
You can read a raw text data file using the textFile() method. Suppose you have the logs of some purchase:
number product_name transaction_id website price date0 jeans 30160906182001 ebay.com 100 12-02-20161 camera 70151231120504 amazon.com 450 09-08-20172 laptop 90151231120504 ebay.ie 1500 07--5-20163 book 80151231120506 packt.com 45 03-12-20164 drone 8876531120508 alibaba.com 120 01-05-2017
Now reading and creating RDD is pretty straightforward using the textFile() method as follows:
myRDD = spark.sparkContext.textFile("sample_raw_file.txt")
$cd myRDD
$ cat part-00000
number product_name transaction_id website price date 0 jeans 30160906182001 ebay.com 100 12-02-20161 camera 70151231120504 amazon.com 450 09-08-2017
As you can see, the structure is not that readable. So we can think of giving a better structure by converting the texts as DataFrame. At first, we need to collect the header information as follows:
header = myRDD.first()
Now filter out the header and make sure the rest looks correct as follows:
textRDD = myRDD.filter(lambda line: line != header)
newRDD = textRDD.map(lambda k: k.split("\t"))
We still have the RDD but with a bit better structure of the data. However, converting it into DataFrame will provide a better view of the transactional data.
The following code creates a DataFrame by specifying the header.split is providing the names of the columns:
textDF = newRDD.toDF(header.split("\t"))
textDF.show()
The output is as follows:
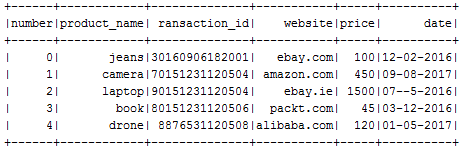
Now you could save this DataFrame as a view and make a SQL query. Let's do a query with this DataFrame now:
textDF.createOrReplaceTempView("transactions")
spark.sql("SELECT * FROM transactions").show()
spark.sql("SELECT product_name, price FROM transactions WHERE price >=500 ").show()
spark.sql("SELECT product_name, price FROM transactions ORDER BY price DESC").show()
The output is as follows:
