
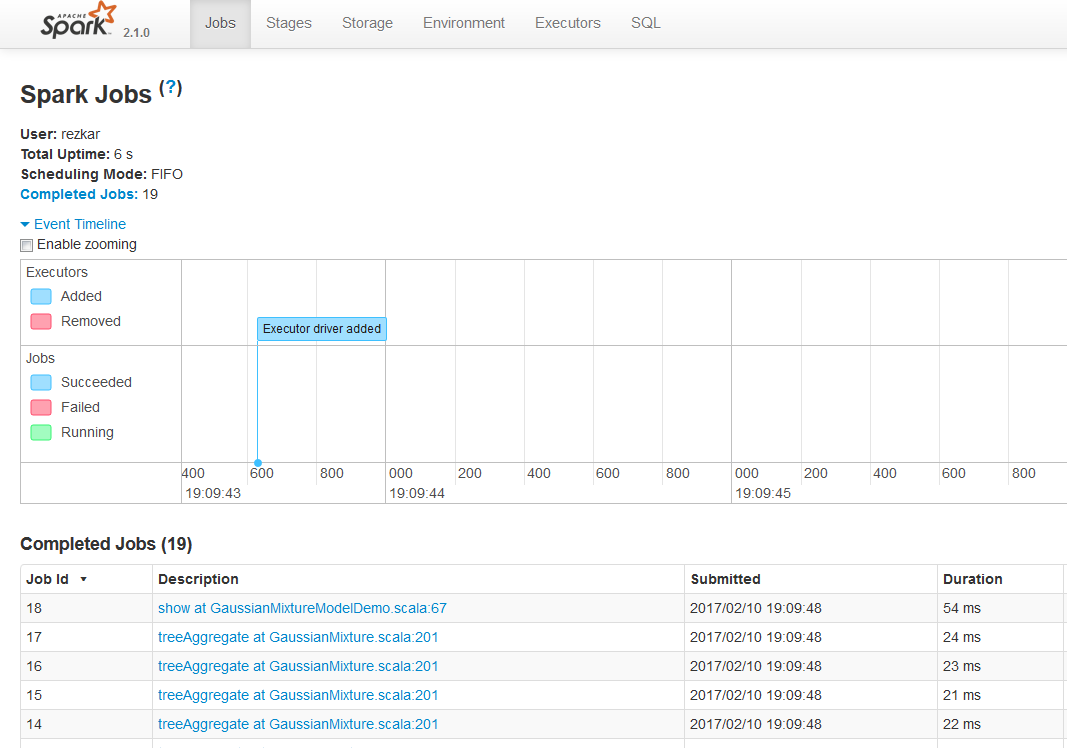
Depending upon the SparkContext, the Jobs tab shows the status of all the Spark jobs in a Spark application. When you access the Jobs tab on the Spark UI using a web browser at http://localhost:4040 (for standalone mode), you should observe the following options:
- User: This shows the active user who has submitted the Spark job
- Total Uptime: This shows the total uptime for the jobs
- Scheduling Mode: In most cases, it is first-in-first-out (aka FIFO)
- Active Jobs: This shows the number of active jobs
- Completed Jobs: This shows the number of completed jobs
- Event Timeline: This shows the timeline of a job that has completed its execution
Internally, the Jobs tab is represented by the JobsTab class, which is a custom SparkUI tab with the jobs prefix. The Jobs tab uses JobProgressListener to access statistics about the Spark jobs to display the above information on the page. Take a look at the following screenshot:
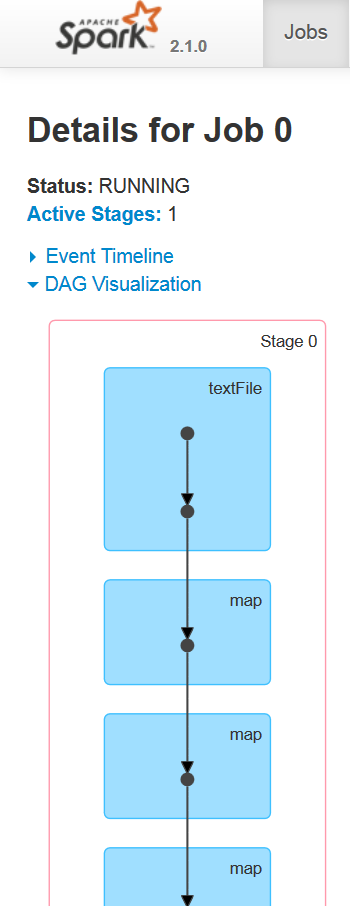
If you further expand the Active Jobs option in the Jobs tab, you will be able to see the execution plan, status, number of completed stages, and the job ID of that particular job as DAG Visualization, as shown in the following:
When a user enters the code in the Spark console (for example, Spark shell or using Spark submit), Spark Core creates an operator graph. This is basically what happens when a user executes an action (for example, reduce, collect, count, first, take, countByKey, saveAsTextFile) or transformation (for example, map, flatMap, filter, mapPartitions, sample, union, intersection, distinct) on an RDD (which are immutable objects) at a particular node.
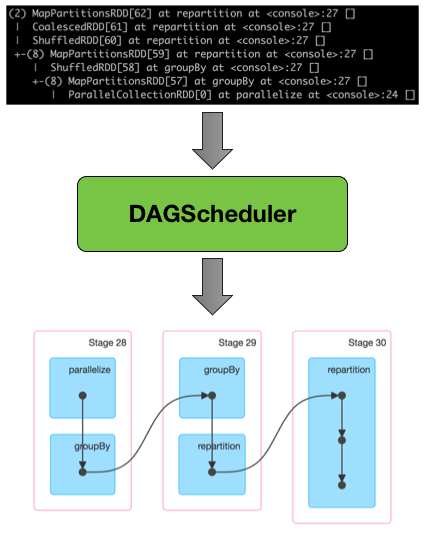
During the transformation or action, Directed Acyclic Graph (DAG) information is used to restore the node to last transformation and actions (refer to Figure 4 and Figure 5 for a clearer picture) to maintain the data resiliency. Finally, the graph is submitted to a DAG scheduler.
At a high level, when any action is called on the RDD, Spark creates the DAG and submits it to the DAG scheduler. The DAG scheduler divides operators into stages of tasks. A stage comprises tasks based on partitions of the input data. The DAG scheduler pipelines operators together. For example, many map operators can be scheduled in a single stage. The final result of a DAG scheduler is a set of stages. The stages are passed on to the task scheduler. The task scheduler launches tasks through the cluster manager (Spark Standalone/YARN/Mesos). The task scheduler doesn't know about the dependencies of the stages. The worker executes the tasks on the stage.
The DAG scheduler then keeps track of which RDDs the stage outputs materialized from. It then finds a minimal schedule to run jobs and divides the related operators into stages of tasks. Based on partitions of the input data, a stage comprises multiple tasks. Then, operators are pipelined together with the DAG scheduler. Practically, more than one map or reduce operator (for example) can be scheduled in a single stage.
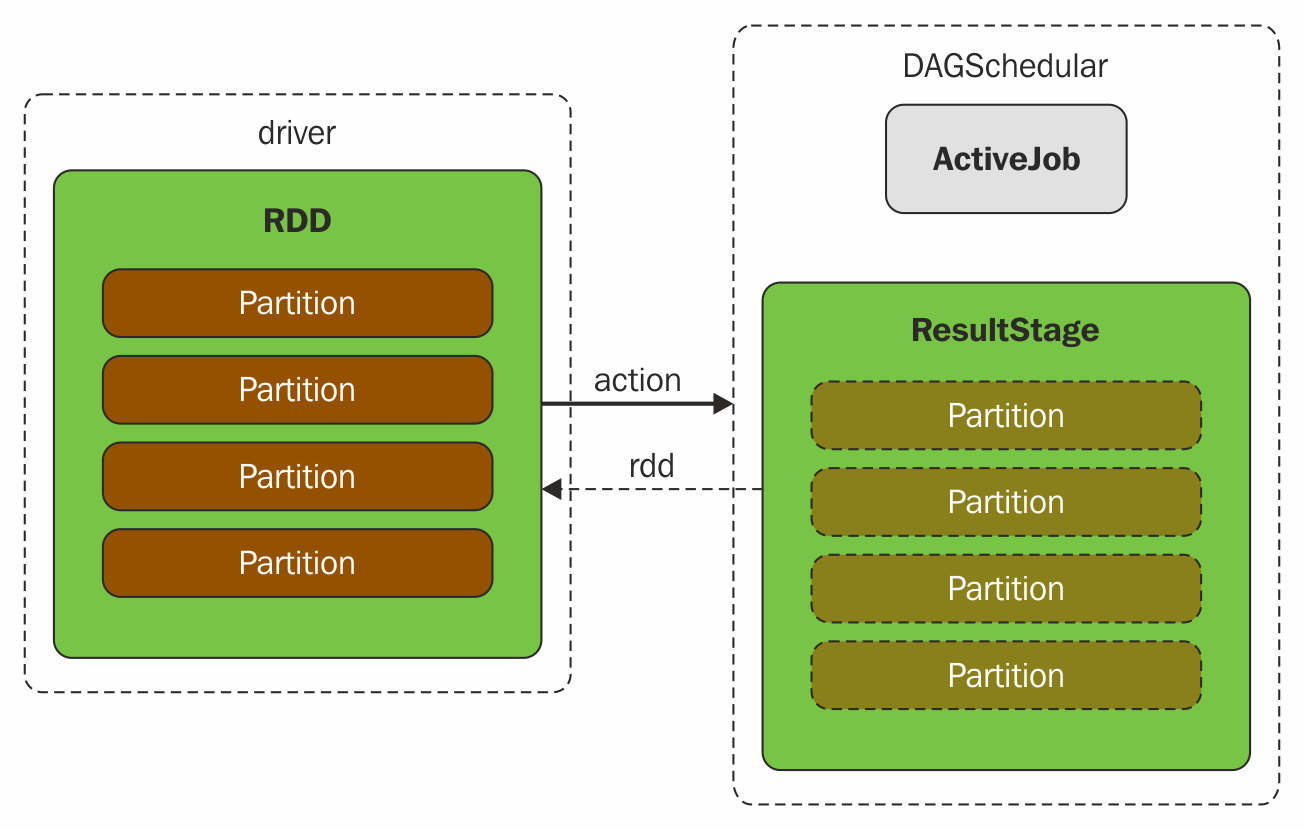
Two fundamental concepts in DAG scheduler are jobs and stages. Thus, it has to track them through internal registries and counters. Technically speaking, DAG scheduler is a part of SparkContext's initialization that works exclusively on the driver (immediately after the task scheduler and scheduler backend are ready). DAG scheduler is responsible for three major tasks in Spark execution. It computes an execution DAG, that is, DAG of stages, for a job. It determines the preferred node to run each task on and handles failures due to shuffle output files being lost.
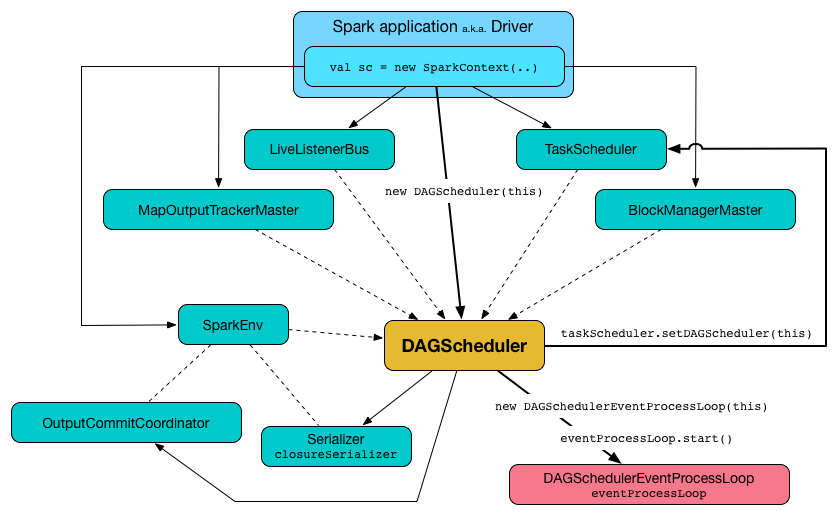
The final result of a DAG scheduler is a set of stages. Therefore, most of the statistics and the status of the job can be seen using this visualization, for example, execution plan, status, number of completed stages, and the job ID of that particular job.