PageRank is one of the most important algorithms in the graph processing space. Originating at Google, the algorithm named after Larry page, the founder of Google, has evolved into many types of use cases based on the concept of ranking vertices or nodes based on relationships or edges.
Using Google PageRank as an example, you can improve the relative importance of a web page on your company website or maybe your blog by promoting the web page among other popular websites and technical blogs. Using this approach, your blog website may appear in Google search results about some article higher than other similar web pages, if there are a lot of third-party websites, which show your blog website and the content.
If you consider web pages as nodes/vertices and the hyperlinks between the web pages as edges, we essentially created a graph. Now, if you can count the rank of a web page as the number of hyperlinks/edges pointed into such as your myblog.com site having links on cnn.com or msnbc.com so that a user can click on the link and come to your myblog.com page. This can be a factor representing the importance of the myblog.com vertex. If we apply this simple logic recursively, we eventually end up with a rank assigned to each vertex calculated using the number of incoming edges and PageRank based on the ranks of the source vertices. A page that is linked to by many pages with high PageRank receives a high rank itself. Let's look at how to solve the PageRank problem at a big data scale using Spark GraphX. As we have seen, PageRank measures the importance of each vertex in a graph, assuming an edge from a to b represents the value of b boosted by a. For example, if a Twitter user is followed by many others, the user will be ranked highly.
GraphX comes with static and dynamic implementations of PageRank as methods on the pageRank object. Static PageRank runs for a fixed number of iterations, while dynamic PageRank runs until the ranks converge. GraphOps allows calling these algorithms directly as methods on the graph:
scala> val prVertices = graph.pageRank(0.0001).vertices
prVertices: org.apache.spark.graphx.VertexRDD[Double] = VertexRDDImpl[8245] at RDD at VertexRDD.scala:57
scala> prVertices.join(users).sortBy(_._2._1, false).take(10)
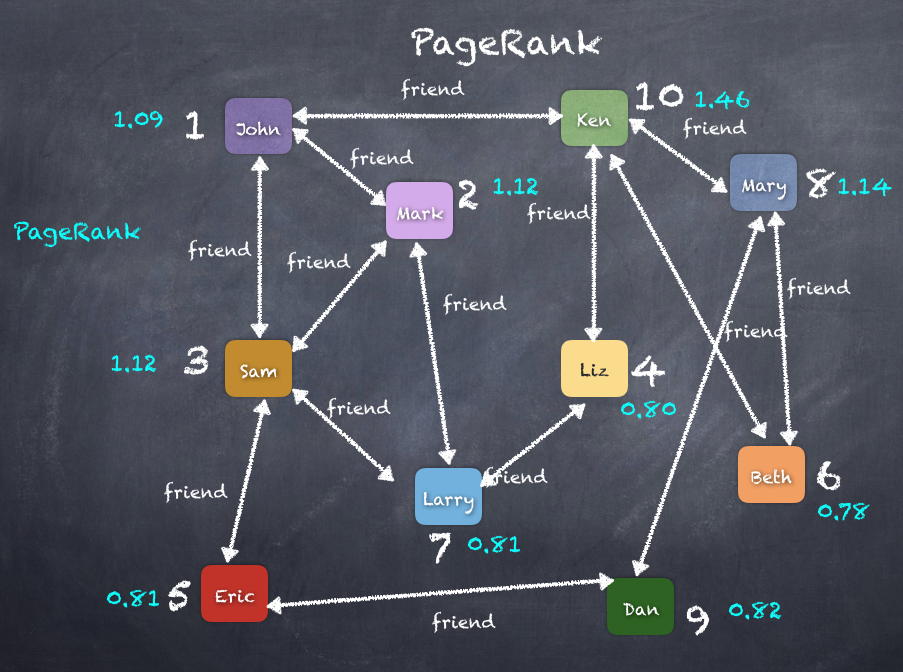
res190: Array[(org.apache.spark.graphx.VertexId, (Double, User))] = Array((10,(1.4600029149839906,User(Ken,Librarian))), (8,(1.1424200609462447,User(Mary,Cashier))), (3,(1.1279748817993318,User(Sam,Lawyer))), (2,(1.1253662371576425,User(Mark,Doctor))), (1,(1.0986118723393328,User(John,Accountant))), (9,(0.8215535923013982,User(Dan,Doctor))), (5,(0.8186673059832846,User(Eric,Accountant))), (7,(0.8107902215195832,User(Larry,Engineer))), (4,(0.8047583729877394,User(Liz,Doctor))), (6,(0.783902117150218,User(Beth,Accountant))))
The diagram of the PageRank algorithm on the graph is as follows: