
Chapter 15. Page content and structure
- Making content optional
- Working with marked content
- Parsing PDF files
The previous chapter was devoted entirely to page content; you learned how to add content the PDF way and the Java way. We’ll continue discussing content in this chapter. We’ll add operators and operands to make part of the content optional. We’ll use marked content to add custom parameters to graphical objects, to make the content accessible for the visually impaired, and to store the structure of the document. Finally, we’ll make a fair attempt at parsing a PDF document and extracting content from a page.
15.1. Making content visible or invisible
All the content you’ve added to a page so far was either visible or it was invisible, whether because it was clipped or because the rendering mode was set to invisible. Beginning with PDF 1.5, you can also add optional content: content that can be selectively viewed or hidden by document authors or consumers.
15.1.1. Optional content groups
Graphics and text that can be made visible or invisible dynamically are grouped in an optional content group (OCG). Content that belongs to a certain group is visible when the group is on, and invisible when the group is off. Figure 15.1 demonstrates this functionality.
Figure 15.1. Making content visible and invisible

The text, “Do you see me?” is added as normal content. The text, “Peek-a-Boo!!!” is added as optional content that’s visible in the upper window, but not in the lower window. In both windows, the Layers panel is opened. “Do you see me?” is the caption of a layer (which is another name for an OCG). By clicking the group’s check box in the Layers panel, end users can make the content visible or invisible.
The next listing shows how the “Do you see me?” layer was created using iText’s PdfLayer object, and how the “Peek-a-Boo!!!” text was made optional using the PdfContentByte methods beginLayer() and endLayer().
Listing 15.1. PeekABoo.java

Note that in this listing the viewer preferences are set so that the optional content panel is shown when the document is opened. The state of the layers can be specified with the setOn() method, which expects a Boolean value. If true, the layer will be visible (this is the default). If false, the layer will be hidden.
If you peek into the content stream of the resulting page, you’ll see this construct:
/OC /Pr1 BDC
1 0 0 1 50 766 Tm
(Peek-a-Boo!!!)Tj
EMC
The optional content is put between the marked-content operators BDC and EMC. This marked content is recognized as optional because of the /OC tag. The operand /Pr1 was created by iText.
You’ll find a reference to the OCG in the resources dictionary of the page:
/Properties<</Pr1 1 0 R>>
The indirect object 1 looks like this:
1 0 obj
<</Type/OCG/Name(Do you see me?)>>
endobj
The OCGs and their properties are listed in the catalog (see section 13.3):
<<
/Type/Catalog
/Pages 4 0 R
/OCProperties<<
/D<<
/Order[1 0 R]
/ListMode/VisiblePages
>>
/OCGs[1 0 R]
>>
/PageMode/UseOC
>>
The optional content of a group can reside anywhere in the document. It doesn’t have to be consecutive in drawing order or belong to the same content stream (or page).
The previous example was simple, with one layer and one sequence of optional content. Let’s see how to work with different layers that are organized in structures.
15.1.2. Adding structure to layers
Figure 15.2 shows different features of the PdfLayer object.
Figure 15.2. Different groups of optional content

We’ll start with the structure that is visible in the Layers tab. It shows a tree with branches: Nested Layers, Grouped Layers, and Radio Group.
Nested Layers
The nested layers in figure 15.2 are visible by default; if you click the eye icon next to Nested Layer 1, the words “nested layer 1” disappear from the page on the right. You can’t change the visibility of “nested layer 2” separately because it has been locked, but if you click the eye icon next to the Nested Layers parent layer, everything that is added to the parent layer is made invisible, as well as everything that is added to its children. This is how it’s done.
Listing 15.2. OptionalContentExample.java

The nested structure is defined by using the addChild() method. It’s not necessary to nest the beginLayer() and endLayer() sequences, but it isn’t forbidden either. Layers can be locked with the lockLayer() method. The visibility of a locked layer can’t be changed using the eye icon in the Layers panel.
Grouped layers are similar to nested layers.
Grouped Layers
If you look at the Layers panel, you’ll see that the Grouped Layers layer can’t be clicked. This layer was constructed with the createTitle() method.
Listing 15.3. OptionalContentExample.java

The parent of this group can’t be used as a parameter for the beginLayer() method. The PdfLayer object returned by createTitle() is a structural element and doesn’t represent an OCG.
Radio Group
This listing uses the same method to create a parent object for a radio group.
Listing 15.4. OptionalContentExample.java

If you open the PDF shown in figure 15.2 in Adobe Reader, clicking another option in the radio group makes “option 1” invisible. Depending on the layer you chose, “option 2” or “option 3” becomes visible.
The PDF shown in the screenshot also contains two sequences of optional content for which there’s no entry in the Layers panel. These layers are visible or invisible depending on the usage of the PDF file.
Visibility Depending on Usage
In listing 15.5, two PdfLayer objects are created, and setOnPanel(false) is used for both. An extra method determines the visibility: The method setPrint() was used to create a layer that will only be visible on screen; the content won’t be printed on paper. The method setZoom() ensures that the layer is only visible if the zoom factor is between 75% and 125% (in the screenshot, the zoom factor is 100%).
Listing 15.5. OptionalContentExample.java
PdfLayer not_printed = new PdfLayer("not printed", writer);
not_printed.setOnPanel(false);
not_printed.setPrint("Print", false);
cb.beginLayer(not_printed);
ColumnText.showTextAligned(cb, Element.ALIGN_CENTER,
new Phrase("PRINT THIS PAGE"), 300, 700, 90);
cb.endLayer();
PdfLayer zoom = new PdfLayer("Zoom 0.75-1.25", writer);
zoom.setOnPanel(false);
zoom.setZoom(0.75f, 1.25f);
cb.beginLayer(zoom);
ColumnText.showTextAligned(cb, Element.ALIGN_LEFT,
new Phrase("Only visible if the zoomfactor is between 75 and 125%"),
30, 530, 90);
cb.endLayer();
Table 15.1 lists the different methods that can be used to add entries to the usage dictionary of an OCG. This dictionary describes the nature of the content controlled by the OCG.
Table 15.1. PdfLayer methods for changing the usage dictionary
|
Method |
Parameters |
Description |
|---|---|---|
| setCreatorInfo | (creator, subtype) | Stores application-specific data associated with this OCG. The creator parameter is a String specifying the group; subtype defines the type of content, such as "Artwork" or "Technical". |
| setLanguage | (lang, preferred) | Specifies the language of the content controlled by this OCG. The lang parameter is a String defining the locale, such as "en-US". If you’ve specified a language, the layer that matches the system language is visible (ON), unless preferred is set to true. |
| setExport | (export) | Indicates the recommended state for content in this group when the document is saved by an application to a format that doesn’t support optional content. If export is true, the layer is visible (ON). |
| setZoom | (min, max) | Specifies a range of magnifications at which the content is best viewed. The parameters min and max are the minimum and maximum recommended zoom factors. Using a negative value for min sets the default to 0; for max a negative value corresponds with the largest possible magnification supported by the viewer. |
| setPrint | (subtype, printstate) | Specifies the state if the content in this group is to be printed. Possible values for subtype are "Print", "Trapped", "PrinterMarks", and "Watermark"; printstate is a boolean. |
| setView | (view) | Indicates that the group should be set to that state when the document is opened in a viewer application. If view is true, the layer is visible (ON). |
| setUser | (type, names) | Specifies one or more users for whom this OCG is primarily intended. Possible values for type are "Ind" (individual), "Ttl" (title), or "Org" (organization). The names parameter can be one or more String objects. |
| setPageElement | (pe) | Indicates that the OCG contains a pagination artifact. Possible values include "HF" (header or footer), "FG" (foreground image or graphic), "BG" (background image or graphic), or "L" (logo). |
The decision as to whether or not an object should be visible can depend on the state of a series of other layers that are grouped in an optional content membership.
15.1.3. Optional content membership
In the previous examples, you’ve added content to a single OCG. This content is visible if the status of the group is on and invisible when it’s off. Consider more complex visibility possibilities, with content not belonging directly to a specific layer, but where the visibility depends on the states of different layers.
Defining a Visibility Policy
Suppose you have three layers, one with the word “dog”, one with the word “tiger”, and one with the word “lion”. Next, define a membership with the word “cat” that is visible only if either of the words “tiger” or “lion” are visible, and a membership with the words “no cat” if none of these words are visible.
This can be achieved with this code.
Listing 15.6. LayerMembershipExample1.java

In this listing, you first create three normal PdfLayer objects. Then you create two PdfLayerMembership objects, cat and no_cat.
This example uses two out of four possible visibility policies:
- ALLON— Visible if all the entries are on.
- ANYON— Visible if any of the entries are on.
- ANYOFF— Visible if any of the entries are off.
- ALLOFF— Visible if all of the entries are off.
You didn’t explicitly define a visibility policy for the cat membership. It was set to ANYON, which is the default value.
Defining a Visibility Expression
Since PDF 1.6, visibility policies are still accepted, but preference is given to a visibility expression. This allows you to specify an arbitrary Boolean expression for computing the visibility from the states of OCGs. The layer memberships in the next listing are equivalent to those in listing 15.6. The end user will not notice any difference.
Listing 15.7. LayerMembershipExample2.java
PdfLayerMembership cat = new PdfLayerMembership(writer);
PdfVisibilityExpression ve1
= new PdfVisibilityExpression(PdfVisibilityExpression.OR);
ve1.add(tiger);
ve1.add(lion);
cat.setVisibilityExpression(ve1);
PdfLayerMembership no_cat = new PdfLayerMembership(writer);
PdfVisibilityExpression ve2
= new PdfVisibilityExpression(PdfVisibilityExpression.NOT);
ve2.add(ve1);
no_cat.setVisibilityExpression(ve2);
Using a PdfVisibilityExpression offers a more general way to define a layer membership. Possible values for the parameter when constructing a PdfVisibilityExpression are AND, OR, and NOT. You can add PdfLayer objects to a visibility expression, and you can nest PdfVisibilityExpression objects. If the value is NOT, you may only add one element. If it’s AND or OR, you can add more elements.
Another way to switch content on or off is by using actions.
15.1.4. Changing the state of a layer with an action
You used the PdfAction class in chapter 7 to jump to another location in a PDF file, to execute JavaScript, and so on. In this section, you’ll create actions to change the visibility of an OCG.
Figure 15.3 shows three questions about movies. The answers are also added to the document, but each answer is added to a separate OCG. They aren’t visible by default, so that you can test your own knowledge about movies and directors.
Figure 15.3. Changing visibility using actions

In this example, the layers are added to the Layers panel, so that you can switch the answers on or off, but the more questions and answers there are in your questionnaire, the less user-friendly this panel will be. It would be better to add clickable areas to the document that allow you to make one or more answers visible. This is illustrated in the next example.
Listing 15.8. OptionalContentActionExample.java
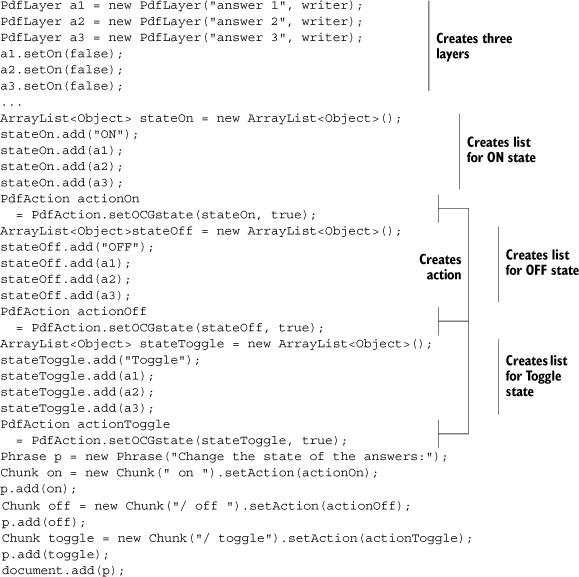
The setOCGState() static method returns a PdfAction object ![]() . The first parameter is an ArrayList, and the first element in this list defines the action: the layers that are added can be turned on ("ON"), turned off ("OFF"), or toggled ("Toggle"). The second parameter makes sense only if you’ve defined radio groups. If it’s false, the fact that a layer belongs to a radio group is ignored. If it’s true, turning on a layer that belongs to a radio group turns off the other layers in the radio group.
. The first parameter is an ArrayList, and the first element in this list defines the action: the layers that are added can be turned on ("ON"), turned off ("OFF"), or toggled ("Toggle"). The second parameter makes sense only if you’ve defined radio groups. If it’s false, the fact that a layer belongs to a radio group is ignored. If it’s true, turning on a layer that belongs to a radio group turns off the other layers in the radio group.
Up until now, you’ve marked content as optional in the content stream, using PdfContentByte methods. You can also mark specific objects as optional.
15.1.5. Optional content in XObjects and annotations
Three types of iText objects are often drawn in an OCG: Images, PdfTemplates, and PdfAnnotations. For convenience, these objects have a setLayer() method that can be used to define the OCG to which the object belongs.
Figure 15.4 shows a map of Foobar. People from all over the world will be coming to the Foobar Film Festival, and to make sure these people find their way to the movie theater, you’ll create a map of the city. You’ll add the street names in three languages—English, French, and Dutch—and put these street names in different layers, organized as a radio group, so that only one layer is visible at a time. You’ll also add more layers showing information about restaurants, movie theaters, and so on. End users can switch these layers on and off depending on what they’re looking for in the city of Foobar.
Figure 15.4. The interactive map of Foobar

This PDF is created from an SVG file, foobarcity.svg containing the map (lines and shapes), and three SVG files, foobarstreets.svg, foobarrues.svg, and foobarstraten.svg, containing the street names in English, French, and Dutch (text only). iText can’t interpret these files. You could try to write your own SVG handler (as was done in the first edition of this book), but it’s easier to use a library that already exists, such as Apache Batik. This listing creates the map without the optional content layers.
Listing 15.9. SvgToPdf.java

The listing could easily have been an example from the previous chapter, where you used the PdfGraphics2D functionality to write to a java.awt.Graphics2D object. The lines and shapes are drawn to a PdfTemplate, and so are the street names. The streets template is added on top of the map template.
In the next listing you’ll create three PdfTemplate objects for the street names. You’ll add these templates on top of each other but define an OCG for each of the templates, making sure that only one layer is visible at a time.
Listing 15.10. SvgLayers.java

The setLayer() method is often used for watermark images, such as for a layer that is only visible when a document is printed, or for specific form fields (widget annotations) that need to be made visible or invisible depending on the values of other fields.
This listing uses a method from table 15.1 to set the language of the street layers. For a watermark image, you’ll use the setPageElement() method with the parameter "BG". The interactive map of Foobar is meant as an inspiring example, showing that you can create really interesting interactive PDF files using the OCG functionality.
Optional content uses the marked-content operators BDC and EMC. In the next section, you’ll learn about more features involving marked content.
15.2. Working with marked content
Marked-content operators are used to identify a portion of a PDF content stream as an element of interest to a particular application or PDF plug-in extension. In this section, we’ll take a closer look at three situations in which marked content is important: adding custom data to objects, making a PDF accessible, and storing the structure of a document along with its content.
15.2.1. Object data
In the map of Foobar, you have icons of movie theaters, but you may want to add extra information, such as the theater name, address, and so on. Figure 15.5 shows different movie posters with the names of the directors added.
Figure 15.5. Using marked content for object data

The properties of each poster in figure 15.5 are shown in the Model Tree panel. This panel is opened if you activate the object data tool by selecting Tools > Analysis > Object Data Tool in the menu. You can check whether this tool is activated by looking at the Analysis toolbar; if it is, there will be an icon with a page, an information symbol, and a crosshair. If this option is selected, you can click a poster of a movie.
When a poster is clicked, the Model Tree panel will open. In this case, there are seven sets of object data, named director1 to director7, one for each director who has a poster in the PDF. In figure 15.5, one of the six posters of movies by Akira Kurosawa has been clicked on, so director2 is selected. You can see more information about this entry in the lower panel:
- Name: Kurosawa
- Given name: Akira
- Posters: 6
All the objects for which these properties are valid—six posters—are highlighted in the page with a red border around the poster.
The next bit of code creates the structure tree that makes this possible.
Listing 15.11. ObjectData.java

If you tell the PdfWriter to create a tagged PDF ![]() , the getStructureTreeRoot() method will create a /StructTreeRoot entry for the root dictionary of the document. The children of the top element contain attributes (/A) that are owned (/O) by user properties (/UserProperties). These properties are defined as an array of dictionaries with a name (/N) and a value (/V). Don’t forget to tell the writer that the structure contains elements that have user properties
, the getStructureTreeRoot() method will create a /StructTreeRoot entry for the root dictionary of the document. The children of the top element contain attributes (/A) that are owned (/O) by user properties (/UserProperties). These properties are defined as an array of dictionaries with a name (/N) and a value (/V). Don’t forget to tell the writer that the structure contains elements that have user properties ![]() ; otherwise the object data tool won’t be able to identify objects.
; otherwise the object data tool won’t be able to identify objects.
If you have a map containing Movie objects and director IDs, you can create the PDF shown in figure 15.5 using the next listing.
Listing 15.12. ObjectData.java (continued)

User properties are one type of attribute that can be added to a marked content sequence. You’ll find more in ISO-32000-1. In the next section, we’ll work with the optional entries that can be added for accessibility support.
15.2.2. Section 508 and accessibility
In the U.S., federal agencies are required to make their electronic and information technology accessible to people with disabilities. This is enforced by law: section 508, an amendment to the Rehabilitation Act of 1973.
Section 508 is about electronic information in general, so it also applies to PDF. We’ve briefly discussed PDF/UA (aka ISO/AWI 14289) in chapter 13. This standard is currently under development. It will be to PDF what the World Wide Web Consortium (W3C)’s Web Content Accessibility Guidelines (WCAG) are to web pages. The Web Accessibility Initiative (WAI) is an effort to improve the accessibility of the web for people with disabilities by defining principles, guidelines, success criteria, benefits, and examples that explain the requirements for making web-based information and applications accessible.
FAQ
Does iText support the creation of PDF documents that are compliant with section 508? You can use iText to create a document that passes all the criteria that are listed in section 508. It’s technically impossible, however, to provide a setPDFUAConformance() method that checks whether the PDF you’re creating is accessible. This is true for any PDF creator, not just for iText. Even a “pass” from Acrobat’s Accessibility Checker doesn’t verify compliance with section 508. Many of the accessibility requirements, such as alternate text, tooltips, and color use, will always require human validation.
PDF includes several facilities in support of accessibility. Documents can be made available for the visually impaired by using screen readers. In Adobe Reader, you can select View > Read out Loud, but you need marked content to enable proper vocalization. Consider the document shown in figure 15.6.
Figure 15.6. Content that can be read out loud

A screen reader doesn’t know that “Dr.” should be read as “Doctor,” nor that EWS is the abbreviation of the movie title Eyes Wide Shut. Viewers will render the poster of 2001: A Space Odyssey, but you should provide alternate text so that the screen reader knows this too. Also, you want Adobe Reader to say “Seven Samurai” instead of the Japanese title.
To achieve this, you’ll use a marked-content operator with /Span as the first operand, and a dictionary with the extra information as the second operand. You could add these elements as PdfStructureElement objects that are part of the structure tree, as was done in listing 15.11, but in this case you’ll add the marked content tag and dictionary directly to the content stream.
Expansion of Abbreviations and Acronyms
This demonstrates how to use the /E entry to expand abbreviations.
Listing 15.13. ReadOutLoud.java
cb.beginText();
cb.moveText(36, 788);
cb.setFontAndSize(bf, 12);
cb.setLeading(18);
cb.showText("These are some famous movies by Stanley Kubrick: ");
dict = new PdfDictionary();
dict.put(PdfName.E, new PdfString("Doctor"));
cb.beginMarkedContentSequence(new PdfName("Span"), dict, true);
cb.newlineShowText("Dr.");
cb.endMarkedContentSequence();
cb.showText(" Strangelove or: How I Learned to Stop Worrying and Love the Bomb.");
dict = new PdfDictionary();
dict.put(PdfName.E, new PdfString("Eyes Wide Shut."));
cb.beginMarkedContentSequence(new PdfName("Span"), dict, true);
cb.newlineShowText("EWS");
cb.endMarkedContentSequence();
cb.endText();
Instead of passing a PdfStructureElement, you now pass three parameters to the beginMarkedContentSequence() method: the name of the tag (/Span), the dictionary with the entries, and a parameter that specifies whether the dictionary has to be added inline (inside the content stream) or as a reference to an indirect object.
Alternate Descriptions and Language
If you know HTML, you know that the img tag has an attribute named alt. This attribute can be used to specify alternate text for the image, which can be used if the image is missing on the server, or if your browser doesn’t download images to save bandwidth, or to conform with accessibility standards. The first two reasons don’t apply for PDF, but to make your document compliant with PDF/UA and section 508, you have to use marked content with an /Alt entry to define alternate text for images, formulas, or other items that are part of the content and that do not translate naturally into text. This is done here.
Listing 15.14. ReadOutLoud.java
dict = new PdfDictionary();
dict.put(PdfName.LANG, new PdfString("en-us"));
dict.put(new PdfName("Alt"), new PdfString("2001: A Space Odyssey."));
cb.beginMarkedContentSequence(new PdfName("Span"), dict, true);
Image img = Image.getInstance(RESOURCE);
img.scaleToFit(1000, 100);
img.setAbsolutePosition(36, 640);
cb.addImage(img);
cb.endMarkedContentSequence();
Note that the listing also uses the /Lang entry to indicate that it’s using the English title.
Replacement Text
Just as alternate descriptions can be provided for images, replacement text can be specified for content that translates into text but that is represented in a nonstandard way: glyphs for ligatures or custom characters, inline graphics corresponding to dropped capitals or to letters in an illuminated manuscript, and so on. The next listing shows the title of the movie Seven Samurai in Japanese, but it uses the English title as /ActualText.
Listing 15.15. ReadOutLoud.java
cb.beginText();
cb.moveText(36, 620);
cb.setFontAndSize(bf, 12);
cb.showText("This is a movie by Akira Kurosawa: ");
dict = new PdfDictionary();
dict.put(PdfName.ACTUALTEXT, new PdfString("Seven Samurai."));
cb.beginMarkedContentSequence(new PdfName("Span"), dict, true);
cb.setFontAndSize(bf2, 12);
cb.showText("u4e03u4ebau306eu4f8d");
cb.endMarkedContentSequence();
cb.endText();
If you try this example, open the document in Adobe Reader and listen to the result. “Dr.” will be vocalized as “Doctor,” “EWS” as “Eyes Wide Shut,” you’ll hear text for the image, and “Seven Samurai” for the Japanese title.
15.2.3. Adding structure
We talked about marked content in chapter 13 when we discussed standards such as PDF/UA and PDF/A. In the previous section, you saw why marked content is important for PDF/UA. In this section, we’ll discuss the extra requirement for PDF/A level A conformance: the PDF needs to be tagged. Tagged PDF is a stylized use of PDF.
In part 1 of this book, you added all kinds of objects to the Document: paragraphs, lists, tables, and so on. Once PdfWriter translated these objects to PDF syntax, all structure was lost; if you have a PDF file, it’s not possible to extract a Paragraph, List, or PdfPTable object. The content inside a PDF consists of a series of operators such as showText(), and there’s no way to know if a snippet of PDF syntax is part of a paragraph, a list, or a table.
When you create a tagged PDF file that conforms with PDF/A level A, you use marked content to store information about the document structure along with the content. The standard structure types that can be used for this purpose are defined in ISO-32000-1. They are divided into these four categories:
- Grouping elements— These group other elements into sequences and hierarchies, but they have no direct effect on layout. For example, /Document, /Part, /Sect, /Div, /TOC, and so on.
- Block-level structure elements (BLSEs)— These describe the overall layout of content on the page: paragraph-like elements (/P, /H, /H1-/H6), list elements (/L, /LI, /Lbl, /LBody), and the table element (/Table).
- Inline-level structure elements (ILSEs)— These describe the layout of content within a BLSE: /Span, /Quote, /Note, /Reference, and so on.
- Illustration elements— These compact sequences of content that are considered to be unitary objects with respect to page layout: /Figure, /Formula, and /Form.
The content of such a structure is enclosed in a marked-content sequence, such as the /Span element used in the previous example. For a full list of all the available elements, see ISO-32000-1 section 14.8.4.
Creating a Tagged Pdf
Suppose that you have an XML file containing the first paragraphs of the book Moby Dick. This XML file uses the custom tags chapter, title, and para. You want to convert this XML file into a tagged PDF file and use the structure elements, but keep the original tags.
The following listing demonstrates the first step in doing this. It creates the root of a structure tree and maps the custom tags to structure elements listed in ISO-32000-1. That way, you can use your custom tags in the rest of the document.
Listing 15.16. StructuredContent.java

In listing 15.16, you create a top element for the structure using the custom tag chapter. A PDF reader will look up what this tag means in the /RoleMap and find out it’s a /Sect element. The XML file containing the first paragraphs of Moby Dick is parsed twice: once to examine the structure ![]() and once to read the content
and once to read the content ![]() .
.
This listing reads the structure elements into a List.
Listing 15.17. StructureParser.java
public class StructureParser extends DefaultHandler {
protected PdfStructureElement top;
protected List elements;
public StructureParser(
PdfStructureElement top, List<PdfStructureElement> elements) {
this.top = top;
this.elements = elements;
}
public void startElement(
String uri, String localName, String qName, Attributes attributes)
throws SAXException {
if ("chapter".equals(qName)) return;
elements.add(new PdfStructureElement(top, new PdfName(qName)));
}
}
The structure elements obtained in listing 15.17 are used in the ContentParser, whose two most important methods are shown here.
Listing 15.18. ContentParser.java
public void startElement(
String uri, String localName, String qName, Attributes attributes)
throws SAXException {
if ("chapter".equals(qName)) return;
current = elements.get(0);
elements.remove(0);
canvas.beginMarkedContentSequence(current);
}
public void endElement(String uri, String localName, String qName)
throws SAXException {
if ("chapter".equals(qName)) return;
try {
String s = buf.toString().trim();
buf = new StringBuffer();
if (s.length() > 0) {
Paragraph p = new Paragraph(s, font);
p.setAlignment(Element.ALIGN_JUSTIFIED);
column.addElement(p);
int status = column.go();
while (ColumnText.hasMoreText(status)) {
canvas.endMarkedContentSequence();
document.newPage();
canvas.beginMarkedContentSequence(current);
column.setSimpleColumn(36, 36, 384, 569);
status = column.go();
}
}
} catch (DocumentException e) {
e.printStackTrace();
}
canvas.endMarkedContentSequence();
}
Creating tagged PDFs with iText is possible, but it demands a lot of discipline. It’s certainly an area where there’s still a lot of work for the iText developers to do. The same goes for parsing tagged PDF files.
Parsing a Tagged Pdf
The code in this listing parses the Moby Dick PDF into an XML file.
Listing 15.19. ParseTaggedPdf.java
public static void main(String[] args)
throws IOException, DocumentException,
SAXException, ParserConfigurationException {
StructuredContent.main(args);
TaggedPdfReaderTool reader = new TaggedPdfReaderTool();
reader.convertToXml(new PdfReader(StructuredContent.RESULT),
new FileOutputStream(RESULT));
}
The TaggedPdfReaderTool class fetches the /StructTreeRoot object from the catalog. Then it recursively inspects all the children of the tree:
PdfDictionary catalog = reader.getCatalog();
PdfDictionary struct = catalog.getAsDict(PdfName.STRUCTTREEROOT);
inspectChild(struct.getDirectObject(PdfName.K));
The convertToXml() method writes an XML file to the OutputStream that is the equivalent of the XML file originally used to create the PDF. Because the structure is stored in the PDF document, you can convert an XML file to PDF and back. The tagged PDF reader tool won’t work for PDF documents that don’t have any structure (which is the case for most PDF files), but it will work for most tagged PDF files.
Note
This functionality is very new (it was originally written as an example for this book) and there’s plenty of room for improvement.
The tool is built on top of the PDF parsing classes that were recently added to iText. Parsing traditional PDFs is extremely difficult, but we’ll make a fair attempt in the next section.
15.3. Parsing PDFs
The first edition of iText in Action had a section named “Why iText doesn’t do text extraction.” It was preceded by an example that demonstrated how to retrieve the content stream of a page using the getPageContent() method, just like you did in section 14.1. The simple Hello World example from chapter 1 resulted in the following stream:
q
BT
36 806 Td
0 -18 Td
/F1 12 Tf
(Hello World!)Tj
0 0 Td
ET
Q
The PDF string (Hello World!) followed by the text operator Tj is visible in clear text. Surely it must be possible to write some code to extract that string? When the first edition was written, the only way to achieve this was by using the PRTokeniser class (mind the British s in the name, instead of the American z).
In this section, we’ll learn how iText has evolved, and find out how to parse the content of PDF content streams to retrieve text and images.
15.3.1. Examining the content stream with PRTokeniser
With PRTokeniser, you can split a PDF content stream into its most elementary parts. Each part has a specific type. The possible types, shown in table 15.2, are enumerated in the enum named TokenType.
Table 15.2. Overview of the token types
|
TokenType |
Symbol |
Description |
|---|---|---|
| NUMBER | The current token is a number. | |
| STRING | () | The current token is a string. |
| NAME | / | The current token is a name. |
| COMMENT | % | The current token is a comment. |
| START_ARRAY | [ | The current token starts an array. |
| END_ARRAY | ] | The current token ends an array. |
| START_DIC | << | The current token starts a dictionary. |
| END_DIC | >> | The current token ends a dictionary. |
| REF | R | The current token ends a reference. |
| OTHER | The current token is probably an operator. | |
| ENDOFFILE | There are no more tokens. |
This listing shows the simplest PDF parser one could write. It gets the page content of page 1, passes the content to a PRTokeniser object, and writes all the tokens with TokenType.STRING to a PrintWriter.
Listing 15.20. ParsingHelloWorld.java
public void parsePdf(String src, String dest) throws IOException {
PdfReader reader = new PdfReader(src);
byte[] streamBytes = reader.getPageContent(1);
PRTokeniser tokenizer = new PRTokeniser(streamBytes);
PrintWriter out = new PrintWriter(new FileOutputStream(dest));
while (tokenizer.nextToken()) {
if (tokenizer.getTokenType() == PRTokeniser.TokenType.STRING) {
out.println(tokenizer.getStringValue());
}
}
out.flush();
out.close();
}
If you try this example with your first Hello World example, you’ll have a very good result:
Hello World!
But as soon as you have more complex PDF files, this simple parser won’t work. Listing 15.21 creates a PDF file with the text “Hello World”, but those words are added in different parts: first “ld”, then “Wor”, then “llo”, and finally “He”. Because of the choice of coordinates, the text reads “Hello World” when opened in a PDF viewer. It also adds the text “Hello People” as a form XObject.
Listing 15.21. ParsingHelloWorld.java

When you use the simple parser from listing 15.20, you’ll get the following output:
ld
Wor
llo
He
PRTokeniser offers the strings in the order they appear in the content stream, not in the order they are shown on the screen. Moreover, the text “Hello People” is missing because it’s not part of the content stream. It’s inside an external object that is referred to from the page dictionary.
Even if all the characters are in the right order, there may be kerning information between substrings, adjusting the space between letters so they look better (for instance between the two letter ls of the word “Hello”). However, the spacing can also be used instead of a whitespace character. That’s one aspect that should be considered and that makes it difficult to extract text from a content stream.
Another aspect is the encoding. It’s possible for a PDF to have a font containing characters that appear in a content stream as a, b, c, and so on, but for which the shapes drawn in the PDF file show a completely different glyph, such as α, β, γ, and so on. An application can create a different encoding for each specific PDF document—for example, in an attempt to obfuscate. More likely, the PDF-generating software does this deliberately, such as when a font with many characters is used but all the text can be shown using only 256 different glyphs. In this case, the software picks character names at random according to the glyphs that are used. Another possibility is that the content stream consists of raw glyph indexes; you then have to write code that goes through the character mappings and finds the right letters.
You’ll also encounter PDF files that were created from scanned images. The content stream of each of the pages in such a document contains a reference to an image XObject. There will be no PDF strings in the stream. In the previous chapter, you created PDF documents with the glyphs drawn by the Java TextLayout object, and you wouldn’t find any strings in this case either. Optical character recognition (OCR) will be your only recourse if you want to extract text from such a PDF document.
The section about text extraction in the first edition was followed by a section entitled “Why you shouldn’t use PDF as a format for editing.” Again, an example and a list of reasons was given for why it’s extremely difficult and not very wise to edit a content stream. But that was then, and this is now. It’s still true that you shouldn’t edit a PDF, but with regards to text extraction, we’ve welcomed a new iText developer, Kevin Day, who has contributed a package (com.itextpdf.text.pdf.parser) containing classes that are able to parse and interpret PDF content.
Warning
The API of this package is subject to change, because other developers—including myself—are still experimenting with it, adding new features, and fixing bugs.
Given the different obstacles I’ve outlined, not every PDF document that can be found in the wild can be parsed effectively, but the functionality does make a good effort at trying to find words and sentences, even if they’re drawn on a page in random order, as was the case with our second “Hello World” example.
15.3.2. Processing content streams with PdfContentStreamProcessor
If you look at the com.itextpdf.text.pdf.parser package, you’ll find utility classes such as ContentByteUtils with static methods to extract byte arrays from a PDF file, and tools such as PdfContentReaderTool with methods to create a String representation of objects and to output lists of objects and contents. For instance,
PdfContentReaderTool.listContentStream(new File(pdf), out);
This code snippet will write all the information that is needed to extract the content of a page, including the extracted text.
The next listing gives an idea of what to expect. Note that the content streams are replaced by ellipses (...).
Listing 15.22. calendar_info.txt generated with InspectPageContent.java
==============Page 1====================
- - - - - Dictionary - - - - - -
(/Type=/Page, /Contents=Stream, /Parent=Dictionary of type: /Pages,
/Resources=Dictionary, /MediaBox=[0, 0, 595, 842], /Rotate=90)
Subdictionary /Parent = (/Count=8, /Type=/Pages, /ITXT=5.0.2_SNAPSHOT,
/Kids=[6 0 R, 8 0 R, 10 0 R, 12 0 R, 14 0 R, 16 0 R, 18 0 R, 20 0 R])
Subdictionary /Resources = (/ProcSet=[/PDF, /Text, /ImageB, /ImageC,
/ImageI], /XObject=Dictionary, /Font=Dictionary)
Subdictionary /XObject = (/Xf2=Stream of type: /XObject,
/Xf1=Stream of type: /XObject)
Subdictionary /Font = (/F1=Dictionary of type: /Font)
Subdictionary /F1 = (/Type=/Font, /BaseFont=/Helvetica,
/Subtype=/Type1, /Encoding=/WinAnsiEncoding)
- - - - - XObject Summary - - - - - -
------ /Xf2 - subtype = /Form = 671 bytes ------
...
------ /Xf2 - subtype = /FormEnd of Content------
------ /Xf1 - subtype = /Form = 162 bytes ------
...
------ /Xf1 - subtype = /FormEnd of Content------
- - - - - Content Stream - - - - - -
...
- - - - - Text Extraction - - - - - -
Day 1 FOOBAR FILM FESTIVAL 2011-10-12
...
This is the first step toward text extraction: collecting all the resources. Now you need to process the information. Listing 15.23 shows a new version of parsePdf() from listing 15.20. The PRTokeniser class is still used, but its complexity is hidden by the PdfContentStreamProcessor class.
Listing 15.23. ParsingHelloWorld.java

The output of this listing depends on the listener. This is an instance of the RenderListener interface to which the processor passes information about the text and images in the page. The following listing is an experimental implementation that will help you understand the mechanism.
Listing 15.24. MyTextRenderListener.java

You’re not concerned with images yet. Angle brackets are placed at the start and end of text blocks, and every text segment is enclosed in angle brackets. If you use this method on the PDF created with listing 15.21, you’ll get the following results:
<>
<<ld><Wor><llo><He>>
<<Hello People>>
The words “Hello World” are still mangled, but the text “Hello People” is picked up correctly.
In listing 15.24, you use the class TextRenderInfo to get a chunk of text with the getText() method, but the render info class also provides methods to get LineSegment objects containing information about the location of the text on the page, to get the font that was used, and so on. With this information, you could write a RenderListener implementation that returns a result that is much better than the output provided by MyTextRenderListener.
Fortunately, this has already been done for you in the form of text-extraction strategies. The TextExtractionStrategy interface extends RenderListener, adding a getResultantText() method. The different implementations of this interface, in combination with the PdfReaderContentParser or PdfTextExtractor, dramatically reduce the number of code lines needed to extract text.
15.3.3. Extracting text with PdfReaderContentParser and PdfTextExtractor
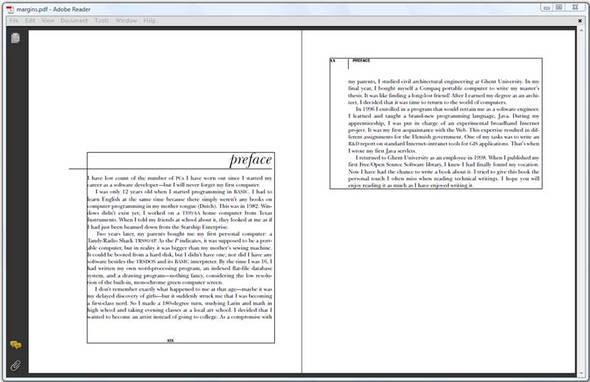
Figure 15.7 shows two pages—the preface from the first edition of iText in Action. The PDF was extracted from the eBook version of the book. It’s a traditional PDF without structure.
Figure 15.7. Preface from the first edition

Let’s try to convert the content from these two pages to a plain text file.
Simple Text Extraction
The next example shows how to use SimpleTextExtractionStrategy in combination with PdfReaderContentParser to create a plain text file with the content of the preface.
Listing 15.25. ExtractPageContent.java
PdfReader reader = new PdfReader(pdf);
PdfReaderContentParser parser = new PdfReaderContentParser(reader);
PrintWriter out = new PrintWriter(new FileOutputStream(txt));
TextExtractionStrategy strategy;
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
strategy = parser.processContent(i, new SimpleTextExtractionStrategy());
out.println(strategy.getResultantText());
}
out.flush();
out.close();
The PdfReaderContentParser uses the PdfContentStreamProcessor internally. The processContent() method performs the same actions you did in listing 15.23, saving you a handful of lines of code.
The SimpleTextExtractionStrategy class is a special implementation of the RenderListener. It stores all the TextRenderInfo snippets in the order they occur in the stream, but it’s intelligent enough to detect which snippets should be combined into one word, and which snippets should be separated with a space character.
This TextExtractionStrategy object, containing all the text of a specific page, is returned by the processContent() method. When you get the resulting text of the first page of the Preface, it starts like this:
xix
preface
I have lost count of the number of PCs I have worn out since I started my
career as a software developer—but I will never forget my first computer.
I was only 12 years old when I started programming in BASIC. I had to
learn English at the same time because there simply weren't any books on
computer programming in my mother tongue (Dutch). This was in 1982. Win-
dows didn't exist yet; I worked on a TI99/4A home computer from Texas
Instruments. When I told my friends at school about it, they looked at
me as if I had just been beamed down from the Starship Enterprise.
The first text element in the content stream is “xix”, the Roman page number that appears at the bottom of the page. The fact that the rest of the text reads correctly is a coincidence. It’s not necessary for an application to put all the paragraphs in the correct order.
Location-Based Text Extraction
Let’s change one line in listing 15.25:
Listing 15.26. ExtractPageContentSorted1.java
PdfReader reader = new PdfReader(pdf);
PdfReaderContentParser parser = new PdfReaderContentParser(reader);
PrintWriter out = new PrintWriter(new FileOutputStream(txt));
TextExtractionStrategy strategy;
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
strategy
= parser.processContent(i, new LocationTextExtractionStrategy());
out.println(strategy.getResultantText());
}
out.flush();
out.close();
The LocationTextExtractionStrategy class will accept all the TextRenderInfo objects from the processor, just like the simple text-extraction strategy, but it will sort all the snippets of text based on their position on the page, before creating the resultant text.
The next example makes this code even more compact by using the PdfTextExtractor class.
Listing 15.27. ExtractPageContentSorted2.java
PdfReader reader = new PdfReader(pdf);
PrintWriter out = new PrintWriter(new FileOutputStream(txt));
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
out.println(PdfTextExtractor.getTextFromPage(reader, i));
}
out.flush();
out.close();
Listings 15.26 and 15.27 have the same output. If you look at the resulting text file, you’ll see that it starts with the word “preface”, and that the page number has moved to the middle:
... As a compromise with
xix
xx PREFACE
my parents, I studied civil architectural engineering at Ghent University.
The strings “xix” and “xx” are page numbers; “PREFACE” is a running header. In tagged documents, these elements would have been referred to as artifacts. Screen readers would have ignored these snippets of text because they are not part of the actual content. When parsing our preface, it would be nice to add a filter that removes the page numbers and headers from the resulting text.
Using Render Filters
The special FilteredTextRenderListener text-extraction strategy combines a normal TextExtractionStrategy implementation with one or more render filters. The next listing uses a subclass of the abstract RenderFilter class, named RegionTextRenderFilter.
Listing 15.28. ExtractPageContentArea.java

In this listing, you create a Rectangle whose dimensions are chosen in such a way that the page numbers and the running headers are outside the rectangle. You then use this rectangle to create a RegionTextRenderFilter. This filter will examine all the text and images that are processed and ignore everything that falls outside the chosen area.
Note
The rect object is currently not an instance of com.itextpdf.text. Rectangle; it’s a java.awt.Rectangle (internally, a java.awt.geom. Rectangle2D object is used). This may change in the future; the API of the PDF parsing functionality hasn’t been finalized yet.
The filter is combined with a text-extraction strategy in a FilteredTextRenderListener object, and from there on the code is similar to the code in listing 15.27, with the exception that you now pass a custom strategy as a parameter for the getTextFromPage() method. The result is the preface text without page numbers and running headers.
15.3.4. Finding text margins
The goal of parsing the content of a page isn’t always to retrieve text. A frequently asked question involves finding the position where the last line of text ends on a page, so that extra text can be added. This can be done using a special RenderListener implementation.
Figure 15.8 shows the same pages as figure 15.7, but with bounding rectangles for the text added.
Figure 15.8. Finding the location of text in existing PDFs
The positions needed to draw these rectangles were retrieved using a TextMarginFinder:
Listing 15.29. ShowTextMargins.java
PdfReader reader = new PdfReader(src);
PdfReaderContentParser parser = new PdfReaderContentParser(reader);
PdfStamper stamper = new PdfStamper(reader, new FileOutputStream(RESULT));
TextMarginFinder finder;
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
finder = parser.processContent(i, new TextMarginFinder());
PdfContentByte cb = stamper.getOverContent(i);
cb.rectangle(finder.getLlx(), finder.getLly(),
finder.getWidth(), finder.getHeight());
cb.stroke();
}
stamper.close();
Note that only text is taken into account. Graphics, such as the line that is drawn under the title “preface,” are ignored by the parser in its current version. The content stream processor only returns objects of type TextRenderInfo and ImageRenderInfo.
15.3.5. Extracting images
Just like TextRenderInfo gives you information about a snippet of text, ImageRenderInfo will give you info about an image: the position of the image and an instance of the PdfImageObject class that encapsulates the image XObject dictionary and the raw image bytes. The next listing processes all the pages of a PDF document and uses a custom ImageRenderListener to extract the images to a file.
Listing 15.30. ExtractImages.java
PdfReader reader = new PdfReader(filename);
PdfReaderContentParser parser = new PdfReaderContentParser(reader);
MyImageRenderListener listener = new MyImageRenderListener(RESULT);
for (int i = 1; i <= reader.getNumberOfPages(); i++) {
parser.processContent(i, listener);
}
The following example shows a special implementation of the RenderListener to extract images. The methods you implemented in the custom text render listener in listing 15.24 are left empty. In this case, you’re not interested in the text; only the renderImage() method is implemented.
Listing 15.31. MyImageRenderListener.java

In listing 15.31, the filename that is chosen for each image has a reference to the indirect object number of the image stream. The bytes of image streams with the filter /DCTDECODE or /JPXDECODE will be written to a file as is, resulting in valid JPEG and JPEG2000 files. For the other types of images, you also need to inspect the stream dictionary for values such as the number of bits per component, the color space, the width and the height, and so on. The getBufferedImage() method will attempt to do this in your place, and return an instance of java.awt.image.BufferedImage. But when you try this example on your own system, you’ll notice that not all images are extracted.
Please don’t report this as a bug. Not all the different types of images are supported yet. This is only a preview of new functionality that has been added to iText recently. Just like with parsing text, a best effort is done; when more types of images are supported will depend on code contributors and paying iText users.
15.4. Summary
This chapter was like a sequel to chapter 14. We continued talking about the content stream of a page, but in the first two sections we added structures that made part of the content optional or that added extra information to the content, like extra properties that belong to objects on the screen, information that improves the accessibility of the document, and structures that allow you to discover elements from the original source, such as paragraphs, lists, and tables.
To demonstrate the power of these structure elements, you’ve seen how to convert an existing PDF document to XML. This only works for PDF documents that are tagged. Other PDF documents can’t be converted to XML, but you can parse them and write the output to a plain text file. We’ve discussed the different strategies that are at play and looked at how you can extract text from a PDF, find margins, and even extract images.
In the next chapter, we’ll start by looking at image and other streams. We won’t return to content streams, but we’ll look at fonts streams and embedded files, and we’ll even look at how to integrate a Flash application into a PDF document.