
Chapter 8
Knowing Tempdb
WHAT’S IN THIS CHAPTER?
- How SQL Server uses tempdb for internal and user-created temporary objects
- Avoiding and troubleshooting common tempdb issues
- How to monitor and tune tempdb performance
- Using configuration best practices to increase the performance and availability of tempdb
WROX.COM CODE DOWNLOADS FOR THIS CHAPTER
The wrox.com code downloads for this chapter are found at http://www.wrox.com/remtitle.cgi?isbn=1118177657 on the Download Code tab. The code is in the Chapter 8 download and individually named according to the names throughout the chapter.
INTRODUCTION
This chapter is about the system database called tempdb, which is used for storing temporary objects and has been a key component of SQL Server since its inception. Beginning with SQL Server 2005, however, the role of tempdb has been brought to the forefront with a plethora of new features and optimizations that depend on temporary objects.
All these features have increased the visibility and requirement for good tempdb performance, which is why we have dedicated a full chapter to a thorough grounding in what it is used for, how to troubleshoot issues, and how it should be configured.
The first section looks at what makes tempdb special, which SQL Server components use it, and specifically how it is used. The next section covers common issues and how to troubleshoot them, which sets the scene for the configuration recommendations that follow. Finally, you’ll find an especially useful best practices section at the end of the chapter.
OVERVIEW AND USAGE
You can think of tempdb as the “scratch” database for SQL Server; it’s a temporary data store used by both applications and internal operations. It is very similar to other databases in that it has a data file and a log file and can be found in SQL Server Management Studio, but it does have some unique characteristics that affect how you use and manage it.
The first fact to note is that everyone using an instance shares the same tempdb; you cannot have any more than one within an instance of SQL Server but you can get detailed information about who is doing what in tempdb using DMVs, which are discussed in the section on troubleshooting space issues later in the chapter.
The following features and attributes should be considered when learning about, using, tuning, and troubleshooting tempdb:
- Nothing stored in tempdb persists after a restart because tempdb is recreated every time SQL Server starts. This also has implications for the recovery of tempdb — namely, it doesn’t need to be done. See the following sidebar.
- Tempdb is always set to “Simple” recovery mode, which, if you remember from Chapter 1, means that transaction log records for committed transactions are marked for reuse after every checkpoint. This means you don’t need to back up the transaction log for tempdb, and in fact, you can’t back up tempdb at all.
- Tempdb can only have one filegroup (the PRIMARY filegroup); you can’t add more.
- Tempdb is used to store three types of objects: user objects, internal objects, and the version store.
User Temporary Objects
All the code in this section uses the Ch8_1TempDBTempObjects.sql code file.
To store data temporarily you can use local temporary tables, global temporary tables, or table variables, all of which are stored in tempdb (you can’t change where they’re stored). A local temporary table is defined by giving it a prefix of # and it is scoped to the session in which you created it. This means no one can see it; and when you disconnect, or your session is reset with connection pooling, the table is dropped. The following example creates a local temporary table, populates it with one row, and then selects from it:
CREATE TABLE #TempTable ( ID INT, NAME CHAR(3) ) ;
INSERT INTO #TempTable ( ID, NAME )
VALUES ( 1, 'abc' ) ;
GO
SELECT *
FROM #TempTable ;
GO
DROP TABLE #TempTable ;Global temporary tables can be seen by all sessions connected to the server and are defined by a prefix of ##. They are used in exactly the same way as local temporary tables, the only difference being that everyone can see them. They are not used very often because if you had a requirement for multiple users to use the same table, you’re more likely to implement a normal table in a user database, rather than a global temporary table. Here is exactly the same code just shown but implemented as a global temporary table:
CREATE TABLE ##TempTable ( ID INT, NAME CHAR(3) ) ;
INSERT INTO ##TempTable ( ID, NAME )
VALUES ( 1, 'abc' ) ;
GO
SELECT *
FROM ##TempTable ;
GO
DROP TABLE ##TempTable ;As you can see, the only difference is the prefix; both local temporary tables and global temporary tables are dropped when the session that created them is closed. This means it is not possible to create a global temporary table in one session, close the session, and then use it in another.
A table variable is used similarly to a local temporary table. The differences are explored in the next section. Here is the same sample again, this time implemented as a table variable:
DECLARE @TempTable TABLE ( ID INT, NAME CHAR(3) ) ;
INSERT INTO @TempTable ( ID, NAME )
VALUES ( 1, 'abc' ) ;
SELECT *
FROM @TempTable ;The syntax for declaring a table variable is slightly different from a temporary table; but a more important difference is that table variables are scoped to the batch, rather than the session. If you kept the GO batch delimiter as in the previous examples, then an “object does not exist” error would be raised for the last SELECT statement because the table variable would not exist in the scope of the statement.
Temp Tables vs. Table Variables
All the code in this section uses the Ch8_2TempTableAndTVStats.sql code file.
Having touched on the concept and scope of temporary tables and table variables in the previous section, the mechanism used to store temporary results usually boils down to the differences in features between a temporary table (#table) and a table variable.
Statistics
The major difference between temp tables and table variables is that statistics are not created on table variables. This has two major consequences, the first of which is that the Query Optimizer uses a fixed estimation for the number of rows in a table variable irrespective of the data it contains. Moreover, adding or removing data doesn’t change the estimation.
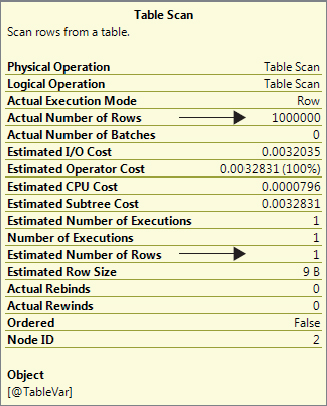
To illustrate this, executing the code below and looking at the properties of the table scan in the actual execution plan will give you the properties shown in Figure 8-1. To understand the example you need to first understand the Query Optimizer, statistics, and execution plans, which are covered in Chapter 1 and Chapter 5.
DECLARE @TableVar TABLE ( c1 INT ) ;
INSERT INTO @TableVar
SELECT TOP 1000000 row_number( ) OVER ( ORDER BY t1.number ) AS N
FROM master..spt_values t1
CROSS JOIN master..spt_values t2 ;
SELECT COUNT(*)
FROM @TableVar ;Note that the Query Optimizer based the plan on an estimation of one row being returned, whereas 1 million rows were actually returned when it was executed. Regardless of the number of rows in the table variable, the Query Optimizer will always estimate one row because it has no reliable statistics with which to generate a better estimation, and this could cause a bad execution plan to be used.
You can do the same test but with a temporary table instead by executing this code:
CREATE TABLE #TempTable ( c1 INT ) ;
INSERT INTO #TempTable
SELECT TOP 1000000 row_number( ) OVER ( ORDER BY t1.number ) AS N
FROM master..spt_values t1
CROSS JOIN master..spt_values t2 ;
SELECT COUNT(*)
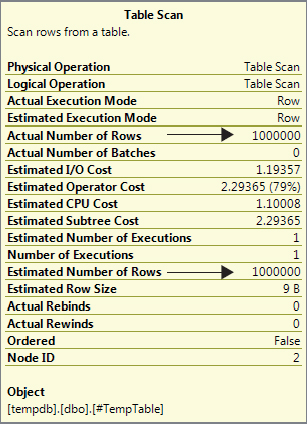
FROM #TempTable ;The properties for the table scan in this scenario are shown in Figure 8-2, which indicates an accurate row estimate of 1000000.
Indexes
You can’t create indexes on table variables although you can create constraints. This means that by creating primary keys or unique constraints, you can have indexes (as these are created to support constraints) on table variables.
Even if you have constraints, and therefore indexes that will have statistics, the indexes will not be used when the query is compiled because they won’t exist at compile time, nor will they cause recompilations.
Schema Modifications
Schema modifications are possible on temporary tables but not on table variables. Although schema modifications are possible on temporary tables, avoid using them because they cause recompilations of statements that use the tables.
Table 8-1 provides a brief summary of the differences between temporary tables and table variables.
TABLE 8-1: Temporary Tables versus Table Variables
| TEMPORARY TABLES | TABLE VARIABLES | |
| Statistics | Yes | No |
| Indexes | Yes | Only with constraints |
| Schema modifications | Yes | No |
| Available in child routines including sp_executesql | Yes | No |
| Use with INSERT INTO . . . EXEC | Yes | No |
| In memory structures | No | No |
SELECT session_id,
database_id,
user_objects_alloc_page_count
FROM sys.dm_db_session_space_usage
WHERE session_id > 50 ;CREATE TABLE #TempTable ( ID INT ) ;
INSERT INTO #TempTable ( ID )
VALUES ( 1 ) ;
GO
SELECT session_id,
database_id,
user_objects_alloc_page_count
FROM sys.dm_db_session_space_usage
WHERE session_id > 50 ;DECLARE @TempTable TABLE ( ID INT ) ;
INSERT INTO @TempTable ( ID )
VALUES ( 1 ) ;
GO
SELECT session_id,
database_id,
user_objects_alloc_page_count
FROM sys.dm_db_session_space_usage
WHERE session_id > 50 ;Whether or not you use temporary tables or table variables should be decided by thorough testing, but it’s best to lean towards temporary tables as the default because there are far fewer things that can go wrong.
I’ve seen customers develop code using table variables because they were dealing with a small amount of rows, and it was quicker than a temporary table, but a few years later there were hundreds of thousands of rows in the table variable and performance was terrible, so try and allow for some capacity planning when you make your decision!
Internal Temporary Objects
Internal temporary objects are objects used by SQL Server to store data temporarily during query processing. Operations such as sorts, spools, hash joins, and cursors all require space in tempdb to run. You can read more about query processing in Chapter 5.
To see how many pages have been allocated to internal objects for each session, look at the internal_object_alloc_page_count column in the sys.dm_db_session_space_usage DMV. You’ll find more details on looking at tempdb usage in the “Troubleshooting Common Issues” section later in the chapter.
The Version Store
Many features in SQL Server 2012 require multiple versions of rows to be maintained, and the version store is used to store these different versions of index and data rows. The following features make use of the version store:
- Triggers — These have used row versions since SQL Server 2005, rather than scan the transaction log as they did in SQL Server 2000.
- Snapshot Isolation and Read-Committed Snapshot Isolation — Two new isolation levels based on versioning of rows, rather than locking. You can read more about them in Chapter 6.
- Online Index Operations — Row versioning to support index updates during an index rebuild.
- MARS (Multiple Active Result Sets) — Row versioning to support interleaving multiple batch requests across a single connection. You can search SQL Server Books Online for more information on this.
Version Store Overhead
The overhead of row versioning is 14 bytes per row, which consists of a transaction sequence number referred to as an XSN and a row identifier referred to as a RID. You can see this illustrated in Figure 8-5.

The XSN is used to chain together multiple versions of the same row; the RID is used to locate the row version in tempdb.
The 14-byte overhead doesn’t reduce the maximum possible row size of 8,060 bytes, and it is added the first time a row is modified or inserted in the following circumstances:
- You’re using snapshot isolation.
- The underlying table has a trigger.
- You’re using MARS.
- An online index rebuild is running on the table.
It is removed in these circumstances:
- Snapshot isolation is switched off.
- The trigger is removed.
- You stop using MARS.
- An online index rebuild is completed.
You should also be aware that creating the additional 14 bytes could cause page splits if the data pages are full and will affect your disk space requirement.
Append-Only Stores
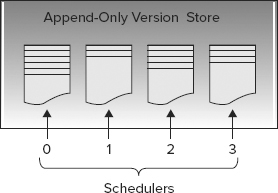
The row versions are written to an append-only store of which there are two; index rebuilds have their own version store and everything else uses the common version store. To increase scalability, each CPU scheduler has its own page in the version store to store rows, as illustrated in Figure 8-6 with a computer that has four CPU cores. See Chapter 5 for more information about CPU cores and schedulers.
You can view the entire contents of the version store using the sys.dm_tran_version_store DMV, but use it with care as it can be resource intensive to run.
For an example demonstrating how row versioning is used, Figure 8-7 illustrates an example of multiple read and write transactions operating under snapshot isolation.

Along the bottom of the diagram a timeline is represented from 0 to 60; the horizontal arrows represent the duration of a specific transaction. The sequence of events occurs like this:
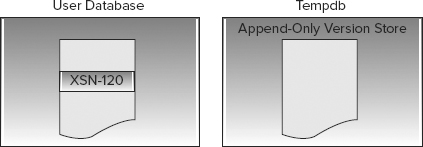
A background thread removes stale versions of rows from tempdb every minute, so at that point only the result of the write operation carried out by transaction Write2 will be stored and no previous versions will be available or stored in tempdb.
Figure 8-8 represents the state of the row on the data page and the versions stored in tempdb at timeline 0. You can see that the only available result is the currently committed value as of XSN-100.
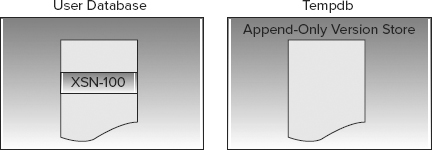
Figure 8-9 shows the state at timeline 45. Two versions are being maintained in tempdb to provide a repeatable read for the Read1, Read2, and Read3 transactions.
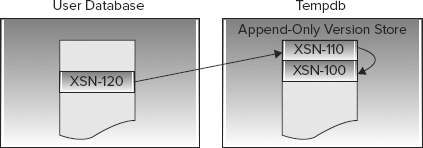
Figure 8-10 shows timeline 60. All transactions that required previous versions to maintain the snapshot isolation level have now completed, so the stale versions stored in tempdb have been cleaned up by a background thread.
TROUBLESHOOTING COMMON ISSUES
The unique nature of tempdb as a shared resource for temporary objects makes it more prone to specific performance problems than other databases. This section describes the most common issues that tempdb is vulnerable to and how to troubleshoot or even avoid them.
Latch Contention
Compared to a normal database, tempdb’s use as a temporary storage area makes the workload pattern likely to contain a disproportionate amount of the creation and destruction of many small objects. This type of workload can lead to latch contention on the pages required to allocate objects in a database.
If you’ve read Chapter 7 on latches, then you know that a latch is a short-term synchronization lock used by SQL Server to protect physical pages — it’s covered only briefly here for the sake of context.
You can’t influence latching behavior by changing the isolation level or by using “hints,” as you can with normal locks; latches are used automatically behind the scenes to protect pages in memory from being modified by another task while the content or structure is being changed or read from disk.
Allocation Pages
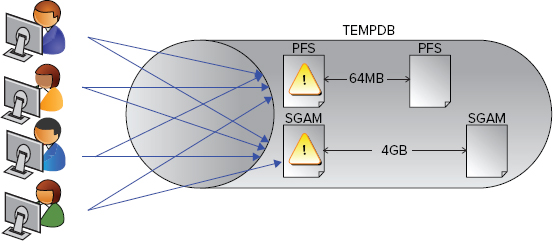
When you create an object such as a temporary table in tempdb, it needs to be allocated space in exactly the same way as creating a table in a normal database. You need to be aware of three pages in the allocation process: Page Free Space, Global Allocation Map, and Shared Global Allocation Map, all of which are covered in the following sections.
PFS (Page Free Space)
The PFS page stores 1 byte of information for each page, indicating how much free space is on it and what it’s used for, which means that a single PFS page can store information about roughly 64MB of pages. Therefore, you’ll find a new PFS page at close to 64MB intervals throughout a database data file.
The first page on any database data file is always a PFS page, so it’s easy to spot the page in an error message. If you see “2:1:1” anywhere, it’s referring to the first page on the first data file in database_id 2, which is tempdb; “5:3:1” would be the first PFS page in file_id 3 in database_id 5.
GAM (Global Allocation Map)
The GAM page tracks 1 bit per extent (an extent is eight pages), indicating which extents are in use and which are empty. SQL Server reads the page to find free space to allocate a full extent to an object.
Storing only 1 bit for each extent (instead of 1 byte per page like the PFS page) means that a single GAM page can track a lot more space, and you’ll find a new GAM page at roughly 4GB intervals in a data file. However, the first GAM page in a data file is always page number 2, so “2:1:2” would refer to the first GAM page in tempdb.
SGAM (Shared Global Allocation Map)
The SGAM page (pronounced ess-gam) also stores 1 bit per extent but the values represent whether the extent is a mixed extent with free space or a full extent. SQL Server reads this page to find a mixed extent with free space to allocate space to a small object.
A single SGAM can track 4GB of pages, so you’ll find them at 4GB intervals just like GAM pages. The first SGAM page in a data file is page 3, so “2:1:3” is tempdb’s first SGAM page.
Allocation Page Contention
Imagine that you take an action within an application that needs to create a temporary table. To determine where in tempdb to create your table, SQL Server will read the SGAM page (2:1:3) to find a mixed extent with free space to allocate to the table.
SQL Server takes out an exclusive latch (latches are covered in Chapter 7) on the SGAM page while it’s updating the page and then moves on to read the PFS page to find a free page within the extent to allocate to the object.
An exclusive latch will also be taken out on the PFS page to ensure that no one else can allocate the same data page, which is then released when the update is complete.
This is quite a simple process (but maybe not to explain) and it works very well until tempdb becomes overloaded with allocation requests. The threshold can be hard to predict and the next section describes several things you can do to proactively avoid it.
The issue itself manifests as a PAGELATCH wait, with 2:1:1 or 2:1:3 as the resource description. Figure 8-11 shows contention on the allocation pages because multiple users are trying to allocate many objects at the same time.
Allocation Page Contention: An Example
All the code in this section uses the Ch8_3TempdbContention.sql code file.
In order to demonstrate page contention I’ve created a couple of stored procedures and a table in an empty database called tempdbdemo. If you want to step through the example yourself, we have provided all the necessary steps and scripts in the associated code file.
-- Create stored procedure that creates a temp table, a clustered index and
populates with 10 rows
-- The script expects a database called tempdbdemo to exist
USE [tempdbdemo] ;
GO
CREATE PROCEDURE [dbo].[usp_temp_table]
AS
CREATE TABLE #tmpTable
(
c1 INT,
c2 INT,
c3 CHAR(5000)
) ;
CREATE UNIQUE CLUSTERED INDEX cix_c1 ON #tmptable ( c1 ) ;
DECLARE @i INT = 0 ;
WHILE ( @i < 10 )
BEGIN
INSERT INTO #tmpTable ( c1, c2, c3 )
VALUES ( @i, @i + 100, 'coeo' ) ;
SET @i += 1 ;
END ;
GO
-- Create stored procedure that runs usp_temp_table 50 times
CREATE PROCEDURE [dbo].[usp_loop_temp_table]
AS
SET nocount ON ;
DECLARE @i INT = 0 ;
WHILE ( @i < 100 )
BEGIN
EXEC tempdbdemo.dbo.usp_temp_table ;
SET @i += 1 ;
END ;The usp_temp_table stored procedure creates a table in tempdb with three columns and a unique clustered index on Column 1. The table is then populated with 10 rows. The usp_loop_temp_table stored procedure runs the usp_temp_table procedure 100 times.
To simulate multiple users trying to run the same procedure at the same time, I’m going to use a tool called OStress, which is part of a download called RML Utilities.
For the purpose of the demo I’m just going to use OStress very simply to run the usp_loop_temp_table procedure using 300 connections. The aim is to simulate 300 people running a stored procedure that recursively calls another stored procedure 100 times.
OStress needs to be run from the command prompt:
C:"Program FilesMicrosoft Corporation"RMLUtilsostress -SchristianvaioNTK12 -E
-Q"EXEC demo.dbo.usp_loop_temp_table;" -ooutput.txt -n300Of course, christianvaioNTK12 is my SQL Server instance name, so change it to your own if you’re following along.
While OStress is running, take a look at the sys.dm_os_waiting_tasks DMV using the following script, reproduced here with the kind permission of Robert Davis (http://www.sqlsoldier.com/wp/sqlserver/breakingdowntempdbcontentionpart2) :
WITH TASKS
AS (SELECT session_id,
wait_type,
wait_duration_ms,
blocking_session_id,
resource_description,
PageID = Cast(Right(resource_description, Len(resource_description)-
Charindex(':', resource_description, 3)) As Int)
From sys.dm_os_waiting_tasks
Where wait_type Like 'PAGE%LATCH_%'
And resource_description Like '2:%')
SELECT session_id,
wait_type,
wait_duration_ms,
blocking_session_id,
resource_description,
ResourceType = Case
When PageID = 1 Or PageID % 8088 = 0 Then 'Is PFS Page'
When PageID = 2 Or PageID % 511232 = 0 Then 'Is GAM Page'
When PageID = 3 Or (PageID − 1) % 511232 = 0 Then 'Is SGAM Page'
Else 'Is Not PFS, GAM, or SGAM page'
End
From Tasks ;The script is filtered on all PAGELATCH waits and shows you for each page whether or not it’s PFS, GAM, or SGAM. Most of the time when you have contention, it will be on the first allocation pages but this script is more thorough as it will detect any of these pages throughout the file.
You should see results similar to those shown in Figure 8-12.
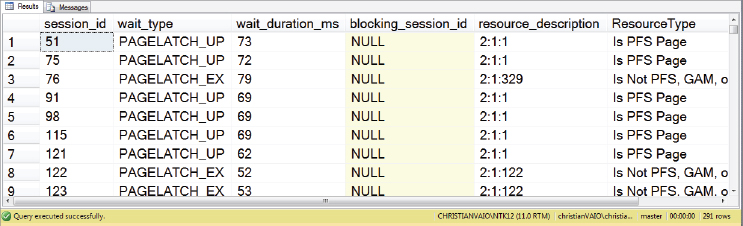
At the time this snapshot of sys.dm_os_waiting_tasks was taken, 291 tasks (from 300 connections) were waiting for a PAGELATCH, and you can see several examples of 2:1:1 (which is the PFS page), so there is evidence of allocation page contention.
Resolving and/or Avoiding Allocation Page Contention Problems
All the code in this section uses the Ch8_4TempDBContentionResolution.sql code file.
Once you’ve determined that you’re suffering from allocation page contention in tempdb (or even if you’re not sure), you have a few different ways to reduce the likelihood of it happening.
Multiple Tempdb Data Files
If you’re a DBA rather than a developer, you might be tempted to opt for this solution first. Recall that there is a set of allocation pages at the start of each data file, so if you have more than one file and can balance the load between them you’ll be less likely to get a hotspot on the allocation pages compared to a single file.
It’s a good best practice to have multiple tempdb files for your instance anyway because doing so is a simple, risk-free way of reducing the likelihood of contention occurring.
Tempdb works with multiple data files by using a proportional fill algorithm to try to balance the amount of free space across all the files. The effect of this is to favor the file with the most free space until it equals all the other files. This is a bad scenario if you’re trying to balance the allocation requests evenly across the files, so you need to ensure that all the tempdb data files are the same size. This is illustrated in Figure 8-13.

To determine whether simply adding more files can make a measurable difference to the contention example from the previous section, you can configure the server to have four equally sized tempdb data files. It’s not important for them to be on separate drives because you’re not doing it to improve I/O performance but simply to have more allocation pages.
You can modify the following the script for your own environment to configure the data files, which are all on the same disk.
ALTER DATABASE tempdb
MODIFY FILE (name=tempdev,size=512MB) ;
GO
ALTER DATABASE tempdb
ADD FILE (name=tempdev2,size=512MB,filename='D:data empdev2.ndf') ;
GO
ALTER DATABASE tempdb
ADD FILE (name=tempdev3,size=512MB,filename='D:data empdev3.ndf') ;
GO
ALTER DATABASE tempdb
ADD FILE (name=tempdev4,size=512MB,filename='D:data empdev4.ndf') ;Run through the demo again and see if it makes a difference. Try adding more and more files to see the effect.
Adding more files in this example will help reduce contention and will even remove it if you add enough files, but you can get easier gains by checking the code.
Temporary Object Reuse
This optimization is a little-known feature called temporary object reuse. If you’re a developer and you manage the code rather than the server, the first thing you’ll likely look at is optimizing the code, rather than reviewing server best practices. In most scenarios changing the code yields the best performance improvements anyway, so it’s not a bad starting approach.
Beginning with SQL Server 2005, it’s possible for SQL Server to cache temporary object definitions so that they can be reused if the same object needs to be created again. To be more specific, one IAM page (Index Allocation Map) and one extent are cached.
Objects that are reused don’t have to be allocated new space and therefore won’t contribute to any allocation problems. Optimizing your code to ensure that your temporary tables are being cached will help to reduce any potential problems.
SQL Server tries to cache temporary tables by default, so the first thing you need to check is whether or not SQL Server is caching yours. To do so, you can run your code in a loop and monitor the difference between the “temp table creation rate” Performance Monitor counter at the start and end of the loop. Fortunately, Sunil Agarwal from Microsoft has written a nice wrapper script that does it for us:
SET NOCOUNT ON ;
GO
DECLARE @table_counter_before_test BIGINT ;
SELECT @table_counter_before_test = cntr_value
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Temp Tables Creation Rate' ;
DECLARE @i INT = 0 ;
WHILE ( @i < 10 )
BEGIN
EXEC tempdbdemo.dbo.usp_loop_temp_table ;
SELECT @i += 1 ;
END ;
DECLARE @table_counter_after_test BIGINT ;
SELECT @table_counter_after_test = cntr_value
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Temp Tables Creation Rate' ;
PRINT 'Temp tables created during the test: '
+ CONVERT(VARCHAR(100), @table_counter_after_test
− @table_counter_before_test) ;To use the script yourself simply change the stored procedure name you want to test from usp_loop_test_table to whatever code you want.
If the code you want to test is complicated, you might want to set the loop iterations to 1 the first time you run this script just to be sure how many different temporary tables are created. Once you know that, you can set it back to 10 loop iterations as in the example.
The example code indicates that only one temporary table creation statement is called many times, so if the value returned from the above script is more than 1, then you can be confident that you’re not getting temporary object reuse.
Running the script provides the following result:
Temp tables created during the test: 1000During 10 executions, 1,000 temporary tables were created, so you can conclude that the table isn’t being cached (remember that the looping procedure executes the procedure creating the temp table 100 times, 10 * 100 = 1,000).
There’s obviously a problem in the example code somewhere, so what you need to determine now is under what circumstances SQL Server will cache temporary tables, so you know whether any changes can be made to the code.
Temporary objects will be cached as long as the following obtains:
- Named constraints are not created.
- DDL (Data Definition Language) statements that affect the table, such as CREATE INDEX or CREATE STATISTICS, are not run after the table has been created.
- The object is not created using dynamic SQL; using sp_executesql, for example.
- The object is created inside another object such as the following:
- Stored procedure
- Trigger
- User-defined function
- The return table of a user-defined table-valued function
If you look back at the code for usp_temp_table you’ll notice that a unique clustered index is created after the table definition, which breaks the rules for cached temporary objects:
CREATE UNIQUE CLUSTERED INDEX cix_c1 ON #tmptable ( c1 ) ;All is not lost, however, because you can utilize a constraint within the temporary table definition to achieve the same results without breaking the rules for temporary object caching. The next code listing shows the new definition with the old CREATE INDEX statement commented out.
USE [tempdbdemo] ;
GO
CREATE PROCEDURE [dbo].[usp_temp_table]
AS
CREATE TABLE #tmpTable
(
c1 INT UNIQUE CLUSTERED,
c2 INT,
c3 CHAR(5000)
) ;
--CREATE UNIQUE CLUSTERED INDEX cix_c1 ON #tmptable ( c1 ) ;
DECLARE @i INT = 0 ;
WHILE ( @i < 10 )
BEGIN
INSERT INTO #tmpTable ( c1, c2, c3 )
VALUES ( @i, @i + 100, 'coeo' ) ;
SET @i += 1 ;
END ;
GOHere, a unique clustered constraint has been added to the c1 column, which SQL Server will enforce internally by using a clustered index, so you can keep exactly the same functionality.
Testing the new stored procedure using the temporary table creation test now returns the following result:
Temp tables created during the test: 1The stored procedure has been successfully optimized for temporary object reuse, but what effect will it have on the allocation page contention example earlier in this chapter? Run through the workload again and see for yourself.
This example has shown you two ways to tackle a tempdb page contention issue: adding more data files and temporary object reuse. Taking advantage of temporary object reuse doesn’t remove the issue because of the large number of concurrent connections trying to use the object name, so adding additional tempdb data files is still required to balance the allocation requests.
Trace Flag 1118
This trace flag was introduced in SQL Server 2000 to help alleviate contention on the SGAM page (2:1:3) by disabling mixed extent allocations in all databases.
You might remember from earlier in the chapter that SGAM pages track mixed extents that have free space available. Every time you create a new table that’s not big enough to fill an extent (which happens a lot in tempdb), the SGAM page is read to find a mixed extent with enough free space to allocate to your table.
The effect of enabling this trace flag is that every object you create will be allocated its own extent (a uniform extent). The only downside to this is the extra disk space that’s needed because every table needs at least 64KB; although that’s unlikely to be an issue on most systems.
SQL Server 2008 introduced an improved algorithm for allocating space in mixed extents, so you’ll be unlikely to encounter this issue often if at all with SQL Server 2012.
Even though you’re unlikely to find SGAM contention in SQL Server 2012, trace flag 1118 still works exactly the same: It disables mixed extent allocations.
Monitoring Tempdb I/O Performance
Troubleshooting SQL Server implies a reactive activity; an issue has occurred that now needs to be fixed. That may be true but one of the differences that separates an average SQL Server professional from a good one is knowing about a problem before it has an impact on a live system.
You should be aware by now of tempdb’s importance to the overall health of an entire instance, so it shouldn’t be a hard sell to realize the benefits of being proactive and monitoring tempdb to get early warning of potential problems before they affect a production system. This section covers the specifics of monitoring tempdb I/O: What you should be looking at and what thresholds should prompt you to do something.
The speed at which requests to store and retrieve data are processed against tempdb is important to the overall performance of any SQL Server instance and can even be critical where tempdb is either heavily used or part of an important business process.
Whether you have tempdb on local storage or a SAN (storage area network), on a RAID10 volume or RAID1, the simplest way to check I/O system performance is to look at the latency of I/O requests. You’ll find a lot more detailed information about storage, including SANs, RAID levels, and benchmarking performance, in Chapter 4.
There are two methods for measuring disk latency: using Performance Monitor (see Chapter 10) and using SQL Server DMVs. Which one you should choose depends on how you want to monitor performance and how accurate you need it to be.
Performance Monitor
The PerfMon counters that you should be interested in are as follows:
- Avg. Disk sec/Transfer
- Avg. Disk sec/Read
- Avg. Disk sec/Write
You’ll find these grouped under Logical Disk, which shows the logical drives and drive letters presented in Windows as you would see them in Explorer; and Physical Disk, which shows the drives as Windows sees them internally. Which group you get the counters from won’t matter in most cases — I tend to use the Logical Disk counters because it’s easier to work with drive letters.
The counters themselves all provide the average latency in milliseconds for I/O requests. “Avg. Disk sec/Transfer” is the combined average for both reads and writes to a drive. This counter provides the simplest measurement for regular long-term monitoring.
“Avg. Disk sec/Read” and “Avg. Disk sec/Write” separate the requests into read and write measurements, respectively, that can be useful for determining how to configure disk controller cache (see Chapter 4). For example, if you’re seeing poor read performance and excellent write performance, you might want to optimize the cache for reads.
SQL Server DMVs
Monitoring the performance of a disk volume using Performance Monitor is a useful indicator of a potential storage performance issue, but you can get a further level of granularity from SQL Server itself. The following script (code file: Ch8_5ReadAndWriteLatency.sql) uses the sys.dm_io_virtual_file_stats DMV to calculate the read and write latency for all database files that have been used since the SQL Server service was last started.
SELECT DB_NAME(database_id) AS 'Database Name',
file_id,
io_stall_read_ms / num_of_reads AS 'Avg Read Transfer/ms',
io_stall_write_ms / num_of_writes AS 'Avg Write Transfer/ms'
FROM sys.dm_io_virtual_file_stats(-1, -1)
WHERE num_of_reads > 0
AND num_of_writes > 0 ;You can see part of the output from running the script on a busy production SQL Server in Figure 8-14. Tempdb has four data files with file_id’s 1, 3, 4, and 5, and a transaction log with file_id 2. All the data files have the same read and write latency, which is a positive indicator that the I/O is balanced across all the files, and all the results indicate good performance from tempdb.

Thresholds
Microsoft suggests the following performance thresholds for disk latency on drives containing SQL Server database files:
Database data files:
- Target: <10ms
- Acceptable: 10–20ms
- Unacceptable: >20ms
Database log files:
- Target: <5ms
- Acceptable: 5–15ms
- Unacceptable: >15ms
You should use these thresholds for guidance only because some systems will never be able to achieve the target latency. If you don’t have any performance issues with your application and you’re seeing latency of 20ms, then it’s not so important; but you can still look at Chapter 4 to see if there’s anything you can do to optimize your existing storage investment.
Using 20ms is a good rule of thumb target on most systems unless SQL Server is spending a lot of time waiting for I/O requests.
Troubleshooting Space Issues
All the code in this section uses the Ch8_6TempDBSpaceIssues.sql code file.
It was mentioned at the beginning of this chapter that all the databases on an instance have to share only one tempdb; this makes it even more important to understand who is doing what in tempdb, so Microsoft provides three DMVs to enable you to do just that.
sys.dm_db_file_space_usage
This DMV provides a view of the number and types of pages that are allocated in tempdb by file, allowing you to see the distribution of pages across your data files.
You can also use this DMV to total the values across all the files to get a single view of the breakdown of tempdb usage, which can help you narrow down the scope of the problem in the event of unexpected usage. Here is an example script for this:
SELECT SUM(total_page_count)*8/1024 AS 'tempdb size (MB)',
SUM(total_page_count) AS 'tempdb pages',
SUM(allocated_extent_page_count) AS 'in use pages',
SUM(user_object_reserved_page_count) AS 'user object pages',
SUM(internal_object_reserved_page_count) AS 'internal object pages',
SUM(mixed_extent_page_count) AS 'Total Mixed Extent Pages'
FROM sys.dm_db_file_space_usage ;Example results from the preceding script are shown in Figure 8-15. Note that user, internal and version pages are from uniform extents only.
sys.dm_db_task_space_usage
This DMV provides details of tempdb usage for currently running tasks. The values are set to 0 at the start of the task and deleted when the task completes, so it’s useful for troubleshooting live issues with currently executing tasks. For example, the following script will give you the top five sessions currently using space in tempdb, ordered by the total amount of space in use:
SELECT TOP 5 *
FROM sys.dm_db_task_space_usage
WHERE session_id > 50
ORDER BY user_objects_alloc_page_count + internal_objects_alloc_page_countsys.dm_db_session_space_usage
When a task completes, the values from sys.dm_db_task_usage are aggregated by session, and these aggregated values are viewable using sys.dm_db_session_space_usage.
The following example code demonstrates how to use this DMV, showing you all the sessions in order of total tempdb usage:
SELECT *
FROM sys.dm_db_session_space_usage
WHERE session_id > 50
ORDER BY user_objects_alloc_page_count + internal_objects_alloc_page_count DESC ;The output won’t include any currently executing tasks, so it’s not very useful for a live issue; but you can look up the session_id in sys.dm_exec_requests to gather information about who’s using that session_id, such as their login details; the server they’re connecting from; and the application they are using.
CONFIGURATION BEST PRACTICES
Because several of the issues addressed in this chapter have required configuration changes, this section consolidates all the best practices for configuring tempdb. You won’t just find prescriptive rules here, but also the background to the recommendations and guidance on how to choose the best configuration for any particular environment. In particular this section covers the following:
- Where to place tempdb
- Initial sizing and autogrowth
- Configuring multiple files
Tempdb File Placement
It’s quite a well-known best practice to separate data, transaction logs, and tempdb, and if you knew that already, are you sure you know why? The origin of this recommendation lies with the separation of types of workload between different physical storage, i.e. separate physical disks.
This is still a valid recommendation for environments where you can guarantee that separation, but more commonly we see customers deploying SQL Server in a shared storage environment, where physical separation is much harder to achieve and usually isn’t even necessary for performance reasons.
It is still a good idea however to maintain separation to help with manageability so that potential problems are easier to isolate. For example, separating tempdb onto its own logical disk means that you can pre-size it to fill the disk (see tempdb sizing later in the chapter) without worrying about space requirements for other files, and the more separation you implement the easier it is to correlate logical disk performance to specific database files.
At the very minimum you should aim to have one logical disk for data files, one for transaction log files, and one for tempdb data files. I prefer to keep the tempdb data files on their own drive so they can be sized to fill the drive and place the tempdb log files with the user database log files where there should be enough free disk space for unexpected autogrow events for any log file.
Local Tempdb for Failover Cluster Instances
Until SQL Server 2012, a failover cluster instance of SQL Server required all its database files to be on shared disk resources within the cluster. This was to ensure that when the instance failed over to another node in the cluster, all its dependent disks could be moved with it.
As you’ve already read at the beginning of the chapter, nothing in tempdb persists after a restart and it’s effectively recreated every time. The failover process for a clustered instance involves a restart of SQL Server so nothing in tempdb needs to be moved across to the other node and there’s no technical reason why tempdb should be on a shared disk.
In SQL Server 2008 R2 you could force tempdb onto a local disk but it wasn’t supported; in SQL Server 2012 it’s fully supported and very straightforward to implement. All you need to do is use ALTER DATABASE like this:
USE master ;
GO
ALTER DATABASE tempdb
MODIFY FILE (NAME = tempdev, FILENAME = 'D: empdbdata empdb.mdf') ;
GO
ALTER DATABASE tempdb
MODIFY FILE (NAME = templog, FILENAME = 'E: empdblogs emplog.ldf') ;
GOYou will see messages after execution that look like this:
Local directory 'D: empdbdata empdb.mdf'is used for tempdb in a clustered
server. This directory must exist on each cluster node and SQL Server
service has read/write permission on it.
The file "tempdev" has been modified in the system catalog. The new path
will be used the next time the database is started.
Local directory 'E: empdblogs emplog.ldf' is used for tempdb in a
clustered server. This directory must exist on each cluster node and SQL
Server service has read/write permission on it.
The file "templog" has been modified in the system catalog. The new path
will be used the next time the database is started.That’s all there is to it. All you need to remember is that you need to have the same path available on all cluster nodes, and the service account needs to have read/write permission so that tempdb can start after failover.
Why Might a Local tempdb Be Useful?
There are two reasons why you might want to move tempdb from a shared disk to a local disk, and both are related to performance.
The first reason is that the relatively recent increase in cost effective, ultra-fast solid-state storage (see Chapter 4) presents an opportunity to achieve significant performance gains on servers experiencing heavy tempdb usage. The challenge prior to SQL Server 2012 was that solid-state storage cards, like those provided by FusionIO and Texas Instruments, plug straight into a server’s motherboard to avoid all the overhead of traditional storage buses. This made it very difficult to use them at all in failover cluster instances and now they can be used for the discrete task of running tempdb.
The second reason you might want to use a local tempdb is to take I/O requests off your shared storage to improve the performance of the shared storage. We used this to great effect for one customer who was really at the peak of their SANs performance capacity; a FusionIO card was placed in each node of several failover clusters and all tempdb activity was re-directed locally. Even though tempdb performance was never bad before, the result was a significant reduction in load against the SAN which extended its life by an additional six months.
Tempdb Initial Sizing and Autogrowth
A default installation of any SQL Server edition will create a tempdb database with an 8MB data file and a 1MB transaction log file. For a lot of SQL Server installations these file sizes won’t be enough, but they are configured to autogrow by 10% as needed. You can see the properties window for tempdb on a default installation of SQL Server 2012 Developer Edition in Figure 8-16.
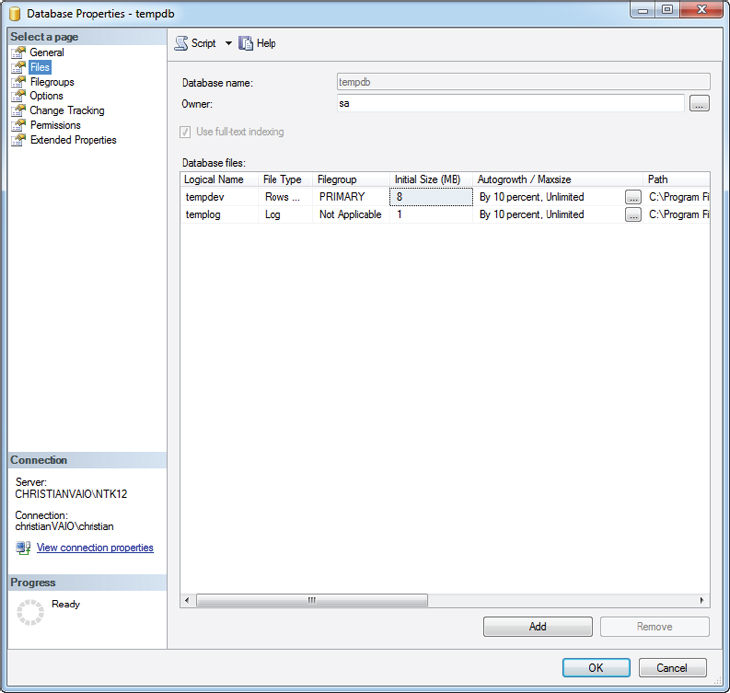
Although the autogrow feature enables a more hands-off approach to maintaining many SQL Server installations, it’s not necessarily desirable because the files cannot be used while they are autogrowing, and it can lead to fragmentation of the files on the hard disk, leading to poor performance.
This is a recommendation that would apply to any SQL Server database, but for tempdb it’s even more relevant. When you restart your SQL Server instance, tempdb is re-created (files will be reused if they already exist) and sized to the value specified in the database properties, which as you’ve just seen is only 8MB for the data file and 1MB for the log file by default.
We’ve reviewed many SQL Server installations with tempdb files of tens of GBs that have autogrown to that size and have the default properties set. The next time SQL Server is restarted, tempdb will be just 8MB and will have to start autogrowing all over again.
Figure 8-17 illustrates an example scenario of tempdb sizing.
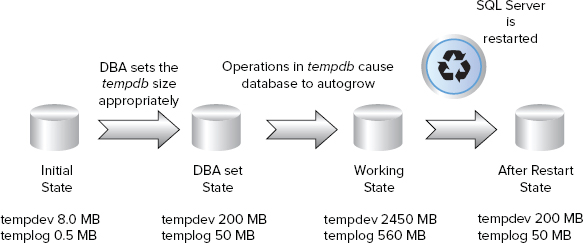
In this case, you can see the size of the initial files, which the DBA has set to 200MB and 50MB. The workload running against SQL Server has then caused the tempdb files to autogrow to 2450MB and 560MB.
SQL Server is then restarted and tempdb returns to 200MB and 50MB, as set by the DBA, and would have to autogrow again to fulfill the workload.
To What Size Should Tempdb Be Set?
This is obviously a difficult question to answer without more details about the workload, but there is still some guidance that you can use. First of all, unless you’re running SQL Server Express, set tempdb to be bigger than the default; that’s an easy one.
Next, if you can give tempdb its own disk, then configure it to almost fill the drive. If nothing else will ever be on the drive, then you’re better off setting it to be larger than you’ll ever need. There’s no performance penalty, and you’ll never have to worry about autogrow again.
If you can’t put tempdb on its own disk, then you’ll need to manage size and autogrow a bit more closely. You could just let it autogrow for a while and then manually set it to be a bit larger than what it grows to, or you could just make it a reasonable size in relation to your other databases and set large autogrow amounts.
To What Size Should Autogrow Be Set?
If you’ve moved tempdb to its own drive and configured it to almost fill the disk, then arguably you don’t need to enable autogrow. That would be a reasonable choice in this scenario, but it may be worth leaving it on if you still have a small amount of disk space left over.
The best way to think of autogrow for any database, not just tempdb, is as a last resort. Your databases should be sized appropriately so they don’t need to autogrow, but you still configure it just in case you need it.
Using fixed-growth amounts is generally a better approach for autogrow because it makes autogrow events more predictable. Autogrowing a 10GB transaction log by 10%, for example, will take a long time and will affect the availability of the database.
The Instant File Initialization (IFI) feature in Windows Server 2003 and later can make things a bit easier for autogrowing the data files, but it doesn’t work for log files because of the way they are used.
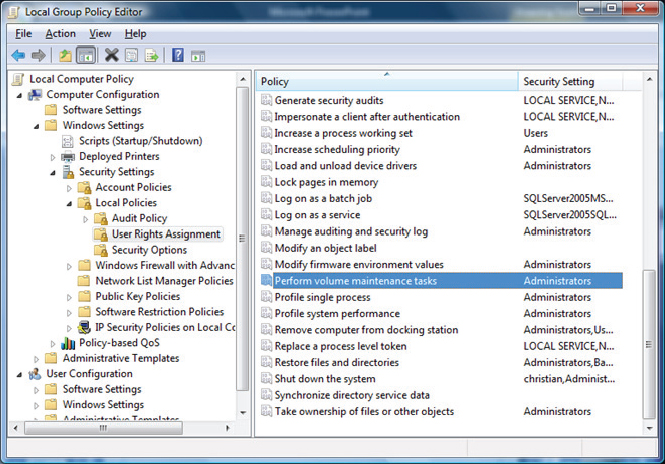
IFI is used automatically by SQL Server if the service account is a local administrator (which it shouldn’t be as a security best practice) or if the account has the Manage Volume Maintenance Tasks advanced user rights. To give the service account the necessary rights, you can use the Local Group Policy Editor, shown in Figure 8-18, by running gpedit.msc.
Once IFI is working, you can set autogrow to be large fixed amounts for data files. 50MB or 500MB are good values depending on the size of the database, but any size is created virtually instantly so you avoid any downtime.
For transaction log files, however, you need to be a lot more conservative and use a figure that balances the time it takes to autogrow and the usefulness of the extra space. Autogrowing by 1MB, for example, is quick, but you might need to do it so often that it becomes a bottleneck. Autogrowing by at least 10MB for the transaction log is a good place to start, but you may need it to be higher to provide enough space to avoid autogrowing again quickly. The best option is to avoid autogrowing in the first place by correctly sizing the files.
Configuring Multiple Tempdb Data Files
The use of multiple data files as an aid to reducing allocation contention problems for tempdb was covered earlier in the chapter. Another reason you might want to use multiple data files is to increase the I/O throughput to tempdb — especially if it’s running on very fast storage.
When you create multiple data files they will all be in the primary filegroup and SQL Server uses a proportional fill algorithm to determine which file to use for each request to create an object. If all the files are exactly the same size, then SQL Server uses the files in a “round robin” fashion, spreading the load equally across the files. This is, of course, exactly what you want.
Microsoft recommends up to a 1:1 mapping between the number of files and logical CPUs because during testing of massive workloads they’ve seen performance benefits, even with hundreds of data files.
A more pragmatic approach however, is to have a 1:1 mapping between files and logical CPUs up to eight, and then add files if you continue to see allocation contention or if you’re looking to push the I/O subsystem harder. The performance benefit from adding files diminishes each time, and in our experience, eight is the sweet spot, especially if you’re implementing this as a pro-active measure.
Whether or not you configure multiple data files as a best practice on all your SQL Servers or just on those for which you’ve detected issues is a choice only you can make. However, you might want to configure them on all the servers you work with as a proactive measure, as it’s hard to see a downside.
SUMMARY
This chapter introduced the concept of, and many uses for, the tempdb database in SQL Server 2012, as well as some of the most common problems you might encounter and how to avoid them.
The key points from this chapter are as follows:
- Three types of objects can be found in tempdb: user-created, internally created, and the version store.
- Latch contention is a common problem even in SQL Server 2012, but it is easy to resolve and even avoid.
- You should familiarize yourself with the following DMVs for help in troubleshooting urgent tempdb space issues:
- sys.dm_db_file_space_usage
- sys.dm_db_task_space_usage
- sys.dm_db_session_space_usage
- Appropriately sizing and configuring tempdb should be paramount for any SQL Server installation to avoid performance issues later.