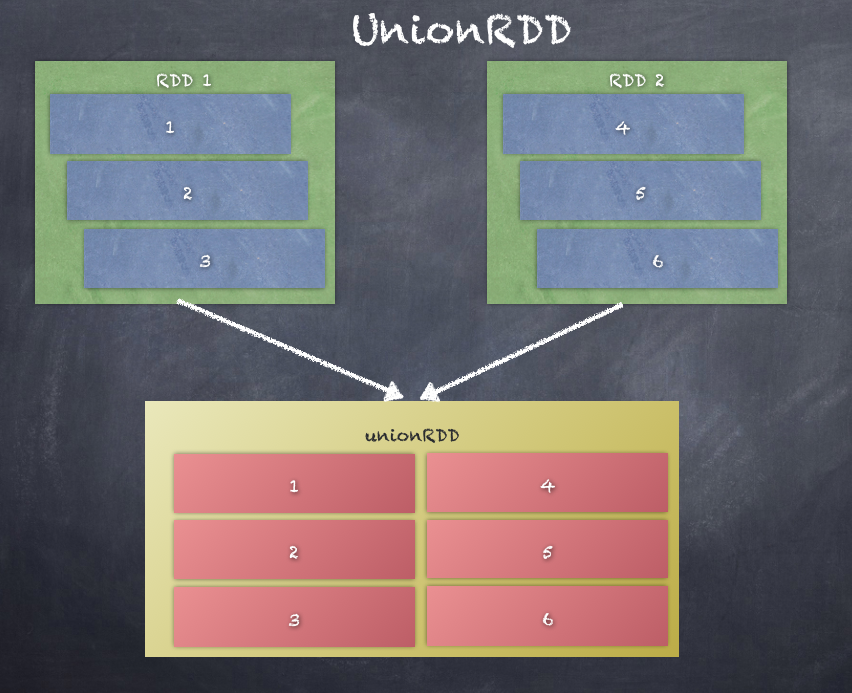
UnionRDD is the result of a union operation of two RDDs. Union simply creates an RDD with elements from both RDDs as shown in the following code snippet:
class UnionRDD[T: ClassTag]( sc: SparkContext, var rdds: Seq[RDD[T]]) extends RDD[T](sc, Nil)
The following code snippet is the API call to create a UnionRDD by combining the elements of the two RDDs:
scala> val rdd_one = sc.parallelize(Seq(1,2,3))
rdd_one: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[85] at parallelize at <console>:25
scala> val rdd_two = sc.parallelize(Seq(4,5,6))
rdd_two: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[86] at parallelize at <console>:25
scala> val rdd_one = sc.parallelize(Seq(1,2,3))
rdd_one: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[87] at parallelize at <console>:25
scala> rdd_one.take(10)
res103: Array[Int] = Array(1, 2, 3)
scala> val rdd_two = sc.parallelize(Seq(4,5,6))
rdd_two: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[88] at parallelize at <console>:25
scala> rdd_two.take(10)
res104: Array[Int] = Array(4, 5, 6)
scala> val unionRDD = rdd_one.union(rdd_two)
unionRDD: org.apache.spark.rdd.RDD[Int] = UnionRDD[89] at union at <console>:29
scala> unionRDD.take(10)
res105: Array[Int] = Array(1, 2, 3, 4, 5, 6)
The following diagram is an illustration of a union of two RDDs where the elements from both RDD 1 and RDD 2 are combined into a new RDD UnionRDD: