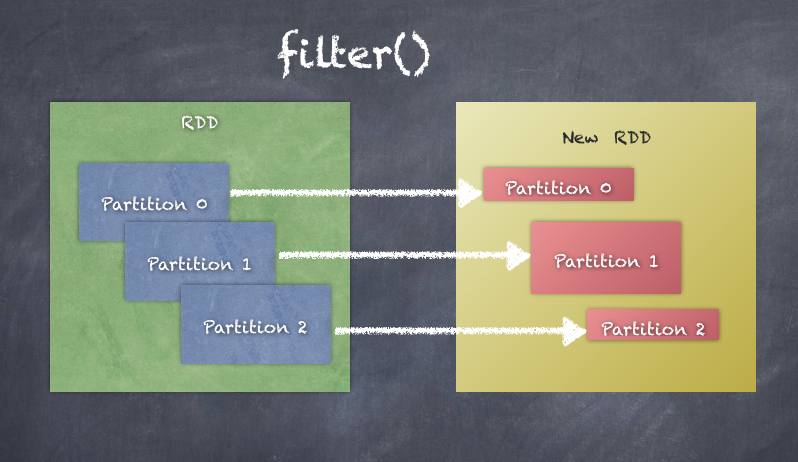
filter applies transformation function to input partitions to generate filtered output partitions in the output RDD.
The following snippet shows how we can filter an RDD of a text file to an RDD with only lines containing the word Spark:
scala> val rdd_two = sc.textFile("wiki1.txt")
rdd_two: org.apache.spark.rdd.RDD[String] = wiki1.txt MapPartitionsRDD[8] at textFile at <console>:24
scala> rdd_two.count
res6: Long = 9
scala> rdd_two.first
res7: String = Apache Spark provides programmers with an application programming interface centered on a data structure called the resilient distributed dataset (RDD), a read-only multiset of data items distributed over a cluster of machines, that is maintained in a fault-tolerant way.
scala> val rdd_three = rdd_two.filter(line => line.contains("Spark"))
rdd_three: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[20] at filter at <console>:26
scala>rdd_three.count
res20: Long = 5
The following diagram explains how filter works. You can see that each partition of the RDD results in a new partition in a new RDD, essentially applying the filter transformation on all elements of the RDD.
Note that the partitions do not change, and some partitions could be empty too, when applying filter