
Chapter 6
Locking and Concurrency
WHAT’S IN THIS CHAPTER?
- ACID: the properties of transactions worth protecting
- Avoiding concurrency dangers with locks
- Lock resources and modes
- A look at how lock escalation works
- A brief description of deadlocks
- Understanding how isolation levels affect locking behavior
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
The wrox.com code downloads for this chapter are found at www.wrox.com/remtitle.cgi?isbn=1118177657 on the Download Code tab. The code is in the Chapter 6 download and individually named according to the names within the chapter.
OVERVIEW
Tommy Cooper, the late great comic magician, did a trick in which he put two handkerchiefs, one white and one blue, into a bag. He said a magic word, pulled them out again, and then stated that the white one had turned blue, and the blue one had turned white. It’s an excellent trick, though perhaps misunderstood, because the audience gets the impression that no change has occurred at all, and that he is simply pretending that the colors have swapped.
All joking aside, when you put something into a database, you have a certain level of expectation. You want to be assured that any data that has been entered can be retrieved in the same state, notwithstanding another process coming along and explicitly changing or deleting it. You don’t want any magic to wreak havoc while you’re looking the other way. In short, you want your transaction to be protected.
This is a challenge that transactional database vendors have, which is investigated both in this chapter and in Chapter 7. It’s something that database users (and by “users” I include database administrators, database developers, database architects and designers — anyone who uses a database in any way) take for granted. Having become so accustomed to the way that a database works, various things are now simply expected, just as you expect a letter to appear when you press a key on your computer keyboard, oblivious to the complex programming by software developers that makes it possible. When writing programs using very low-level languages, developers still need to consider those types of things, but for all the other developers, there is a lot that can be taken for granted.
Nonetheless, the concepts used to protect your data should be understood. After all, you need to allow many processes to access your databases at once, and therefore need to appreciate the difference between having some “magic” occur that has unexpected results, and controlling the behavior that occurs when multiple processes want to act on the same pieces of data. Nothing should give a database user the impression of magic, and the power of concurrency — coordinating multiple processes — should be appreciated and leveraged.
Protecting data from unexpected results is achieved through a system of locks and latches. Latches, which protect memory, are explained further in Chapter 7. This chapter is dedicated to locks, and how you can use them to provide a level of protection to the transactions in your system. You will look at what they are designed to preserve, how they do it, and the various options available for consideration. You will also look at the plusses and minuses of locking, and see how locks can be leveraged for your benefit. The point of this scrutiny is to enable as many processes as possible accessing the data.
Scalability continues to drive computing technology; and as your systems demand increasingly heavy workloads, locks become increasingly important also.
TRANSACTIONS
Just to ensure that we’re all on the same page, let’s quickly review what we’re talking about when we discuss transactions. The most common analogy used to understand database transactions is the bank transaction. Beginning with the deposit, suppose you take $50 to the counter, resulting in a credit transaction in that amount to your account. When you look at your account statement when it arrives, you expect the transaction record to reflect that you deposited $50, not $48 or $52, depending on any fees or charges that might apply. This expectation actually stems from four aspects of transactions that have been identified by experts and that should be protected: atomicity, consistency, isolation, and durability, which form the neat acronym ACID. The following sections first examine these in the context of the bank transaction, and then you will revisit them in the context of your database.
A Is for Atomic
Atomic means indivisible — in this case, a collection of events being treated as a single unit. When you take your money to the bank and deposit it, you expect the transaction to be completed successfully. That is, you don’t expect the teller to accept your money and then go to lunch, forgetting to credit your account. That kind of behavior would obviously ruin a bank; and when we revisit atomicity in the context of the database, you’ll see that it would also ruin a database.
C Is for Consistent
Consistent means that everything is in agreement — in this case, the amount deposited is the amount credited. If you access a list of your recent transactions, the $50 that you deposited on Monday must be recorded as $50 on Monday, not $48 on Monday, not $52 on Tuesday, or any other combination of incorrect data. In other words, it is imperative that your records match the bank’s records. Although you may feel personally slighted or ignored at the bank, or the teller may not remember you between visits, you need to feel confident that the bank can successfully process your transactions such that they are completed in a consistent manner.
I Is for Isolated
Banks understand discretion. If you are going through your dealings with a teller, you don’t expect someone to be listening to the conversation and potentially making decisions based on what’s going on. Isolation is the protection provided around the visibility of what’s going on during each stage of the transaction, and extends out to whether your transaction can be affected by anything else that might be going on at the same time. Importantly, there are different levels of isolation that can be chosen.
For example, if your spouse is in another branch making a separate transaction, you might be okay with that branch seeing some information about your transaction part way through it, but you almost certainly wouldn’t want to see a bank statement issued that only gave half the story.
D Is for Durable
Durability reflects the fact that your bank transaction cannot be accidentally deleted or otherwise compromised. After you deposit your money and receive a receipt, you are assured that your money is safe and available to you. Even in the event of system failure, the record of the fact that you deposited money should persist, no matter what happens next.
DATABASE TRANSACTIONS
Having looked at the ACID principles in the context of a bank transaction in the preceding section, this section examines how these four principles relate to your database environment, which you need to protect with just as much care as the bank affords to your monetary transactions.
Atomicity
When you make a change in the database that involves multiple operations, such as modifying two separate tables, if you have identified these operations as a single transaction, then you expect an all-or-nothing result — that is, the change is completely atomic. Recall from the bank analogy that depositing $50 must result in an additional $50 in your account. If the bank’s server freezes or the teller’s terminal stops working, then you expect your personal data to remain unchanged. In a database, locks help to achieve this, by ensuring that a transaction has exclusive access to anything that is being changed, so that it is either committed or rolled back completely. Anything short of that would break this very basic property of transactions.
Consistency
Databases enforce logic in many different ways. When a change is attempted, it can’t be allowed to occur until the system is satisfied that no rules are going to be broken. For example, suppose you remove a value from a table but there are foreign keys referring to that column. The system must verify that these kinds of associations are handled before it can agree to that change; but in order to perform those checks and potentially roll them back if something has gone wrong, locks are needed. For another example, it should be impossible to delete a row while something else is being inserted in another table that relies on it.
Isolation
When the database engine inserts values into a table, nothing else should be able to change those values at the same time. Similarly, if the database engine needs to roll back to a previous state, nothing else should have affected that state or left it indeterminate. In other words, each action must happen in isolation from all others.
In terms of what other users see when they look at a transaction, or the data that is being considered, that’s the domain of the isolation level, which is examined in much more detail later in this chapter. This concept of isolation is very important to understand, as you can exercise a lot of control over the environment.
Durability
Even if a failure occurs a split-second after your transaction has taken place, you need to be sure that the transaction has been persisted in the database. This is achieved through one of the most significant aspects of SQL Server — the behavior of the transaction log.
Most experienced database administrators have had to salvage MDF files, where the databases’ data is stored, from a failed server, only to find that the MDF files alone do not provide enough information to recover the databases completely. Ideally, this situation prompts the DBA to learn why, after which they understand that MDF files without the accompanying LDF files (the transaction log) do not reflect the whole story.
That’s because the transaction log is not like many of the other logs on a Windows server, such as the Windows Event Log. Those logs record information about what’s going on, but only in order to provide a report of what has happened — typically for troubleshooting purposes. The SQL Server transaction log is much more than this.
When a transaction takes place, it is recorded in the transaction log. Everything that the transaction is doing is recorded there, while the changes to the actual data are occurring in memory. Once the transaction is complete and a commit command is sent, the changes are hardened, which is done in the transaction log. Locks are released at this point (as shown later in this chapter), but the record of the transaction appears in the transaction log files, rather than the data files. The data files are updated later. For the time being, the change exists in memory (where processes can access the updated data) and in the transaction log. Changes to the data files happen shortly afterward, when a separate CHECKPOINT operation takes place. Until then, the MDF files do not contain the current version of the database — for that, the MDF and LDF files are both needed.
Therefore, the durability of a transaction is provided by the existence and preservation of the database’s transaction log. Database administrators protect their transaction logs above anything else; because in the event of a failure, the transaction log is the only record of the latest database changes.
For a minimally logged operation, the behavior is slightly different, and the transaction log contains only sufficient information to be able to commit or rollback the transaction fully; but the transaction log still performs a vital role in ensuring that transactions are durable.
THE DANGERS OF CONCURRENCY
Before tackling the subject of locks, it is important to understand concurrency. Database concurrency ensures that when multiple operations are occurring at once, the final result is still in agreement — that they concur. This agreement typically depends on a set of rules and constraints that coordinate the behaviors of transactions, making sure that different operations will play nicely together.
Having considered the attributes of your transactions that you need to protect, the following sections consider the types of things that can happen if you let transactions have a free-for-all environment — one where all the different transactions don’t regard each other’s boundaries, where isolation is completely ignored. Later, you’ll look at the various isolation levels in more detail, but in this section if you look closely you’ll often see the isolation level is set in the scripts.
The problems described next only occur when multiple sessions are occurring at once in your database. This is typical behavior, I’m sure, but it’s worth noting that in a single-session environment, these problems won’t happen.
Lost Updates
A lost update occurs when two processes read the same data and then try to update the data with a different value. Consider a scenario in which you and your partner have the romantic notion of a joint bank account. On pay day, your respective employers both deposit your salaries into the joint account. To perform the update, each process reads the data. At the time of the payments, all is well in the world and you have an outstanding balance of $10,000. Each process therefore reads $10,000 as its starting point. Your employer attempts to update the $10,000 figure with your monthly salary of $2,000, but at the same time your partner’s employer updates the sum with his or her salary of $4,000. Your partner’s salary is added just before yours, updating the $10,000 balance to $14,000. Your payment then runs and updates the $10,000 balance to $12,000. A look at the ATM shows $12,000. The first update has been lost, and even worse, it represented the bigger update!
This situation is one that the SQL Server platform handles automatically, regardless of the isolation level. However, database developers can introduce this behavior themselves by performing an update in two steps, rather than one. Consider this example (code file Ch6LostUpdates.sql):
/* SESSION 1*/
USE AdventureWorks2012;
DECLARE @SafetyStockLevel int = 0
,@Uplift int = 5;
BEGIN TRAN;
SELECT @SafetyStockLevel = SafetyStockLevel
FROM Production.Product
WHERE ProductID = 1;
SET @SafetyStockLevel = @SafetyStockLevel = @Uplift;
WAITFOR DELAY '00:00:05.000';
UPDATE Production.Product
SET SafetyStockLevel = @SafetyStockLevel
WHERE ProductID = 1;
SELECT SafetyStockLevel
FROM Production.Product
WHERE ProductID = 1;
COMMIT TRAN;Does it look OK? The developer has wrapped the read and the write in an explicit transaction, but all this scenario needs is for some concurrent activity and a lost update will occur. The WAITFOR is only present to make it easier to detonate the code. In a separate session, have the following code ready:
/* SESSION 2*/
USE AdventureWorks2012;
DECLARE @SafetyStockLevel int = 0
,@Uplift int = 100;
BEGIN TRAN;
SELECT @SafetyStockLevel = SafetyStockLevel
FROM Production.Product
WHERE ProductID = 1;
SET @SafetyStockLevel = @SafetyStockLevel + @Uplift;
UPDATE Production.Product
SET SafetyStockLevel = @SafetyStockLevel
WHERE ProductID = 1;
SELECT SafetyStockLevel
FROM Production.Product
WHERE ProductID = 1;
COMMIT TRAN;Now run Session 1; and then as soon as you have executed it, click over to Session 2 and execute that code. Session 2 should come back almost immediately showing that the transaction has raised the safety stock level from 1,000 to 1,100 (see Figure 6-1). If you return to Session 1, you should now be able to see that this transaction has also completed, except that the Safety Stock Level has gone from 1,000 to 1,005 (see Figure 6-2). The design of the transaction is flawed, causing an update to be lost.
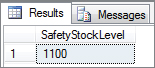

What caused this loss? The developer wrote the transaction in such a way that both sessions are able to read the data and store the stock level in a variable. Consequently, when the update is made, both transactions start with the same value. This is a situation that should be avoided through more careful coding. Even raising the isolation level does not resolve this particular problem, which should be addressed by performing the addition as part of the update operation, as shown here:
UPDATE Production.Product
SET SafetyStockLevel += @Uplift
WHERE ProductID = 1;We know you are all too smart to code your transactions in a way that could allow lost updates, but it does show what can happen when insufficient consideration is given to the transaction design. Interestingly, SQL Server enables the syntax to support this behavior using the NOLOCK hint, although it is largely ignored.
Dirty Reads
A dirty read takes no notice of any lock taken by another process. The read is officially “dirty” when it reads data that is uncommitted. This can become problematic if the uncommitted transaction fails or for some other reason is rolled back.
Imagine a scenario in which you are shopping on a website and place an item into your basket and proceed to payment. The site’s checkout process decrements the stock by one and starts to charge your card all in the one transaction. At that time, a second unrelated process starts. The website’s back office stock interface runs and makes a dirty read of all the product inventory levels, reading the reduced value. Unfortunately, there is a problem with your transaction (insufficient funds), and your purchase transaction is rolled back. The website stock level has now reverted to the original level, but the stock interface has just reported a different value.
You can run the following example against the AdventureWorks2012 database. Session 1 starts an explicit transaction to update all persons with a last name of “Jones” to have the same first name of “James.” This transaction will be rolled back after five seconds, and a SELECT is run to show the original values (code file Ch6DirtyReads.sql):
/* SESSION 1 */
USE AdventureWorks2012;
BEGIN TRANSACTION;
UPDATE Person.Person
SET FirstName = 'James'
WHERE LastName = 'Jones';
WAITFOR DELAY '00:00:05.000';
ROLLBACK TRANSACTION;
SELECT FirstName
,LastName
FROM Person.Person
WHERE LastName = 'Jones';Once Session 1 is running, quickly switch over to a second session and execute the following SQL statement. The SQL in this second session will perform a dirty read. If you time it right and execute this query while the transaction in Session 1 is open (it has not yet been rolled back), then your output will match Figure 6-3 and every person with a surname of “Jones” now has a first name of “James”:
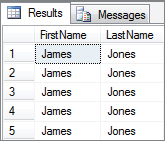
/* SESSION 2 */
USE AdventureWorks2012;
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT FirstName
,LastName
FROM Person.Person
WHERE LastName = 'Jones';Non-Repeatable Reads
A non-repeatable read is one in which data read twice inside the same transaction cannot be guaranteed to contain the same value. This very behavior was discussed when looking at transactions earlier in the chapter. Depending on the isolation level, another transaction could have nipped in and updated the value between the two reads.
Non-repeatable reads occur because at lower isolation levels reading data only locks the data for the duration of the read, rather than for the duration of the transaction. Sometimes this behavior might be completely desirable. Some applications may want to know the absolute, real-time value, even mid transaction, whereas other types of transactions might need to read the same value multiple times.
Consider the following example. In Session 1 the transaction reads the data for the top five people from Person.Person and then waits for five seconds before repeating the step. Execute the code in Session 1 before flipping to a second session and executing the code in Session 2 (code file Ch6NonRepeatableReads.sql):
/*SESSION 1*/
USE AdventureWorks2012;
SET TRANSACTION ISOLATION LEVEL
READ COMMITTED;
--REPEATABLE READ;
BEGIN TRANSACTION;
SELECT TOP 5
FirstName
,MiddleName
,LastName
,Suffix
FROM Person.Person
ORDER BY LastName;
WAITFOR DELAY '00:00:05.000';
SELECT TOP 5
FirstName
,MiddleName
,LastName
,Suffix
FROM Person.Person
ORDER BY LastName;
COMMIT TRANSACTION;
/*SESSION 2*/
USE AdventureWorks2012;
BEGIN TRANSACTION;
UPDATE Person.Person
SET Suffix = 'Junior'
WHERE LastName = 'Abbas'
AND FirstName = 'Syed';
COMMIT TRANSACTION;
/*
UPDATE Person.Person
SET Suffix = NULL
WHERE LastName = 'Abbas'
AND FirstName = 'Syed';
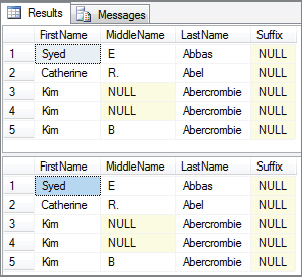
*/Providing you execute the update in Session 2 in time, your results will match Figure 6-4. The first read from Session 1, Syed Abbas, had no suffix; but in the second read he’s now Syed Abbas Junior. The first read, therefore, hasn’t been repeatable.

You can use the commented-out code in Session 2 to reset the data. Execute this code now. To get a repeatable read, change the transaction isolation level in Session 1 as indicated here:
SET TRANSACTION ISOLATION LEVEL
--READ COMMITTED;
REPEATABLE READ;Now rerun Session 1 and Session 2 as before. You should notice that Session 2 has been blocked from performing its update until after the transaction has been completed. The first read in Session 1 is now repeatable. Your results from Session 1 should now match those in Figure 6-5.

Phantom Reads
Phantom reads occur when a row is inserted into or deleted from a range of data by one transaction that is being read by another set of data. Recall the earlier work queue scenario. Suppose a user reads the work queue searching for new work items and gets back 10 records. Another user inserts a new work order. Shortly afterward, the first user refreshes the list of new work orders. There are now 11. This additional row is a phantom row.
Often this outcome is desirable. In cases when you need to be able to rely on the range of data previously read, however, it is not. The following example uses the Person.Person table to demonstrate a phantom (code file Ch6PhantomReads.sql):
/*SESSION 1*/
USE AdventureWorks2012;
SET TRANSACTION ISOLATION LEVEL
READ COMMITTED;
--SERIALIZABLE;
BEGIN TRANSACTION;
SELECT TOP 5
FirstName
,MiddleName
,LastName
,Suffix
FROM Person.Person
ORDER BY LastName;
WAITFOR DELAY '00:00:05.000';
SELECT TOP 5
FirstName
,MiddleName
,LastName
,Suffix
FROM Person.Person
ORDER BY LastName;
COMMIT TRANSACTION;In Session 1 the transaction is again going to read the top five people from the Person.Person table twice in relatively quick succession. Session 2, however, inserts a new person who meets the criteria in the results of the query.
/*SESSION 2*/
USE AdventureWorks2012;
BEGIN TRANSACTION;
INSERT INTO [Person].[BusinessEntity]
([rowguid]
,[ModifiedDate])
VALUES
(NEWID()
,CURRENT_TIMESTAMP);
DECLARE @Scope_Identity int;
SELECT @Scope_Identity = SCOPE_IDENTITY();
INSERT INTO [Person].[Person]
([BusinessEntityID]
,[PersonType]
,[NameStyle]
,[Title]
,[FirstName]
,[MiddleName]
,[LastName]
,[Suffix]
,[EmailPromotion]
,[AdditionalContactInfo]
,[Demographics]
,[rowguid]
,[ModifiedDate])
VALUES
(@Scope_Identity
,'EM'
,'0'
,'Mr.'
,'James'
,'Anthony'
,'A'
,Null
,0
,Null
,Null
,NEWID()
,CURRENT_TIMESTAMP
);
EXEC SP_EXECUTESQL
N'PRINT ''DELETE FROM Person.Person WHERE BusinessEntityID = '' +CAST(@Scope_
Identity as varchar(8));
PRINT ''DELETE FROM Person.BusinessEntity WHERE BusinessEntityID = ''
+CAST(@Scope_Identity as varchar(8));'
,N'@Scope_Identity int',@Scope_Identity = @Scope_Identity
SELECT @Scope_Identity as BusinessEntityID
COMMIT TRANSACTION;Run Session 1 now before switching over and executing Session 2. You should see in the results of the first query from Session 1 (see Figure 6-6) that Syed Abbas is the first person of five returned.
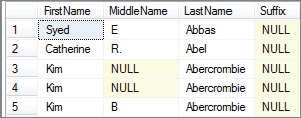
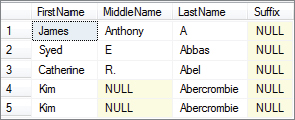
However, in the result of the second query from Session 1 (see Figure 6-7) James Anthony A is now first. James Anthony A is a phantom.
To demonstrate how phantoms can be prevented, first remove James Anthony A from the table. If you revert to Session 2 and look in your message tab, you should see two delete statements (see Figure 6-8 for details).
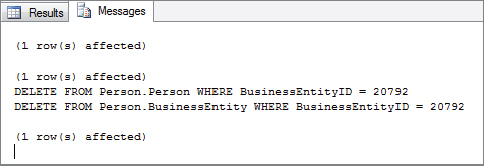
Copy those two rows into a new window and execute them.
In Session 1, change the transaction isolation level from read committed to serializable, and repeat the example by running the code in Session 1 first, followed by that in Session 2:
SET TRANSACTION ISOLATION LEVEL
--READ COMMITTED;
SERIALIZABLE;This time the results for selects one and two from Session 1 are the same, as shown in Figure 6-9. Note that the insert from Session 2 still happened, but only after the transaction in Session 1 had been committed.
Don’t forget to remove James Anthony A from your AdventureWorks2012 database before continuing by repeating the steps just outlined.
Double Reads
Double reads can occur when scanning data while using the default read committed isolation level, covered later in this chapter. During a period of concurrent activity, it is possible for one query to perform a range scan on a table and, as it is scanning, a second transaction can come in and move a row, thus causing it to be read twice. This can happen when the initial read during the range scan is not repeatable. The locks taken when reading data are by default released as soon as the data has been successfully read. Specific action is required to prevent this; you must increase the isolation level.
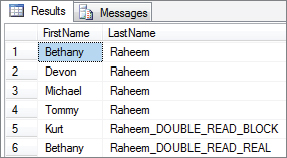
For example, the following code moves Bethany Raheem and so reads her record twice. There are only five Raheems in the AdventureWorks2012 database. However, in this example you will see six.
First, Session 1 creates a blocking update midway through the range scan of the Raheem data on a row that is further through the index than Bethany’s row (code file Ch6DoubleReads.sql):
/* SESSION 1 PART 1 */
Use AdventureWorks2012;
BEGIN TRAN
UPDATE Person.Person
SET LastName = 'Raheem_DOUBLE_READ_BLOCK'
WHERE LastName = 'Raheem'
AND FirstName = 'Kurt';Now Session 2 starts a scan to return all persons whose surname begins with Raheem. This query will scan the index and be blocked by the uncommitted update in Session 1:
/* SESSION 2 */
USE AdventureWorks2012;
SELECT FirstName
,LastName
FROM Person.Person
WHERE LastName Like 'Raheem%';Return to Session 1 and move Bethany Raheem, who has already been read, to a position in the index after the row being updated in Session 1:
/* SESSION 1 PART 2 */
UPDATE Person.Person
SET LastName = 'Raheem_DOUBLE_READ_REAL'
WHERE LastName = 'Raheem'
AND FirstName = 'Bethany';
COMMIT TRAN;The range scan query in Session 2 can now complete, and the results look like those in Figure 6-10.
Halloween Effect
The Halloween effect refers to a scenario in which data moves position within the result set and consequently could be changed multiple times. This effect is different from the double read because it is driven by data modification, rather than read queries.
In order to perform an update, the data must be read first. This is performed using two cursors: one for the read and the other for the write. If the data is updated by the write cursor before all the data was read in, then it is possible that a row will move position (courtesy of the update), potentially be read a second time, and consequently be updated again. In theory, this could go on forever. Reading the data using an index whose key is going to be updated by the query is an example of the Halloween effect.
This scenario is obviously highly undesirable, and thankfully the Storage Engine in SQL Server protects against it. As mentioned, SQL Server uses two cursors during an update: one to perform the read and another to perform the write. To ensure that the data available to the write has been read fully, SQL Server needs to inject a blocking operator such as a spool into the plan. It doesn’t have to be the spool, but this operator is commonly selected because it invariably has the lowest cost attached to it. That said, it still isn’t very efficient, as it means all the data has to be inserted into tempdb before it can be used by the write cursor. It does ensure that all the data is read before any modifications take place.
To achieve a greater level of efficiency, SQL Server actually looks out for the Halloween effect problem when creating the plan. It introduces the blocking operator only when there is a chance of the Halloween effect occurring. Even then it adds an extra one only if no blocking operator is already present in the plan performing this function.
In most update scenarios the index is used to locate data, and other non-key columns are updated in the table. You wouldn’t normally expect the key to be frequently updated as well, so being able to remove the blocking operator is an important optimization.
It is worth remembering the performance penalty of the Halloween effect when deciding on your indexing strategy. Perhaps that index you were thinking of adding isn’t such a great idea after all. When index or performance tuning, it is always worthwhile to keep an eye on the impact that your changes have on tempdb.
LOCKS
You’ve just read about blocking other users from seeing what’s going on, or jumping in with other changes that stop a transaction from being able to behave in proper isolation. The mechanism in SQL Server that is used for this is a lock. By locking a piece of data, SQL Server prevents access to it. As you might expect, there are a variety of lock types (known as lock modes), and a variety of types of access they are designed to prevent. A lock is needed for almost every kind of data access, even reads, which means that locks actually do their blocking against other lock types. We don’t say that an exclusive lock blocks reads; we say that an exclusive lock is incompatible with a shared lock — but the effect is the same. To picture the kind of blocking that will occur, imagine the kind of access that needs to take out the incompatible locks.
There are also many different types of things that can be locked. These are known as lock resources. By identifying what is locked, what caused it to be locked, and the type of lock that is taken out, you have the full set of information about the lock.
Monitoring Locks
Two main dynamic management views (DMVs) are used to monitor locks: sys.dm_tran_locks and sys.dm_os_wait_stats. The former lists all the locks that have currently been taken, and includes information identifying the lock resource and more, while the latter lists information about how often processes have had to wait when acquiring the various lock types.
The DMV sys.dm_tran_locks returns a lot of useful information about the locks currently held in the SQL Server instance. It shows not only the lock resource (as per the list of lock resources described next) and lock mode (also discussed later), but also the ID of the database in which the lock is located, plenty of information to identify the resource that has been locked, whether the lock was actually granted (it could be being converted, or it could be waiting), how many locks of that type are on the resource, the sessionid, and more.
There are a lot of columns, as described in Table 6-1.
TABLE 6-1: Currently Active Lock Resource Information Returned by sys.dm_tran_locks
| COLUMN NAME | DESCRIPTION |
| resource_type | The type of lock resource that a transaction is trying to take a lock on, such as OBJECT, PAGE, KEY, etc. |
| Resource_subtype | Provides a subclassification of the resource requested. Not mandatory, but good for qualifying the resource; for example, if you create a table in a transaction you will get a subtype of DDL on the DATABASE resource_type lock. |
| Resource_database_id | The database in which the resource was requested |
| Resource_description | Contains information describing the resource that isn’t available in any other column |
| Resource_associated_entity_id | Describes the entity upon which the lock is being requested. It can be one of three things depending on the resource type: Object ID, HoBT ID, or Allocation Unit ID. |
| Resource_lock_partition | Normally 0. Lock partitioning must be available to you in order to see anything in this column, and only available on machines with 16 cores presented. It applies only to object locks, and even then only to those without a resource_subtype. |
| Request_mode | The mode in which the lock is requested. If the lock has a status of granted, then this is the lock mode under which the resource is currently operating — for example, IX (Intent Exclusive), X (Exclusive), etc. |
| Request_type | This value is always LOCK because this view only supports locks. |
| Request_status | This is one of three values: |
| GRANT: The requested lock is in effect. | |
| WAIT: The lock is prevented from being acquired (blocked) because the resource is already locked with an incompatible locking mode. For instance one connection has a Grant X (Exclusive) lock on the object, and you are trying to also acquire an exclusive lock on the same object. | |
| CONVERT: The lock was previously granted with another status and is trying to upgrade to a more restrictive mode but is currently being blocked from doing so. | |
| Request_reference_count | An approximate count of the number of times that a requestor has requested a lock on the given resource |
| Request_session_id | In most cases this is the session that requested the resource. |
| Two special values: | |
| -2: A distributed transaction with no enlisted sessions | |
| -3: A deferred recovery transaction | |
| Request_exec_context_id | Execution context of the process that owns the request |
| Request_request_id | Batch ID of the request that owns the resource |
| Request_owner_type | The entity type of the owner of the request. Possible types are as follows: |
| TRANSACTION | |
| CURSOR | |
| SESSION | |
| SHARED_TRANSACTION_WORKSPACE | |
| EXCLUSIVE_TRANSACTION_WORKSPACE | |
| Request_owner_id | Used when the owner type is TRANSACTION and represents the transaction ID |
| Request_owner_guid | Used when the owner type is TRANSACTION and the request has been made by a distributed transaction. In that circumstance, the value equates to the MSDTC GUID for that transaction. |
| Lock_owner_address | Represents the in-memory address of the request. Use this column to join to the resource_address column in sys.dm_os_waiting_tasks to see blocking lock information. |
The DMV sys.dm_os_wait_stats shows the wait stats for the locks by their mode (the list of lock modes is shown later in this chapter), and you can see these in the wait_type column, with values such as LCK_M_IX for IX-locks, and LCK_M_S for S-locks. For each wait_type, the number of times waits have been required is shown, along with the total and maximum wait times and the total signal wait time. Using this DMV can highlight when the Database Engine must wait to acquire the various locks.
Lock Resources
Table 6-2 describes the many different types of things that can be locked, known as lock resources. It also gives an example of what each type of resource might look like.
TABLE 6-2: List of Lock Resources and Examples
| RESOURCE TYPE | EXAMPLE OF RESOURCE | DESCRIPTION |
| RID | 1:8185:4 | A row identifier used to lock a single row when the table in question is a heap |
| The RID format can be understood as: <File : Page : Slot ID> |
||
| The lock resource RID can be retrieved with the undocumented %%lockres%% function. | ||
| KEY | (3a01180ac47a) | A lock on a single row on an index. This includes row locks taken on tables that have a clustered index on them. The resource is a hash value that can be retrieved against your table with %%lockres%%. |
| PAGE | 1:19216 | A lock on an index or data page. Breaks down as <FILE ID>:<PAGE NUMBER>. |
| These map to the file_id and page_id fields in the sys.dm_os_buffer_descriptors DMV. | ||
| EXTENT | 1:19216 | A contiguous set of eight pages. Pages are allocated to tables in extents. Breaks down as <FILE ID> : <FIRST PAGE NO> |
| HoBT | 72057594058637312 | HoBT is a Heap or Balanced Tree (BTree). When a table is a heap (no clustered index), it protects the heap. Otherwise, it protects the BTree of the index. |
| OBJECT | 2105058535 | Normally a table lock but it could be anything with an OBJECT_ID. If it’s a table lock, then it covers both data pages and all indexes on the table. |
| APPLICATION | 0:[MyAppLock]: (6731eaf3) | An application lock. Set by sp_getapplock. |
| METADATA | xml_collection_id = 65536 | Used to lock SQL Server system metadata — e.g., when taking a schema stability lock on metadata of an XML column when querying a row. |
| ALLOCATION_UNIT | 72057594039828480 | Allocation Unit ID seen during deferred drop operations, such as on a large table. Also visible during minimally logged operations such as SELECT INTO. |
| FILE | 0 | Seen when adding or removing files from a database. No resource description information is published. |
| DATABASE | 7 | A lock against the entire database. This can be a shared transaction workspace lock to identify a connection in the DB or a transaction lock when altering the database. Changing from read_write to read_only requires an exclusive transaction against the database. |
You may look at this table with a degree of hope that your locks never end up too far down the list. It’s quite understandable and reasonable to expect that your normal querying behavior should be able to get away with just locking rows, pages, and occasionally a whole HoBT; but remember that a single object’s locks can cover many HoBT locks, which in turn, might cover thousands or millions of pages, and who knows how many rows. A trade-off must be made between having a smaller number of locks with more data locked than strictly necessary and having less data locked with a larger number of locks.
Lock escalation occurs when a number of locks are converted into a smaller number of locks at levels further down that list (typically to the object level) — that is, making the trade-off to reduce the number of locks through coarser granularity. This can be beneficial in that it reduces the amount of overhead to manage the locks; but of course with more data locked, there is a higher likelihood of processes being blocked by encountering locked data. Details about how this escalation occurs are covered later in the chapter, after the lock modes and compatibility between the lock modes have been considered. For now, be aware of the kinds of things that can be locked.
Lock Modes
Data in a database is not like a book, which can only be in the possession of one person at a time. If you are reading a book, the book is in your hands and other people can’t read it. Data is more like a notice on a board. You and other people can read it at the same time. However, if you want to change it, then you need to take the notice down off the board, and no one else can change it at the same time. Whether or not they can read it while it is being changed is a separate matter (the isolation level), but this scenario is related to the concept of lock modes, and the compatibility matrix between them, as described in the following sections.
Shared Lock Mode (S)
When a read request for a row of data is made by a task, by default, SQL Server will request a lock in shared mode. Shared mode is compatible with most other locks, as it is only permitted to read the row on the data page.
Update Lock Mode (U)
Update mode is a special kind of lock. It is used when searching data during a data modification request. The process is straightforward: SQL Server uses the update lock by locating the data and then preventing others from updating it. It prevents other requests from modifying the data by virtue of the update lock’s compatibility with other locks. Any other requests wishing to lock the resource with an update or exclusive lock are forced to wait. However, in order to effect the data modification, the update lock must be converted to an exclusive lock. As the update lock has blocked all other data modification locks, all it needs to do is wait until it can get an exclusive lock when the last, if any, shared locks have been released. This allows for greater concurrency in the system as opposed to all writers just taking exclusive locks. If the latter were the case, then blocking would be a much greater problem. Concurrent queries would be blocked for the entire duration of the update (the read part and the write) as opposed to just the write.
Exclusive Lock Mode (X)
Exclusive locks are used for data modification via INSERT, UPDATE, and DELETE statements. In terms of compatibility, exclusive locks are not compatible with any other kind of lock, including other exclusive locks. All locks must wait for the exclusive lock to be released before they can proceed; provided your solution isn’t using dirty reads and therefore bypassing the lock entirely. As mentioned earlier, exclusive locks are held until the end of the transaction, whether that is by commit or rollback.
Schema Lock Modes (Sch-S), (Sch-M)
There are actually two types of schema lock mode: schema modification (Sch-M) and schema stability (Sch-S). These locks are taken by different processes but basically boil down to the same thing. A query takes a schema-modification lock when it wants to change the schema in some way. Schema stability is designed to block schema modification if needed. For example, when a stored procedure is compiled, a schema-stability lock is taken to ensure that no one changes the table during the compilation process. Alternatively, a schema-modification lock is taken when altering a table, as you have seen, but also when performing partition switching. In this case, a Sch-M is taken on both the source and the target.
Intent Lock Modes (IS), (IU), (IX)
As shown previously in the discussion of lock granularity, SQL Server can grant locks at various levels or degrees of granularity. These levels are used to form a hierarchy within SQL Server. A row is at the bottom of this hierarchy and belongs to a page; the page itself belongs to a table, and so on. The lock hierarchy is covered in detail in the next section, but the purpose of the intent lock is to indicate at the higher levels of the lock hierarchy that a part of the resource has a lock held against it. This allows checks to be performed at the level at which a lock is requested, which is a great performance optimization.
If an exclusive row lock is acquired on a table, the page and the table will have intent exclusive locks held against them. Consequently, if another process wants to take out a table lock, it can check at the table level, see that there is an intent exclusive lock present, and know it is blocked without having to scan the entire table looking for conflicting locks.
Intent locks shouldn’t be considered as locks in the same vein as a shared, update, or exclusive lock. They act as indicators to SQL Server, pointing out that an actual lock has been acquired at a lower level in that hierarchy for that resource.
Consider an ALTER TABLE statement, which needs to be executed when no other users are trying to run queries against the table. If the table changed during the query, this would be very bad news indeed. However, it would also be a massive pain to check the locks for every row of the table to determine whether any are being read or modified. Instead, a table-level check takes place, which indicates immediately in a single request whether any other activity is occurring in the table.
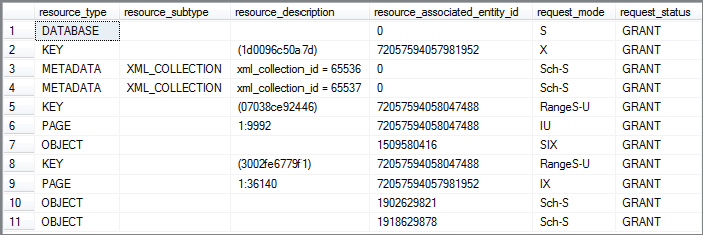
Try this for yourself. In Session 1, run the following code (code file Ch6IntentLockModes.sql):
USE AdventureWorks2012;
/* SESSION 1 */
BEGIN TRANSACTION;
UPDATE Production.Product
SET SafetyStockLevel = SafetyStockLevel
WHERE ProductID =1;
--ROLLBACK TRAN;
SELECT resource_type
,resource_subtype
,resource_description
,resource_associated_entity_id
,request_mode
,request_status
FROM sys.dm_tran_locks
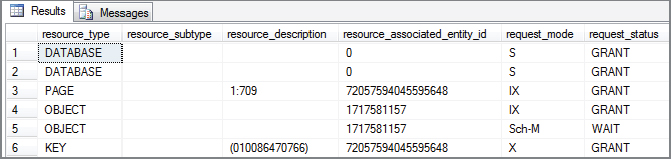
WHERE request_session_id = @@spid;Note the intent locks (request_mode is IX) on page and object in Figure 6-11. Now try to run this ALTER TABLE statement in another query window:

USE AdventureWorks2012;
/* SESSION 2 */
BEGIN TRANSACTION;
ALTER TABLE Production.Product
ADD TESTCOLUMN INT NULL;
--ROLLBACK TRANSACTION;The ALTER TABLE statement should be blocked. How do you know this? First, it will take forever to make that change, as the explicit transaction in Session 1 hasn’t been closed. However, more important, look at row 5 in the output shown in Figure 6-12 (the query for sys.dm_tran_locks has been rerun in the Session 1 window but also includes the SPID used for Session 2). Note that the request_mode contains a schema modify lock, and that the request_status is set to WAIT. This means it is on the wait list, which ties back to the fact that it is blocked. Finally, look at the resource_type. It’s an object resource request. The database engine checks for the existence of an object resource_type for the same resource_associated_entity_id as the one requested. Because one exists, the ALTER TABLE cannot proceed.
You might want to roll back those transactions now to release the locks.
Conversion Lock Modes (SIX), (SIU), (UIX)
SQL Server also provides the facility to convert shared, update, or exclusive locks to shared with intent exclusive (SIX), shared with intent update (SIU), or update with intent exclusive (UIX). This happens when a statement inside a transaction already holds a lock at a coarse granularity (a table) but now needs to modify a component of the resource held at a much finer granularity (a row). The lock held against the coarse granularity needs to reflect this.
Consider the following example of a SIX lock (code file Ch6ConversionLockModes.sql):
USE AdventureWorks2012;
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
SELECT BusinessEntityID
,FirstName
,MiddleName
,LastName
,Suffix
FROM Person.Person;
SELECT resource_type
,resource_subtype
,resource_description
,resource_associated_entity_id
,request_mode
,request_status
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID;
UPDATE Person.Person
SET Suffix = 'Junior'
WHERE FirstName = 'Syed'
AND LastName = 'Abbas';
SELECT resource_type
,resource_subtype
,resource_description
,resource_associated_entity_id
,request_mode
,request_status
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID;
ROLLBACK TRANSACTION;A transaction has selected all rows from the Person.Person table. This generates a table-level shared lock, as shown in Figure 6-13.

The transaction continues through to update a single row. This triggers the need to convert the table-level shared lock to a SIX lock as the row must be exclusively locked. Figure 6-14 clearly shows that the row is locked with an exclusive KEY lock, but also that the table/object has converted its lock from shared (S) to shared with intent exclusive (SIX).
Bulk Update Lock Mode (BU)
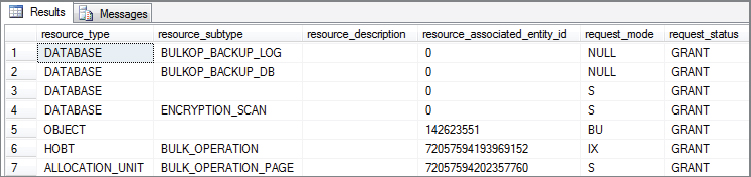
Bulk Update first appeared in SQL Server 2005. It is designed to allow multiple table-level locks on a single heap while using the Bulk API. This is important for parallel loading in data warehousing. However, in order to see it, you need to be loading into a heap and you must have specified a Tablock on the target table. The Tablock is a hint to say you’ll take a table lock, but SQL Server sees that the Bulk API is making the assertion. So a BU lock is issued instead. Because multiple BU locks are permitted on the same table, you are therefore empowered to perform parallel loading into the heap, as each loader will take its own compatible BU lock. Note that dirty reads are also permitted against the target table.
The following SQL code example is using the BULK INSERT statement to load into a replica heap of the dbo.factinternetsales table. Notice that a Tablock hint has also been used. You can see the BU lock that is issued as a result in Figure 6-15 by querying sys.dm_tran_locks in a separate session as before. You’ll have to be quick though! The sample data files contain only 60,398 rows (code file Ch6BulkUpdateLockMode.sql).
USE AdventureWorksDW2012;
CREATE TABLE [dbo].[TestFactInternetSales](
[ProductKey] [int] NOT NULL,
[OrderDateKey] [int] NOT NULL,
[DueDateKey] [int] NOT NULL,
[ShipDateKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[SalesTerritoryKey] [int] NOT NULL,
[SalesOrderNumber] [nvarchar](20) NOT NULL,
[SalesOrderLineNumber] [tinyint] NOT NULL,
[RevisionNumber] [tinyint] NOT NULL,
[OrderQuantity] [smallint] NOT NULL,
[UnitPrice] [money] NOT NULL,
[ExtendedAmount] [money] NOT NULL,
[UnitPriceDiscountPct] [float] NOT NULL,
[DiscountAmount] [float] NOT NULL,
[ProductStandardCost] [money] NOT NULL,
[TotalProductCost] [money] NOT NULL,
[SalesAmount] [money] NOT NULL,
[TaxAmt] [money] NOT NULL,
[Freight] [money] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) NULL,
[CustomerPONumber] [nvarchar](25) NULL) ON [PRIMARY];
BULK INSERT dbo.TestFactInternetSales
FROM 'C:factinternetsales.txt'
WITH (TABLOCK
,FORMATFILE = 'C:formatFIS.txt'
);
/* SESSION 2 */
SELECT resource_type
,resource_subtype
,resource_description
,resource_associated_entity_id
,request_mode
,request_status
FROM sys.dm_tran_locks
where request_session_id = <insert your session spid here,int, 0>Compatibility Matrix
Having looked at the list of lock modes that SQL Server uses, this section considers which of these are compatible with each other — that is, which locks prevent other locks from being taken out, and which ones are allowed. Two matrices of compatibility are shown — the first is explained, and the second one you can use for reference. Table 6-3 illustrates the first matrix.
TABLE 6-3: Sample Matrix of Compatibility
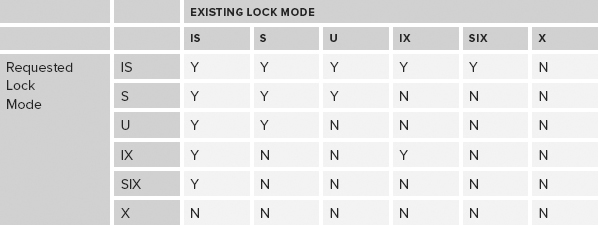
First, note the symmetry of this matrix. The labels “Existing Lock Mode” and “Requested Lock Mode” could be swapped without any of the Ys or Ns changing. The fact that a shared lock is incompatible with an intent exclusive lock is true whichever one is taken out first.
Next, look at the compatibility of the exclusive lock mode, the row and column marked with an X. Remember that this is the lock mode used when data is actually being modified. It’s not compatible with any other lock modes. Therefore, if data is being modified, no other process can do anything with that data. It can’t read it, and it definitely can’t change it.
At the other end of the matrix, you can see that the intent shared lock mode is compatible with everything except the exclusive lock. This is the lock that is used on index pages and index objects, where a shared lock has been taken out at a more granular level. There is no problem taking out a lock of this type unless the resource itself is being changed. An intent exclusive lock is fine though — so if a single page of a table is locked with an exclusive lock, causing an object intent exclusive lock on the table/index itself, then a different part of the table can still be read. An intent shared lock can be taken out on the object despite the existence of the intent exclusive lock.
An intent exclusive doesn’t prevent another intent exclusive lock from being taken out — two parts of a table can be changed at the same time without getting in each other’s way. However, if part of a table is being changed, a shared lock cannot be taken out (remember, we’re not talking about an intent shared lock).
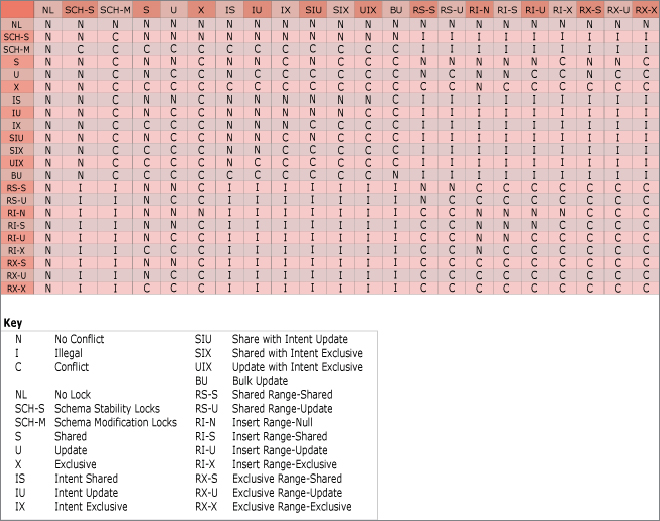
The complete compatibility matrix found in SQL Server Books Online is shown in Figure 6-16. Although it seems dauntingly complex, if you take the time to study it you’ll glean quite a bit of useful information.
LOCK ESCALATION
When more than 5,000 locks are taken out on the rows or pages of a particular table within a single T-SQL statement, lock escalation is triggered. During this process, the intent lock at the higher level is converted to a full lock — assuming this is possible and not prevented by other locks that may be already acquired — and then the locks at the more granular levels can be released, freeing up the resources needed to manage them.
As explained earlier, when a lock is taken out on a row or page, intent locks are taken out on the items higher up in the lock hierarchy — in particular, on the HoBTs and tables related to the locked row/page. In addition to providing a shortcut to determining whether something might be locking part of the table, these intent locks provide escalation points if the overhead of maintaining the locks becomes too high.
Escalation is to either the HoBT (for partitioned tables) or to the table itself (which is more typical). A page lock is not considered an escalation point — probably because by the time 5,000 locks are taken out, quite a large number of pages are locked, and a full table lock is a sensible solution to be able to reduce the number of locks.
If escalation can’t occur, the more granular locks can’t be released, and everything continues as before, with locks being taken out at the more granular points. This is typically because of other activity occurring in the affected table. Escalation will be attempted each time another 1,250 locks are acquired.
Lock escalation can be prevented by setting a table option to disallow it, or by forcing queries to take out table locks to start with. Ideally, you should let the system escalate locks as required, and only consider this kind of action when the number of escalations (monitored through Lock:Escalation events) becomes significantly higher than expected (compared to a benchmark of your system in a healthy state). You can also use trace flags (1211 and 1224) to disable lock escalation.
DEADLOCKS
Ideally, despite locks, your database system will allow a lot of users at once, and each transaction will get in, make the single change needed, and get out again; but locks inevitably mean blocking, and when transactions need to do multiple operations, this locking can even lead to deadlocks.
Although your application users will report that the application has deadlocked, this kind of behavior does not actually mean a deadlock has occurred. When a deadlock has been detected, the Database Engine terminates one of the threads, resolving the deadlock. The terminated thread gets a 1205 error, which conveniently suggests how to resolve it:
Error 1205 : Transaction (Process ID) was deadlocked on resources with another
process and has been chosen as the deadlock victim. Rerun the transaction.Indeed, rerunning the transaction is often the best course of action here, and hopefully your application or even your stored procedure will have caught the error, recognized that it is a 1205, and tried the transaction again. Let’s consider how a deadlock occurs, though.
It’s quite straightforward really — one transaction locks a resource and then tries to acquire a lock on another resource but is blocked by another transaction. It won’t be able to finish its transaction until such time as this second transaction completes and therefore releases its locks. However, if the second transaction does something that needs to wait for the first transaction, they’ll end up waiting forever. Luckily this is detected by the Database Engine, and one of the processes is terminated.
When diagnosing these kinds of problems, it’s worth considering that there are useful trace events such as Lock:Deadlock and Deadlock graph events. This enables you to see which combination of resources was being requested, and hopefully track down the cause. In most cases, the best option is to help the system get the quickest access to the resources that need updating. The quicker a transaction can release its resources, the less likely it is to cause a deadlock. However, another option is to lock up additional resources so that no two transactions are likely to overlap. Depending on the situation, a hint to lock an entire table can sometimes help by not letting another transaction acquire locks on parts of the table, although this can also cause blocking that results in transactions overlapping, so your mileage may vary.
ISOLATION LEVELS
Isolation levels determine how much transactions can see into other transactions, and can range from not-at-all to plenty. Understanding what the isolation levels do so that you can see how they prevent the concurrency side-effects described earlier can help you find an appropriate compromise between locking down too much and providing the necessary protection for your environment.
Many people misunderstand isolation levels. You may have seen large amounts of database code out there that use the NOLOCK hint, for example. To help combat this, you could find ways to educate people about isolation levels. Kendra Little has drawn a poster about them, shown in Figure 6-17. (You can find all her posters at www.littlekendra.com/sqlserverposters.) It could hang on a wall and serve as a conversation piece — people will ask you about it, providing an opportunity to talk to them about isolation levels.
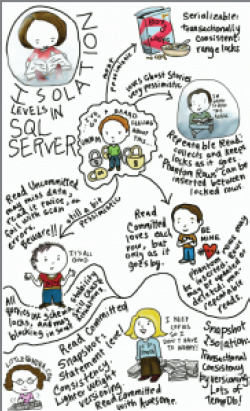
Kendra’s poster highlights the pessimism/optimism balance between the various isolation levels. There are four pessimistic isolation levels, and two optimistic ones. The optimistic levels involve the creation of snapshot data to allow additional concurrency, rather than the pessimistic behavior of blocking.
The following sections first describe the pessimistic isolation levels, followed by the optimistic ones.
Serializable
The serializable isolation level is the most pessimistic isolation level in SQL Server. It exhibits none of the concurrency problems that were shown earlier in the chapter. It simply locks everything up to ensure that no side-effects can take place. It does this by taking out range locks, which appear in the larger of the two lock compatibility matrices. These locks ensure that the whole range of any data that has been queried during the transaction is preserved, including avoiding insertions, to avoid the problem of phantom reads. These range locks typically conflict with each other, much more so than intent locks, thereby keeping the isolation as its utmost level.
Range locks can be seen in the following code (code file Ch6IsolationLevels.sql) and in Figure 6-18:

USE AdventureWorks2012;
GO
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
SELECT BusinessEntityID
FROM Person.Person
where BusinessEntityID < 10;
SELECT resource_type
,resource_subtype
,resource_description
,resource_associated_entity_id
,request_mode
,request_status
FROM sys.dm_tran_locks
WHERE request_session_id = @@SPID;
ROLLBACK TRAN;Repeatable Read
This level is not as strict as serializable, and it does not take out range locks. However, this means that data can be inserted into a set in such a way that the phantom reads scenario can occur.
Shared (S) locks are taken out and not released until the end of the transaction, including intent shared locks going up the lock hierarchy. These can be easily demonstrated by running the same block of code shown for the serializable example, but using SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; instead of the first line. The results do not show range locks, but standard full locks instead (see Figure 6-19).
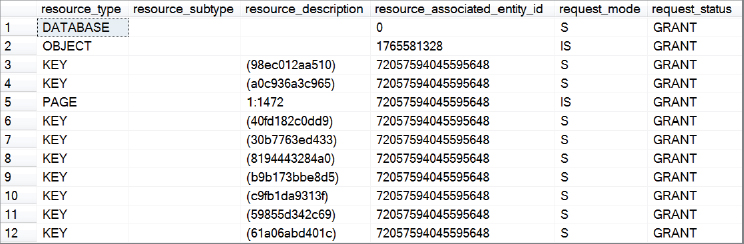
Read Committed
Read committed is the default locking behavior of SQL Server 2012. In this environment, shared locks are released after the particular read operation, but, as in the more pessimistic isolation levels, they are still blocked by exclusive locks. This isolation level can exhibit some of the concurrency issues that were described earlier; but with fewer locks being taken out, the behavior is often considered good enough for many environments. It is entirely possible to read a piece of data in the transaction and then read it again later in the transaction, only to find that another transaction has snuck in and removed or changed that data — a non-repeatable read, which as implied, is not possible in the repeatable read isolation level.
If SET TRANSACTION ISOLATION LEVEL READ COMMITTED; is substituted in the preceding example, then both the shared locks from the repeatable read isolation level and the range locks of the serializable level will be eliminated, leaving only the shared lock on the whole database. See Figure 6-20.
Read Uncommitted/NOLOCK
We mention the NOLOCK hint here because that is how many developers force the read uncommitted isolation level on their system. It is the least pessimistic isolation level, but it still is not classed as optimistic.
In the read uncommitted isolation level, shared (S) locks are not taken out at all. This also applies if the transaction is using a different isolation level but the NOLOCK hint is used. The upshot of this is the problem of dirty reads described earlier. Read transactions are not blocked by data with exclusive locks, but the data they read is of a potentially dubious value. Performance is increased, as without shared locks being acquired, there is no lock compatibility to be checked.
Note that some locks can still block reads in this isolation level — locks that stop anything getting near data, such as schema modification locks. The behavior of this isolation level has already been demonstrated as part of the dirty reads problem, so that code is not repeated here.
Snapshot
The optimistic snapshot isolation level is turned on using the command SET TRANSACTION ISOLATION LEVEL SNAPSHOT;. Before this can be done, however, the database must be configured to allow it, as shown here:
ALTER DATABASE AdventureWorks
SET ALLOW_SNAPSHOT_ISOLATION ON;After the snapshot isolation level is set, the database can perform the extra work required when a transaction starts, ensuring that for the length of that transaction, the entire database appears as it did at the start of it. This has an interesting effect on the locking required for reads — no locks are required.
This may sound useful, but every time data is changed, the previous copy of the data must be stored until every transaction that was active when the change was made has been completed (except its own transaction, which naturally sees the newer copy of the data). The data to support this behavior is kept in the tempdb database.
Read Committed Snapshot
This isolation level is similar to the snapshot isolation level, but it only provides statement-level read consistency. Therefore, the behavior feels more like the read committed isolation level, with the same drawbacks of read committed regarding non-repeatable reads and the like, but it doesn’t have the same blocking problems as read committed. When another transaction requests locked data using this isolation level, row versioning can provide a copy of it. However, the older versions of these rows are released when the transaction is over, thereby allowing more side-effects than are possible in the snapshot isolation level.
This last isolation level cannot be set using the SET TRANSACTION ISOLATION LEVEL command; it can only be set using the following:
ALTER DATABASE AdventureWorks
SET READ_COMMITTED_SNAPSHOT ON;SUMMARY
In this chapter you looked at how locking protects your transactions and why it is important. You have seen what can happen if concurrency is ignored completely, and the various ways that these negative consequences can be prevented. You’ve also seen how you can determine what is going on with the locks in your system, and you should now understand the types of things that can cause the various types of locks to be acquired.
With a good understanding of locks, a database administrator should be able to find strategies for minimizing their impact. As you use the information in this chapter to investigate the locking patterns in your database, you should be able to get a good picture of the locking that is happening within your system, and then devise strategies using isolation levels and even perhaps hints (which have been deliberately avoided in this chapter, as they should only be a last resort) to control what’s going on.
Finally, to return to the anecdote from the beginning of the chapter, Tommy Cooper’s magic should be celebrated and enjoyed. It shouldn’t cause you nightmares as you think of the problems you have with your database environment. Your “handkerchiefs” should only change color if you are expecting them to do that.