
CountVectorizer and CountVectorizerModel aim to help convert a collection of text documents to vectors of token counts. When the prior dictionary is not available, CountVectorizer can be used as an estimator to extract the vocabulary and generates a CountVectorizerModel. The model produces sparse representations for the documents over the vocabulary, which can then be passed to other algorithms such LDA.
Suppose we have the text corpus as follows:
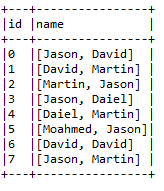
Now, if we want to convert the preceding collection of texts to vectors of token counts, Spark provides the CountVectorizer () API for doing so. First, let's create a simple DataFrame for the earlier table, as follows:
val df = spark.createDataFrame(
Seq((0, Array("Jason", "David")),
(1, Array("David", "Martin")),
(2, Array("Martin", "Jason")),
(3, Array("Jason", "Daiel")),
(4, Array("Daiel", "Martin")),
(5, Array("Moahmed", "Jason")),
(6, Array("David", "David")),
(7, Array("Jason", "Martin")))).toDF("id", "name")
df.show(false)
In many cases, you can set the input column with setInputCol. Let's look at an example of it and let's fit a CountVectorizerModel object from the corpus, as follows:
val cvModel: CountVectorizerModel = new CountVectorizer()
.setInputCol("name")
.setOutputCol("features")
.setVocabSize(3)
.setMinDF(2)
.fit(df)
Now let's downstream the vectorizer using the extractor, as follows:
val feature = cvModel.transform(df)
spark.stop()
Now let's check to make sure it works properly:
feature.show(false)
The preceding line of code produces the following output:

Now let's move to the feature transformers. One of the most important transformers is the tokenizer, which is frequently used in the machine learning task for handling categorical data. We will see how to work with this transformer in the next section.