (18) in Sec. 19.3 but now setting r = (x − xn+1)/h, we have
![]()
We now integrate over x from xn to xn+1 as before. This corresponds to integrating over r from −1 to 0. We obtain

Replacing the differences as before gives
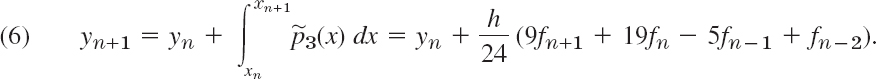
This is usually called an Adams–Moulton formula.3 It is an implicit formula because fn+1 = f(xn+1, yn+1) appears on the right, so that it defines yn+1 only implicitly, in contrast to (5), which is an explicit formula, not involving yn+1 on the right. To use (6) we must predict a value ![]() , for instance, by using (5), that is,
, for instance, by using (5), that is,

The corrected new value yn+1 is then obtained from (6) with fn+1 replaced by ![]() and the other f’s as in (6); thus,
and the other f’s as in (6); thus,

This predictor–corrector method (7a), (7b) is usually called the Adams–Moulton method of fourth order. It has the advantage over RK that (7) gives the error estimate
![]()
as can be shown. This is the analog of (10) in Sec. 21.1.
Sometimes the name Adams–Moulton method is reserved for the method with several corrections per step by (7b) until a specific accuracy is reached. Popular codes exist for both versions of the method.
Getting Started. In (5) we need f0,f1,f2,f3. Hence from (3) we see that we must first compute y1, y2, y3 by some other method of comparable accuracy, for instance, by RK or by RKF. For other choices see Ref. [E26] listed in App. 1.
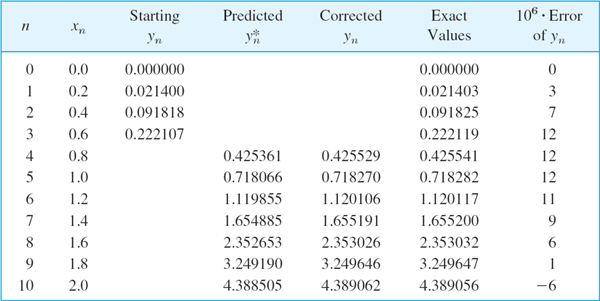
EXAMPLE 1 Adams–Bashforth Prediction (7a), Adams–Moulton Correction (7b)
Solve the initial value problem
![]()
by (7a), (7b) on the interval 0 ![]() x
x ![]() 2, choosing h = 0.2.
2, choosing h = 0.2.
Solution. The problem is the same as in Examples 1 and 2, Sec. 21.1, so that we can compare the results. We compute starting values y1, y2, y3 by the classical Runge–Kutta method. Then in each step we predict by (7a) and make one correction by (7b) before we execute the next step. The results are shown and compared with the exact values in Table 21.9. We see that the corrections improve the accuracy considerably. This is typical.
Table 21.9 Adams–Moulton Method Applied to the Initial Value Problem (8); Predicted Values Computed by (7a) and Corrected Values by (7b)
Comments on Comparison of Methods. An Adams–Moulton formula is generally much more accurate than an Adams–Bashforth formula of the same order. This justifies the greater complication and expense in using the former. The method (7a), (7b) is numerically stable, whereas the exclusive use of (7a) might cause instability. Step size control is relatively simple. If |Corrector − Predictor| > TOL, use interpolation to generate “old” results at half the current step size and then try h/2 as the new step.
Whereas the Adams–Moulton formula (7a), (7b) needs only 2 evaluations per step, Runge–Kutta needs 4; however, with Runge–Kutta one may be able to take a step size more than twice as large, so that a comparison of this kind (widespread in the literature) is meaningless.
For more details, see Refs. [E25], [E26] listed in App. 1.
1–10 ADAMS–MOULTON METHOD
Solve the initial value problem by Adams–Moulton (7a), (7b), 10 steps with 1 correction per step. Solve exactly and compute the error. Use RK where no starting values are given.
- y′ = y, y(0) = 1, h = 0.1, (1.105171, 1.221406, 1.349858)
- y′ = 2xy, y(0) = 1, h = 0.1
- y′ = 1 + y2, y(0) = 0, h = 0.1, (0.100335, 0.202710, 0.309336)
- Do Prob. 2 by RK, 5 steps, h = 0.2. Compare the errors.
- Do Prob. 3 by RK, 5 steps, h = 0.2. Compare the errors.
- y′ = (y − x − 1)2 + 2, y(0) = 1, h = 0.1, 10 steps
- y′ = 3y − 12y2, y(0) = 0.2, h = 0.1
- y′ = 1 − 4y2, y(0) = 0, h = 0.1
- y′ = 3x2(1 + y), y(0) = 0, h = 0.05
- y′ = x/y, y(1) = 3, h = 0.2
- Do and show the calculations leading to (4)–(7) in the text.
- Quadratic polynomial. Apply the method in the text to a polynomial of second degree. Show that this leads to the predictor and corrector formulas
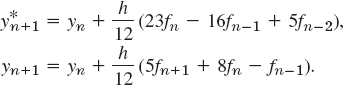
- Using Prob. 12, solve y′ = 2xy, y(0) = 1 (10 steps, h = 0.1, RK starting values). Compare with the exact solution and comment.
- How much can you reduce the error in Prob. 13 by halfing h (20 steps, h = 0.05)? First guess, then compute.
- CAS PROJECT. Adams–Moulton. (a) Accurate starting is important in (7a), (7b). Illustrate this in Example 1 of the text by using starting values from the improved Euler–Cauchy method and compare the results with those in Table 21.8.
(b) How much does the error in Prob. 11 decrease if you use exact starting values (instead of RK values)?
(c) Experiment to find out for what ODEs poor starting is very damaging and for what ODEs it is not.
(d) The classical RK method often gives the same accuracy with step 2h as Adams–Moulton with step h, so that the total number of function evaluations is the same in both cases. Illustrate this with Prob. 8. (Hence corresponding comparisons in the literature in favor of Adams–Moulton are not valid. See also Probs. 6 and 7.)
21.3 Methods for Systems
and Higher Order ODEs
Initial value problems for first-order systems of ODEs are of the form
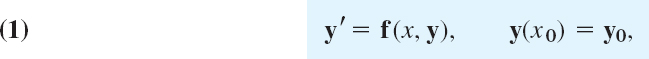
in components

Here, f is assumed to be such that the problem has a unique solution y(x) on some open x-interval containing x0. Our discussion will be independent of Chap. 4 on systems.
Before explaining solution methods it is important to note that (1) includes initial value problems for single m th-order ODEs,

and initial conditions y(x0) = k1, y′ (x0) = k2, …, y(m−1)(x0) = Km as special cases.
Indeed, the connection is achieved by setting
![]()
Then we obtain the system

and the initial conditions y1(x0) = K1, y2(x0) = K2, …, ym(x0) = Km.
Euler Method for Systems
Methods for single first-order ODEs can be extended to systems (1) simply by writing vector functions y and f instead of scalar functions y and f, whereas x remains a scalar variable.
We begin with the Euler method. Just as for a single ODE, this method will not be accurate enough for practical purposes, but it nicely illustrates the extension principle.
EXAMPLE 1 Euler Method for a Second-Order ODE. Mass–Spring System
Solve the initial value problem for a damped mass–spring system
![]()
by the Euler method for systems with step h = 0.2 for x from 0 to 1 (where x is time).
Solution. The Euler method (3), Sec. 21.1, generalizes to systems in the form

in components

and similarly for systems of more than two equations. By (4) the given ODE converts to the system

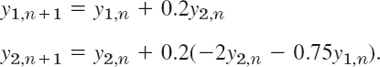
The initial conditions are y(0) = y1 (0) = 3, y′(0) = y2(0) = −2.5. The calculations are shown in Table 21.10. As for single ODEs, the results would not be accurate enough for practical purposes. The example merely serves to illustrate the method because the problem can be readily solved exactly,
![]()
Table 21.10 Euler Method for Systems in Example 1 (Mass–Spring System)
Runge–Kutta Methods for Systems
As for Euler methods, we obtain RK methods for an initial value problem (1) simply by writing vector formulas for vectors with m components, which, for m = 1, reduce to the previous scalar formulas.
Thus, for the classical RK method of fourth order in Table 21.3, we obtain

and for each step n = 0, 1, …, N − 1 we obtain the 4 auxiliary quantities

and the new value [approximation of the solution y(x) at xn+1 = x 0 + (n + 1)h]

EXAMPLE 2 RK Method for Systems. Airy's Equation. Airy Function Ai(x)
Solve the initial value problem
![]()
by the Runge–Kutta method for systems with h = 0.2; do 5 steps. This is Airy's equation,4 which arose in optics (see Ref. [A13], p. 188, listed in App. 1). is the gamma function (see App. A3.1). The initial conditions are such that we obtain a standard solution, the Airy function Ai(x), a special function that has been thoroughly investigated; for numeric values, see Ref. [GenRef1], pp. 446, 475.
Solution. For y″ = xy, setting y1 = y, y2 = ′1 = y′ setting we obtain the system (4)
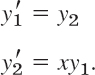
Hence f = [f1 f2]T in (1) has the components f1 (x, y) = y2, f2(x, y) = xy1. We now write (6) in components. The initial conditions (6a) are y1,0 = 0.35502805, y2,0 = −0.25881940. In (6b) we have fewer subscripts by simply writing k1 = a, k2 = k3 = c, k4 = d, so that a = [a1 a2]T, etc. Then (6b) takes the form
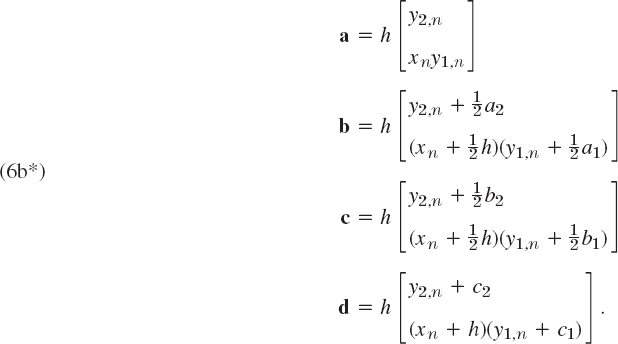
For example, the second component of b is obtained as follows. f(x, y) has the second component f2(x, y) = xy1. Now in b (= k2) the first argument is
![]()
The second argument in b is
![]()
and the first component of this is
![]()
Together,
![]()
Similarly for the other components in (6b*). Finally,
![]()
Table 21.11 shows the values y(x) = y1(x) of the Airy function Ai(x) and of its derivative y′(x) = y2(x) as well as of the (rather small!) error of y(x).
Table 21.11 RK Method for Systems: Values y1,n (xn) of the Airy Function Ai(x) in Example 2

Runge–Kutta–Nyström Methods (RKN Methods)
RKN methods are direct extensions of RK methods (Runge–Kutta methods) to second-order ODEs y″ = f(x, y, y′), as given by the Finnish mathematician E. J. Nyström [Acta Soc. Sci. fenn., 1925, L, No. 13]. The best known of these uses the following formulas, where n = 0, 1, …, N − 1 (N the number of steps):

From this we compute the approximation yn+1 of y(xn+1) at xn+1 = x0 + (n + 1)h,
![]()
and the approximation ![]() of the derivative y′(xn +1) needed in the next step,
of the derivative y′(xn +1) needed in the next step,
![]()
RKN for ODEs y″ = f(x, y) Not Containing y′. Then k2 = k3 in (7), which makes the method particularly advantageous and reduces (7a)–(7c) to
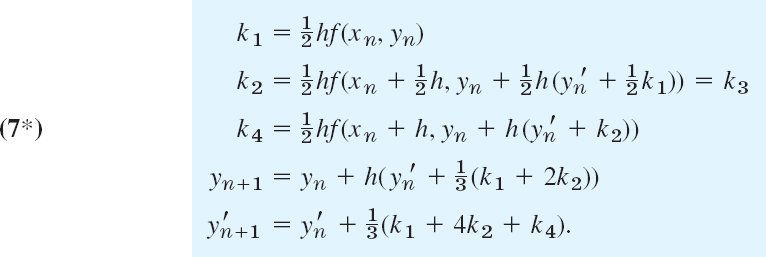
EXAMPLE 3 RKN Method. Airy's Equation. Airy Function Ai(x)
For the problem in Example 2 and h = 0.2 as before we obtain from (7*) simply k1 = 0.1xnyn and
![]()
Table 21.12 shows the results. The accuracy is the same as in Example 2, but the work was much less.
Table 21.12 Runge–Kutta–Nyström Method Applied to Airy's Equation, Computation of the Airy Function y = Ai(x)
Our work in Examples 2 and 3 also illustrates that usefulness of methods for ODEs in the computation of values of “higher transcendental functions.”
Backward Euler Method for Systems. Stiff Systems
The backward Euler formula (16) in Sec. 21.1 generalizes to systems in the form
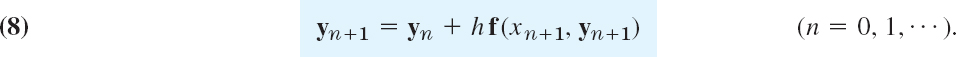
This is again an implicit method, giving yn+1 implicitly for given yn. Hence (8) must be solved for yn+1. For a linear system this is shown in the next example. This example also illustrates that, similar to the case of a single ODE in Sec. 21.1, the method is very useful for stiff systems. These are systems of ODEs whose matrix has eigenvalues of very different magnitudes, having the effect that, just as in Sec. 21.1, the step in direct methods, RK for example, cannot be increased beyond a certain threshold without losing stability. (λ = −1 and − 10 in Example 4, but larger differences do occur in applications.)
EXAMPLE 4 Backward Euler Method for Systems of ODEs. Stiff Systems
Compare the backward Euler method (8) with the Euler and the RK methods for numerically solving the initial value problem
![]()
converted to a system of first-order ODEs.
Solution. The given problem can easily be solved, obtaining
![]()
so that we can compute errors. Conversion to a system by setting y = y1, y′ = y2 [see (4)] gives

The coefficient matrix

whose value is λ2 11λ + 10 = (λ + 1)(λ + 1)(λ + 10). Hence the eigenvalues are −1 and −10 as claimed above. The backward Euler formula is

Reordering terms gives the linear system in the unknowns y1,n+1 and y2,n+1

The coefficient determinant is D = 1 + 11h + 10h2, and Cramer's rule (in Sec. 7.6) gives the solution
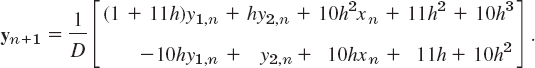
Table 21.13 Backward Euler Method (BEM) for Example 4. Comparison with Euler and RK
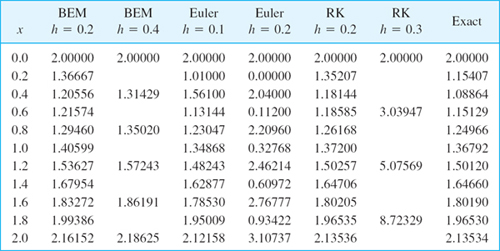
Table 21.13 shows the following.
Stability of the backward Euler method for h = 0.2 and 0.4 (and in fact for any h; try h = 5.0) with decreasing accuracy for increasing h
Stability of the Euler method for h = 0.1 but instability for h = 0.2
Stability of RK for h = but instability for h = 0.3
Figure 452 shows the Euler method for h = 0.18, an interesting case with initial jumping (for about x > 3) but later monotone following the solution curve of y = y1. See also CAS Experiment 15.
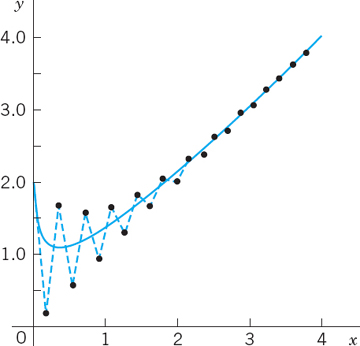
Fig. 452. Euler method with h = 0.18 in Example 4
1–6 EULER FOR SYSTEMS AND SECOND-ORDER ODEs
Solve by the Euler's method. Graph the solution in the y1y2-plane. Calculate the errors.
- y′ = 2y1 − 4y2, y′2 = y1 − 3y2, y1(0) = 3, y2(0), h = 0.1, 10 steps
- Spiral. y′1 = −y1 + y2, y′2 = y1 − 3y2, y1(0) = 3, y2(0) = 0, h = 0.1, 10 steps
 , 5 steps
, 5 steps- y′1 = −3y1 + y2, y′2 = y1 − 3y2, y1(0) = 2, y2(0) = 0, h = 0.1, 5 steps
- y″ − y = x, y(0) = 1, y′(0) = −2, h = 0.1, 5 steps
- y′1 = y1, y′1 = −y2, y1(0) = 2, y2(0) = 2, h = 0.1, 10 steps
7–10 RK FOR SYSTEMS
Solve by the classical RK.
- 7. The ODE in Prob. 5. By what factor did the error decrease?
- 8. The system in Prob. 2
- 9. The system in Prob. 1
- 10. The system in Prob. 4
- 11. Pendulum equation y″ + sin y = 0, y(π) = 1, as a system, h = 0.2, 20 steps. How does your result fit into Fig. 93 in Sec. 4.5?
- 12. Bessel Function J0. xy″ + y′ + xy = 0, y(1) = 0.765198, y′(1) = −0.440051, h = 0.5, 5 steps. (This gives the standard solution J0 (x) in Fig. 110 in Sec. 5.4.)
- 13. Verify the formulas and calculations for the Airy equation in Example 2 of the text.
- 14. RKN. The classical RK for a first-order ODE extends to second-order ODEs (E. J. Nyström, Acta fenn. No 13, 1925). If the ODE is y″ = f(x, y), not containing y′, then

Apply this RKN (Runge–Kutta–Nyström) method to the Airy ODE in Example 2 with h = 0.2 as before, to obtain approximate values of Ai(x).
- 15. CAS EXPERIMENT. Backward Euler and Stiffness. Extend Example 3 as follows.
- Verify the values in Table 21.13 and show them graphically as in Fig. 452.
- Compute and graph Euler values for h near the “critical” h = 0.18 to determine more exactly when instability starts.
- Compute and graph RK values for values of h between 0.2 and 0.3 to find h for which the RK approximation begins to increase away from the exact solution.
- Compute and graph backward Euler values for large h; confirm stability and investigate the error increase for growing h.
21.4 Methods for Elliptic PDEs
We have arrived at the second half of this chapter, which is devoted to numerics for partial differential equations (PDEs). As we have seen in Chap. 12, there are many applications to PDEs, such as in dynamics, elasticity, heat transfer, electromagnetic theory, quantum mechanics, and others. Selected because of their importance in applications, the PDEs covered here include the Laplace equation, the Poisson equation, the heat equation, and the wave equation. By covering these equations based on their importance in applications we also selected equations that are important for theoretical considerations. Indeed, these equations serve as models for elliptic, parabolic, and hyperbolic PDEs. For example, the Laplace equation is a representative example of an elliptic type of PDE, and so forth.
Recall, from Sec. 12.4, that a PDE is called quasilinear if it is linear in the highest derivatives. Hence a second-order quasilinear PDE in two independent variables x, y is of the form
![]()
u is an unknown function of x and y (a solution sought). F is a given function of the indicated variables.
Depending on the discriminant ac − b2, the PDE (1) is said to be of
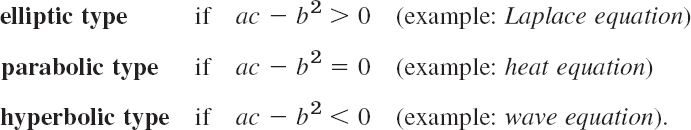
Here, in the heat and wave equations, y is time t. The coefficients a, b, c may be functions of x, y, so that the type of (1) may be different in different regions of the xy-plane. This classification is not merely a formal matter but is of great practical importance because the general behavior of solutions differs from type to type and so do the additional conditions (boundary and initial conditions) that must be taken into account.
Applications involving elliptic equations usually lead to boundary value problems in a region R, called a first boundary value problem or Dirichlet problem if u is prescribed on the boundary curve C of R, a second boundary value problem or Neumann problem if un = ∂u/∂n (normal derivative of u) is prescribed on C, and a third or mixed problem if u is prescribed on a part of C and un on the remaining part. C usually is a closed curve (or sometimes consists of two or more such curves).
Difference Equations
for the Laplace and Poisson Equations
In this section we develop numeric methods for the two most important elliptic PDEs that appear in applications. The two PDEs are the Laplace equation
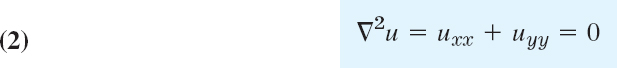
and the Poisson equation

The starting point for developing our numeric methods is the idea that we can replace the partial derivatives of these PDEs by corresponding difference quotients. Details are as follows:
To develop this idea, we start with the Taylor formula and obtain

We subtract (4b) from (4a), neglect terms in h3, h4, …, and solve for ux. Then
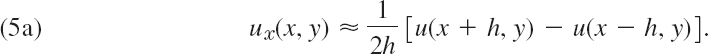
Similarly,
![]()
and
![]()
By subtracting, neglecting terms in k3, k4, …, and solving for uy we obtain
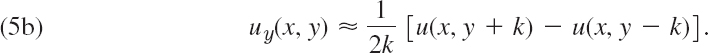
We now turn to second derivatives. Adding (4a) and (4b) and neglecting terms in h4, h5, …, we obtain u(x + h, y) + u(x − h, y) ≈ 2u(x, y) + h2uxx(x, y). Solving for uxx we have

Similarly,

We shall not need (see Prob. 1)
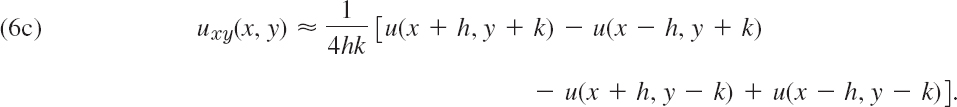
Figure 453a shows the points (x + h, y), (x − h, y), … in (5) and (6).
We now substitute (6a) and (6b) into the Poisson equation (3), choosing k = h to obtain a simple formula:
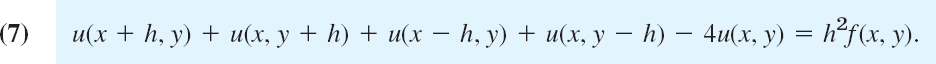
This is a difference equation corresponding to (3). Hence for the Laplace equation (2) the corresponding difference equation is

h is called the mesh size. Equation (8) relates u at (x, y) to u at the four neighboring points shown in Fig. 453b. It has a remarkable interpretation: u at (x, y) equals the mean of the values of u at the four neighboring points. This is an analog of the mean value property of harmonic functions (Sec. 18.6).
Those neighbors are often called E (East), N (North), W (West), S (South). Then Fig. 453b becomes Fig. 453c and (7) is


Fig. 453. Points and notation in (5)–(8) and (7*)
Our approximation of ![]() in (7) and (8) is a 5-point approximation with the coefficient scheme or stencil (also called pattern, molecule, or star)
in (7) and (8) is a 5-point approximation with the coefficient scheme or stencil (also called pattern, molecule, or star)

Dirichlet Problem
In numerics for the Dirichlet problem in a region R we choose an h and introduce a square grid of horizontal and vertical straight lines of distance h. Their intersections are called mesh points (or lattice points or nodes). See Fig. 454.
Then we approximate the given PDE by a difference equation [(8) for the Laplace equation], which relates the unknown values of u at the mesh points in R to each other and to the given boundary values (details in Example 1). This gives a linear system of algebraic equations. By solving it we get approximations of the unknown values of u at the mesh points in R.
We shall see that the number of equations equals the number of unknowns. Now comes an important point. If the number of internal mesh points, call it p, is small, say, p < 100, then a direct solution method may be applied to that linear system of p < 100 equations in p unknowns. However, if p is large, a storage problem will arise. Now since each unknown u is related to only 4 of its neighbors, the coefficient matrix of the system is a sparse matrix, that is, a matrix with relatively few nonzero entries (for instance, 500 of 10,000 when p = 100). Hence for large p we may avoid storage difficulties by using an iteration method, notably the Gauss–Seidel method (Sec. 20.3), which in PDEs is also called Liebmann's method (note the strict diagonal dominance). Remember that in this method we have the storage convenience that we can overwrite any solution component (value of u) as soon as a “new” value is available.
Both cases, large p and small p, are of interest to the engineer, large p if a fine grid is used to achieve high accuracy, and small p if the boundary values are known only rather inaccurately, so that a coarse grid will do it because in this case it would be meaningless to try for great accuracy in the interior of the region R.
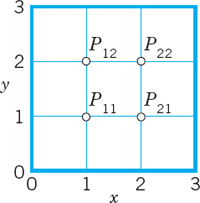
We illustrate this approach with an example, keeping the number of equations small, for simplicity. As convenient notations for mesh points and corresponding values of the solution (and of approximate solutions) we use (see also Fig. 454)
![]()

Fig. 454. Region in the xy-plane covered by a grid of mesh h, also showing mesh points p11 = (h, h), …, pij = (ih, jh), …
With this notation we can write (8) for any mesh point Pij in the form

Remark. Our current discussion and the example that follows illustrate what we may call the reuseability of mathematical ideas and methods. Recall that we applied the Gauss–Seidel method to a system of ODEs in Sec. 20.3 and that we can now apply it again to elliptic PDEs. This shows that engineering mathematics has a structure and important mathematical ideas and methods will appear again and again in different situations. The student should find this attractive in that previous knowledge can be reapplied.
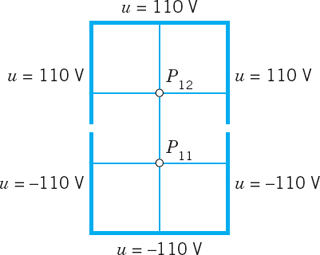
EXAMPLE 1 Laplace Equation. Liebmann's Method
The four sides of a square plate of side 12 cm, made of homogeneous material, are kept at constant temperature 0°C and 100°C as shown in Fig. 455a. Using a (very wide) grid of mesh 4 cm and applying Liebmann's method (that is, Gauss–Seidel iteration), find the (steady-state) temperature at the mesh points.
Solution. In the case of independence of time, the heat equation (see Sec. 10.8)
![]()
reduces to the Laplace equation. Hence our problem is a Dirichlet problem for the latter. We choose the grid shown in Fig. 455b and consider the mesh points in the order p11, p21, p12, p22. We use (11) and, in each equation, take to the right all the terms resulting from the given boundary values. Then we obtain the system

In practice, one would solve such a small system by the Gauss elimination, finding u11 = u21 = 87.5, u12 = u22 = 62.5.
More exact values (exact to 3S) of the solution of the actual problem [as opposed to its model (12)] are 88.1 and 61.9, respectively. (These were obtained by using Fourier series.) Hence the error is about which is surprisingly accurate for a grid of such a large mesh size h. If the system of equations were large, one would solve it by an indirect method, such as Liebmann's method. For (12) this is as follows. We write (12) in the form (divide by −4 and take terms to the right)
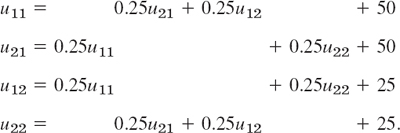
These equations are now used for the Gauss–Seidel iteration. They are identical with (2) in Sec. 20.3, where u11 = x1, u21 = x2, u12 = x3, u22 = x4, and the iteration is explained there, with 100, 100, 100, 100 chosen as starting values. Some work can be saved by better starting values, usually by taking the average of the boundary values that enter into the linear system. The exact solution of the system is u11 = u21 = 87.5, u12 = u22 = 62.5, as you may verify.
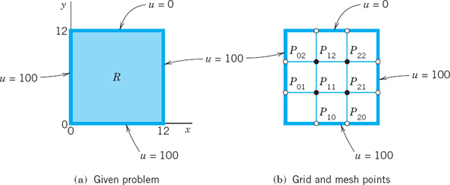
Fig. 455. Example 1
Remark. It is interesting to note that, if we choose mesh h = L/n (L = side of R) and consider the (n − 1)2 internal mesh points (i.e., mesh points not on the boundary) row by row in the order
![]()
then the system of equations has the (n − 1)2 × (n − 1)2 coefficient matrix

is an (n − 1) × (n − 1) matrix. (In (12) we have n = 3, (n − 1)2 = 4 internal mesh points, two submatrices B, and two submatrices I.) The matrix A is nonsingular. This follows by noting that the off-diagonal entries in each row of A have the sum 3 (or 2), whereas each diagonal entry of A equals −4, so that nonsingularity is implied by Gerschgorin's theorem in Sec. 20.7 because no Gerschgorin disk can include 0.
A matrix is called a band matrix if it has all its nonzero entries on the main diagonal and on sloping lines parallel to it (separated by sloping lines of zeros or not). For example, A in (13) is a band matrix. Although the Gauss elimination does not preserve zeros between bands, it does not introduce nonzero entries outside the limits defined by the original bands. Hence a band structure is advantageous. In (13) it has been achieved by carefully ordering the mesh points.
ADI Method
A matrix is called a tridiagonal matrix if it has all its nonzero entries on the main diagonal and on the two sloping parallels immediately above or below the diagonal. (See also Sec. 20.9.) In this case the Gauss elimination is particularly simple.
This raises the question of whether, in the solution of the Dirichlet problem for the Laplace or Poisson equations, one could obtain a system of equations whose coefficient matrix is tridiagonal. The answer is yes, and a popular method of that kind, called the ADI method (alternating direction implicit method) was developed by Peaceman and Rachford. The idea is as follows. The stencil in (9) shows that we could obtain a tridiagonal matrix if there were only the three points in a row (or only the three points in a column). This suggests that we write (11) in the form
![]()
so that the left side belongs to y-Row j only and the right side to x-Column i. Of course, we can also write (11) in the form
![]()
so that the left side belongs to Column i and the right side to Row j. In the ADI method we proceed by iteration. At every mesh point we choose an arbitrary starting value ![]() . In each step we compute new values at all mesh points. In one step we use an iteration formula resulting from (14a) and in the next step an iteration formula resulting from (14b), and so on in alternating order.
. In each step we compute new values at all mesh points. In one step we use an iteration formula resulting from (14a) and in the next step an iteration formula resulting from (14b), and so on in alternating order.
In detail: suppose approximations ![]() have been computed. Then, to obtain the next approximations
have been computed. Then, to obtain the next approximations ![]() , we substitute the
, we substitute the ![]() on the right side of (14a) and solve for the
on the right side of (14a) and solve for the ![]() on the left side; that is, we use
on the left side; that is, we use
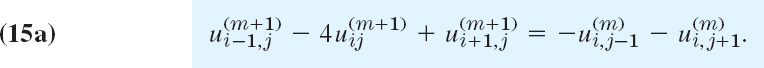
We use (15a) for a fixed j, that is, for a fixed rowj, and for all internal mesh points in this row. This gives a linear system of N algebraic equations (N = number of internal mesh points per row) in N unknowns, the new approximations of u at these mesh points. Note that (15a) involves not only approximations computed in the previous step but also given boundary values. We solve the system (15a) (j fixed!) by Gauss elimination. Then we go to the next row, obtain another system of N equations and solve it by Gauss, and so on, until all rows are done. In the next step we alternate direction, that is, we compute the next approximations ![]() column by column from the
column by column from the ![]() and the given boundary values, using a formula obtained from (14b) by substituting
and the given boundary values, using a formula obtained from (14b) by substituting ![]() the on the right:
the on the right:

For each fixed i, that is, for each column, this is a system of M equations (M = number of internal mesh points per column) in M unknowns, which we solve by Gauss elimination. Then we go to the next column, and so on, until all columns are done.
Let us consider an example that merely serves to explain the entire method.
EXAMPLE 2 Dirichlet Problem. ADI Method
Explain the procedure and formulas of the ADI method in terms of the problem in Example 1, using the same grid and starting values 100, 100, 100, 100.
Solution. While working, we keep an eye on Fig. 455b and the given boundary values. We obtain first approximations ![]() from (15a) with m = 0. We write boundary values contained in (15a) without an upper index, for better identification and to indicate that these given values remain the same during the iteration. From (15a) with m = 0 we have for j = 1 (first row) the system
from (15a) with m = 0. We write boundary values contained in (15a) without an upper index, for better identification and to indicate that these given values remain the same during the iteration. From (15a) with m = 0 we have for j = 1 (first row) the system

The solution is ![]() . For j = 2 (second row) we obtain from (15a) the system
. For j = 2 (second row) we obtain from (15a) the system

The solution is ![]() .
.
Second approximations ![]() are now obtained from (15b) with m = 1 by using the first approximations just computed and the boundary values. For i = 1 (first column) we obtain from (15b) the system
are now obtained from (15b) with m = 1 by using the first approximations just computed and the boundary values. For i = 1 (first column) we obtain from (15b) the system
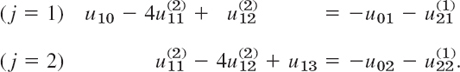
The solution is ![]() , For i = 2 (second column) we obtain from (15b) the system
, For i = 2 (second column) we obtain from (15b) the system

The solution is ![]() ,
, ![]() .
.
In this example, which merely serves to explain the practical procedure in the ADI method, the accuracy of the second approximations is about the same as that of two Gauss–Seidel steps in Sec. 20.3 (where u11 = x1, u21 = x2, u12 = x3, u22 = x4), as the following table shows.

Improving Convergence. Additional improvement of the convergence of the ADI method results from the following interesting idea. Introducing a parameter p, we can also write (11) in the form
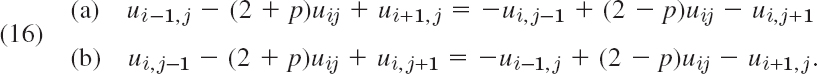
This gives the more general ADI iteration formulas

For p = 2, this is (15). The parameter p may be used for improving convergence. Indeed, one can show that the ADI method converges for positive p, and that the optimum value for maximum rate of convergence is
![]()
where K is the larger of M + 1 and N + 1 (see above). Even better results can be achieved by letting p vary from step to step. More details of the ADI method and variants are discussed in Ref. [E25] listed in App. 1.
- Derive (5b), (6b), and (6c).
- Verify the calculations in Example 1 of the text. Find out experimentally how many steps you need to obtain the solution of the linear system with an accuracy of 3S.
- Use of symmetry. Conclude from the boundary values in Example 1 that u21 = u11 and u22 = u12. Show that this leads to a system of two equations and solve it.
- Finer grid of 3 × 3 inner points. Solve Example 1, choosing
 (instead of
(instead of  ) and the same starting values.
) and the same starting values.
5–10 GAUSS ELIMINATION, GAUSS–SEIDEL ITERATION
For the grid in Fig. 456 compute the potential at the four internal points by Gauss and by 5 Gauss–Seidel steps with starting values 100, 100, 100, 100 (showing the details of your work) if the boundary values on the edges are:
- 5. u(1, 0) = 60, u(2, 0) = 300, u = 100 on the other three edges.
- 6. u = 0 on the left, x3 on the lower edge, 27 − 9y2 on the right, x3 − 27x on the upper edge.
- 7. U0 on the upper and lower edges, −U0 on the left and right. Sketch the equipotential lines.
- 8. u = 220 on the upper and lower edges, 110 on the left and right.
- 9.
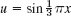 on the upper edge, 0 on the other edges, 10 steps.
on the upper edge, 0 on the other edges, 10 steps. - 10. u = x4 on the lower edge, 81 − 54y2 + y4 on the right, x4 − 54x2 + 81 on the upper edge, y4 on the left. Verify the exact solution x4 − 6x2y2 + y4 and determine the error.
- 11. Find the potential in Fig. 457 using (a) the coarse grid, (b) the fine grid 5 × 3, and Gauss elimination. Hint. In (b), use symmetry; take u = 0 as boundary value at the two points at which the potential has a jump.
- 12. Influence of starting values. Do Prob. 9 by Gauss–Seidel, starting from 0. Compare and comment.
- 13. For the square 0 x 4, 0 y 4 let the boundary temperatures be 0°C on the horizontal and 50°C on the vertical edges. Find the temperatures at the interior points of a square grid with h = 1.
- 14. Using the answer to Prob. 13, try to sketch some isotherms.
- 15. Find the isotherms for the square and grid in Prob. 13 if
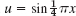 on the horizontal and
on the horizontal and  on the vertical edges. Try to sketch some isotherms.
on the vertical edges. Try to sketch some isotherms. - 16. ADI. Apply the ADI method to the Dirichlet problem in Prob. 9, using the grid in Fig. 456, as before and starting values zero.
- 17. What in (18) should we choose for Prob. 16? Apply the ADI formulas (17) with that value of to Prob. 16, performing 1 step. Illustrate the improved convergence by comparing with the corresponding values 0.077, 0.308 after the first step in Prob. 16. (Use the starting values zero.)
- 18. CAS PROJECT. Laplace Equation. (a) Write a program for Gauss–Seidel with 16 equations in 16 unknowns, composing the matrix (13) from the indicated 4 × 4 submatrices and including a transformation of the vector of the boundary values into the vector b of Ax = b.
(b) Apply the program to the square grid in 0
x 5, 0 y 5 with h = 1 and u = 220 on the upper and lower edges, u = 110 on the left edge and u = −10 on the right edge. Solve the linear system also by Gauss elimination. What accuracy is reached in the 20th Gauss–Seidel step?
21.5 Neumann and Mixed Problems.
Irregular Boundary
We continue our discussion of boundary value problems for elliptic PDEs in a region R in the xy-plane. The Dirichlet problem was studied in the last section. In solving Neumann and mixed problems (defined in the last section) we are confronted with a new situation, because there are boundary points at which the (outer) normal derivative un = ∂u/∂n of the solution is given, but u itself is unknown since it is not given. To handle such points we need a new idea. This idea is the same for Neumann and mixed problems. Hence we may explain it in connection with one of these two types of problems. We shall do so and consider a typical example as follows.
EXAMPLE 1 Mixed Boundary Value Problem for a Poisson Equation
Solve the mixed boundary value problem for the Poisson equation
![]()
shown in Fig. 458a.

Fig. 458. Mixed boundary value problem in Example 1
Solution. We use the grid shown in Fig. 458b, where h = 0.5. We recall that (7) in Sec. 21.4 has the right side h2f(x, y) = 0.52 · 12xy = 3xy. From the formulas u = 3y3 and un = 6x given on the boundary we compute the boundary data
![]()
p11 and p21 are internal mesh points and can be handled as in the last section. Indeed, from (7), Sec. 21.4, with h2 = 0.25 and h2f(x, y) = 3xy and from the given boundary values we obtain two equations corresponding to p11 and p21, as follows (with resulting from the left boundary).

The only difficulty with these equations seems to be that they involve the unknown values u12 and u12 of u at p12 and p22 on the boundary, where the normal derivative un = ∂u/∂n = ∂u/∂y is given, instead of u; but we shall overcome this difficulty as follows.
We consider p12 and p22. The idea that will help us here is this. We imagine the region R to be extended above to the first row of external mesh points (corresponding to y = 1.5), and we assume that the Poisson equation also holds in the extended region. Then we can write down two more equations as before (Fig. 458b)

On the right, 1.5 is 12xyh2 at and 3 is 12xyh2 at (1, 1) and 0 (at p02) and 3 (at p32) are given boundary values. We remember that we have not yet used the boundary condition on the upper part of the boundary of R, and we also notice that in (2b) we have introduced two more unknowns u13, u23. But we can now use that condition and get rid of u13, u23 by applying the central difference formula for du/dy. From (1) we then obtain (see Fig. 458b)

Substituting these results into (2b) and simplifying, we have
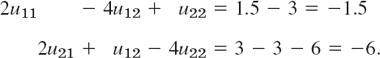
Together with (2a) this yields, written in matrix form,

(The entries 2 come from u13 and u23, and so do −3 and −6 on the right). The solution of (3) (obtained by Gauss elimination) is as follows; the exact values of the problem are given in parentheses.
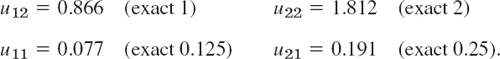
Irregular Boundary
We continue our discussion of boundary value problems for elliptic PDEs in a region R in the xy-plane. If R has a simple geometric shape, we can usually arrange for certain mesh points to lie on the boundary C of R, and then we can approximate partial derivatives as explained in the last section. However, if C intersects the grid at points that are not mesh points, then at points close to the boundary we must proceed differently, as follows.
The mesh point O in Fig. 459 is of that kind. For O and its neighbors A and P we obtain from Taylor's theorem
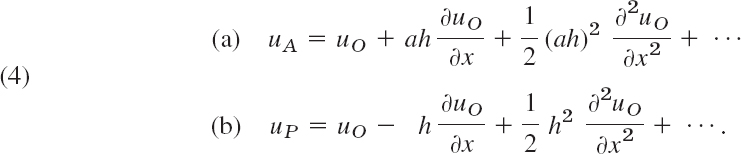
We disregard the terms marked by dots and eliminate ∂uO/∂x. Equation (4b) times a plus equation (4a) gives


Fig. 459. Curved boundary C of a region R, a mesh point O near C, and neighbors A, B, P, Q
We solve this last equation algebraically for the derivative, obtaining
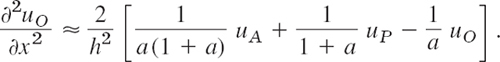
Similarly, by considering the points O, B, and Q,
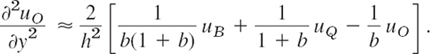
By addition,

For example, if ![]() , instead of the stencil (see Sec. 21.4)
, instead of the stencil (see Sec. 21.4)

because ![]() , etc. The sum of all five terms still being zero (which is useful for checking).
, etc. The sum of all five terms still being zero (which is useful for checking).
Using the same ideas, you may show that in the case of Fig. 460.

a formula that takes care of all conceivable cases.
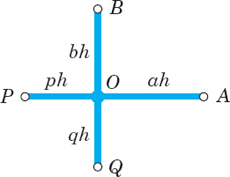
Fig. 460. Neighboring points A, B, P, Q of a mesh point O and notations in formula (6)
EXAMPLE 2 Dirichlet Problem for the Laplace Equation. Curved Boundary
Find the potential u in the region in Fig. 461 that has the boundary values given in that figure; here the curved portion of the boundary is an arc of the circle of radius 10 about (0,0). Use the grid in the figure.
Solution. u is a solution of the Laplace equation. From the given formulas for the boundary values u = x3, u = 512 − 24y2, … we compute the values at the points where we need them; the result is shown in the figure. For p11 and p12 we have the usual regular stencil, and for p21 and p22 we use (6), obtaining
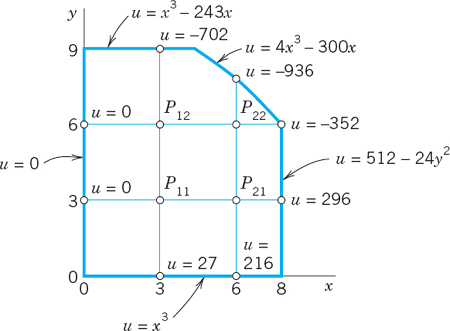
Fig. 461. Region, boundary values of the potential, and grid in Example 2
We use this and the boundary values and take the mesh points in the usual order p11, p21, p12, p22. Then we obtain the system

In matrix form,

Gauss elimination yields the (rounded) values
![]()
Clearly, from a grid with so few mesh points we cannot expect great accuracy. The exact solution of the PDE (not of the difference equation) having the given boundary values is u = x3 − 3xy2 and yields the values
![]()
In practice one would use a much finer grid and solve the resulting large system by an indirect method.
1–7 MIXED BOUNDARY VALUE PROBLEMS
- Check the values for the Poisson equation at the end of Example 1 by solving (3) by Gauss elimination.
- Solve the mixed boundary value problem for the Poisson equation ∇2u = 2(xu = 2(x2 + y2) in the region and for the boundary conditions shown in Fig. 462, using the indicated grid.

- CAS EXPERIMENT. Mixed Problem. Do Example 1 in the text with finer and finer grids of your choice and study the accuracy of the approximate values by comparing with the exact solution u = 2xy3. Verify the latter.
- Solve the mixed boundary value problem for the Laplace equation
 in the rectangle in Fig. 458a (using the grid in Fig. 458b) and the boundary conditions ux = 0 on the left edge, ux = 3 on the right edge, u = x2 on the lower edge, and u = x2 − 1 on the upper edge.
in the rectangle in Fig. 458a (using the grid in Fig. 458b) and the boundary conditions ux = 0 on the left edge, ux = 3 on the right edge, u = x2 on the lower edge, and u = x2 − 1 on the upper edge. - Do Example 1 in the text for the Laplace equation (instead of the Poisson equation) with grid and boundary data as before.
- Solve
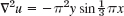 for the grid in Fig. 462 and
for the grid in Fig. 462 and  , u = 0 on the other three sides of the square.
, u = 0 on the other three sides of the square. - Solve Prob. 4 when un = 110 on the upper edge and u = 110 on the other edges.
8–16 IRREGULAR BOUNDARY
- 8. Verify the stencil shown after (5).
- 9. Derive (5) in the general case.
- 10. Derive the general formula (6) in detail.
- 11. Derive the linear system in Example 2 of the text.
- 12. Verify the solution in Example 2.
- 13. Solve the Laplace equation in the region and for the boundary values shown in Fig. 463, using the indicated grid. (The sloping portion of the boundary is y = 4.5 − x.)
- 14. If, in Prob. 13, the axes are grounded (u = 0), what constant potential must the other portion of the boundary have in order to produce 220 V at p11?
- 15. What potential do we have in Prob. 13 if u = 100 V on the axes and u = 0 on the other portion of the boundary?
- 16. Solve the Poisson equation
 in the region and for the boundary values shown in Fig. 464, using the grid also shown in the figure.
in the region and for the boundary values shown in Fig. 464, using the grid also shown in the figure.

21.6 Methods for Parabolic PDEs
The last two sections concerned elliptic PDEs, and we now turn to parabolic PDEs. Recall that the definitions of elliptic, parabolic, and hyperbolic PDEs were given in Sec. 21.4. There it was also mentioned that the general behavior of solutions differs from type to type, and so do the problems of practical interest. This reflects on numerics as follows.
For all three types, one replaces the PDE by a corresponding difference equation, but for parabolic and hyperbolic PDEs this does not automatically guarantee the convergence of the approximate solution to the exact solution as the mesh h → 0; in fact, it does not even guarantee convergence at all. For these two types of PDEs one needs additional conditions (inequalities) to assure convergence and stability, the latter meaning that small perturbations in the initial data (or small errors at any time) cause only small changes at later times.
In this section we explain the numeric solution of the prototype of parabolic PDEs, the one-dimensional heat equation
![]()
This PDE is usually considered for x in some fixed interval, say, 0 ![]() x
x ![]() L, and time t
L, and time t ![]() 0, and one prescribes the initial temperature u(x, 0) = f(x) (f given) and boundary conditions at x = 0 and x = L for all t
0, and one prescribes the initial temperature u(x, 0) = f(x) (f given) and boundary conditions at x = 0 and x = L for all t ![]() 0, for instance, u(0, t) = 0, u(L, t) = 0. We may assume c = 1 and L = 1; this can always be accomplished by a linear transformation of x and t (Prob. 1). Then the heat equation and those conditions are
0, for instance, u(0, t) = 0, u(L, t) = 0. We may assume c = 1 and L = 1; this can always be accomplished by a linear transformation of x and t (Prob. 1). Then the heat equation and those conditions are

A simple finite difference approximation of (1) is [see (6a) in Sec. 21.4; j is the number of the time step]
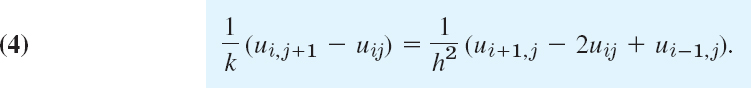
Figure 465 shows a corresponding grid and mesh points. The mesh size is h in the x-direction and k in the t-direction. Formula (4) involves the four points shown in Fig. 466. On the left in (4) we have used a forward difference quotient since we have no information for negative t at the start. From (4) we calculate ui,j+1, which corresponds to time row j + 1, in terms of the three other u that correspond to time row j. Solving (4) for ui,j+1, we have
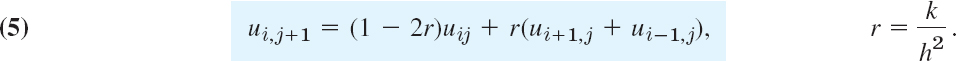
Computations by this explicit method based on (5) are simple. However, it can be shown that crucial to the convergence of this method is the condition


Fig. 465. Grid and mesh points corresponding to (4), (5)

Fig. 466. The four points in (4) and (5)
That is, uij should have a positive coefficient in (5) or (for r = ![]() ) be absent from (5). Intuitively, (6) means that we should not move too fast in the t-direction. An example is given below.
) be absent from (5). Intuitively, (6) means that we should not move too fast in the t-direction. An example is given below.
Crank–Nicolson Method
Condition (6) is a handicap in practice. Indeed, to attain sufficient accuracy, we have to choose h small, which makes k very small by (6). For example, if h = 0.1, then k ![]() 0.005. Accordingly, we should look for a more satisfactory discretization of the heat equation.
0.005. Accordingly, we should look for a more satisfactory discretization of the heat equation.
A method that imposes no restriction on r = k/h2 is the Crank–Nicolson (CN) method,5 which uses values of u at the six points in Fig. 467. The idea of the method is the replacement of the difference quotient on the right side of (4) by ![]() times the sum of two such difference quotients at two time rows (see Fig. 467). Instead of (4) we then have
times the sum of two such difference quotients at two time rows (see Fig. 467). Instead of (4) we then have
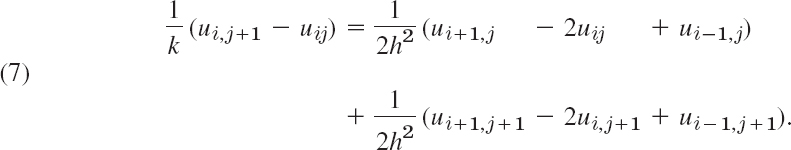
Multiplying by 2k and writing r = k/h2 as before, we collect the terms corresponding to time row j + 1 on the left and the terms corresponding to time row j on the right:

How do we use (8)? In general, the three values on the left are unknown, whereas the three values on the right are known. If we divide the x-interval 0 ![]() x
x ![]() 1 in (1) into n equal intervals, we have n − 1 internal mesh points per time row (see Fig. 465, where n = 4). Then for j = 0 and i = 1, …, n − 1, formula (8) gives a linear system of n − 1 equations for the n − 1 unknown values u11, u21, …, un−1,1 in the first time row in terms of the initial values u00, u10, …, un0 and the boundary values u01(= 0), un1 (= 0). Similarly for j = 1, j = 2, and so on; that is, for each time row we have to solve such a linear system of n − 1 equations resulting from (8).
1 in (1) into n equal intervals, we have n − 1 internal mesh points per time row (see Fig. 465, where n = 4). Then for j = 0 and i = 1, …, n − 1, formula (8) gives a linear system of n − 1 equations for the n − 1 unknown values u11, u21, …, un−1,1 in the first time row in terms of the initial values u00, u10, …, un0 and the boundary values u01(= 0), un1 (= 0). Similarly for j = 1, j = 2, and so on; that is, for each time row we have to solve such a linear system of n − 1 equations resulting from (8).
Although r = k/h2 is no longer restricted, smaller r will still give better results. In practice, one chooses a k by which one can save a considerable amount of work, without making r too large. For instance, often a good choice is r = 1 (which would be impossible in the previous method). Then (8) becomes simply
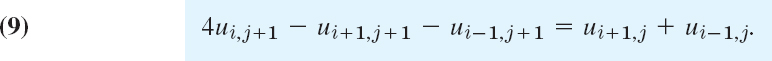
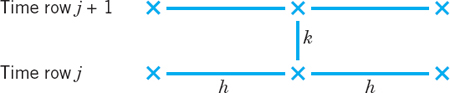
Fig. 467. The six points in the Crank–Nicolson formulas (7) and (8)

Fig. 468. Grid in Example 1
EXAMPLE 1 Temperature in a Metal Bar. Crank–Nicolson Method, Explicit Method
Consider a laterally insulated metal bar of length 1 and such that c2 = 1 in the heat equation. Suppose that the ends of the bar are kept at temperature u = 0°C and the temperature in the bar at some instant—call it t = 0—is f(x) = sin πx. Applying the Crank–Nicolson method with h = 0.2 and r = 1, find the temperature u(x, t) in the bar for 0 ![]() t
t ![]() 0.2. Compare the results with the exact solution. Also apply (5) with an r satisfying (6), say, and with values not satisfying (6), say, r = 1 and r = 2.5.
0.2. Compare the results with the exact solution. Also apply (5) with an r satisfying (6), say, and with values not satisfying (6), say, r = 1 and r = 2.5.
Solution by Crank–Nicolson. Since r = 1, formula (8) takes the form (9). Since h = 0.2 and r = k/h2 = 1, we have k = h2 = 0.04. Hence we have to do 5 steps. Figure 468 shows the grid. We shall need the initial values
![]()
Also, u30 = u20 and u40 = u10. (Recall that u10 means u at p10 in Fig. 468, etc.) In each time row in Fig. 468 there are 4 internal mesh points. Hence in each time step we would have to solve 4 equations in 4 unknowns. But since the initial temperature distribution is symmetric with respect to x = 0.5, and u = 0 at both ends for all t, we have u31 = u21, u41 = u11 in the first time row and similarly for the other rows. This reduces each system to 2 equations in 2 unknowns. By (9), since u31 = u21 and u01 = 0, for j = 0 these equations are

The solution is u11 = 0.399274, u21 = 0.646039. Similarly, for time row j = 1 we have the system

The solution is u12 = 0.271221, u22 = 0.438844, and so on. This gives the temperature distribution (Fig. 469):


Fig. 469. Temperature distribution in the bar in Example 1
Comparison with the exact solution. The present problem can be solved exactly by separating variables (Sec. 12.5); the result is
![]()
Solution by the explicit method (5) with r = 0.25. For h = 0.2 and r = k/h2 = 0.25 we have k = rh2 = 0.25 · 0.04 = 0.01. Hence we have to perform 4 times as many steps as with the Crank–Nicolson method! Formula (5) with r = 0.25 is
![]()
We can again make use of the symmetry. For j = 0 we need u00 = 0, u10 = 0.587785 (see p. 939), u20 = u30 = 0.951057 and compute

Of course we can omit the boundary terms u01 = 0, u02 = 0, … from the formulas. For j = 1 we compute
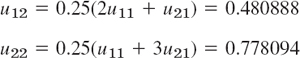
and so on. We have to perform 20 steps instead of the 5 CN steps, but the numeric values show that the accuracy is only about the same as that of the Crank–Nicolson values CN. The exact 3D-values follow from (10).
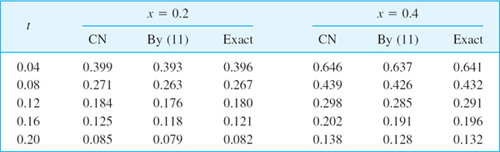
Failure of (5) with r violating (6). Formula (5) with h = 0.2 and r = 1—which violates (6)—is
![]()
and gives very poor values; some of these are

Formula (5) with an even larger r = 2.5 (and h = 0.2 as before) gives completely nonsensical results; some of these are

- Nondimensional form. Show that the heat equation
 , can be transformed to the “nondimensional” standard form ut = uxx, 0 x 1, by setting
, can be transformed to the “nondimensional” standard form ut = uxx, 0 x 1, by setting 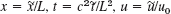 , where u0 is any constant temperature.
, where u0 is any constant temperature. - Difference equation. Derive the difference approximation (4) of the heat equation.
- Explicit method. Derive (5) by solving (4) for ui,j+1.
- CAS EXPERIMENT. Comparison of Methods.
- Write programs for the explicit and the Crank—Nicolson methods.
- Apply the programs to the heat problem of a laterally insulated bar of length 1 with u(x, 0) = sin πx and u(0, t) = u(1, t) = 0 for all t, using h = 0.2, k = 0.01 for the explicit method (20 steps), h = 0.2 and (9) for the Crank–Nicolson method (5 steps). Obtain exact 6D-values from a suitable series and compare.
- Graph temperature curves in (b) in two figures similar to Fig. 299 in Sec. 12.7.
- Experiment with smaller h (0.1, 0.05, etc.) for both methods to find out to what extent accuracy increases under systematic changes of h and k.
EXPLICIT METHOD
- 5. Using (5) with h = 1 and k = 0.5, solve the heat problem (1)–(3) to find the temperature at t = 2 in a laterally insulated bar of length 10 ft and initial temperature f(x) = x(1 − 0.1x).
- 6. Solve the heat problem (1)–(3) by the explicit method with h = 0.2 and k = 0.01, 8 time steps, when f(x) = x if
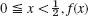 , f(x) = 1 − x if
, f(x) = 1 − x if 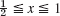 . Compare with the 3S-values 0.108, 0.175 for t = 0.08, x = 0.2, 0.4 obtained from the series (2 terms) in Sec. 12.5.
. Compare with the 3S-values 0.108, 0.175 for t = 0.08, x = 0.2, 0.4 obtained from the series (2 terms) in Sec. 12.5. - 7. The accuracy of the explicit method depends on
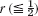 . Illustrate this for Prob. 6, choosing
. Illustrate this for Prob. 6, choosing  (and h = 0.2 as before). Do 4 steps. Compare the values for t = 0.04 and 0.08 with the 3S-values in Prob. 6, which are 0.156, 0.254 (t = 0.04), 0.105, 0.170 (t = 0.08).
(and h = 0.2 as before). Do 4 steps. Compare the values for t = 0.04 and 0.08 with the 3S-values in Prob. 6, which are 0.156, 0.254 (t = 0.04), 0.105, 0.170 (t = 0.08). - 8. In a laterally insulated bar of length 1 let the initial temperature be f(x) = x if 0 x < 0.5, f(x) = 1 − x if 0.5 x 1. Let (1) and (3) hold. Apply the explicit method with h = 0.2, k = 0.01, 5 steps. Can you expect the solution to satisfy u(x, t) = u(1 − x, t) for all t?
- 9. Solve Prob. 8 with f(x) = x if 0 x 0.2, f(x) = 0.25(1 − x) if 0.2 < x 1, other data being as before.
- 10. Insulated end. If the left end of a laterally insulated bar extending from x = 0 to x = 1 is insulated, the boundary condition at x = 0 is un(0, t) = ux(0, t) = 0. Show that, in the application of the explicit method given by (5), we can compute u0j+1 by the formula

Apply this with h = 0.2 and r = 0.25 to determine the temperature u(x, t) in a laterally insulated bar extending from x = 0 to 1 if u(x, 0) the left end is insulated and the right end is kept at temperature
 . Hint. Use 0 = ∂u0j/∂x = (u1j − u−1j)/2h.
. Hint. Use 0 = ∂u0j/∂x = (u1j − u−1j)/2h.
CRANK–NICOLSON METHOD
- 11. Solve Prob. 9 by (9) with h = 0.2, 2 steps. Compare with exact values obtained from the series in Sec. 12.5 (2 terms) with suitable coefficients.
- 12. Solve the heat problem (1)–(3) by Crank–Nicolson for 0 t 0.20 with h = 0.2 and k = 0.04 when f(x) = x if
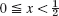 , f(x) = 1 − x − x if
, f(x) = 1 − x − x if  . Compare with the exact values for t = 0.20 obtained from the series (2 terms) in Sec. 12.5.
. Compare with the exact values for t = 0.20 obtained from the series (2 terms) in Sec. 12.5.
13–15 Solve (1)–(3) by Crank–Nicolson with r = 1 (5 steps), where:
- 13. f(x) = 5x if 0 x < 0.25, f(x) = 1.25(1 − x) if 0.25 x 1, h = 0.2
- 14. f(x) = x(1 − x), h = 0.1. (Compare with Prob. 15.)
- 15. f(x) = x(1 − x), h = 0.2
21.7 Method for Hyperbolic PDEs
In this section we consider the numeric solution of problems involving hyperbolic PDEs. We explain a standard method in terms of a typical setting for the prototype of a hyperbolic PDE, the wave equation:

Note that an equation utt = c2uxx and another x-interval can be reduced to the form (1) by a linear transformation of x and t. This is similar to Sec. 21.6, Prob. 1.
For instance, (1)–(4) is the model of a vibrating elastic string with fixed ends at x = 0 and x = 1 (see Sec. 12.2). Although an analytic solution of the problem is given in (13), Sec. 12.4, we use the problem for explaining basic ideas of the numeric approach that are also relevant for more complicated hyperbolic PDEs.
Replacing the derivatives by difference quotients as before, we obtain from (1) [see (6) in Sec. 21.4 with y = t]

where h is the mesh size in x, and k is the mesh size in t. This difference equation relates 5 points as shown in Fig. 470a. It suggests a rectangular grid similar to the grids for parabolic equations in the preceding section. We choose r* = k2/h2 = 1. Then uij drops out and we have

It can be shown that for 0 < r* ![]() 1 the present explicit method is stable, so that from (6) we may expect reasonable results for initial data that have no discontinuities. (For a hyperbolic PDE the latter would propagate into the solution domain—a phenomenon that would be difficult to deal with on our present grid. For unconditionally stable implicit methods see [E1] in App. 1.)
1 the present explicit method is stable, so that from (6) we may expect reasonable results for initial data that have no discontinuities. (For a hyperbolic PDE the latter would propagate into the solution domain—a phenomenon that would be difficult to deal with on our present grid. For unconditionally stable implicit methods see [E1] in App. 1.)

Fig. 470. Mesh points used in (5) and (6)
Equation (6) still involves 3 time steps j − 1,j,j + 1, whereas the formulas in the parabolic case involved only 2 time steps. Furthermore, we now have 2 initial conditions. So we ask how we get started and how we can use the initial condition (3). This can be done as follows.
From ut(x, 0) = g(x) we derive the difference formula

where. gi = g(ih). For t = 0, that is, j = 0, equation (6) is
![]()
Into this we substitute ui, −1 as given in (7). We obtain ui1 = ui−1,0 + ui+1,0 − ui1 + 2kgi and by simplification
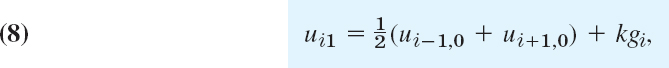
This expresses ui1 in terms of the initial data. It is for the beginning only. Then use (6).
EXAMPLE 1 Vibrating String, Wave Equation
Apply the present method with h = k = 0.2 to the problem (1)–(4), where
![]()
Solution. The grid is the same as in Fig. 468, Sec. 21.6, except for the values of t, which now are 0.2, 0.4, … (instead of 0.04, 0.08,…). The initial values u00, u10, … are the same as in Example 1, Sec. 21.6. From (8) and g(x) = 0 we have
![]()
From this we compute, using u10 = u40 = sin 0.2π = 0.587785, u20 = u30 = 0.951057,

and u31 = u21, u41 = u11 by symmetry as in Sec. 21.6, Example 1. From (6) with j = 1 we now compute, using u01 = u02 = … = 0,

and u32 = u22, u42 = u12 by symmetry; and so on. We thus obtain the following values of the displacement of the string over the first half-cycle:
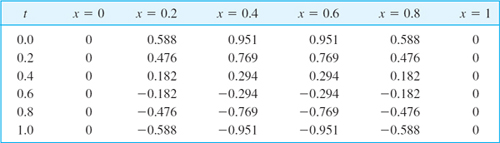
These values are exact to 3D (3 decimals), the exact solution of the problem being (see Sec. 12.3)
![]()
The reason for the exactness follows from d'Alembert's solution (4), Sec. 12.4. (See Prob. 4, below.)
This is the end of Chap. 21 on numerics for ODEs and PDEs, a field that continues to develop rapidly in both applications and theoretical research. Much of the activity in the field is due to the computer serving as an invaluable tool for solving large-scale and complicated practical problems as well as for testing and experimenting with innovative ideas. These ideas could be small or major improvements on existing numeric algorithms or testing new algorithms as well as other ideas.
VIBRATING STRING
1–3 Using the present method, solve (1)–(4) with h = k = 0.2 for the given initial deflection f(x) and initial velocity 0 on the given t-interval.
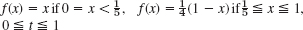
- f(x) = x12 − x3, 0 t 2
- f(x) = 0.2(x − x2), 0 t 2
- Another starting formula. Show that (12) in Sec. 12.4 gives the starting formula
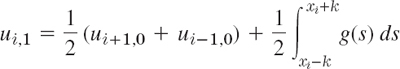
(where one can evaluate the integral numerically if necessary). In what case is this identical with (8)?
- Nonzero initial displacement and speed. Illustrate the starting procedure when both f and g are not identically zero, say, f(x) = 1 − cos 2πx, g(x) = x(1 − x), h = k = 0.1, 2 time steps.
- Solve (1)–(3) (h = k = 0.2, 5 time steps) subject to f(x) = x2, g(x) = 2x, ux(0, t) = 2t, u(1, t = (1 + t)2.
- Zero initial displacement. If the string governed by the wave equation (1) starts from its equilibrium position with initial velocity g(x) = sin πx, what is its displacement at time t = 0.4 and x = 0.2, 0.4, 0.6, 0.8? (Use the present method with h = 0.2, k = 0.2. Use (8). Compare with the exact values obtained from (12) in Sec. 12.4.)
- Compute approximate values in Prob. 7, using a finer grid (h = 0.1, k = 0.1), and notice the increase in accuracy.
- Compute u in prob. 5 for t = 0.1 and x = 0.1, 0.2, …, 0.9, using the formula in Prob. 8, and compare the values.
- Show that from d’ Alembert's solution (13) in Sec. 12.4 with c = 1 it follows that (6) in the present section gives the exact value ui,j+1 = u(ih, (j + 1)h).
CHAPTER 21 REVIEW QUESTIONS AND PROBLEMS
- Explain the Euler and improved Euler methods in geometrical terms. Why did we consider these methods?
- How did we obtain numeric methods from the Taylor series?
- What are the local and the global orders of a method? Give examples.
- Why did we compute auxiliary values in each Runge–Kutta step? How many?
- What is adaptive integration? How does its idea extend to Runge–Kutta?
- What are one-step methods? Multistep methods? The underlying ideas? Give examples.
- What does it mean that a method is not self-starting? How do we overcome this problem?
- What is a predictor–corrector method? Give an important example.
- What is automatic step size control? When is it needed? How is it done in practice?
- How do we extend Runge–Kutta to systems of ODEs?
- Why did we have to treat the main types of PDEs in separate sections? Make a list of types of problems and numeric methods.
- When and how did we use finite differences? Give as many details as you can remember without looking into the text.
- How did we approximate the Laplace and Poisson equations?
- How many initial conditions did we prescribe for the wave equation? For the heat equation?
- Can we expect a difference equation to give the exact solution of the corresponding PDE?
- In what method for PDEs did we have convergence problems?
- Solve y′ = y, y(0) = 1 by Euler's method, 10 steps, h = 0.1.
- Do Prob. 17 with h = 0.01, 10 steps. Compute the errors. Compare the error for x = 0.1 with that in Prob. 17.
- Solve y′ = 1 + y2, y(0) = 3 by the improved Euler method, 10 steps.
- Solve y′ = y = (x + 1)2, y(0) = 3 by the improved Euler method, 10 steps with h = 0.1. Determine the errors.
- Solve Prob. 19 by RK with h = 0.1, 5 steps. Compute the error. Compare with Prob. 19.
- Fair comparison. Solve
 , y(1) = 0 for 1 x 1.8 (a) by the Euler method with h = 0.1, (b) by the improved Euler method with h = 0.2, and (c) by RK with h = 0.4. Verify that the exact solution is y = (In x)2 + In x. Compute and compare the errors. Why is the comparison fair?
, y(1) = 0 for 1 x 1.8 (a) by the Euler method with h = 0.1, (b) by the improved Euler method with h = 0.2, and (c) by RK with h = 0.4. Verify that the exact solution is y = (In x)2 + In x. Compute and compare the errors. Why is the comparison fair? - Apply the Adams–Moulton method to
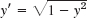 , y(0) = 0, h = 0.2, x = 0, …, 1, starting with 0.198668, 0.389416, 0.564637.
, y(0) = 0, h = 0.2, x = 0, …, 1, starting with 0.198668, 0.389416, 0.564637. - Apply the A–M method to y′ = (x + y − 4)2, y(0) = 4, h = 0.2, x = 0, …, 1, starting with 4.00271, 4.02279, 4.08413.
- Apply Euler's method for systems to y″ = x2y, y(0) = 1, y′(0) = 0, h = 0.1, 5 steps.
- Apply Euler's method for systems to
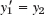 ,
,  y1(0) = 2, y2(0) = 0, h = 0.2, 10 steps. Sketch the solution.
y1(0) = 2, y2(0) = 0, h = 0.2, 10 steps. Sketch the solution. - Apply Runge–Kutta for systems to y″ + y = 2ex, y(0) = 0, y′(0) = 1, h = 0.2, 5 steps. Determine the errors.
- Apply Runge–Kutta for systems to
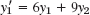 ,
,  , y1(0) = −3, y2(0) = −3, h = 0.05, 3 steps.
, y1(0) = −3, y2(0) = −3, h = 0.05, 3 steps. - Find rough approximate values of the electrostatic potential at p11, p12, p13 in Fig. 471 that lie in a field between conducting plates (in Fig. 471 appearing as sides of a rectangle) kept at potentials 0 and 220 V as shown. (Use the indicated grid.)
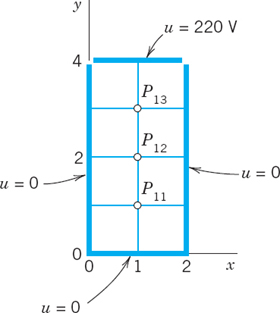
- A laterally insulated homogeneous bar with ends at x = 0 and x = 1 has initial temperature 0. Its left end is kept at 0, whereas the temperature at the right end varies sinusoidally according to
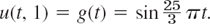
Find the temperature u(x, t) in the bar [solution of (1) in Sec. 21.6] by the explicit method with h = 0.2 and r = 0.5 (one period, that is, 0
t 0.24). - Find the solution of the vibrating string problem utt = uxx, u(x, 0) = x(1 − x), ut = 0, u(0, t) = u(1, t) = 0 by the method in Sec. 21.7 with h = 0.1 and k = 0.1 for t = 0.3.
32–34 POTENTIAL
Find the potential in Fig. 472, using the given grid and the boundary values:
- 32.

- 33. u(p10) = u(p30) = 960, u(p20) = −480, u = 0 elsewhere on the boundary
- 34. u = 70 on the upper and left sides, u = 0 on the lower and right sides

- 35. Solve ut = uxx(0 x 1, t
 0), u(x, 0) = x2(1 − x), u(0, t) = u(1, t) = 0 by Crank–Nicolson with h = 0.2, k = 0.04, 5 time steps.
0), u(x, 0) = x2(1 − x), u(0, t) = u(1, t) = 0 by Crank–Nicolson with h = 0.2, k = 0.04, 5 time steps.
SUMMARY OF CHAPTER 21
Numerics for ODEs and PDEs
In this chapter we discussed numerics for ODEs (Secs. 21.1–21.3) and PDEs (Secs. 21.4–21.7). Methods for initial value problems
![]()
involving a first-order ODE are obtained by truncating the Taylor series
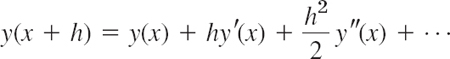
where, by (1), y′ = f, y″ = f′ = ∂f/∂x + (∂f/∂y)y′, etc. Truncating after the term hy′, we get the Euler method, in which we compute step by step
![]()
Taking one more term into account, we obtain the improved Euler method. Both methods show the basic idea but are too inaccurate in most cases.
Truncating after the term in h4, we get the important classical Runge–Kutta (RK) method of fourth order. The crucial idea in this method is the replacement of the cumbersome evaluation of derivatives by the evaluation of f(x, y) at suitable points (x, y); thus in each step we first compute four auxiliary quantities (Sec. 21.1)

and then the new value
![]()
Error and step size control are possible by step halving or by RKF (Runge–Kutta–Fehlberg).
The methods in Sec. 21.1 are one-step methods since they get yn+1 from the result yn of a single step. A multistep method (Sec. 21.2) uses the values of yn, yn−1, … of several steps for computing yn+1. Integrating cubic interpolation polynomials gives the Adams–Bashforth predictor (Sec. 21.2)
![]()
where fj = f(xj, yj), and an Adams–Moulton corrector (the actual new value)
![]()
where ![]() . Here, to get started, y1, y2, y3 must be computed by the Runge–Kutta method or by some other accurate method.
. Here, to get started, y1, y2, y3 must be computed by the Runge–Kutta method or by some other accurate method.
Section 19.3 concerned the extension of Euler and RK methods to systems
![]()
This includes single m th-order ODEs, which are reduced to systems. Second-order equations can also be solved by RKN (Runge–Kutta–Nyström) methods. These are particularly advantageous for y″ = f(x, y) with f not containing y′.
Numeric methods for PDEs are obtained by replacing partial derivatives by difference quotients. This leads to approximating difference equations, for the Laplace equation to
![]()
for the heat equation to
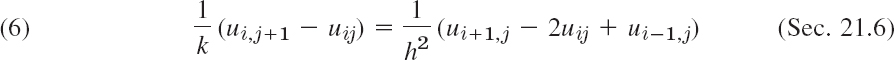
and for the wave equation to
![]()
here h and k are the mesh sizes of a grid in the x- and y-directions, respectively, where in (6) and (7) the variable y is time t.
These PDEs are elliptic, parabolic, and hyperbolic, respectively. Corresponding numeric methods differ, for the following reason. For elliptic PDEs we have boundary value problems, and we discussed for them the Gauss–Seidel method (also known as Liebmann's method) and the ADI method (Secs. 21.4, 21.5). For parabolic PDEs we are given one initial condition and boundary conditions, and we discussed an explicit method and the Crank–Nicolson method (Sec. 21.6). For hyperbolic PDEs, the problems are similar but we are given a second initial condition (Sec. 21.7).
1Named after the German mathematicians KARL RUNGE (Sec. 19.4) and WILHELM KUTTA (1867–1944). Runge [Math. Annalen 46 (1895), 167–178], the German mathematician KARL HEUN (1859–1929) [Zeitschr. Math. Phys. 45 (1900), 23–38], and Kutta [Zeitschr. Math. Phys. 46 (1901), 435–453] developed various similar methods. Theoretically, there are infinitely many fourth-order methods using four function values per step. The method in Table 21.3 is most popular from a practical viewpoint because of its “symmetrical” form and its simple coefficients. It was given by Kutta.
2Named after JOHN COUCH ADAMS (1819–1892), English astronomer and mathematician, one of the predictors of the existence of the planet Neptune (using mathematical calculations), director of the Cambridge Observatory; and FRANCIS BASHFORTH (1819–1912), English mathematician.
3FOREST RAY MOULTON (1872–1952), American astronomer at the University of Chicago. For ADAMS see footnote 2.
4Named after Sir GEORGE BIDELL AIRY (1801–1892), English mathematician, who is known for his work in elasticity and in PDEs.
5JOHN CRANK (1916–2006), English mathematician and physicist at Courtaulds Fundamental Research Laboratory, professor at Brunel University, England. Student of Sir WILLIAM LAWRENCE BRAGG (1890–1971), Australian British physicist, who with his father, Sir WILLIAM HENRY BRAGG (1862–1942) won the Nobel Prize in physics in 1915 for their fundamental work in X-ray crystallography. (This is the only case where a father and a son shared the Nobel Prize for the same research. Furthermore, W. L. Bragg is the youngest Nobel laureate ever.) PHYLLIS NICOLSON (1917–1968), English mathematician, professor at the University of Leeds, England.