 Aggregate checks
by Andrea Vacche, Patrik Uytterhoeven, Rihards Olups
Zabbix: Enterprise Network Monitoring Made Easy
Aggregate checks
by Andrea Vacche, Patrik Uytterhoeven, Rihards Olups
Zabbix: Enterprise Network Monitoring Made Easy
- Zabbix: Enterprise Network Monitoring Made Easy
- Table of Contents
- Zabbix: Enterprise Network Monitoring Made Easy
- Zabbix: Enterprise Network Monitoring Made Easy
- Credits
- Preface
- I. Module 1
- 1. Getting Started with Zabbix
- The first steps in monitoring
- Zabbix features and architecture
- Installation
- Summary
- 2. Getting Your First Notification
- 3. Monitoring with Zabbix Agents and Basic Protocols
- 4. Monitoring SNMP Devices
- 5. Managing Hosts, Users, and Permissions
- 6. Detecting Problems with Triggers
- 7. Acting upon Monitored Conditions
- 8. Simplifying Complex Configurations with Templates
- 9. Visualizing Data with Graphs and Maps
- 10. Visualizing Data with Screens and Slideshows
- 11. Advanced Item Monitoring
- 12. Automating Configuration
- 13. Monitoring Web Pages
- 14. Monitoring Windows
- 15. High-Level Business Service Monitoring
- 16. Monitoring IPMI Devices
- 17. Monitoring Java Applications
- 18. Monitoring VMware
- 19. Using Proxies to Monitor Remote Locations
- 20. Encrypting Zabbix Traffic
- 21. Working Closely with Data
- 22. Zabbix Maintenance
- A. Troubleshooting
- B. Being Part of the Community
- 1. Getting Started with Zabbix
- II. Module 2
- 1. Zabbix Configuration
- 2. Getting Around in Zabbix
- 3. Groups, Users, and Permissions
- 4. Monitoring with Zabbix
- Introduction
- Active agents
- Passive agents
- Extending agents
- SNMP checks
- Internal checks
- Zabbix trapper
- IPMI checks
- JMX checks
- Aggregate checks
- External checks
- Database monitoring
- Checks with SSH
- Checks with Telnet
- Calculated checks
- Building web scenarios
- Monitoring web scenarios
- Some advanced monitoring tricks
- Autoinventory
- 5. Testing with Triggers in Zabbix
- 6. Working with Templates
- 7. Data Visualization and Reporting in Zabbix
- 8. Monitoring VMware and Proxies
- 9. Autodiscovery
- 10. Zabbix Maintenance and API
- C. Upgrading and Troubleshooting Zabbix
- III. Module 3
- 1. Deploying Zabbix
- 2. Distributed Monitoring
- 3. High Availability and Failover
- Understanding high availability
- Understanding the levels of IT service
- Some considerations about high availability
- Implementing high availability on a web server
- Configuring the Zabbix server for high availability
- Implementing high availability for a database
- Summary
- 4. Collecting Data
- 5. Visualizing Data
- 6. Managing Alerts
- 7. Managing Templates
- 8. Handling External Scripts
- 9. Extending Zabbix
- 10. Integrating Zabbix
- D. Bibliography
- Index
Running individual checks has been great so far, but they are just checks on one system. What if you would like to know the total CPU load of a group of servers? For example, when you are running a cluster of servers? For this we can make use of the aggregated checks in Zabbix.
To be able to finish this recipe successfully we need our Zabbix server with a few Linux hosts installed and properly configured.
- First, we create a new host called
linuxgroup, for the agent IP address we can just put0.0.0.0and add it in a fictive hostgroup or for example, Discovered hosts. - Next, we create a new group (Configuration | Host groups)
"aggregated"and we add two or more Linux hosts in this group. - Now we create an active item
"system.cpu.load[percpu,avg1]"in a new template that we can link to all our hosts available in our"aggregated"group. - The next step is to create a new template for example
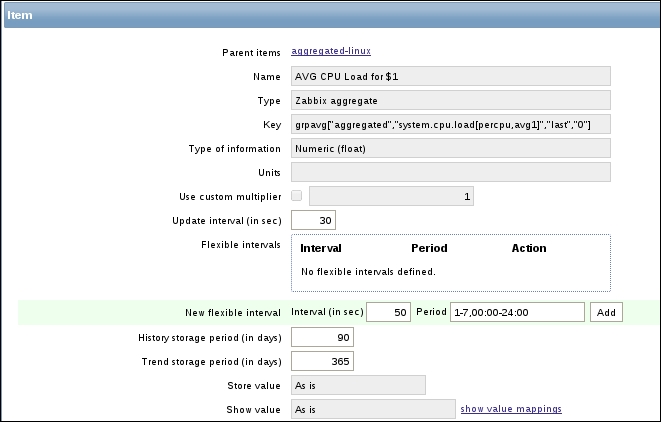
aggregated-linuxand link this template to our fake hostlinuxgroupthat we made in step 1. - In this template, create an item with the Key:
grpavg["aggregated","system.cpu.load[percpu,avg1]","last"," 0"]
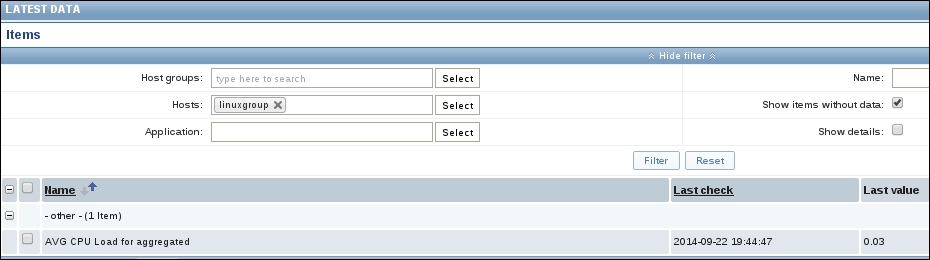
When you go now to Monitoring | Latest data, you will see on our fake host the average CPU load from all our hosts in the group "aggregated".
Aggregated items summarize the readings of an item of all hosts in a group together. The structure used to create an aggregated item is as follows:
groupfunc["Host group","Item key",itemfunc,timeperiod]
The groupfunc is just a placeholder and needs to be replaced with grpavg, grpmax, grpmin, or grpsum. The Host group is the group of servers that we want to use for our calculation. The item key is the item that is available on all servers in the group. The item function can be avg, count, last, max, min, or sum.
Aggregated checks don't rely on any Zabbix agent or server check. Instead the Zabbix server will look at existing data in the database and reuse it to calculate a new item.
When you create an aggregated check in a template and link this template to all servers in for example, the group webservers; then Zabbix will recalculate this check on every server in this group. The result is that Zabbix server will calculate and store the same data for every server. One solution is to add the item local on a host or a better solution could be to create a fake host like we did in the example with the name related to the purpose of our cluster.
-
No Comment