
Compression and Multiplexing
Compression and multiplexing are used to improve efficiency on wireless and wireline networks. Compression shrinks the data and multiplexing combines data from multiple sources onto a single path.
Compression—Manipulating Data for More Capacity
Just as a trash compactor makes trash smaller so that more refuse can be packed into a garbage barrel, compression makes data smaller so that more information can be packed into telephone lines. It is a technique to get more capacity on telephone lines, the Internet, cellular networks and airwaves used for broadcasts. Advances in compression have enormous potential to make dialup, cable modem, DSL and cellular networks adequate for movies, games, music and downloading graphics such as JPEG and PowerPoint images.
Compression Standards = Interoperability
There are many types of compression methods. A device called a codec (short for coder-decoder) encodes text, audio, video or images using a mathematical algorithm. For compression to work, both the sending and receiving ends must use the same compression method. The sending end looks at the data, voice or image. It then compresses it using a mathematical algorithm. The receiving end of the transmission decodes the transmission. For devices from multiple manufacturers to interoperate, compression standards agreed upon for modems, digital television, video teleconferencing and other devices must be used. See the appendix to this chapter for compression standards.
Modems—Using Compression to Get Higher Throughput
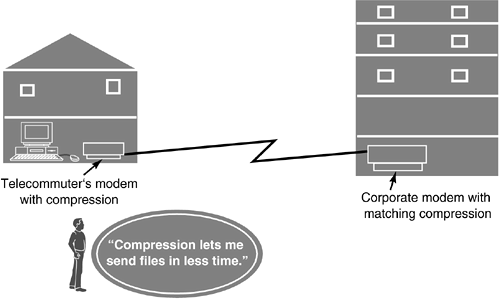
When compression is used with text and facsimile, data to be transmitted is made smaller by removing white spaces and redundant images, and by abbreviating the most frequently appearing letters. For example, with facsimile, compression removes white spaces from pictures and only transmits the images. Modems use compression to achieve higher throughput. Throughput is the actual amount of useful data sent on a transmission. When modems equipped with compression transmit text, repeated letters are abbreviated into smaller codes. For example, the letters E, T, O and I appear frequently in text. Compression sends shortened versions of these letters with 3 bits rather than the entire 8 bits for each letter. Thus, a page of text might be sent using 1600 bits rather than 2200 bits. Telecommuters who access and send data to corporate locations often use modems equipped with compression to transmit files more quickly (see Figure 1.4).
Figure 1.4. Compression in modems.
Compression—Commercially Viable, Full-Motion Videoconferencing
Improvements in the mid-1980s in video compression spawned the commercial viability of full-motion, room-type videoconference systems. Video systems that transmit at 128 Kbps to 768 Kbps are known as full-motion systems. Television is a broadcast-quality service. Compression made it economical to use full-motion video by enabling video to be acceptable on slower, lower cost telephone lines. Older systems required expensive, full T-1 lines for video, the cost of which inhibited sales of room-type video systems. New compression techniques available in the 1980s from companies such as PictureTel and VTEL required only 128 Kbps to 384 Kbps for acceptable picture quality. Thus, videoconferencing became affordable to a wide range of organizations. A new industry boomed.
In video, compression works by transmitting only the changed image, not the same image over and over. For example, in a videoconference, nothing is transmitted after the initial image of a person until that person moves or speaks. Fixed objects such as walls, desks and background are not repeatedly transmitted. Another way video compression works is by not transmitting the entire image. For example, the device performing the compression, the codec, knows that discarding minor changes in the image won't noticeably distort the viewed image.
Compressing and Digitizing Speech
The use of sophisticated compression has enabled audio to be transmitted from the Internet without using high-speed phone lines. Speech, audio and television are all analog in their original form. Before they are transmitted over digital networks, codecs compress them and convert them to digital. Codecs sample speech at different heights (amplitude) along the sound wave and convert them to either a one or a zero. At the receiving end, decoders convert the ones and zeros back to sound waves. With compression, codecs do not have to sample every height on the sound wave to achieve high-quality sound. For example, they skip silence or predict the next sound based on the previous sound. Thus, fewer bits per second are transmitted to represent the speech. Codecs are located in the following digital devices: cellular handsets, telephones, televisions and radios.
Proposed Compression Standard for Digital Radio
iBiquity has proposed a new compression technology, In-Band On-Channel Digital Audio Broadcasting (IDAB™), that uses airwaves within the current AM and FM spectrum to broadcast digital programming. IDAB is based on Perceptual Audio Coder (PAC™). There are many sounds that the ear cannot discern because they are masked by louder sounds. PAC discerns and discards these sounds that the ear cannot hear and that are not necessary to retain the quality of the transmission. This results in transmission with 15 times fewer bits. PAC, Perceptual Audio Coder, was first developed at Bell Labs in the 1930s.
Streaming Media
Streaming media techniques are the major reason the Internet is used to distribute music and multimedia content. It makes on-line music accessible to users without high-speed Internet connections.
Speeding Up Internet Connections
Streaming speeds up transmission of video, images and audio over the Internet. When graphics and text are sent to an Internet user's browser, the text can be viewed as soon as it reaches the PC. The graphics are filled in as they are received. Streaming is different than downloading. When music is streamed, callers listen to the music but cannot store it to listen to it later. Downloading actually stores the music files on a listener's computer hard drive. The Napster court case involved unauthorized downloading of music. The MP3.com case was about unauthorized listening (streaming) of music. (See Chapter 8 for a description of the issues litigated in these cases.)
When text, music or graphics are downloaded, the entire file must be downloaded before it can be viewed or played. With streaming technology, as soon as a URL is clicked, information starts to be viewable by the end user. Streaming is an important feature of browsers. When Web pages with both text and graphical ads are downloaded, the text reaches the end user's computer faster than the graphics. For example, someone reading the online edition of The Wall Street Journal can start reading articles while the ads are being received.
MPEG Standards
MPEG standards are used for streaming audio and video. The International Telecommunications Union (ITU) formed the Moving Picture Experts Group (MPEG) in 1991 to develop compression standards for playback of video clips and digital TV. MPEG3 came to be used for streaming audio. MPEG and proprietary streaming media compression schemes are asymmetrical. It takes more processing power to code than to decode an image. Streaming compression algorithms assume that the end user will have less processing power to decode than developers and broadcasters that encode the video and audio.
The two most prevalent streaming media software products are those developed by RealNetworks Inc. and Microsoft Corporation. RealNetworks' RealSystem® and RealPlayer® have a larger market share. Microsoft's product is Windows® Media Player® services. According to The Wall Street Journal WSJ.com “Reality Bytes” on January 29, 2001, less than half of computer users had media players capable of playing MP3 files. Statistics in the article from Jupiter Research, Media Metrix indicated that 28% of total home computers had RealPlayer and 22% had Windows Media Player installed by the third quarter of 2000. Both Microsoft and RealNetworks give away their streaming media software for free in the hope that their software will become the de facto standard and that developers will purchase server-based products from them.
More powerful personal computers as well as improvements in compression have increased the use of streaming audio and video over the Internet. In December 2000, Microsoft announced new compression software in its products that it claims uses a third of the computer disc space as MP3 and downloads 60% faster. Listen.com's subsidiary TuneTo.com announced in April 2001 a new streaming technology that will cut transmission to 1000 bits of data from 50,000 to 138,000 bits for current streaming methods. Listen.com claims this will make streaming audio viable for slower speed cellular devices.
Speech Recognition—Making the Web and Wireless Services Friendlier
When users call companies they no longer have to press 1 for sales and 2 for service. They can say “sales” or “service.” If they know the name of the person they're calling, they can speak the name of the person and the system they've dialed into recognizes the name and transfers them. Internet service provider (ISP) AOL lets people log into and hear their email messages by speaking commands from telephones. Web users no longer need their computers with them to listen to their messages. More powerful, faster computers have given speech recognition software from companies such as Nuance Communications and SpeechWorks International the tools to develop software capable of translating speech into computer commands.
How Speech Recognition Works
Speech recognition works by first detecting and then capturing spoken words (utterances). It converts the captured utterances to a digital representation of the words after removing background noises. Capturing the speech and digitally representing it is done by digital signal processors (DSPs), which are high-speed specialized computer chips. The speech recognition software then breaks up the sounds into small chunks, which are easier to define than larger pieces of sound. Next, the software compares various properties of the chunks of sound to large amounts of previously captured data. Based on these comparisons, the speech is assigned probabilities of matching particular phonemes. (Phonemes are the most basic sounds such as “b” and “aw.”) Finally, the software compares phonemes, matching probabilities with possible user responses from a database. The software puts together possible responses made up of phonemes, vocabulary and grammar in the speech recognition software. Grammar refers to the way the words are strung together.
Faster computer processors are a key factor in improvements in speech recognition. New computers perform the digitization and comparisons in milliseconds. They also take into account gender differences and regional accents. Systems contain different databases of expected responses based on the application. A corporate directory has a different speech database than one for airline scheduling or lost luggage applications. Important speech recognition improvements are:
Speaker independence— Previous systems needed users to “train” the system to recognize words. New systems recognize words from the general population. They are speaker independent.
Barge in— Users who call frequently can interrupt system prompts and say commands or department names as soon as the system answers the phone.
Voice authentication— Voice authentication provides another layer of security for access to secure corporate files. In financial institutions, speech recognition recognizes a particular user's voice. Systems also require passwords on top of voice authentication for access to corporate files.
Continuous speech— Systems can pick out keywords when callers are speaking naturally. If a caller says, “I think I'd like my email,” the system picks out the word email from the sentence.
VoiceXML—Linking Speech to Databases
Voice eXtensible Markup Language (VoiceXML) is a markup programming language. A markup language contains tags that tell how code is to be processed. Just as HTML adds tags to format Web pages, VoiceXML is a proposed standard to use tags with audio prompts to describe call flow and dialog in speech recognition applications. The goal of VoiceXML is to create interfaces to Web- and call center–based data for words spoken from cellular phones, landline phones and wireless personal digital assistants. The tags contain fields denoting actions such as if transfer this call <if>. The tags also identify prompts and fields that contain links that transfer calls based on callers' spoken commands.
VoiceXML is interpreted by speech browsers that present speech content to listeners who have requested information. The speech browser is a gateway between the telephone and the Internet or call center. It provides the link between the user and the requested information. It is essentially an integrated voice response unit enabled to interpret speech as well as touch-tone commands. Just as voice response units translate touch-tone to computer commands, speech browsers translate speech and provide access to databases. (See Chapter 2 for integrated voice response systems.)
Having a VoiceXML standard will enable speech browsers from any manufacturer to easily interact with Web servers. Speech access is particularly attractive internationally where many more people have cellular telephones than personal computers for Web access.
Multiplexing—Let's Share
Multiplexing combines traffic from multiple voice or data devices into one stream so that they can share a telecommunications path. Like compression, multiplexing enables companies and carriers to send more information on cellular airwaves and telephone lines. However, unlike compression, multiplexing does not alter the actual data sent. Multiplexing equipment is located in long distance companies, local telephone companies and at end-user premises. It is used with both analog and digital services. Examples of multiplexing over digital facilities include T-1, fractional T-1, T-3, ISDN and ATM.
The oldest multiplexing techniques were devised by AT&T for use with analog voice services. The goal was to make more efficient use of the most expensive portion of the public telephone network, the outside wires used to connect homes and telephone offices to each other. This analog technique was referred to as frequency division multiplexing. Frequency division multiplexing divides the available range of frequencies among multiple users. It enabled multiple voice and later data calls to share paths between central offices. Thus, AT&T did not need to construct a cable connection for each conversation. Rather, multiple conversations could share the same wire between telephone company central offices.
Digital multiplexing schemes also enable multiple channels of voice and data to share one path. Digital multiplexing schemes operate at higher speeds and carry more traffic than analog multiplexing. For example, T-3 carries 672 conversations over one line at a speed of 45 megabits per second (see Figure 1.5). A matching multiplexer is required at both the sending and receiving ends of multiplex equipped communications channels.
Figure 1.5. Multiplexers for sharing a telephone line.

T-3 is used for very large customers, telephone company and Internet service provider networks. T-1 is the most common form of multiplexing for end-user organizations. T-1 is lower in cost and capacity than T-3. T-1 allows 24 voice and/or data conversations to share one path. T-1 applications include linking organization sites together for voice calls, Internet access and links between end users and telephone companies for discounted rates on telephone calls.