
Chapter 13. PDFs inside-out
This chapter covers
- The history of PDF
- The Carousel Object System
- Low-level PDF manipulation
One of the initial strengths that made iText a success was that a developer was—and still is—able to create documents in the PDF format without having to know anything about the PDF specification. In the first versions of iText, you only had to know how a Chunk related to a Phrase, a Phrase to a Paragraph, and so on. The functionality was simple, but rather limited. Features that are specific to PDF, such as forms, optional content, and file attachments, weren’t supported yet. The more functionality was added, the more there was a need for developers to understand what PDF is about. That’s why we’re going to take a look inside.
But before you open up a PDF file, let’s look at why PDF was invented and how the format evolved from a de facto to an ISO standard.
13.1. PDF, why and how?
We can’t talk about the history of PDF without talking about the history of the inventors of PDF, Adobe Systems Incorporated. Adobe was founded in 1982 by John Warnock and Chuck Geschke. Its first products were digital fonts, but nowadays Adobe offers a wide range of products and technologies. In this section, we’ll look at the ancestors of PDF, and you’ll learn about the different types of PDF that were created for different purposes.
13.1.1. The ancestors of PDF
In 1985, Adobe introduced the PostScript (PS) Page Description Language (PDL). PS is an interpretive programming language. Its primary goal is to describe the appearance of text, graphical shapes, and sampled images. It also provides a framework for controlling printing devices; for example, it can specify the number of copies to be printed, activate duplicate printing, and so forth.
Also in 1985, Adobe developed an application for the Apple Macintosh called Adobe Illustrator, a vector-based drawing program with its own format, AI, which was derived from PS. Illustrator was ported to Windows in 1989, so it covered an important market in the graphical industry.
Producing high-quality visual materials was the privilege of specialists for a long time, but with the advent of PostScript and Illustrator, anyone with a computer could accomplish high-end document publishing. By introducing these two technologies, Adobe started the desktop publishing revolution. But the founders of Adobe felt there was something missing.
In 1991, John Warnock wrote the “Camelot paper,” in which he said:
The specific problem is that most programs print to a wide range of printers, but there is no universal way to communicate and view this printed information electronically... What industries badly need is a universal way to communicate documents across a wide variety of machine configurations, operating systems, and communication networks.
The Camelot Project, John Warnock
As a result of this writing, a new development project was started, and the engineers at Adobe enhanced the PostScript and Illustrator technologies to create a suite of applications with which to create and visualize documents of this format. Carousel was the original code name for what later became Acrobat. The new document format was originally called Interchange PostScript (IPS) but was soon known as the Portable Document Format (PDF).
13.1.2. The history of PDF
In February 1993, Jim King, Adobe’s principal scientist, talked about “liberating” the information locked up on computer systems. In many cases, you had to use the computer application that was used to collect and assemble a document in order to read it on screen or to print it.
This is analogous to requiring the reader of a newspaper to own a photo-typesetting machine. Or the reader of a book to own a printing press. Acrobat frees the computer industry from this ridiculous model, establishing a standard for electronic final-form documents and providing simple viewing and printing tools that are widely and generally usable. Acrobat is an information liberation system!
Jim King, principal scientist, Adobe
PDF is called the Portable Document Format because a PDF document can be viewed and printed on any platform: Windows, Mac, Linux, and so on. In theory, a PDF document looks the same on any of these platforms (although we’ve looked at some exceptions, such as in chapters 2 and 11 when we talked about embedding fonts). In analogy with Java’s Write Once, Run Anywhere, you could say PDF is Write Once, Read Anywhere—but in a more reliable way than the catchy Java advertising phrase promises.
In June 1993, Adobe announced its new product, Acrobat. The first documentation on PDF was called the Portable Document Format Reference Manual and published by Addison-Wesley. Five more editions would follow, although not all of them were printed on paper—the sixth edition for PDF version 1.7 was only available as a PDF document. Figure 13.1 shows the cover of the first PDF reference, as well as an advertisement for the Acrobat Starter Kit, and the diskettes on which Acrobat was distributed.
Figure 13.1. PDF reference cover, Acrobat Starter Kit advertisement, and Acrobat diskettes

In September 1993, Acrobat Exchange was the software that allowed users to exchange electronic documents with other Adobe Acrobat users. They could create, view, collate, navigate, place sticky notes, and print documents for $195. Acrobat Distiller converted (and still converts) PS to PDF. Distiller was priced at $695; Network Distiller at $2495. Finally, there was Acrobat Reader, described as “a special tool for corporate and commercial publishers who need to distribute documents to large audiences (50 or more) in the most time-efficient and cost effective way.” In those days, Reader wasn’t distributed for free; it was sold at $2500 for 50 copies. By version 2.0, released in 1994, the Reader was made available for free and Distiller was included with Acrobat Pro.
The Relationship Between PDF and PS
Although PS and PDF are related, they’re different formats. PDF leverages the ability of the PS language to render complex text and graphics, and brings this feature to the screen as well as to the printer. With PDF, reduced flexibility was traded for improved efficiency and predictability. Unlike PS, PDF can contain a lot of document structure, links, and other related information, but PDF can’t tell the printer to use a certain input tray, change the resolution, or use any other hardware-specific features.
PDF isn’t a programming language like PS. A PDF file consists of a number of objects. In his presentations about the PDF format, Jim King often refers to PDF as “object-oriented PostScript” because this object structuring is something that doesn’t exist in PS. We’ll have a closer look at the different objects in the Carousel Object System (COS) in section 13.2.
One of the key advantages PDF has over PS is page independence. With PS, something in the description of page 1 can affect page 1000, so to view page 1000, you have to interpret all the pages before it. PDF and PS share the same underlying Adobe imaging model, but in PDF, each page is self-contained and can be drawn individually. Each page has access to the text, font specifications, margins, layout, graphical elements, and background and text colors. We’ll have a closer look at the syntax for drawing content in chapter 14, and at the way font specifications and graphical elements are embedded in the document in chapter 16.
But let’s continue with the historical overview of PDF and Acrobat.
PDF Version History
In some of the examples you’ve made so far, you’ve changed the PDF version of a document because you were using technology that was introduced in a later version than the default. Table 13.1 shows a nonexhaustive list of new features that were added in each version.
Table 13.1. New features in different PDF versions
|
PDF version |
Year |
Version |
New features |
|---|---|---|---|
| PDF-1.0 | 1993 | Acrobat 1 |
|
| PDF-1.1 | 1994 | Acrobat 2 |
|
| PDF-1.2 | 1996 | Acrobat 3 |
|
| PDF-1.3 | 1999 | Acrobat 4 |
|
| PDF-1.4 | 2001 | Acrobat 5 |
|
| PDF-1.5 | 2003 | Acrobat 6 |
|
| PDF-1.6 | 2004 | Acrobat 7 |
|
| PDF-1.7 | 2006 | Acrobat 8 |
|
| PDF-1.7 Extension Level 3 | 2008 | Acrobat 9.0 |
|
| PDF-1.7 Extension Level 5 | 2009 | Acrobat 9.1 |
|
| PDF-2.0 | 2011 | Acrobat 10? |
|
The final part of this table needs more explaining. Up until PDF 1.7, Adobe owned the copyright of the PDF specification. To promote the use of the format for information exchange among diverse products and applications—including, but not necessarily limited to, Acrobat products—Adobe gave anyone copyright permission to do the following:
- Prepare files whose content conforms to the specification
- Write drivers and applications that produce output represented in PDF
- Write software that accepts input in PDF and displays, prints, or otherwise interprets the contents
- Copy Adobe’s copyrighted list of data structures and operators, as well as the example code and PostScript language function definitions to the extent necessary to use PDF for the purposes above
These were the conditions of such copyright permissions:
- Authors of software that accepts input in the form of PDF must make reasonable efforts to ensure that the software they create respects the access permissions and permissions controls.
- Anyone who uses the copyrighted list of data structures and operators, as stated above, must include an appropriate copyright notice.
These permissions granted by Adobe made it possible for me to start writing iText. Looking at the success of iText, I must have found a hole in the market. Whereas Acrobat was an information liberation system for data locked away on your computer, iText enabled you to liberate the data on your server. At the time iText was developed, the End User License Agreement of Acrobat (EULA) prevented the use of the product to produce PDF documents for multiple users on a server. The EULA of Acrobat still prevents this use, but Adobe now offers LiveCycle Enterprise Suite as a very powerful server solution.
13.1.3. PDF as an ISO standard
In spite of the far-reaching freedom provided by Adobe, there were always people who didn’t consider the format open enough. They pestered Adobe because the company kept the privilege of owning and controlling the language specification, whereas the trend of the new millennium was to make everything as open as possible. At some point, Adobe must have decided the time was ripe to make this decision:
SAN JOSE, Calif.—Jan. 29, 2007—Adobe Systems Incorporated (Nasdaq:ADBE) today announced that it intends to release the full Portable Document Format (PDF) 1.7 specification to AIIM, the Enterprise Content Management Association, for the purpose of publication by the International Organization for Standardization (ISO).
Adobe Press Release
Jim King explains why this decision was made:
It was not a simple or easy decision for Adobe to make, but it has come up nearly every year since we first announced PDF and each time we’ve decided not to do it. I view it as a balance scale for weighing things. We put positive things on the right side and negative things on the left. Negative and positive for all of Adobe, our customers, our competitors, etc. It always has come out not to do it. Things do change and this year it came out (to my surprise) that the scale tipped the other way for the first time. There were just too many good reasons to do it and not many not so good. We believe that it will benefit everyone. I have been asked if this was in response to the pressure from government for open specifications or because of something Microsoft has done or might do, or because we think the language is becoming mature. Well my answer is yes, of course, but not because of any single one of those kinds of things. Just the accumulated long list of benefits and the scale tipped.
The Future of PDF and Flash, Jim King
The standard was published by the ISO on July 1, 2008. To us, iText users and developers working with PDF, the corporate politics didn’t really matter; my personal reason why I liked Adobe bringing the specification to ISO was nicely phrased by Jim King:
From what I have been able to figure out there are over a billion PDF files being stored on computers in this world—could be a lot bigger number. What we want to do is to help ISO get an accurate specification under their control that documents the rules all those PDF files obey. We think they all, well nearly all, obey Adobe’s current PDF 1.7 specification so a clean clear ISO version of that is what we’re after. Please note that this is not tied in any significant way to Adobe products like Acrobat. It is your billion PDF files we’re interested in documenting, not Acrobat. Once the ISO standard has been established, Adobe will be just one other (key we hope) company working together with other companies to make any changes to ISO PDF that are needed.
The Future of PDF and Flash, Jim King
From now on, any company can write their own extensions to the Portable Document Format and submit them to ISO as proposed changes to the PDF specification. ISO may or may not accept these extensions; for instance, Adobe submitted a series of proposals for inclusion in ISO-32000-2. This new ISO will be published in 2011 and will result in PDF version 2.0. (There will be no PDF version 1.8.)
Extensions to the PDF specification aren’t identified by PDF version identifiers. They use the extension mechanism defined in ISO-32000-1. The new convention lets companies and other entities identify their own extensions relative to a base version of PDF. Additionally, the convention identifies extension levels relative to that base version. Table 13.1 listed extension levels 3 and 5. These are two extensions published by Adobe for Acrobat 9.0 and 9.1.
The intent of the extensions convention is twofold:
- To enable developers of PDF-producing applications to identify the use of company-specific extensions they have added to a PDF document and to associate those extensions with their own publicly available specifications.
- To enable developers of PDF-consuming applications to determine which extensions are present in a PDF document and to associate those extensions with the specifications that describe them.
To avoid collisions over company names and company-specific extension names, ISO provides the prefix name registry. The prefix registry designates a 4-character, case-sensitive prefix that identifies a company or other entity. This prefix is used for company-specific version identifiers. For example, ADBE is the prefix registered by Adobe; ITXT is the prefix used for iText. For more info about the use of these prefixes, read appendix E of ISO-32000-1.
ISO-32000 wasn’t the first ISO standard for PDF, nor will it be the last.
13.1.4. PDF/X, PDF/A, PDF/E, PDF/UA, and other types of PDF
There are many different ways to create a valid PDF file. This freedom is an advantage, but it can be a disadvantage too. Not all valid PDF files are usable in every context. To tackle this problem, different ISO standards were created, the first one dating from 2001: PDF/X.
X For Exchange
The prepress sector uses PDF for a very specific purpose: to create digital documents that are meant to be produced on a printing press. Quality press output requires depositing precise amounts of different colors of ink at resolutions as high as 5000 dots per inch. Such high resolution also calls for images to have been sampled at a high rate. Not just any old PDF file can be used to produce high-quality press output under these conditions.
Confronted with a number of issues relating to parts of the PDF reference, a consortium of prepress companies got together and released specifications for PDF/X. This is a set of ISO standards (ISO 15930-1 to ISO 15930-8) describing well-defined subsets of the PDF specification that promise predictable and consistent output for press printing. Because these standards are subsets of PDF, files meeting these standards also meet the standard as normal PDF files. Each of these PDF/X standards has its own specific requirements and constraints, but in general you can say that functionality that will probably break PDF/X conformance includes encryption, the use of fonts that aren’t embedded, RGB colors, layers, image masks, transparency, and some blend modes.
The two most useful PDF/X standards are supported by iText: PDF/X-1a:2001 and PDF/X-3:2002. The main goal of PDF/X-1a is to support blind exchange of PDF documents. Blind exchange means you can deliver PDF documents to a print service provider with hardly any technical discussion. PDF/X-3 is a superset of PDF/X-1a. The primary difference is that a PDF/X-3 file can also contain color-managed data. This listing shows how to set the PDF/X conformance. You can replace the parameter PdfWriter.PDFX1A2001 with PdfWriter.PDFX32002 to change the conformance to PDF/X-3.
Listing 13.1. PdfXPdfA.java

As soon as you introduce functionality that isn’t allowed in the PDF/X specification you’ve chosen, iText will throw an exception explaining what went wrong. For instance, try making these changes:
- Replace BaseFont.EMBEDDED
 with BaseFont.NOT_EMBEDDED. Try executing the example, and it will throw an exception saying, “All the fonts must be embedded. This one isn’t: ArialMT.”
with BaseFont.NOT_EMBEDDED. Try executing the example, and it will throw an exception saying, “All the fonts must be embedded. This one isn’t: ArialMT.”
- Replace the CMYKColor
 used for the font color by an instance of the BaseColor class. iText will throw the following error: “Colorspace RGB is not allowed.”
used for the font color by an instance of the BaseColor class. iText will throw the following error: “Colorspace RGB is not allowed.”
The exceptions help you discover what is missing.
iText has similar functionality for PDF/A, although iText won’t always throw an exception if you forget some of the requirements. You need a PDF validator after creating a PDF/A file with iText to see if you’ve met all the conditions and restrictions.
A For Archiving
The PDF/A specification is also known as ISO 19005-1:2005: Document Management—Electronic Document File Format for Long-Term Preservation—Part 1: Use of PDF 1.4 (PDF/A-1). The standard was approved in September 2005. The initiative for PDF/A was started by the Association for Information and Image Management (AIIM) and the Association for Suppliers of Printing, Publishing, and Converting Technology (NPES).
There are many electronic formats and technologies to choose from for archiving electronic data. The proprietary nature of many of these formats is one of the biggest disadvantages. There’s no guarantee that a Word document created with the latest Microsoft Word version will open up in the newest version ten years from now. And even if you’re able to open it, you can’t expect it to look like it looked in the version of Word that was used to create it.
As opposed to most word-processing formats, PDF represents not only the data contained in the document, but also the exact form the document takes. The file can be viewed without the originating application. Adobe also made sure that all the revisions of the PDF specification are backward compatible, so no matter the version number, the PDF will always look the same even on newer PDF viewers. Even before PDF was published as an ISO standard, the PDF version of the specification was available for free. Anyone, at any time, using any hardware or software, can create programs to access PDF documents. This makes PDF (ISO-32000) an interesting candidate as a format for archiving.
PDF/A goes a step further. It’s a subset of PDF-1.4, and like PDF/X, PDF/A imposes requirements and constraints.
PDF/A Level B
In order to meet level-B conformance, all fonts must be embedded, encryption isn’t allowed, audio and video content are forbidden, JavaScript and executable file launches are not permitted, and so forth. Each PDF/A document must contain metadata in the form of an XMP stream.
Here is how to create a level-B PDF/A document using iText.
Listing 13.2. PdfXPdfA.java

In this example, you create XMP metadata ![]() , embed the font
, embed the font ![]() , and create a color profile. The constant PROFILE refers to a color profile saved on disk. This profile is used to set the output intents
, and create a color profile. The constant PROFILE refers to a color profile saved on disk. This profile is used to set the output intents ![]() . When color values are specified in a PDF file using the device color spaces, those values are to directly control the quantity
of colorant (ink) used on a particular device or device class. The output intent supplies the color characteristics of that
device so that the actual colors to be produced can be know in a device-independent way.
. When color values are specified in a PDF file using the device color spaces, those values are to directly control the quantity
of colorant (ink) used on a particular device or device class. The output intent supplies the color characteristics of that
device so that the actual colors to be produced can be know in a device-independent way.
PDF/A Level A
Level-A conformance includes all the requirements and constraints of level-B, but also requires that the PDF be tagged. Tagged PDF is a stylized use of PDF; it defines a set of standard structure types and attributes that allow page content to be extracted and reused for other purposes. Page content is represented so that the characters, words, and text order can be determined reliably. We’ll learn about some more advantages of tagged PDFs when we discuss PDF/UA, and we’ll create tagged PDFs in chapter 15.
Another important step in the history of PDF ISO specifications is PDF/E.
E For Engineering
PDF/E, or ISO 24517-1:2008, was ratified by ISO as an open standard in June 2007. Based on PDF 1.6, it’s meant to be used in engineering workflows. It was designed to be an open and neutral exchange format for engineering and technical documentation. PDF/E provides secure distribution of intellectual property and reliable exchange and change management. It also reduces costs associated with paper (including the cost to store and archive paper). It covers three primary areas:
- Compact, accurate printing of engineering drawings.
- Support for exchanging and managing annotation and comment data.
- Incorporation of complex data into PDF (3D, object-level data, and so on)
There’s no direct support for PDF/E in iText yet. But there’s already some functionality added that will be mandatory for PDF/UA.
UA For Universal Accessibility
To make the document accessible for the visually impaired, a PDF file should contain a logical reading order, images should be given alternate descriptions, and so on. All of these requirements will be bundled in the soon to be published ISO/AWI 14289.
The mission of PDF/UA is to develop technical and other standards for the authoring, remediation, and validation of PDF content to ensure accessibility for people who use assistive technology, such as screen readers.
This is not meant to be a techniques (how to) specification, but rather a set of guidelines for creating accessible PDF. The components and their structure are highly dependent upon which objects (graphics, text, multimedia, form fields) are to be present in the PDF file. The specification will describe such components and the conditions governing their inclusion in a PDF file in order to be considered accessible for a particular document type.
AIIM, PDF/UA, Universal Accessibility Committee Scope
The mechanism of tagged PDF offers a number of techniques for different aspects of PDF accessibility. We’ll take a look at some of these techniques in section 15.2.2. For instance, you can add extra tags that make it easier to understand a text that’s read out loud by the speech software that’s integrated into Adobe Reader.
FAQ
Can I use iText to convert a plain PDF document to PDF/X, PDF/A, ...? This is not possible out of the box for several reasons: external resources are needed (for instance, fonts need to be embedded), iText doesn’t have the “intelligence” to add tags (for PDF/A level A, you need to add structure information that isn’t there), iText doesn’t convert RGB colors into CMYK, and so on. There are commercial tools that can help you to turn a plain PDF into a PDF/X, PDF/A,... document, but these tools usually need human input to make decisions.
We’ve talked about different ISO specifications for PDF, but there are plenty of other flavors of PDF files.
Other Types of PDF
This is a nonexhaustive list of PDF and PDF-related types of documents you can encounter:
- Tagged PDF— As explained when we talked about PDF/A and PDF/UA, you can add extra structure to a PDF file that allows a PDF consumer to “understand” the content.
- Linearized PDF— A linearized PDF file is organized in a special way to enable efficient incremental access, thus enhancing the viewing performance. Its primary goal is to display the first page as quickly as possible without the need to read all of the rest of the file or to read the cross-reference table that normally is at the end of the file. This enhances the experience when viewing a PDF file over a streaming communications channel such as the internet. Linearized PDF is sometimes referred to as PDF for “fast web view.” When data for a page is delivered over a slow channel, you’d like to have the page content displayed incrementally as it arrives. With the essential cross-reference table at the end of the file, this is not possible unless the file is linearized. Linearization can only be done after the PDF file is complete and after all resources are known. iText can read linearized PDFs, but it can’t create a linearized PDF, nor can you linearize an existing PDF using iText.
- PDF/H— PDF for the healthcare providers and consumers. PDF/H is described in a “Best Practices Guide.” It aims to provide a more secure electronic container for storing and transferring healthcare information, including documents, XML data, DICOM images and data, clinical notes, lab reports, electronic forms, scanned images, photographs, digital X-rays, and ECGs.
- XML Data Package (XDP)— When we discussed dynamic XFA forms, we had a PDF that was used as the container and an XML stream embedded in the PDF representing the content of the PDF. In an XDP file, it’s the other way around. An XDP file is an XML file that packages a PDF file (base64 encoded), along with XML form and template data. PDF and XDP are interchangeable representations of the same underlying electronic form. PDF offers advantages for large documents, when file size is important, or when forms contain images. XDP is interesting when forms have to fit in an XML workflow and data needs to be manipulated by software that isn’t PDF-aware. XDP files aren’t supported in iText.
There are other types of PDF in the works, such as PDF/VT (for the variable and transactional printing industry). Some specifications have emerged, and then disappeared, never to be heard about again; for example, Adobe Mars was another XML alternative for PDF by Adobe.
But that’s outside the scope of this book. Let’s return to the PDF and find out why Jim King sometimes calls it object-oriented PostScript.
13.2. Understanding the Carousel Object System
Although Carousel was only a code name for what later became Acrobat, the name is still used to refer to the way a PDF file is composed. In part 1 of this book, you worked with the high-level API of iText, creating a document using objects that implement the Element interface. On the lowest level, iText works with objects that are derived from the abstract class PdfObject. This was one of the first iText classes that was written, immediately followed by the basic PDF objects in the Carousel Object System.
13.2.1. Basic PDF objects
There are eight basic types of objects in PDF. They’re explained in sections 7.3.2 to 7.3.9 in ISO-32000-1. Table 13.2 lists these types as well as their corresponding objects in iText.
Table 13.2. Overview of the basic PDF objects
|
PDF object |
iText object |
Description |
|---|---|---|
| Boolean | PdfBoolean | This type is similar to the Boolean type in programming languages and can be true or false. |
| Numeric object | PdfNumber | There are two types of numeric objects: integer and real. You’ve used them frequently to define coordinates, font sizes, and so on. |
| String | PdfString | String objects can be written in two ways:
|
| Name | PdfName | A name object is an atomic symbol uniquely defined by a sequence of characters. You’ve been using names as keys for dictionaries, to define a destination on a page, and so on. You can easily recognize them in a PDF file because they’re all introduced with a forward slash: /. |
| Array | PdfArray | An array is a one-dimensional collection of objects, arranged sequentially between square brackets. You’ve used arrays to define the size of a page; for instance, [0 0 595 842]. |
| Dictionary | PdfDictionary | A dictionary is an associative table containing pairs of objects known as dictionary entries. The key is always a name; the value can be (a reference to) any other object. The collection of pairs is enclosed by double angle brackets: << and >>. |
| Stream | PdfStream | Like a string object, a stream is a sequence of bytes. The main difference is that a PDF consumer reads a string entirely, whereas a stream is best read incrementally. Strings are generally used for small pieces of data; streams are used for large amounts of data. Each stream consists of a dictionary followed by zero or more bytes bracketed between the keywords stream (followed by newline) and endstream. |
| Null object | PdfNull | This type is similar to the null object in programming languages. Setting the value of a dictionary to null is equivalent to omitting the entry. |
You’ve used subclasses of these objects frequently in previous chapters:
- PdfAction, PdfFormField, and PdfOutline are only a few of the many subclasses of the PdfDictionary class.
- PdfRectangle is a special type of PdfArray because it’s a sequence of four values: [llx, lly, urx, ury].
- PdfDate extends PdfString because a date is a special type of string.
These objects are called direct when they’re used as shown in the following code snippet:
<<
/CreationDate(D:20100219095234+01'00')
/Producer(iText 5.0.2 (c) 1T3XT BVBA)
/ModDate(D:20100219095234+01'00')
>>
This is a dictionary with three entries. The key of each entry is a name; in this case the value of each entry is a string.
An object can also be labeled as an indirect object:
5 0 obj
<<
/Type/Catalog
/Pages 3 0 R
>>
endobj
Using the keywords obj and endobj, the object is given a unique object identifier by which other objects can refer to it. The value of the /Pages entry is such a reference: 3 0 R is an indirect reference to the indirect object with number 3.
Note
A stream object may never be used as a direct object. For example, if an entry in a dictionary is a stream, the value always has to be an indirect reference to an indirect object containing a stream. The stream dictionary always has to be a direct object. This dictionary contains information about the stream, such as its length in bytes and the filter that was used to compress the stream.
When you look inside a PDF file, you’ll find out that a large part of the PDF consists of a series of indirect objects.
13.2.2. The PDF file structure
Figure 13.2 shows two PDF files opened in Notepad++. Extra lines were added to identify the different parts.
In general, a PDF has four parts:
- The header— Discussed in section 1.3.3. It specifies the PDF version (which can be overruled in the Catalog dictionary) and contains a comment section that ensures that the file’s content is treated as binary content.
- The body— Contains a sequence of indirect objects that make up the document: pages, outlines, annotations, and so on.
- The cross-reference table— Contains information that allows random access to the indirect objects in the body.
- The trailer— Gives the location of the cross-reference table and of certain special objects in the body of the file.
You can see these four parts in the PDF in the background of figure 13.2. The PDF in the foreground is slightly different. That PDF is fully compressed (see section 12.2.1). The trailer is shorter. The cross-reference table isn’t missing, but it’s compressed in the object with number 8. Object 5 is a so-called object stream, in which a sequence of indirect objects may be stored as an alternative to their being stored at the outermost file level. The purpose of such an object stream is to allow objects other than streams to be stored more compactly by using the facilities provided by stream compression filters.
Figure 13.2. Hello World PDFs opened in Notepad++

It’s also possible to create a PDF in append mode. In this case, the four parts of the original file are kept intact, and an extra body, cross-reference table, and trailer are added. There are different reasons why you might choose to work in append mode:
- To avoid signatures being invalidated when adding multiple signatures (see section 12.4.3)
- To preserve the usage rights when filling out Reader-enabled forms (see section 8.7)
- To make it possible to restore previous revisions of a document (see listings 13.4 and 13.5)
There will also be more than one body, xref, and trailer when you open a linearized PDF in a text editor. Linearized PDF files have the first page’s cross-reference table at the beginning of the file. This way, a PDF viewer has all the necessary information to show the first page, even before the content of the second page is downloaded. Page two can be shown before page three is downloaded, and so on. Linearized PDFs are the exception to the rule. In all other cases, a PDF viewer has to start reading a PDF file at the end.
Examining the Content of a PDF File
Let’s look at a simple PDF file that isn’t fully compressed and that isn’t linearized.
Listing 13.3. hello.pdf

Listing 13.3 shows the contents of the hello.pdf file. You created this file in listing 1.1 of chapter 1. Note that the file has been slightly reorganized to improve its readability.
You need to start reading this file at the end. The last line of each PDF file should contain the end-of-file marker, %EOF. The two preceding lines contain the keyword startxref and the byte offset of the cross-reference table. That’s the position of the word xref counted from the start of the file.
The Trailer
The trailer begins with the keyword trailer, followed by the trailer dictionary. In listing 13.3, the first entry of this dictionary is a file identifier. The /Size entry shows the total number of entries in the file’s cross-reference table. There are two references to special dictionaries: the /Info key to the info dictionary and the /Root key to the catalog dictionary. The info dictionary contains the metadata discussed in section 12.1.1; we’ll take a closer look at the catalog in section 13.3.
Note
For fully compressed PDF files, startxref is followed by the byte offset of the cross-reference stream. In the compressed file shown in figure 13.2, the entries of the trailer dictionary were moved to the /XRef dictionary in the cross-reference stream.
Other possible entries in the trailer dictionary are the /Encrypt key, which is required if the document is encrypted, and the /Prev key, which is present only if the file has more than one cross-reference section.
This listing creates a PDF file with two cross-reference tables, reusing the hello.pdf file created in listing 1.1.
Listing 13.4. AppendMode.java
PdfReader reader = new PdfReader(src);
PdfStamper stamper =
new PdfStamper(reader, new FileOutputStream(dest), '�', true);
PdfContentByte cb = stamper.getUnderContent(1);
cb.beginText();
cb.setFontAndSize(BaseFont.createFont(), 12);
cb.showTextAligned(Element.ALIGN_LEFT, "Hello People!", 36, 770, 0);
cb.endText();
stamper.close();
At first sight, this looks like a typical PdfStamper example from part 2 of this book. The only difference is that you use extra parameters to create the stamper object. The binary null ('/0') ensures that the PDF version of the original PDF file won’t be changed. The boolean value indicates whether the original file should be appended (true) or not (false). This example tells iText to preserve the original file; the extra content is added after the end-of-file marker of the original file.
When you open the resulting file in a text editor, you’ll see the exact same content as shown in listing 13.3, followed by the content of this listing.
Listing 13.5. appended.pdf

You’ll recognize the indirect objects in the body. They can occur in any order; for instance, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() in listing 13.3, and
in listing 13.3, and ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() in listing 13.5. An application reading the PDF (for instance, using the PdfReader class), can find the different objects thanks to the cross-reference table.
in listing 13.5. An application reading the PDF (for instance, using the PdfReader class), can find the different objects thanks to the cross-reference table.
The Cross-Reference Table
The cross-reference table stores the information required to locate every indirect object in the body.
For reasons of performance, a PDF consumer doesn’t read the entire file. Imagine a document with 10,000 pages. If you only need to see the last page, a PDF viewer doesn’t have to know what’s inside the 9999 previous pages. It can use the cross reference to find the resources for the requested page in no time.
The cross-reference table contains two types of lines:
- Lines with two numbers— For example, 6 3 in listing 13.5 means the next line is about object 6 in a series of three consecutive objects: 6, 7, and 8.
- Lines with exactly 20 bytes— A 10-digit number represents the byte offset; a 5-digit number indicates the generation of the object. If these numbers are followed by the keyword n, the object is in use. Otherwise, the keyword f is present, meaning the object is free. These three parts are separated by a space character and end with a 2-byte end-of-line sequence.
The first entry in the xref table is always free and has a generation number of 65,535. Except for this 0 object, all objects in the cross-reference table have a generation number 0. In theory, the generation number of objects 3, 4, and 6 in listing 13.5 should have been 1; these objects replace the objects with the same number in listing 13.3. In practice, the use of generation numbers has been abandoned. It was one of the items that was eligible for removal when writing ISO-32000-1, but eventually the concept remained part of the specification, although not many products implement it.
Now pretend that you’re a PDF viewer; how do you read a PDF file?
13.2.3. Climbing up the object tree
You need to start at the end to find the offset of the cross-reference tree. The first object you need is the root object, aka the catalog. The trailer dictionary tells you that you need object 5:
5 0 obj
<<
/Type/Catalog
/Pages 3 0 R
>>
endobj
The catalog contains a reference to a pages dictionary. This is the root of the page tree; see the following indirect object:
3 0 obj
<<
/Count 1
/Type/Pages
/Kids[4 0 R]
>>
endobj
Such a dictionary can refer to branches—other /Pages dictionaries—and leaves—/Page dictionaries. This is a simple example containing only one page (/Count 1).
The /Kids array only has one value, a reference to object 4:
4 0 obj
<<
/Type/Page
/Contents[8 0 R 2 0 R]
/Parent 3 0 R
/Resources<<
/ProcSet [/PDF /Text /ImageB /ImageC /ImageI]
/Font<</F1 1 0 R/Xi0 7 0 R>>
<<
/MediaBox[0 0 595 842]
>>
endobj
This page has references to the original content, the stream in indirect object ![]() in listing 13.3, and the new content added with listing 13.4, object
in listing 13.3, and the new content added with listing 13.4, object ![]() . Each page also has a back-reference to its parent, in this case object
. Each page also has a back-reference to its parent, in this case object ![]() in listing 13.3. The /Resources dictionary tells you which resources are needed to render the page. In this case, you’ll find references to font objects,
but in more complex examples you’ll find references to form and image XObjects. If a page has annotations, there will also
be an /Annots entry in the page dictionary. The size of the page is defined by the /MediaBox rectangle (there’s no /CropBox in this example).
in listing 13.3. The /Resources dictionary tells you which resources are needed to render the page. In this case, you’ll find references to font objects,
but in more complex examples you’ll find references to form and image XObjects. If a page has annotations, there will also
be an /Annots entry in the page dictionary. The size of the page is defined by the /MediaBox rectangle (there’s no /CropBox in this example).
A PDF viewer has no problem finding, using, and reusing the different objects that compose a page. Although you’ve pretended to be a PDF viewer, you’re not. In the past, I’ve “climbed the object tree” of many PDF files looking for bugs in the PDF, scrolling up and down in a text editor. This may be easy for a simple file, as shown in listings 13.3 and 13.5, but it’s far from easy in larger files, especially if they contain more than one trailer or if objects are compressed in a stream. That’s why I wrote a tool named RUPS. Rups is a Dutch word meaning caterpillar. It’s also an acronym for Reading and Updating PDF Syntax. It’s not possible to update the syntax of a PDF document yet, but you can already use RUPS to browse through the internal structure like a caterpillar.
Figure 13.3 shows the ebook version of the first edition of iText in Action opened in RUPS.
Figure 13.3. The iText in Action, first edition ebook opened in RUPS

In the left panel, you can see the objects that make up the PDF file in a tree. In this figure, I started with the catalog dictionary, opened the /Pages entry (object 31260), went into the /Kids array, and selected indirect object 1325 which is in turn a /Pages dictionary. I went into that /Kids array and selected object 1253. This is page 30 of the PDF, labeled page 1 (the first 29 pages are numbered i, ii, iii, iv, and so on). To see what’s inside that page, I opened the /Contents entry of the page dictionary. I clicked the word Stream, which allows me to consult the stream dictionary in the bottom-left panel. The actual stream is shown in the bottom-right panel.
That’s one way to find page 30. A simpler way is to select page 30 in the Pages panel on the right. The tree will open automatically, showing the /Page dictionary of the selected page. The right pane also contains panels that allow you to jump to the objects that form the outline tree, an AcroForm, or an XFA form, and there’s also a complete overview of the cross-reference table.
This tool is under development; the GUI may change, and more functionality may be added in the near future, but I’m already using it extensively when people post questions about “PDFs that don’t work.” If you know the PDF specification, you can use RUPS to find out what’s wrong with a broken PDF.
In the next section, we’ll dig into ISO-32000-1 to find out more about the entries in the catalog dictionary that deal with viewer preferences, pages, destinations, and AcroForms.
13.3. Exploring the root of a PDF file
Table 28 in ISO-32000-1 lists the possible entries in the catalog dictionary. Some of these entries should already look familiar because we’ve discussed them before:
- Version and Extensions— As explained in section 1.3.3, the PDF version can be found in the header of a PDF file, but this version number can be overruled if the /Version key is present in the catalog. As shown in table 13.1, you can also specify which extensions from which company are used. The version is set using the method PdfWriter.setPdfVersion(); the extension can be defined using the PdfDeveloperExtension class, and it can be added to the PDF with PdfWriter.addDeveloperExtension().
- OpenAction and AA— In section 7.1.4, you added actions triggered by events to a PDF: an open action and additional actions. If the document has an open action, you’ll find an array specifying a destination or an action dictionary in the /OpenAction entry. The /AA entry can contain a dictionary with keys referring to events such as PdfWriter.WILL_PRINT or PdfWriter.DOCUMENT_CLOSE. If you look at the source code of PdfWriter, you’ll see that these constants are PdfName objects.
- Metadata— This refers to an XMP stream containing metadata about the complete document; see section 12.1.2. Note that a stream always has to be added as an indirect object, and that an XMP stream can never be compressed or encrypted.
- OutputIntents— Listing 13.2 defines an output intent. The catalog contains an array of dictionaries that specify the color characteristics of output devices on which the document might be rendered.
We won’t go into further detail as far as these entries are concerned, but we’ll select some other entries for a closer look.
13.3.1. Page layout, page mode, and viewer preferences
If you open a document in Adobe Reader, and no viewer preferences are specified inside the document, the Reader shows the document using default settings for the zoom factor, the visibility of toolbars, and so on. The panes or panels to the left, showing bookmarks, for example, are closed by default. You can change this default behavior by setting three entries in the catalog dictionary: /PageLayout, /PageMode, and / ViewerPreferences. You can do this using the setViewerPreferences() and addViewerPreference() convenience methods, which are present in PdfWriter as well as in PdfStamper. The setViewerPreferences() method expects an int value that’s a combination of the values for the page layout (table 13.3) and the page mode (table 13.4).
Table 13.3. Page layout values
|
Value |
Description |
|---|---|
| PageLayoutSinglePage | Displays one page at a time (this is the default). |
| PageLayoutOneColumn | Displays the pages in one column. |
| PageLayoutTwoColumnLeft | Displays the pages in two columns, with odd-numbered pages on the left. |
| PageLayoutTwoColumnRight | Displays the pages in two columns, with odd-numbered pages on the right. |
| PageLayoutTwoPageLeft | Displays the pages two at a time, with odd-numbered pages on the left. |
| PageLayoutTwoPageRight | Displays the pages two at a time, with odd-numbered pages on the right. |
Table 13.4. Page mode values
|
Value |
Description |
|---|---|
| PageModeUseNone | None of the tabs on the left are selected (this is the default). |
| PageModeUseOutlines | The document outline is visible (bookmarks). |
| PageModeUseThumbs | Images corresponding with the page are visible. |
| PageModeFullScreen | Full-screen mode; no menu bar, window controls, or any other windows are visible. |
| PageModeUseOC | The optional content group panel is visible (since PDF 1.5). |
| PageModeUseAttachments | The attachments panel is visible (since PDF 1.6). |
Page Layout
With the values in table 13.3, you can specify the page layout to be used when a document is opened.
Figure 13.4 shows documents that are opened using (from left to right) PageLayoutTwoColumnLeft, PageLayoutTwoColumnRight, and PageLayoutOneColumn. You can change the page layout by choosing View > Page Display. Note that features described in the PDF reference are often referred to by another name in end-user products. In Acrobat terminology, you have the choice of displaying Single Page, Single Page Continuous, Two-Up, and Two-Up Continuous.
Figure 13.4. Page layout with columns

The version number is set to PDF 1.5 in listing 13.6, because that’s when the values /TwoPageLeft and /TwoPageRight were introduced.
Listing 13.6. PageLayoutExample.java
PdfWriter writer
= PdfWriter.getInstance(document, new FileOutputStream(filename));
writer.setPdfVersion(PdfWriter.VERSION_1_5);
writer.setViewerPreferences(viewerpreference);
With page layout preferences, you define how the pages are organized in the document window. With page mode preferences, you can define how the document opens in Adobe Reader.
Page Mode
Table 13.4 lists page mode preferences. This gives you an idea of the different panels available in Adobe Reader.
Typically, these page modes are set to stress the fact that the document has bookmarks, optional content, and so on. We’ll discuss optional content in chapter 15 and attachments in chapter 16.
With page layout and page mode, you’re supposed to choose one option from each list. It doesn’t make sense to choose two different page layout or page mode values, but you can always combine a page mode with a page layout option. For instance,
PdfWriter.PageLayoutTwoColumnRight | PdfWriter.PageModeUseThumbs
If you choose a full-screen mode, you can add another option related to the panel to the left. This preference specifies how to display the document on exiting full-screen mode; see table 13.5.
Table 13.5. Page mode values on exiting full-screen mode
|
Value |
Description |
|---|---|
| NonFullScreenPageModeUseNone | None of the tabs at the left are visible. |
| NonFullScreenPageModeUseOutlines | The document outline is visible. |
| NonFullScreenPageModeUseThumbs | Thumbnail images corresponding with the pages are visible. |
| NonFullScreenPageModeUseOC | The optional content group panel is visible. |
These options only make sense if the page mode is full screen. For instance,
PdfWriter.PageModeFullScreen | PdfWriter.NonFullScreenPageModeUseOutlines
Note that you can exit full-screen mode using the Escape key.
The value that’s set when you choose one of these NonFullScreenPageMode options can be found as an entry in the /ViewerPreferences dictionary.
Viewer Preferences
In the View menu of Adobe Reader, you can select toolbar items that must be shown or hidden. You can control the initial state of some of these items by setting the viewer preferences listed in table 13.6.
Table 13.6. Values for the viewer preferences
|
Description |
|
|---|---|
| HideToolbar | Hides the toolbar when the document is opened. |
| HideMenubar | Hides the menu bar when the document is opened. |
| HideWindowUI | Hides UI elements in the document’s window (such as scrollbars and navigation controls), leaving only the document’s contents displayed. |
| FitWindow | Resizes the document’s window to fit the size of the first displayed page. |
| CenterWindow | Puts the document’s window in the center of the screen. |
| DisplayDocTitle | Displays the title that was added in the metadata in the top bar (otherwise the filename is displayed). |
With the following preference values, you can determine the predominant order of the pages.
- DirectionL2R— Left to right (the default).
- DirectionR2L— Right to left, including vertical writing systems such as Chinese, Japanese, and Korean.
This preference also has an effect on the way pages are shown when displayed side by side.
FAQ
How can I show the title of the PDF in my browser window? How can I hide the location bar of my browser? We’re talking about viewer preferences, not about browser preferences. The Reader plug-in isn’t able to control the settings of the browser, unless you embed the PDF as an object in an HTML page and use JavaScript as described in section 9.3.
These viewer preferences can also be set using the setViewerPreferences() method. For example,
writer.setViewerPreferences(PdfWriter.FitWindow | PdfWriter.HideToolbar);
You can also add the entries of the viewer preferences dictionary using the addViewerPreference() method, like this:
writer.addViewerPreference(PdfName.FITWINDOW, PdfBoolean.TRUE);
writer.addViewerPreference(PdfName.HIDETOOLBAR, PdfBoolean.TRUE);
This method can also be used with the keys shown in table 13.7 and one of the page boundaries discussed in section 5.3 as the value: PdfName.MEDIABOX, PdfName.CROPBOX, PdfName.BLEEDBOX, PdfName.TRIMBOX, or PdfName.ARTBOX.
Table 13.7. More viewer preferences
|
Description |
|
|---|---|
| PdfName.VIEWAREA | Defines the area of the pages that will be displayed when viewing the document on the screen. |
| PdfName.VIEWCLIP | Clips the contents of the pages when viewing the document on the screen. |
| PdfName.PRINTAREA | Defines the area of the pages that will be rendered when printing the document. |
| PdfName.PRINTCLIP | Clips the contents of the pages when printing the document. |
The viewer preferences also include a number of printing preferences.
Printing Preferences
When an end user chooses to print a document, a Print dialog box is displayed, in which the page range, the number of copies, and so on, can be set. You can help the end user by predefining values for some of the keys listed in table 13.8.
Table 13.8. Keys and values of printing preferences
|
Key |
Possible values |
|---|---|
| PdfName.PRINTSCALING | Valid values are PdfName.NONE, which indicates no page scaling, and PdfName.APPDEFAULT, which indicates the conforming Reader’s default print scaling. |
| PdfName.DUPLEX | The value can be PdfName.SIMPLEX (print single-sided), PdfName.DUPLEXFLIPSHORTEDGE (duplex printing, flip on the short edge of the sheet), PdfName.DUPLEXFLIPLONG-EDGE (duplex printing, flip on the long edge of the sheet). |
| PdfName.PICKTRAYBYPDFSIZE | Expects a PdfBoolean. If set to PDFTRUE, the check box in the Print dialog box associated with input paper tray will be checked. |
| PdfName.PRINTPAGERANGE | Expects a PdfArray containing an even number of integers to be interpreted in pairs, with each pair specifying the first and last pages in a subrange of pages to be printed. The first page of the PDF file is denoted by 1. |
| PdfName.NUMCOPIES | Expects a PdfNumber. Supported values are the integers 2 through 5. Values outside this range are ignored. |
Figure 13.5 shows a Print dialog box with some values that were set using viewer preferences.
Figure 13.5. Print dialog box with default values set using viewer preferences

Listing 13.7 shows how it was done.
Listing 13.7. PrintPreferencesExample.java
PdfWriter writer
= PdfWriter.getInstance(document, new FileOutputStream(filename));
writer.setPdfVersion(PdfWriter.VERSION_1_5);
writer.addViewerPreference(PdfName.PRINTSCALING, PdfName.NONE);
writer.addViewerPreference(PdfName.NUMCOPIES, new PdfNumber(3));
writer.addViewerPreference(PdfName.PICKTRAYBYPDFSIZE, PdfBoolean.PDFTRUE);
Not every viewer supports all these viewer preferences. ISO-32000-1 warns that most viewers disregard /ViewArea, /ViewClip, /PrintArea, /PrintClip, and that /PickTrayByPDFSize only works on operating systems that have the ability to pick the input tray by size. You also can’t force an end user to use these preferences: they can always change the page layout, the page mode, the properties of the viewer, and the printer settings.
FAQ
Why are the measurements not correct when I print a PDF? A lot of printers have margin limitations; they can’t print anything close to the borders of the page. The amount of space that’s left blank varies from printer to printer. If you look at figure 13.5, you’ll see that there’s a property named Page Scaling. Possible values for this property are None, Fit to Printable Area, Shrink to Printable Area, Multiple Pages per Sheet, and Booklet Printing. You need to set the page scaling to none if you don’t want the measurements to be scaled down.
This concludes our overview of the viewer preferences that can be set for a PDF document. Let’s continue with the catalog entries concerning pages.
13.3.2. Pages and page labels
The value of the /Pages entry in the catalog dictionary refers to the root of the page tree. ISO-32000-1 explains how pages are organized inside a PDF document:
The pages of a document are accessed through a structure known as the page tree, which defines the ordering of pages in the document. Using the tree structure, [PDF] readers using only limited memory, can quickly open a document containing thousands of pages. The tree contains nodes of two types—intermediate nodes, called page tree nodes, and leaf nodes, called page objects—whose form is described in the subsequent sub-clauses... The simplest structure can consist of a single page tree node that references all of the document’s page objects directly. However, to optimize application performance, a [PDF] writer can construct trees of a particular form, known as balanced trees.
ISO-32000-1 section 7.7.3.1
In section 5.2.4, you learned that iText automatically creates a balanced tree, unless you use the setLinearPageMode() method. Linear page mode was necessary if you wanted to be able to reorganize the order of the pages.
Manipulating Page Dictionaries
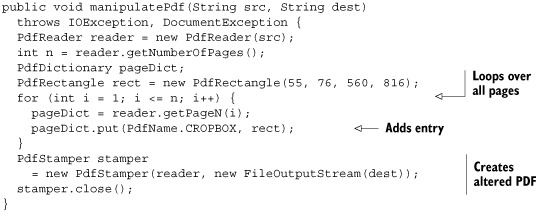
If you want to inspect the resources of a specific page, you don’t have to walk through the page tree; iText can do this for you if you use the method getPageN(). The next listing shows how you can get the page dictionary to change the page boundaries.
Listing 13.8. CropPages.java
Listing 13.8 demonstrates a technique that’s very powerful. In previous examples, you’ve created PdfReader instances to retrieve properties from PDF files. Now you also change some of the objects in the PDF. In this case, you add an extra entry to the page dictionary of every page. Once you’ve applied all the changes, you create a new, altered PDF document using PdfStamper. This is different from what you did in part 2; you’re manipulating a PDF file at the lowest level.
The next listing is similar to listing 13.8. Instead of adding an entry, you change the /Rotate entry, adding 90 degrees to the original value.
Listing 13.9. RotatePages.java
public void manipulatePdf(String src, String dest)
throws IOException, DocumentException {
PdfReader reader = new PdfReader(MovieTemplates.RESULT);
int n = reader.getNumberOfPages();
int rot;
PdfDictionary pageDict;
for (int i = 1; i <= n; i++) {
rot = reader.getPageRotation(i);
pageDict = reader.getPageN(i);
pageDict.put(PdfName.ROTATE, new PdfNumber(rot + 90));
}
PdfStamper stamper
= new PdfStamper(reader, new FileOutputStream(RESULT));
stamper.close();
}
Table 30 in ISO-32000-1 lists all the possible entries in the page dictionary. For instance, you can find an array referring to all the annotations that are present on the page (/Annots).
Removing Launch Actions
I was once asked to write code that removed every launch action. Launch actions are triggered from an annotation on a page, but instead of looping over all the pages, I wrote a loop over all the objects in the PDF file, looking for action dictionaries. Whenever a launch action was encountered, I replaced it with a JavaScript action.
Listing 13.10. RemoveLaunchActions.java

Observe that you can ask the reader object for an indirect object with the getPdfObject() method, passing the number of the object as a parameter ![]() . This code is used on a mail server that needs to remove possible security hazards from attachments.
. This code is used on a mail server that needs to remove possible security hazards from attachments.
There are no references to page numbers in the page dictionary. Every page is self-contained and doesn’t care about the other pages in the page tree. The page number is determined by the order of the page dictionaries in the page tree. When walking through the page tree, the first page dictionary that’s encountered is the dictionary of page 1, the second of page 2, and so on. If you want to create page numbers for “human consumption”—for instance, i, ii, iii for pages 1 to 3, followed by 1, 2, 3 for pages 4 to 6—you can define page labels.
Adding Page Labels
With the /PageLabels entry in the catalog, you can define the page labeling for the document. You can define page label dictionaries for the page indices of your choice. Each page index will denote the first page in a labeling range to which the specified page label dictionary applies.
Figure 13.6 shows a PDF opened on page 3 of 10, but the page label says it’s page 1, because the first two pages in the page tree are labeled A and B. Starting with page 6 (labeled page 4), the page numbers get a prefix.
Figure 13.6. Page numbers versus page labels

This listing shows how shows how the PDF in figure 13.6 was created.
Listing 13.11. PageLabelExample.java
PdfPageLabels labels = new PdfPageLabels();
labels.addPageLabel(1, PdfPageLabels.UPPERCASE_LETTERS);
labels.addPageLabel(3, PdfPageLabels.DECIMAL_ARABIC_NUMERALS);
labels.addPageLabel(6,
PdfPageLabels.DECIMAL_ARABIC_NUMERALS, "Movies-", 4);
writer.setPageLabels(labels);
This example uses two of the six possible numbering types for the page labels. The numbering types are listed in table 13.9.
Table 13.9. Page label numbering types
|
Type |
Description |
|---|---|
| DECIMAL_ARABIC_NUMERALS | Decimal Arabic numerals |
| UPPERCASE_ROMAN_NUMERALS | Uppercase Roman numerals |
| LOWERCASE_ROMAN_NUMERALS | Lowercase Roman numerals |
| UPPERCASE_LETTERS | Uppercase letters: A to Z for the first 26 pages, AA to ZZ for the next 26, and so on |
| LOWERCASE_LETTERS | Lowercase letters: a to z for the first 26 pages, aa to zz for the next 26 and so on |
| EMPTY | No page numbers |
There are different addPageLabel() methods in the PdfPageLabels class. They all take a page number as the first and a numbering style as the second parameter. Changing the numbering style resets the page number to 1.
A method with three parameters can be used to add a String that serves as a prefix. This method can also be used in combination with the EMPTY numbering style if you want to create text-only page labels.
The method with four parameters lets you define the first logical page number. In listing 13.11, when you start labeling pages with "Movies-", you can define that the first page labeled that way should be page 4.
Retrieving and Replacing Page Labels
The PdfPageLabels class also has a static method that allows you to get an array of Strings, containing the page labels of every page:
String[] labels = PdfPageLabels.getPageLabels(new PdfReader(src));
Now suppose you want to change the prefix Movies- shown in figure 13.6 to Film-, and you want to restart the page count, changing Movies-4 into Film-1. You can do this using the same technique you’ve used to crop and rotate pages.
Listing 13.12. PageLabelExample.java

Here you don’t have a method, such as getPageN(), that takes you straight to the dictionary you need. Instead, you climb up the object tree, jumping from object to object starting from the root.
Retrieving Objects From an Array or Dictionary
PdfDictionary has a get() method that returns the PdfObject that corresponds with a specific PdfName. This can be a PdfIndirectReference, in which case you have to look up the corresponding indirect object; or it can be a direct object in the form of a PdfObject that needs to be cast to the proper type. If you know in advance which type of object you’ll get, you can use one of the convenience methods listed in table 13.10 (as was done in listing 13.12).
Table 13.10. Convenience methods for getting specific objects
|
Method |
Return value |
|---|---|
| getAsBoolean() | A PdfBoolean or null |
| getAsNumber() | A PdfNumber or null |
| getAsString() | A PdfString or null |
| getAsName() | A PdfName or null |
| getAsArray() | A PdfArray or null |
| getAsDict() | A PdfDictionary or null |
| getAsStream() | A PdfStream or null |
These methods exist for the classes PdfArray, PdfDictionary, and PdfStream. If you don’t know which object to expect, you can use the getDirectObject() method. If the value in the array is referenced, the reference will be resolved. If you want to get the PdfIndirectReference object instead of the actual object, you need the getAsIndirectObject() method.
You need the PDF reference to understand what happens in listing 13.12—as will always be the case when you manipulate a PDF at the lowest level. Section 12.4.2 of ISO-32000-1 tells us that the value of the /PageLabels entry is a number tree: an array (/Nums) with ordered pairs of numbers and values. Each number corresponds with the index of a page for which a style was defined in listing 13.11. It’s important to note that page 1 has index 0; if you want to change the page label with prefix Movie- (starting on page 6), you have to look for the page label value corresponding with index 5. This value is a dictionary whose entries are explained in table 159 of ISO-32000-1. The key /St is used for the numeric portion for the first page label in the range. If you remove this entry, the default value will be used: 1. The /P key is used for the label prefix. You can replace it with Film-.
The functionality offered by iText is comprehensive, but once in a while you’re confronted with a requirement for which there is no high-level method. The examples in this chapter are inspired by some of the more exceptional requests that have been posted to the mailing list. In cases like this, you need to manipulate the PDF at the lowest level.
Let’s continue with another not so trivial assignment and explore another feature: how to add an extra object to an existing PDF file.
13.3.3. Outlines, destinations, and names
In section 7.1.1, you learned how to retrieve the named destinations from a document. In section 7.2, you did the same with bookmarks. In the next listing you read the /Outlines entry directly from the catalog dictionary. You can use the information retrieved from the bookmarks to create named destinations.
Listing 13.13. Bookmarks2NamedDestinations.java

You’ve already worked with a number tree for page labels; now you’ll work with a name tree: an array with ordered pairs of strings and values. In the addKids() method, you use the title of the outlines as the key and the destination of the outline, an array, as the value. You add the name tree to the document with the method addPdfObject(). An indirect object will be created, and you’ll receive a PdfIndirectReference object that refers to this new object. You replace the /Names entry in the catalog with a new one that has a /Dests item. This /Dests item has a /Names entry referring to the newly created indirect object.
Warning
If the catalog already has a /Names entry, the put() method will replace it, and you may break existing functionality. The examples in this chapter explain a mechanism; you shouldn’t copy and paste the code snippets and use them as definitive solutions.
Changing outlines into named destinations is one of the more exotic requirements I’ve encountered. A more common situation where you may need low-level access to a PDF involves forms.
13.3.4. AcroForms revisited
The catalog has two entries concerning forms: /AcroForm and /NeedsRendering. The value of /NeedsRendering is a flag (a boolean). If true, documents containing XFA forms will be regenerated when the document is first opened. You could check whether there’s an XFA form inside a PDF by looking for an XFA entry in the AcroForm dictionary, but you’ve used easier methods in section 8.6 to get the same result. In this section, we’ll have a closer look at some problems related to AcroForms that can be solved using low-level functionality.
Fixing a Broken Form
There’s a plethora of tools that are able to create PDF documents, but the quality of the PDF that’s produced isn’t always as good. We regularly get questions on the mailing list about forms created by a free UNIX tool. These forms can be filled out using Acrobat, but not with iText. After inspecting such a form, we discovered that the widget dictionaries of the form fields were present in the /Annots array of the page dictionary, but were missing from the /Fields array of the AcroForm. As a result, the widgets were rendered correctly on the page, but when seen from the perspective of the AcroFields object, the form was empty. Such forms are broken, and iText can’t fill them until they’re fixed. Let’s look at how to fix them.
The next bit of code makes the assumption that every annotation in each page is a widget annotation corresponding to one field. It loops over every page and puts the references to each annotation into the fields array.
Listing 13.14. FixBrokenForm.java

The annots object is an array, and this listing assumes that all the elements in this array are indirect references (instead of direct objects). You get these references with the getAsIndirectObject() method.
Although this code sample isn’t perfect, it has already helped many developers.
Inspecting Fields at a Low Level
In chapter 8, you used the AcroFields class to manipulate form fields in a PDF document. This class offers the most common functionality you’ll need, but sometimes you’ll need more. For instance, how could you find out whether a text field is a password field, or a multiline field?
In the next listing, you’ll get the fields as instances of the inner class AcroFields.Item. From this inner class, you’ll retrieve a dictionary that merges the field and the widget dictionary. You’ll inspect the field flags, /FF, to see if the PASSWORD or the MULTILINE bits are set.
Listing 13.15. InspectForm.java

If you use this code to inspect the form used in section 8.5.2, the following output is returned:
personal.loginname
personal.name
personal.reason -> multiline
personal.password -> password
You may wonder why the getMerged() method needs a parameter. In chapter 8, you learned that a field can be represented by different widget annotations. You can ask an Item object how many widgets are associated with the field by using the size() method. In the form you’ve inspected here, there was only one widget per field, and it had the index 0. You can get more info about a widget with index idx using the methods from table 13.11.
Table 13.11. AcroFields.Item methods
|
Method |
Description |
|---|---|
| getValue(idx) | Returns a dictionary where the /V entry is present. This entry holds the field value whose format varies depending on the field type. |
| getWidget(idx) | Returns one of the widget dictionaries of the field. |
| getWidgetRef(idx) | Returns the PdfIndirectReference for the widget. |
| getMerged(idx) | Retrieves the merged dictionary for the given instance. This PdfDictionary contains all the keys present in the parent fields, though they may have been overwritten (or modified) by children. |
| getPage(idx) | Retrieves the page number on which the widget with index idx is placed. |
| getTabOrder(idx) | Returns the tab index of the given field widget. |
You can use these methods to inspect the widget annotations of a field, and even to manipulate a field at the lowest level.
Adding Javascript to a Field
Imagine an IRS form asking a citizen if they are married. This could be done using a radio field named Married with possible values Yes and No. There could also be a Partner text box to which a name could be added. This text field should only be filled in if the value for Married is Yes.
Listing 13.16 shows how to add the setReadOnly() JavaScript method to the radio field button. The method is triggered when one of the buttons gets the focus. This method is written so that the content of the Partner field is blanked out and made read-only if Married is set to No. When changed back to Yes, the read-only status is set to false.
Listing 13.16. AddJavaScriptToForm.java

There’s more than one way to achieve this. This example uses the PdfReader.getPdfObject() method with a PdfIndirectReference to the widget as a parameter. You fetch the additional actions dictionary from the widget dictionary; if such a dictionary isn’t present, you create a new one. The JavaScript stream is added to stamper.getWriter() implicitly.
Replacing the URL of a Submit Button
You could have used a shortcut to get the widget dictionary in listing 13.16. You’ll use this shortcut in the next example to replace the submit URL of the Post button of an AcroForm.
Listing 13.17. ReplaceURL.java
PdfReader reader = new PdfReader(src);
AcroFields form = reader.getAcroFields();
AcroFields.Item item = form.getFieldItem("post");
PdfDictionary field = item.getMerged(0);
PdfDictionary action = field.getAsDict(PdfName.A);
PdfDictionary f = action.getAsDict(PdfName.F);
f.put(PdfName.F, new PdfString("http://itextpdf.com:8080/book/request"));
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream(dest));
stamper.close();
Almost every example in this chapter is what we call a hack. Each example solves a specific problem, but it probably won’t work for every PDF. Manipulating PDFs at the lowest level gives you a lot of power, but you can seriously damage a PDF file if you add, change, or remove objects directly. You should always remember the words of Spider-Man’s Uncle Ben: “With great power comes great responsibility.” It’s your responsibility to check ISO-32000-1 to see if your changes result in a valid PDF file.
You should also consult the ISO specification if you want to know more about the following entries of the root dictionary: /Threads, /URI, /Lang, /SpiderInfo, /PieceInfo, /Legal, /Requirements, and /Perms. But please read on if you want to know more about /OCProperties, /StructTreeRoot, /MarkInfo, or /Collection, because these will be discussed in the upcoming chapters.
13.4. Summary
We started this chapter with a short historical overview: why did the world need PDF, and how did PDF evolve from a de facto standard owned by a company to an ISO standard? We looked at different flavors of PDF, such as PDF/A and PDF/X. The history lesson was necessary to understand how and why the Carousel Object System was invented.
You opened up one of the PDF documents you created in chapter 1 and learned about the different objects that make a PDF file. You attempted to read this file the same way a PDF viewer would read it, interpreting the different parts in the file structure. You jumped from indirect object to indirect object in the body, following the path defined by indirect references. As you saw, you can do this for a small PDF file, but you need a tool such as iText RUPS as soon as you want to inspect the objects of a larger PDF document.
The examples in this book solved specific problems by manipulating PDF documents at the lowest level. These examples were taken from the collection of code snippets that accumulated in the “sandbox” directory on my computer. Most of these snippets were written in answer to a question on the mailing list, but I selected them in such a way that they explained the mechanisms that can be used to select, change, add, or remove objects when manipulating an existing PDF document.
One type of object was deliberately overlooked: PdfStream. When we studied the structure of the Hello World document, we didn’t look at the part marked as binary content, and we didn’t look at streams representing fonts and images. That’s what the next chapters are about.